스크래치부터 시작하는 강화학습의 모든 것
Online Course.
스크래치부터 시작하는
강화학습의 모든 것

-
모델 개선과 실무에서의 활용 연계성을
고려한 커리큘럼 구성!강화학습 모델을 개선하면서 자주 발생하는
오류 및 디버깅 과정을 담아 문제를 해결 -
강화학습의 성능 확장 원리를
단계별로 이해할 수 있는 방법론불안정하고 유동성이 큰 현업 환경에서
성능 개선에 도움을 주는 아이디어 학습 -
스크래치부터 단계별로
구현하는 강화학습벤치마크 환경을 하나하나 뜯어 보면서
강화학습 구현을 위한 시물레이션 환경 구축
최근 강화학습은 우리 주변에서
어떻게 활용되고 있을까요?

-
 01. CHAT GPT인공지능 기업 OPEN AI는 사람이 모델의 결과에 대해 평가한 피드백을 반영하고 loss를 설계한 RLHF 훈련을 통해 사용자의 지시를 따르고 만족스러운 반응을 생성하는 AI 모델을 만들었습니다.
01. CHAT GPT인공지능 기업 OPEN AI는 사람이 모델의 결과에 대해 평가한 피드백을 반영하고 loss를 설계한 RLHF 훈련을 통해 사용자의 지시를 따르고 만족스러운 반응을 생성하는 AI 모델을 만들었습니다. -
 02. 게임NC Soft의 ‘리니지’ 는 MMORPG 게임 특성 상 반복되는 패턴의 사냥이 플레이어들에게 있어 피로감을 느끼기 쉬워, AI 강화학습 기술로 다양한 상황에 맞는 지능적인 전투를 선보였습니다.
02. 게임NC Soft의 ‘리니지’ 는 MMORPG 게임 특성 상 반복되는 패턴의 사냥이 플레이어들에게 있어 피로감을 느끼기 쉬워, AI 강화학습 기술로 다양한 상황에 맞는 지능적인 전투를 선보였습니다.
-
 03. 자율주행기아 자동차는 세계 최초로 '전방 예측 변속 시스템'을 도입하여 내리막길, 과속 방지턱 등의 구간에서 더 안전하게 통과할 수 있게 되었습니다.
03. 자율주행기아 자동차는 세계 최초로 '전방 예측 변속 시스템'을 도입하여 내리막길, 과속 방지턱 등의 구간에서 더 안전하게 통과할 수 있게 되었습니다. -
 04. 금융·투자신한 금융그룹은 국내 금융권 최초로 강화학습 인공지능 알고리즘이 적용된 ‘신한BNPP SHAI네오(NEO)자산배분 증권투자신탁’ 과 ’신한 NEO AI 펀드랩’을 출시하였습니다.
04. 금융·투자신한 금융그룹은 국내 금융권 최초로 강화학습 인공지능 알고리즘이 적용된 ‘신한BNPP SHAI네오(NEO)자산배분 증권투자신탁’ 과 ’신한 NEO AI 펀드랩’을 출시하였습니다.
다양한 분야에서 활용되는 강화학습
그러나
 실제 활용에서는
실제 활용에서는
어떤 어려움들이 있을까요?


실무에서 강화학습 적용이 어려운 수강생들을 위해
패스트캠퍼스가 준비했습니다!

단계별 성능 개선 방법 부터
강화학습의 최신 기법까지 확실하게 알려드립니다.







실전 문제 해결력!
스크래치부터 구현하는 강화학습을 수강하면
갖출 수 있습니다!
-

강화학습은 알고리즘 성능만 좋다고 만능이 아닙니다.
실제로 성능에 영향을 끼치는 요소들을 학습하며
차근차근 개선해나갑니다. -

META RL과 OFFLINE RL을 학습하여
한정된 환경 속 기존 강화학습 대비
더 좋은 결과를 낼 수 있는지 학습합니다.
-

해결하고자 하는 문제가 강화학습에서 다루는
‘환경’적으로 명확한 경우와 명확하지 않은 경우
모두 환경을 구성하여 문제를 해결할 수 있습니다. -

현업의 문제에서 상태, 행동, 트렌지션을
어떻게 구성하고 시스템을 설계하여,
시뮬레이션 환경을 구축하는지 학습합니다.
강화학습을 완벽하게 끝내 줄
핵심 포인트 6가지!

