MCP의 문제점(Context Window오염)과 새로운 해결책, feat. Code Execution, skills방식
Disclaimer:
아래 글은 11월4일 공개된 Anthrophic Blog, Cloudflare Blog글(Reference 링크 아래 필독)을 기반으로 정리한 내용이므로 추가적 자세한 내용은 반드시 Reference자료를 확인하실것을 추천합니다.
최근 AI업계에서 MCP버블이라고 불릴만큼 유행중인데 최근 MCP개발사인 Anthrophic이 자신들이 설계한 MCP프로토콜에 심각한 문제가 있다는것을 시인했고, 공개된 MCP문제점과 해결방안에 대한 내용이 포함이 되길 희망합니다.
간단히 말씀드리면 MCP프로토콜의 인증기능부재, 비효율적 컨텍스트낭비, PII나 민감데이터 포함문제, Sandbox문제등 여러가지 구조적 프로토콜 근본문제에 대한 하나의 해결방안이라고 보시면 될 것 같습니다.
세줄요약
기존 MCP 방식의 가장 비효율적 문제는 모든 tool definition과 중간 결과(대량 데이터)를 매번 LLM context에 밀어 넣어서 token/비용/latency를 폭발시키고, LLM에게 data plumbing까지 떠맡기는 구조다.
Code execution 방식은 MCP 호출·loop·filtering·가공을 sandbox된 Python/TypeScript 코드에서 처리하고, 그 결과의 핵심 요약만 LLM에 다시 넘기는 구조다.
그래서 LLM은 MCP와 직접 계속 통신하지 않고, 정말 필요한 정보만 받아서 reasoning·요약·결정에 집중할 수 있게 되어 훨씬 효율적이다.
MCP의 근본적 문제점과 '코드 실행'을 통한 해결책
MCP(Model Context Protocol)는 AI 에이전트와 외부 도구를 연결하는 표준 프로토콜이지만, 초기 사용 방식에는 심각한 비효율 문제가 있었습니다.
문제점: 컨텍스트 과부하와 누적
기존 방식은 수백 개의 도구 정의를 대화 시작 시점에 전부 모델의 컨텍스트 창에 주입하고, 각 도구 호출의 결과까지 대화 기록에 계속 누적시키는 방식이었습니다. 예를 들어, 구글 드라이브에서 문서를 읽어 세일즈포스에 업데이트하려면, 문서 전체 내용이 컨텍스트에 추가된 후, 모델이 이 내용을 다시 복사해 다음 도구를 호출해야 했습니다. 이는 응답 속도 저하, 토큰 비용 급증을 유발했으며, 불필요한 정보 과부하로 모델의 성능까지 저하시켰습니다.
그외 문제점으로 Auth인증부재, 중간 데이터(민감정보 PII, 내부 문서 전체 내용 등)가 전부 모델 context로 들어갈 수 있다. => provider에게 공유되는 데이터 범위가 커진다.
