초격차 패키지 : 한 번에 끝내는 자연어 처리
초격차 패키지 Online.
한 번에 끝내는
자연어 처리

-
한국어 특화 자연어 처리 커리큘럼
자연어 처리 중 유독 어려운
한국어 자연어 처리 노하우를
익힐 수 있는 강력한 커리큘럼! -
최신 알고리즘도 모두 섭렵 가능!
Hugging-face를 활용한
Transformer 실습부터
하이퍼파라미터의 의미 파악까지 -
내 Task에 적용할 수 있는 강의
요즘 자연어 처리의 가장 핫 이슈인
Pretrained Model을 어떻게 내 Task에
활용할 지 학습 가능
요즘 핫한 ChatGPT의 근간이 되는 자연어 처리 기술!
이녕우 강사님이 설명해주는 ChatGPT 이야기도 들어보세요!👇
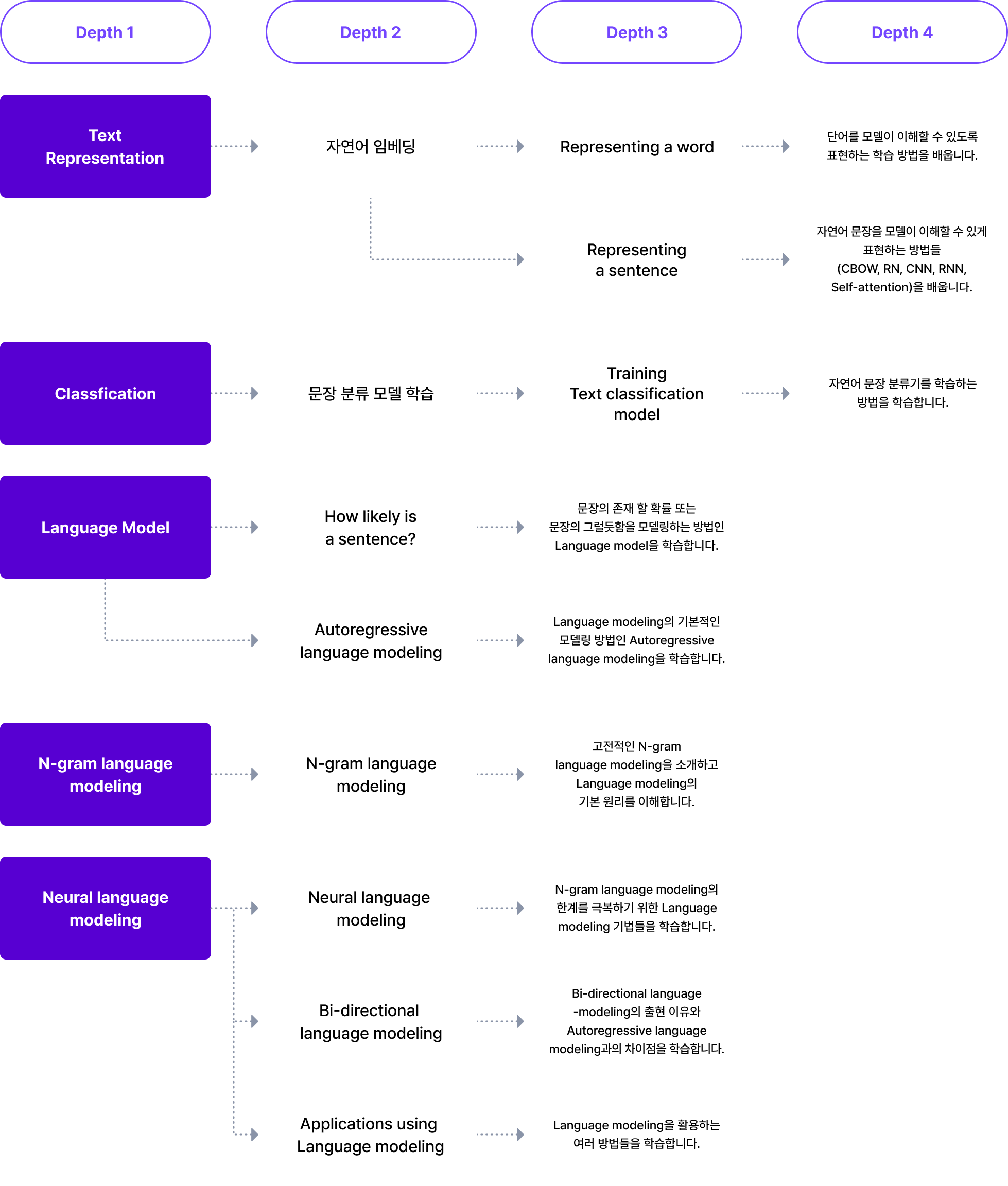
NLP의 가장 기본 Task부터 최신 Transformer까지
한 번에 공부하는 방법!
패스트캠퍼스 초격차 강의로 가능합니다!
자연어 처리 초격차 패키지만의
특별한 3가지 Point