Point 01
강화학습의 이해를 돕기 위한 기초 지식
지도학습, 비지도학습과 비교하며
강화학습만의 특징과 차이점을 학습합니다.
-
 Step 1강화학습이 어떤 형태의 학습 방법인지 알아보고 강화학습의 예시를 알아봅니다.
Step 1강화학습이 어떤 형태의 학습 방법인지 알아보고 강화학습의 예시를 알아봅니다. -
 Step 2지도학습, 비지도학습과 비교하며 강화학습만의 특징과 차이점을 학습합니다.
Step 2지도학습, 비지도학습과 비교하며 강화학습만의 특징과 차이점을 학습합니다. -
 Step 3강화학습에서 쓰이는 가장 기본적인 개념인 Agent, Environment, Action, State, Policy, Reward의 의미를 학습합니다.
Step 3강화학습에서 쓰이는 가장 기본적인 개념인 Agent, Environment, Action, State, Policy, Reward의 의미를 학습합니다.
Point 02
MDP의 이해
가치함수, 행동가치함수
강화학습에서 환경을 묘사하는 개념인 MDP를 학습하고
가치함수, 행동가치함수의 수식적 표현을 이해합니다.


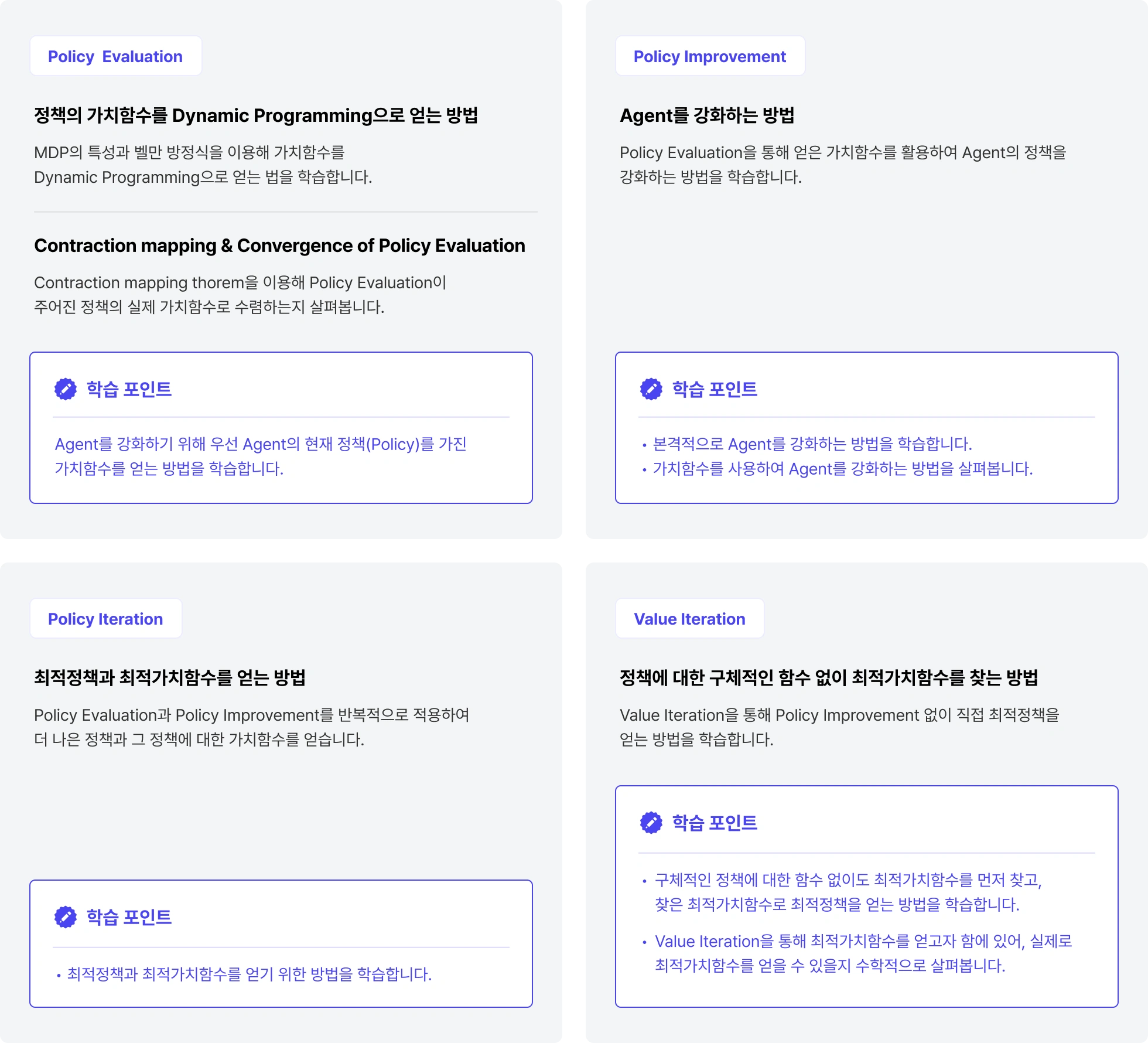
Point 03
Planning by Danamic
Programming
환경에 대한 MDP 모델과 Dynamic Programming을 이용하여
Agent를 강화하는 알고리즘을 학습합니다.
Point 04
Model Free Learning &
TD Learning
환경에 대한 MDP 모델없이 Agent를 강화하는
알고리즘을 학습합니다.