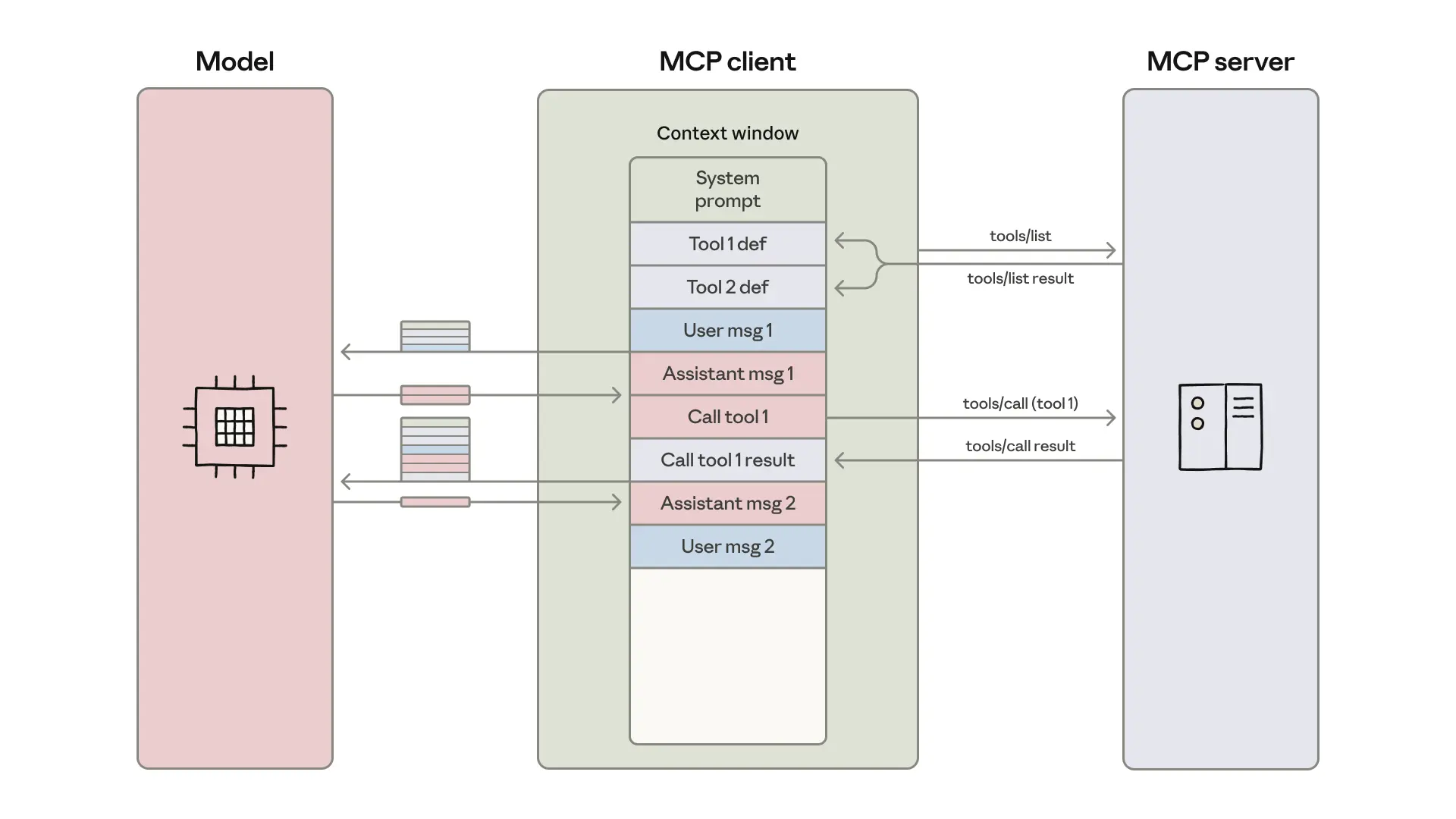
해결책: 코드 실행 (Code Execution) 패러다임
이 문제의 해결책으로 MCP 창시자인 앤트로픽과 클라우드플레어 모두 '코드 실행' 방식을 제시합니다. 이는 LLM이 MCP 도구를 직접 호출하는 대신, 도구들을 TypeScript 같은 API로 변환하고, LLM이 이 API를 호출하는 코드를 작성하도록 하는 패러다임의 전환입니다.
모델은 필요한 도구만 동적으로 로드(import)하고, 데이터 처리는 코드 실행 환경(샌드박스) 내에서 변수로 다룹니다. 덕분에 회의록 같은 대용량 중간 결과가 모델의 컨텍스트에 포함되지 않아 토큰 사용량을 98% 이상 획기적으로 줄일 수 있습니다. 또한, LLM이 훨씬 더 잘하는 코드 작성을 활용해 반복문, 조건문 등 복잡한 로직 수행이 쉬워지며, 민감 데이터가 모델에 전송되지 않아 보안과 개인정보보호가 크게 강화됩니다.