자연어 처리 기초 이론부터
한국어 Application 구성까지
경험해 볼 수 있는 커리큘럼 로드맵




자연어 처리 기초 이론부터
한국어 Application 구성까지
경험해 볼 수 있는 커리큘럼 로드맵
-
KLUE 란?
한국어 자연어 이해 평가 데이터셋(Korean Language Understanding Evaluation Benchmark)의 약자로,
한국어 언어모델의 공정한 평가를 위해 개체명 인식, 관계 추출 등 8개 종류의 한국어 자연어 이해가 포함 된 데이터 집합체



이 외에도 다양한 KLUE 데이터셋을 다루고 한국어 데이터를 활용한 Application을 구성해보실 수 있습니다.
수강 후에 한국어 자연어 처리에 대한 이해가 한층 더 높아질 거예요!

수강생들을 위해 직접 제작한
실습 환경 자료부터 최신 자연어 처리 트렌드 정리 뉴스레터까지-


강의 하나로 자연어 기초부터 Transformer까지
모두 마스터하고 싶다면
패스트캠퍼스 초격차 패키지로 시작하세요!



머신러닝과 딥러닝으로
자연어 기본기 마 · 스 · 터
기초 수학 지식부터 머신러닝 기본기,
인공신경망 구현을 통해 자연어 처리 기본기 완성!



이론 학습 후 실습을 통해
원리까지 완벽하게 이해합니다!
Step 1
Machine Learning 실습



Step 2
Deep Learning 실습


자연어를 다루기 위한 Text 표현 방법론과
Large Modeling의 원리 파악
딥러닝 모델이 자연어를 이해할 수 있도록 여러가지 형태로 변환하는 방법을 배우고
BERT, GPT-3등 최신 Large Language Model의 출현 배경과 Large Model의 원리를 학습합니다.

이론 학습 후 실습을 통해
원리까지 완벽하게 이해합니다!
Step 1
Machine Learning 실습




Step 2
Deep Learning 실습


자연어를 다루기 위한 Text 표현 방법론과
Large Modeling의 원리 파악
딥러닝 모델이 자연어를 이해할 수 있도록 여러가지 형태로 변환하는 방법을 배우고
BERT, GPT-3등 최신 Large Language Model의 출현 배경과 Large Model의 원리를 학습합니다.
point 1.
주요 자연어 처리 Task 이론 학습