Point 05
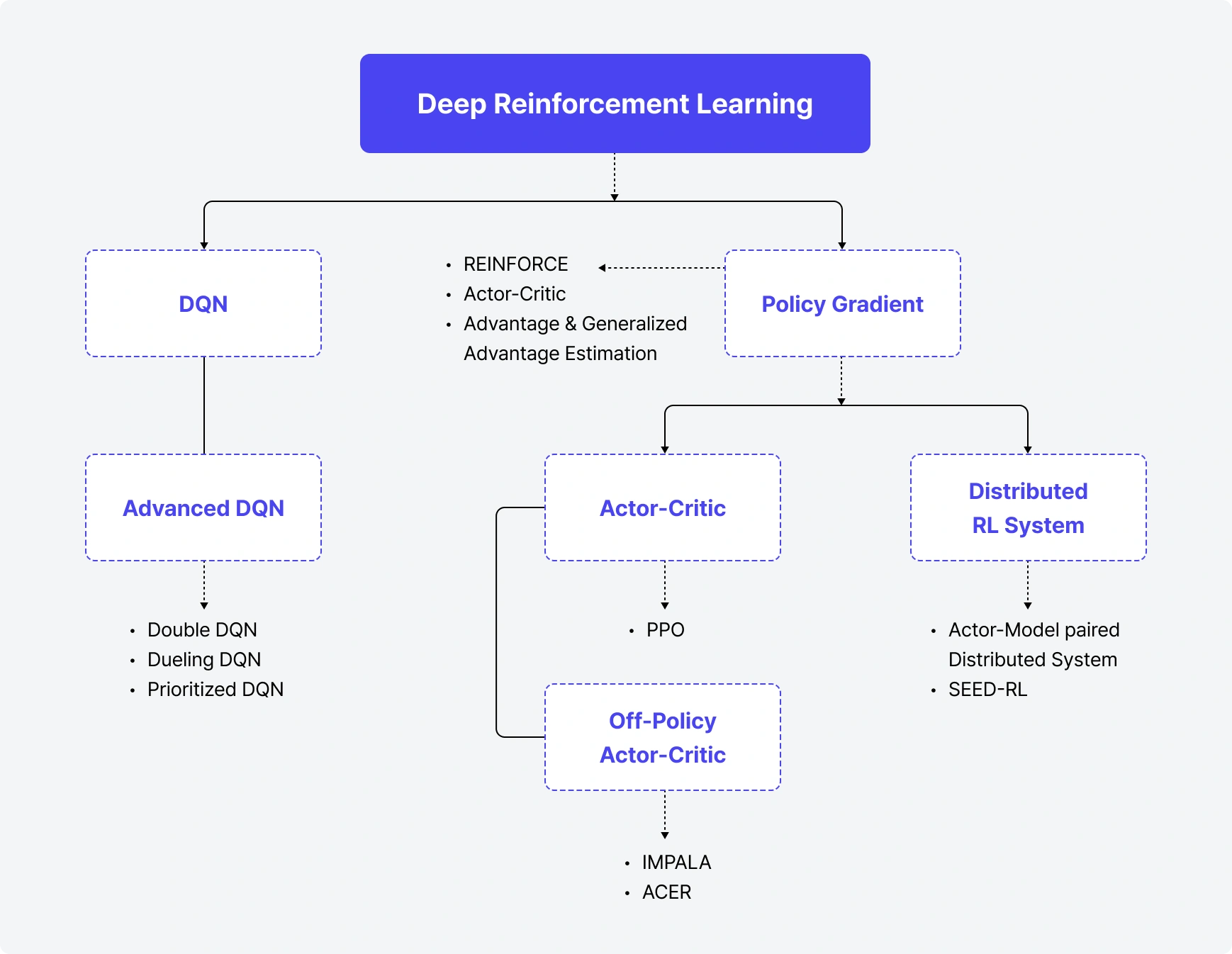
Deep Reinforcement Learning
강화학습의 대표적인 방법론 DQN, Actor-Critic을 공부합니다.
각 방법론에서 성능, 안정성, 효율이 더 향상된 알고리즘과
개선점을 학습합니다.