결론적으로, '코드 실행'은 LLM의 강점을 극대화하여 기존 MCP의 비효율과 비용 문제를 해결하고, 더 강력하고 안전하며 확장 가능한 AI 에이전트를 구축하는 핵심적인 방법론입니다.


해결책의 방향: “툴이 아니라 코드로 생각하자”
Anthropic + Cloudflare의 공통 아이디어는 단순하다.
LLM에게 수백 개의 MCP tools를 직접 쓰게 하지 말고,
“TypeScript API + 코드 실행 환경”을 줘서
LLM이 코드를 써서 MCP를 호출하게 하자.
핵심 변화:
모델에게 expose되는 tool은 사실상 단 하나:
execute_code(또는 Cloudflare의 경우 “codemode 실행 tool”)MCP server들은 **코드 레벨의 API (TS functions)**로 묶인다.
LLM은
필요할 때만 tool 정의를 읽어오고
TypeScript로 작은 프로그램을 작성하고
그 프로그램 안에서 MCP tool들을 호출하고
필요한 결과만 log/return해서 모델에 보여준다.
토큰/구조 측면에서 보면:
대량의 tool 정의 → 코드 환경 안의 파일/타입 정의로 이동
대량의 툴 결과 → 코드 환경 메모리/파일 안에 있고,
모델에게는 summary나 잘린 일부만 전달
Anthropic: “Code execution with MCP” 구조
파일 트리로 MCP tool을 노출 Anthropic 글에서 제안한 구조는 대략 이런 TypeScript 프로젝트다.
```
servers/
google-drive/
getDocument.ts
getSheet.ts
index.ts
salesforce/
updateRecord.ts
query.ts
index.ts
skills/
save-sheet-as-csv.ts
...
workspace/
... (중간 결과 파일)
```
각 MCP tool은 TS function으로 감싸진다.
// ./servers/google-drive/getDocument.ts
import { callMCPTool } from "../../client"; // MCP client 래퍼
// MCP tool 입력 타입 정의
interface GetDocumentInput {
documentId: string;
fields?: string[];
}
// MCP tool 출력 타입 정의
interface GetDocumentResponse {
content: string;
title: string;
}
// Google Drive에서 문서를 읽어오는 래퍼 함수
export async function getDocument(
input: GetDocumentInput,
): Promise<GetDocumentResponse> {
// 실제 MCP tool 이름은 예: "google_drive__get_document"
return callMCPTool<GetDocumentResponse>("google_drive__get_document", input);
}
이걸 사용하는 코드 예시:
// ./scripts/addTranscriptToLead.ts
import * as gdrive from "../servers/google-drive";
import * as salesforce from "../servers/salesforce";
export async function run() {
// 1. Google Drive에서 transcript를 읽는다
const doc = await gdrive.getDocument({ documentId: "abc123" });
// 2. Salesforce lead를 업데이트한다
await salesforce.updateRecord({
objectType: "SalesMeeting",
recordId: "00Q5f000001abcXYZ",
data: { Notes: doc.content }, // 대량 텍스트는 코드 환경 안에만 존재
});
console.log("Salesforce lead updated with transcript");
}
Anthropic이 권장하는 모드: workspace + skills + 파일트리
Anthropic 글의 진짜 포인트는 "재사용 가능한 코드/skill을 점점 쌓아라”쪽이다.