point 2.
실습을 통해 주요 자연어 처리 Task 심층 이해
-
 실습 내용
실습 내용
∙ 자연어 처리 실습을 위한 Google Colab 환경을 소개합니다.
∙ 자연어 처리 분야의 주요 모듈인 Huggingface의 사용법을 익히기 위해, 네이버 영화 긍·부정 분석 작업을 실습해봅니다. -
 실습 내용
실습 내용
∙ 일반적인 한국어 코퍼스의 전처리 과정에 대해 학습합니다.
∙ 자연어 코퍼스 수집 → Tokenization → Preprocessing → Normalization
전 과정을 이해할 수 있도록 간단한 실습을 진행합니다. -
 실습 내용
실습 내용
∙ 학습된 언어 모델을 사용하여 두 문장 간 벡터 유사도를 구합니다.
∙ 학습된 BERT 모델을 다운받아서 예시 문장들 간 벡터 유사도를 계산합니다. -
 실습 내용
실습 내용
∙ 학습된 언어 모델의 시각화 된 임베딩을 관찰합니다.
∙ 공개된 BERT 모델의 임베딩 프로젝터를 사용하여 시각화 된 임베딩을 관찰합니다.
-
 실습 내용
실습 내용
∙ 한국어 코퍼스 데이터로 Word2vec을 만듭니다.
∙ 네이버 영화 리뷰 데이터를 다운 받아 한국어 Word2vec을 만들어봅니다. -
 실습 내용
실습 내용
∙ 문장 임베딩을 활용하여 간단한 답변 랭킹 모델을 만들어봅니다.
∙ 공개된 한국어 챗봇 데이터 셋(Chattbot_data_for_Korean v1.0)을 활용하여 BERT를 학습하고, 이를 활용하여 간단한 답변 랭킹 모델을 만듭니다. -
 실습 내용
실습 내용
∙ 사전학습 된 BERT 모델을 파인튜닝하여 다양한 기법들을 시도합니다.
∙ 네이버 영화 리뷰 데이터로 파인튜닝하여 성능을 분석하고 다양한 파인튜닝 기법들에 대해 실습합니다. -
 실습 내용
실습 내용
∙ NLU Task 중 하나인 자연어 추론 실습을 진행합니다.
∙ KLUE-NLI 데이터 셋을 활용하여 자연어 추론 실습을 진행합니다.
-
 실습 내용
실습 내용
∙ 기계 번역 Task에 대한 간단한 실습을 진행합니다.
∙ AI-Hub에 있는 한국어 · 영어 데이터로 기계 번역 실습을 진행합니다. -
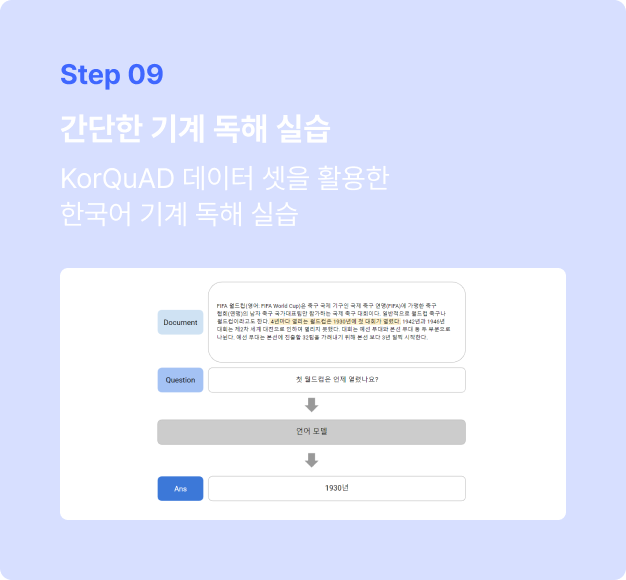 실습 내용
실습 내용
∙ 기계 독해 Task에 대한 간단한 실습을 진행합니다.
∙ KorQuAD 데이터 셋을 활용하여 간단한 한국어 기계 독해 실습을 진행합니다. -
 실습 내용
실습 내용
∙ 자연어 문장 생성에 대한 간단한 실습을 진행합니다.
∙ GPT 기반의 모델로 다양한 추론 방법을 활용하여 자연어 문장을 생성하고 평가하는 방법을 실습합니다.

Attention Mechanism의 이해
왜 자연어 처리에서 Attention Mechanism이 등장하게 되었는지에 대한 배경과
기존에 RNN이 가지고 있던 고질적인 문제를 어떻게 해결하고 있는지 학습합니다.
-
Attention Mechanism이란?
자연어 처리 Task에서 입력 시퀀스(문장)가 길어질수록
출력 시퀀스(문장)의 정확도가 떨어지는 현상을 보정해주기 위해 등장한 기법입니다.




[Attention Mechanism의 구조 학습]

Transformer
Transformer의 등장 배경 및 동작 원리를 학습합니다.
이후 Transformer의
Encoder, Decoder 구조를 파악하고 학습 파라미터에 대해 학습합니다.

Transformer의 등장 배경 및 동작 원리를 학습합니다. 이후 Transformer의 Encoder, Decoder 구조를 파악하고 학습 파라미터에 대해 학습합니다.

Query, Key, Value의 기본 컨셉에 대해 이해합니다.

Attention 연산을 행렬로 처리합니다.

Input, Position Embedding에 대해서 이해하고, Transformer가 자연어 처리 데이터에 적합한 이유를 학습합니다.
Transformer의 기본 원리를 학습한 뒤에 Transformer를 동작하는 2개의 Attention Mechanism과
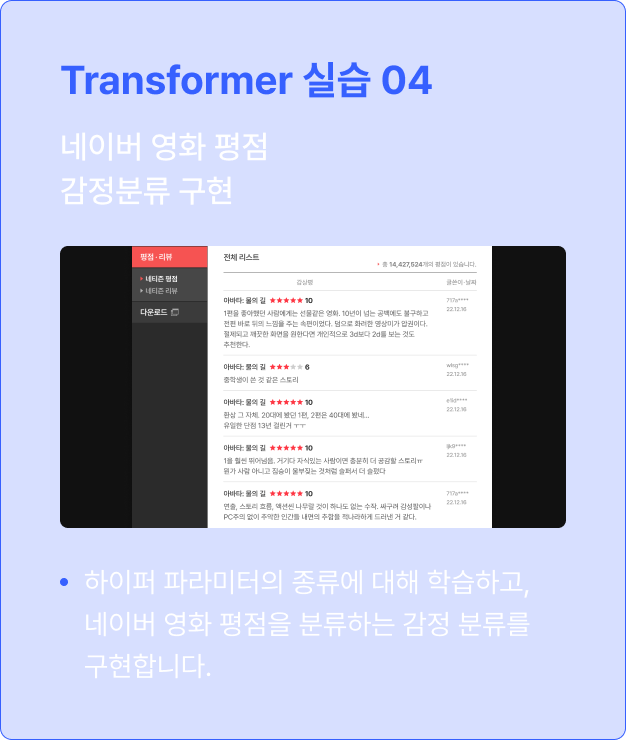
네이버 영화 평점 감정 분류 구현, 시퀀스(문장)를 번역할 수 있는 번역기의
두 아키텍쳐 Encoder, Decoder를 학습하고 구현합니다.