Deep Reinforcement Learning 파트 수강 후
수강생 여러분들은 이렇게 실무에 도움이 될 수 있습니다.
각 알고리즘 별 실습을 하게 되면서 알고리즘의 하이퍼파라미터 조정과 디버깅하는 방법을 학습하실 수 있습니다.
강화학습에서 알고리즘의 하이퍼파라미터 조정과 디버깅을 하는 가장 큰 이유는 더 우수한 성능 Agent를 학습시키기 위한
목적으로 진행되기 때문입니다. 또한 알고리즘과 별개로 강화학습을 실제로 적용하면서 더 높은 성능을 구현하기 위해
Reward, Discount Factor, Batch Size, Sequence Length, Model Structure 등의 요소들을 설정하는 방법을 학습합니다.
Point 06
Advanced Deep Reinforcement Learning
기존의 강화학습 알고리즘은 데이터 셋을 처음부터 스스로 수집하여야 하기 때문에 굉장히 비효율적입니다.
기존의 데이터 셋, 미리 학습한 사전 정보, 사람의 Feedback을 활용하여 데이터 효율을 증가시키고
나아가 실제 문제 해결에 한 걸음 더 가깝게 학습합니다.

강화학습에 필요한 시뮬레이션 환경 구축
• 강화학습 알고리즘을 적용하기 위해 반드시 정의 되어야 하는 상태, 행동, 보상, 전이확률에 대한 개념을 복습합니다.
• 직접 구현해 본 시뮬레이터에 PPO 알고리즘을 구현합니다.
• 직접 구현해 본 시뮬레이터에 Actor-Critic 알고리즘을 구현합니다.
| 강의에서 사용하는 시뮬레이터 환경 - MuJoCo
Offline RL
• Offline RL 중 Model을 학습하지 않는 Model Free 기법을 학습합니다.
• Offline Dataset을 어떻게 활용하는지 학습하여 강화학습의 데이터 효율을 증가시키는 원리를 이해합니다.
• Offline RL 중 Model을 학습하는 Model Based 기법을 학습합니다.
• Model Based와 Model Free 간의 차이를 이해하고 각각 구현합니다.
| 정교한 Task를 한 번에 수행하는 Policy로 학습하여 기존 강화학습 대비 복잡한 결과 수행이 가능한 Offline RL
Meta RL
• Meta RL의 개념과 최신 Meta RL 논문 리뷰를 통해 실제 환경에서 Meta RL이 어떻게 적용되는지 학습합니다.
• 물리적인 현상을 빠르고 자연스럽게 구현할 수 있는 MuJoCo 환경을 활용하여 MAML, MAESN, PEARL, ST Protocol 기법을 학습합니다.
| 적은 업데이트만으로 빠르게 Task Adaptation이 가능한 META RL
Preference Based RL
• 사람의 Feedback으로 보상함수를 학습하고 이를 통해 RL을 구현합니다.
• 비지도 사전학습, 랭킹 정보, 리워드 네트워크의 학습 방식을 구현합니다.
| 보상함수를 특정하기 어려운 Backflip 동작을 Human Feedback으로 학습한 Preference Based RL
Point 07
