데이터 엔지니어링 Signature : AI 모델 학습과 추론을 위한 데이터 파이프라인 개발
얼마 안 남았습니다!
지금이 가장 저렴해요.
본 강의는 1월 26일에 신규 런칭한 강의로
사전 구매하신 분들께 얼리버드 혜택을 제공하고 있습니다.
얼리버드
26년 2월 9일 ~ 2월 28일까지
정가 1,380,000원
판매가 358,000원
12개월 할부 적용시
월 29,833원
얼리버드
26년 2월 9일 ~ 2월 28일까지
정가 1,380,000원
판매가 359,000원
12개월 할부 적용시
월 29,917원
정가
1,380,000원
AI 시대, 데이터 엔지니어가 반드시 갖춰야 할










IT 대기업들도 9가지 기술을 모두 다룰 줄 아는
데이터 엔지니어를 찾고 있습니다.














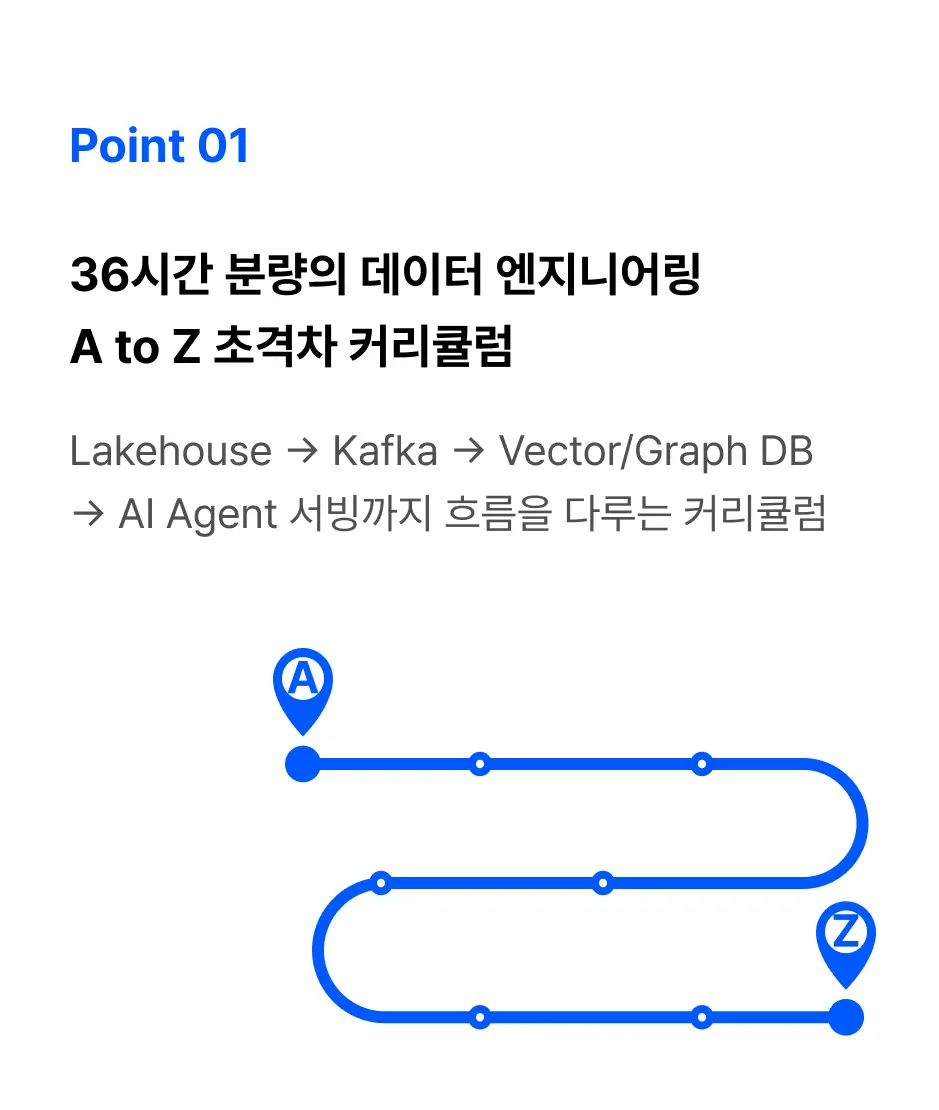









압도적인 학습 로드맵
데이터 파이프인 구축부터 AI 인프라 설계까지
빈틈없이 구성한 커리큘럼
Part 1 ㅣ AI 시대의 데이터 엔지니어링
AI 모델 지원으로의 데이터 엔지니어 역할 변화 AI 모델 성능 보장을 위한 데이터 품질 관리 학습