새로 제안된 MCP 단점을 극복한 패턴 정리:
MCP = 통합 RPC layer
tool 정의 + auth + connectivity를 표준 방식으로 제공하는 “백엔드”
LLM = 코드 작성기
MCP tool을 직접 부르는 클라이언트가 아니라,
MCP용 TypeScript/Python SDK를 사용하는 “에이전트 코드”를 작성하는 존재
코드 실행 환경 = 실제 orchestrator
MCP client, 파일시스템, 상태, security policy를 모두 이 레이어에 구현
모델은 고수준 전략과 코드 생성에만 집중
Cloudflare Code Mode, Anthropic code execution은
이 패턴을 각각 Workers 기반 / 일반적인 code runner 기반으로 구현한 사례다.
tool schema 레벨에서 무슨 일이 일어나는지
예를 들어 MCP client가 모델에게 이런 tool 하나만 알려준다고 하자:
{
"name": "executeTypescript",
"description": "주어진 TypeScript 코드를 sandbox에서 실행한다",
"parameters": {
"type": "object",
"properties": {
"code": { "type": "string" }, // 실행할 코드 전체
"entry": { "type": "string" } // 진입점 함수 이름 (예: "run")
},
"required": ["code", "entry"]
}
}
system prompt에는 대략 이런 식의 규칙이 들어간다 (요약):
MCP servers는
./servers/...디렉토리를 통해 TypeScript 함수로 노출되어 있다.사용자는 자연어로 일을 시키고, 너는 필요한 경우
executeTypescripttool을 호출해서run()함수를 가진 코드를 작성해 실행해라.코드는 반드시
run()을 export해야 한다.console.log에 찍은 내용이 모델로 돌아온다. Anthropic+1
이 상태에서 유저가:
“Google Drive에서 sheet 읽어서
Status === "pending"인 row만 세고,샘플 5개만 보여줘”
라고 말하면, **모델이 출력하는 건 코드 자체가 아니라 “tool call + 코드 문자열”**이다.
{
"tool": "executeTypescript",
"arguments": {
"entry": "run",
"code": "import { getSheet } from './servers/google-drive/getSheet';\n" +
"export async function run() {\n" +
" const sheet = await getSheet({ sheetId: 'abc123' });\n" +
" const pending = sheet.rows.filter(r => r.Status === 'pending');\n" +
" console.log('Pending count:', pending.length);\n" +
" console.log('Sample rows:', pending.slice(0, 5));\n" +
"}\n"
}
}
여기서 중요한 포인트:
**LLM 입장에선 그냥 “특정 포맷의 문자열을 생성하는 작업”**일 뿐이다.
우리가 “이런 식의 TypeScript 코드를 써라”라고 system + few-shot 예시로 세뇌해둠.
host(client)가 이 tool call을 받으면:
code문자열을 sandbox (Node, Deno, Python 등)로 넘기고실행 후
console.logoutput, return 값 등을 다시 모델에게 돌려준다.
즉 “실시간 코드 생성”이란 말은 거창한 무언가가 아니라:
tool schema가
parameters.code: string이라서LLM이 그 string 안을 TypeScript 코드로 채워넣는 패턴이다.
Anthropic이 권장하는 모드: workspace + skills + 파일트리
하지만 Anthropic 글의 진짜 포인트는 “재사용 가능한 코드/skill을 점점 쌓아라” 쪽이다. Anthropic+1
패턴을 쪼개보면:
고정 코드 / SDK 레이어 (우리가 작성)
./servers/google-drive/getDocument.ts./servers/salesforce/updateRecord.ts이런 것들은 사람이 짜고 git으로 관리.
skills 디렉토리 (persistent, 재사용 가능)
./skills/saveSheetAsCsv.ts./skills/syncLeadsFromSheet.ts처음에는 LLM이 작성해서 저장하거나, 사람이 seed를 넣어줄 수 있음.