Encoder와 Decoder를 조합하여 트랜스포머를 구현해 보았다면
이번에는 하이퍼파라미터에 대해 학습하고 손실 함수를 정의합니다.




Pretrained Language Model
사전 학습 모델(PLM)의 의미와 대표 모델의 구조적 특성 및 학습 방법에 대해 알아봅니다.
실제 어떻게 PLM을 활용하는지 뉴스기사 요약 실습을 통해 학습할 수 있습니다.





Huggingface 실습
Transformer에서 활용 가능한 프레임워크 중 가장 많이 쓰이는
Huggingface 프레임워크를 활용하여 대표 모델들을 실습합니다.







KLUE 실습
한국어 자연어 이해 벤치마크 KLUE로 총 8개의 Task를 이해하고 실습합니다.
한국어 표준 데이터셋으로 다양한 모델을 미세 조정할 수 있고, 모델의 성능을 직관적으로 확인합니다.









학습하다 궁금하면 바로 질문하세요!
언제든 질의응답이 가능한 디스코드 채널 운영
현업에서 NLP 전문가로 근무하고 계시는 강사님들이 직접 답변해드립니다!

*교육 내용 범주 안에서만 질의응답 가능합니다.
*2023년 1월 30일부터 2025년 1월 30일까지 운영됩니다.
-
상세 커리큘럼
자세한 커리큘럼 및 내용은 여기서 확인하세요!

강사 소개

김성주 강사님
현) N사 Tech Lead
전) N사 AI·ML 개발자
전) 노매드커넥션 AI 연구원
프로젝트 경력
· N사, Question Answering 모델 개발
· N사, ODAQ를 위한 Neural Information Retrieval 모델 개발
· N사, Pretrained Language Model 개발
· N사, 대화시스템 개발

이녕우 강사님
현) 스캐터랩 Machine Learning Researcher
프로젝트 경력
· Scatterlab, 이루다 제품 연구 개발 (Alignment Research, Continual Learning)
· KAIST KEAI (NLP) 연구실, 챗봇 관련 연구 프로젝트 진행(2020~2022)
· KAIST KIXLAB (HCI) 연구실, 챗봇 관련 연구 프로젝트 진행(2018~2019)
· 스타트업 운영 및 시드 투자 유치(2015~2016)
연구 경력
· PNEG : Prompt-based Negative Response Generation for Dialogue Response Selection Task, Nyoungwoo Lee, ChaeHun Park, Ho-Jin Choi, Jaegul Choo, ACL 2022
· Constructing Multi-Modal Dialogue Dataset by Replacing Text with Semantically Relevant Images, Nyoungwoo Lee, Suwon Shin, Jaegul Choo, Hojin Choi, Seonghyon Myaeng, ACL 2021
· ProtoChat : Supporting the Conversation Design Process with Crowd Feedback, Yoonseo Choi, TJK Monserrat, Jeongeon Park, Hyungyu Shin, Nyoungwoo Lee, Juho Kim, CSCW 2020

이도명 강사님
현) 신한카드 NLP Engineer
전) 인공지능연구원(AIRI) Researcher
프로젝트 경력
· 신한카드, AI 모델 적용한 상담 자동화 시스템 개발
· AIRI, 대규모 사전학습 언어모델 연구개발
· AIRI, 적대훈련[Adversarial Training] 관련 연구개발
커리큘럼
아래의 모든 강의를 초격차 패키지 하나로 모두 들을 수 있습니다.
지금 한 번만 결제하고 모든 강의를 평생 소장하세요!
Step 1. 자연어처리에 필요한 기본 수학지식 및 딥러닝 기초
Step 2. 주요 자연어처리 Task 및 실습
Step 3. 최신 자연어 처리 알고리즘
이 강의도 추천해요.