Part 2 ㅣ AI 모델 학습/추론 중심의 데이터 파이프라인 설계
데이터 파이프라인을 설계하면서 AI 모델의 학습/추론/서빙 관점에서 고려해야 할 구성요소 학습





Part 3 ㅣ Semantic & Context 기반 데이터 설계
데이터를 단순히 값이 아닌 의미와 관계, 문맥으로 이해할 수 있도록 만드는 데이터 설계 방법 학습





Part 4 ㅣ 실시간 및 대규모 데이터 분산 처리 설계
Online 추론을 위한 저지연 아키텍쳐 설계와 지연/중복/재처리 등 핵심 이슈 및 SLO/SLA 등 운영 관점까지 학습





Part 5 ㅣ 실전 RAG 및 Agent 구축
데이터 엔지니어링에 LLM을 접목하여 실제 서비스 가능한 수준의 RAG와 멀티 에이전트 시스템 구축 방법 학습






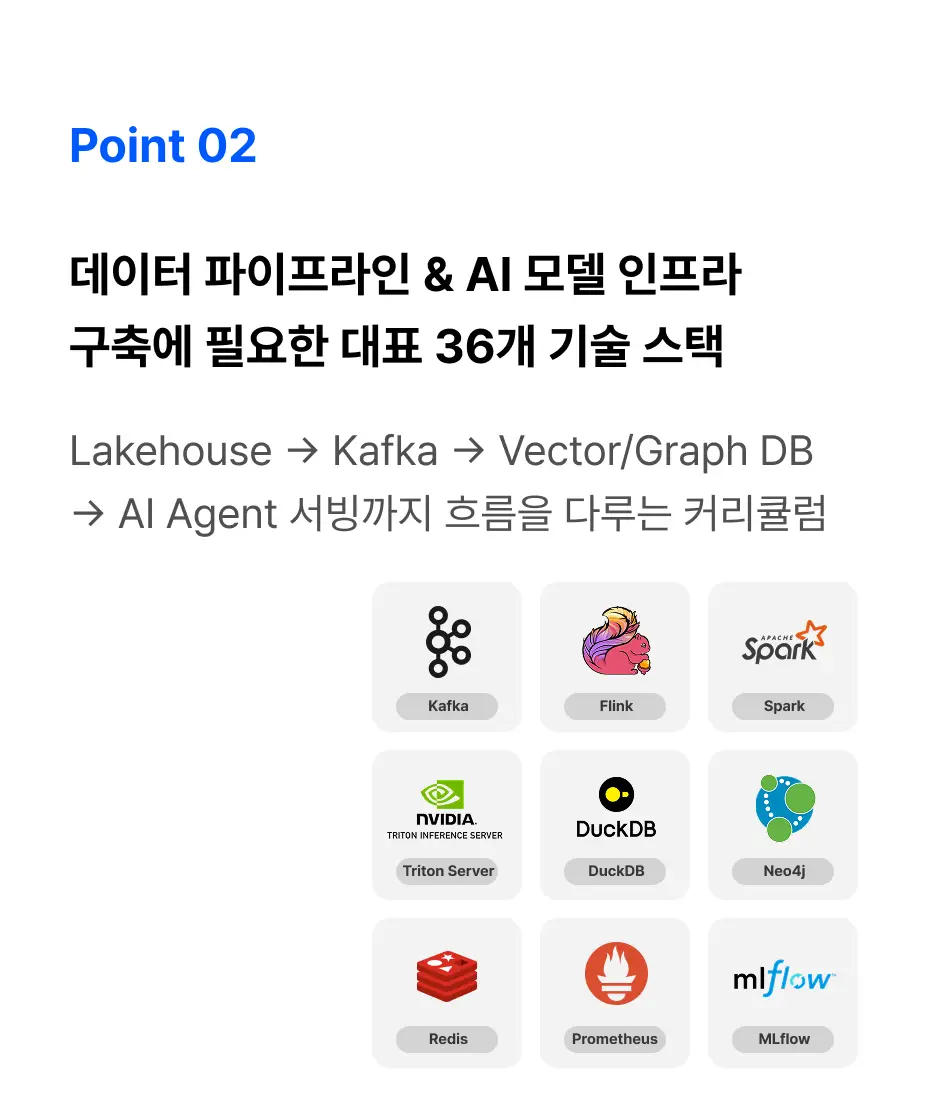
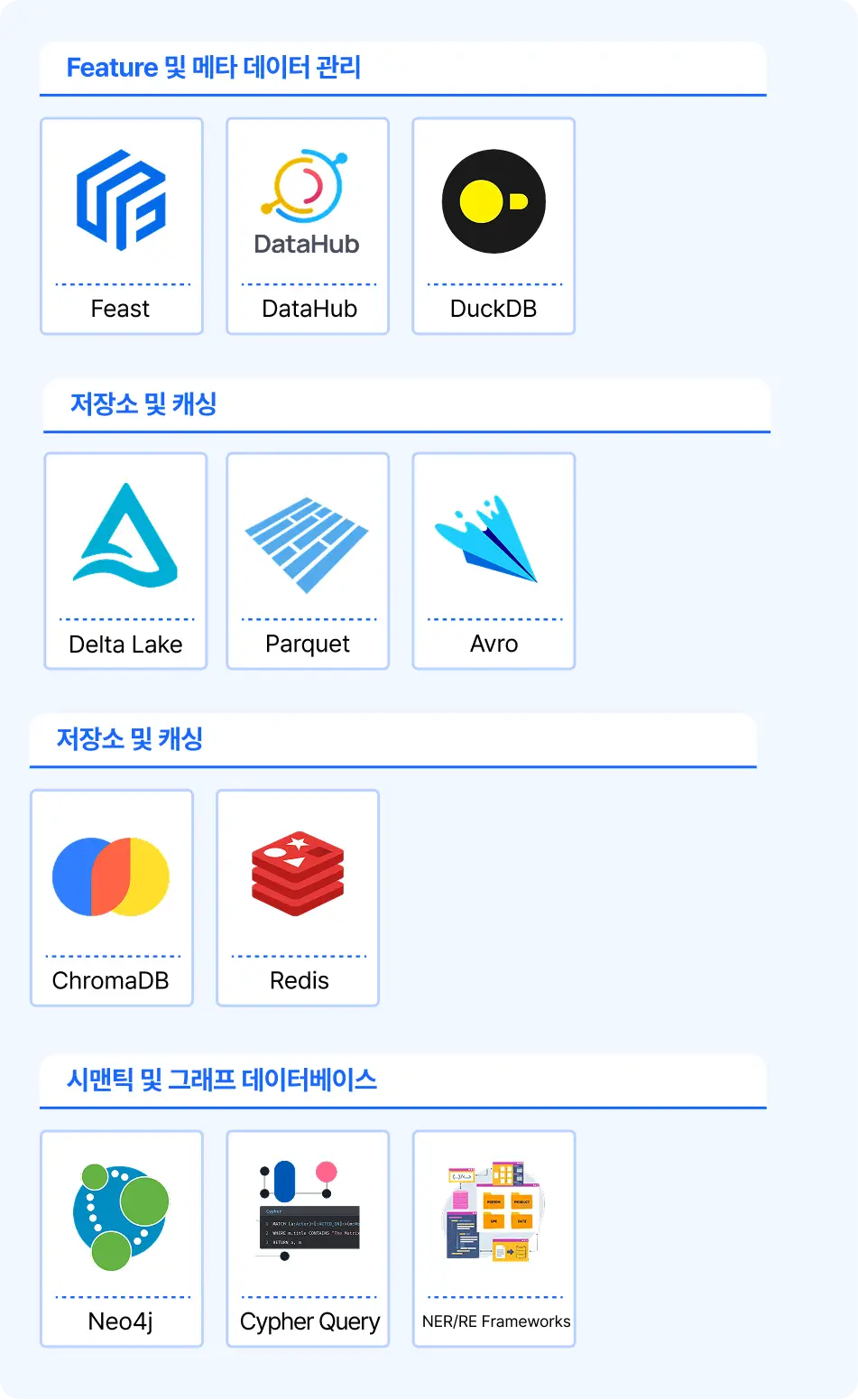
36가지 기술 스택으로
엔터프라이즈급 데이터 파이프라인 구축 전 과정을 다룹니다.



실습 프로젝트
AI 모델의 안정성을 높이기 위한 데이터 파이프라인부터
RAG/Agent로 데이터 검색 품질까지 고려한 24개의 실습 프로젝트
AI, RAG, Agent 등 AX 전환에 목마른 데이터 엔지니어에게
반드시 필요한 실습 프로젝트만 담았습니다.