task-specific orchestration 코드 (ephemeral or half-persistent)
./scripts/run-once-20251115.ts“이번 대화에서만 필요한 glue 코드”
예시: skill로 승격시키는 패턴
처음에는 LLM이 이런 one-off 코드를 작성한다고 하자:
// scripts/one-off.ts
import { getSheet } from "../servers/google-drive/getSheet";
export async function run() {
const sheet = await getSheet({ sheetId: "abc123" });
const emails = sheet.rows.map(r => r.email).filter(Boolean);
console.log("Emails:", emails);
}
우리가(또는 LLM이) “이거 자주 쓸 듯?”이라고 판단하면
LLM에게 이렇게 시킨다:
"이 코드를
skills/extractEmailsFromSheet.ts라는 재사용 가능한 함수로 리팩토링해서 저장해"
그럼 LLM은
// skills/extractEmailsFromSheet.ts
import { getSheet } from "../servers/google-drive/getSheet";
export async function extractEmailsFromSheet(sheetId: string): Promise<string[]> {
const sheet = await getSheet({ sheetId });
return sheet.rows.map(r => r.email).filter(Boolean);
}
같은 코드를 생성하고,
MCP code-execution 서버의 “파일 쓰기 tool”을 통해 디스크에 저장하게 한다(블로그에서 권장하는 패턴). unwind ai
이후 비슷한 요청이 오면 LLM은:
import { extractEmailsFromSheet } from "../skills/extractEmailsFromSheet";
export async function run() {
const emails = await extractEmailsFromSheet("abc123");
// ...
}
처럼 기존 skill을 import하게 된다.
요약하면:
“항상 모든 걸 새로 짠다” → 가능한 모드지만 권장 X
“자주 쓰는 로직은
skills/에 올려두고 import해서 재사용” → 권장 패턴
2.3 persistence는 어디서 관리하나?
여기서 헷갈리는 부분이:
“sandbox는 ephemeral인데 코드 저장은 어떻게?”
패턴은 다양하지만 대표적인 두 가지:
persistent workspace 디렉토리
MCP code-execution 서버가
$HOME/.mcp-workspaces/<project>/같은 디렉토리를각 프로젝트/유저별로 유지.
sandbox 실행 시 이 디렉토리를 마운트해서
servers/,skills/,workspace/등을 계속 재사용.
remote 저장소 (git / S3 / DB)
skill 파일을 git repo에 push하거나
object storage에 올려놓고, 다음 세션에서 다시 checkout.
Anthropic 공식 글과, 그것을 구현한 예제 MCP 서버들 대부분이
“workspace 폴더 + skills 폴더 유지” 패턴을 기본 전제처럼 쓰고 있다
아키텍처 관점 비교
항목 | Cloudflare Code Mode | Anthropic Code Execution |
|---|---|---|
정체성 | 완제품 플랫폼 + SDK | 아키텍처 패턴 / 레퍼런스 디자인 |
코드 실행 환경 | Cloudflare Workers V8 isolate + Worker Loader API로 동적 sandbox 제공 | 개발자가 직접 고른 환경 (Docker, WASM, Lambda, Workers 등) 위에 구현 |
네트워크 제어 |
| “적절한 sandboxing과 resource limits 필요”라고만 안내. 실제 네트워크 정책은 직접 구현해야 함 |
secrets / key 보호 | binding 안에 숨겨져서 LLM 코드에서 key를 직접 볼 수 없음 | MCP client / executor 설계에 따라 달라짐. 잘못 설계하면 key가 코드 바깥으로 새어 나갈 수 있음 |
책임 범위 | 인프라 보안, 프로세스 격리, V8 sandbox는 Cloudflare가 담당. 사용자는 어떤 binding을 열어줄지와 high-level 정책에 집중 | Anthropic는 “이렇게 설계하면 효율적이다”까지만 제공. 실행 인프라와 sandbox 보안 책임은 전적으로 host/개발자 몫 |
Reference
- Code execution with MCP: Building more efficient agents(Anthrophic Blog)
- Code Mode: the better way to use MCP(Cloudflare Blog)
- Anthropic admits that MCP sucks(Youtube, Theo - t3․gg)
작성자: AIStudyMon
정리시 활용 AI: GPT5.1 Extended Thinking Mode, Gemini 2.5 pro