궁금한 내용은 언제든 디스코드 질의응답 채널에 질문하세요!
현직 강화학습 전문가들이 직접 답변 드립니다!
* 디스코드 질의응답 운영 기간은 2023년 4월 28일 ~ 2025년 04월 28일 입니다.
-
상세 커리큘럼.
자세한 커리큘럼 및 내용은 여기서 확인하세요!

수업 실습 환경
-

별도의 개발 지식 없이
사용할 수 있는 구글 코랩을
활용하여 실습이 진행됩니다. -

경로 이동, 파일 생성, 파이썬 커맨드
실행 등 기초 수준의 지식으로
Linux(Python 3.7) OS를 활용하여
실습이 진행됩니다. -

강화학습 Mujoco 환경을 활용하여
실습이 진행됩니다.
강사소개

권태환 강사님
[이력]
현) 카카오브레인 AI 연구원전) NC Soft 강화학습팀 연구원
프로젝트 및 연구 경력
• 리니지 거울전쟁 AI 개발 프로젝트 진행
• Starcraft2 환경에서 강화학습 기반 AI 연구 및 개발 진행
• NeurlPS 2022 IGLU Challenge 강화학습 부문 우승
• NeurlPS 2021 NetHack Challenge Neural Agent 부문 준우승

이경재 강사님
[이력]
현) 중앙대학교 RAI LAB 조교수 & 연구책임자프로젝트 및 연구 경력
• Robot Learning for Object Manipulation with Uncertainty-Aware Autonomous Data Generation and Task Optimization (2021 ~ )
• [SW Star Lab] Robot Learning: Efficient, Safe, and Socially-Acceptable Machine Learning (2019 ~ 2020)
• Intelligent Agent System using Reinforcement Learning (2019 ~ 2020)
• Learning-Based Robotic Grasping (2019)
• Robot Learning from Demonstrations with Mixed Qualities (2017 ~ 2019)
• Human-Level Lifelong Machine Learning (2014 ~ 2017)
• Biomimetic Recognition Technology (2013 ~ 2018)
• Human-Centric Networked Robotics Technology (2013 ~ 2016)
커리큘럼
Part 1. Introduction to Reinforcement Learning
Part 2. MDP & Value Function & Action Value Function
Part 3. 환경에 대한 MDP 모델과 Dynamic Programming으로 Agent를 강화하는 알고리즘
Part 4. 환경에 대한 MDP 모델 없이 Agent를 강화하는 알고리즘
Part 5 & 6. Deep Reinforcement Learning
Part 7. Advanced Deep Reinforcement Learning