 학습 포인트
학습 포인트
—————————————————————————————
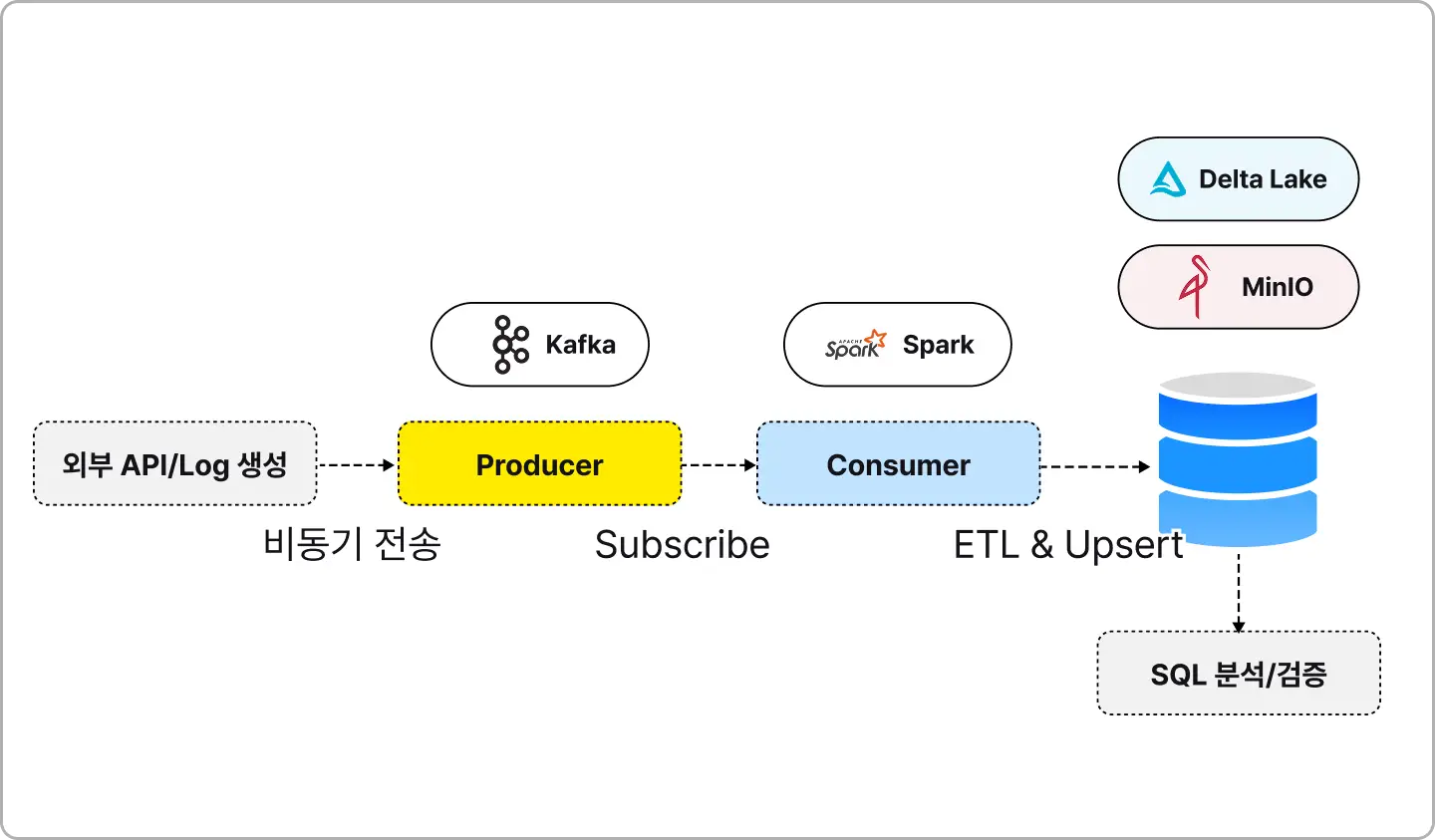
∙ 대용량 데이터를 실시간으로 메시지 큐(Kafka)로 받고, 이를 스파크 스트리밍으로 처리하여 Delta Lake에 무결성 있게 적재하는 파이프라인을 완성합니다.
—————————————————————————————
∙ 실시간 데이터 스트리밍의 기본 원리와 메시지 큐 처리
∙ 정형/비정형 데이터의 실시간 변환 처리
∙ 기존 Data Lake의 한계를 극복하는 ACID 트랜잭션 및 Time Travel 기능 구현

 학습 포인트
학습 포인트
—————————————————————————————
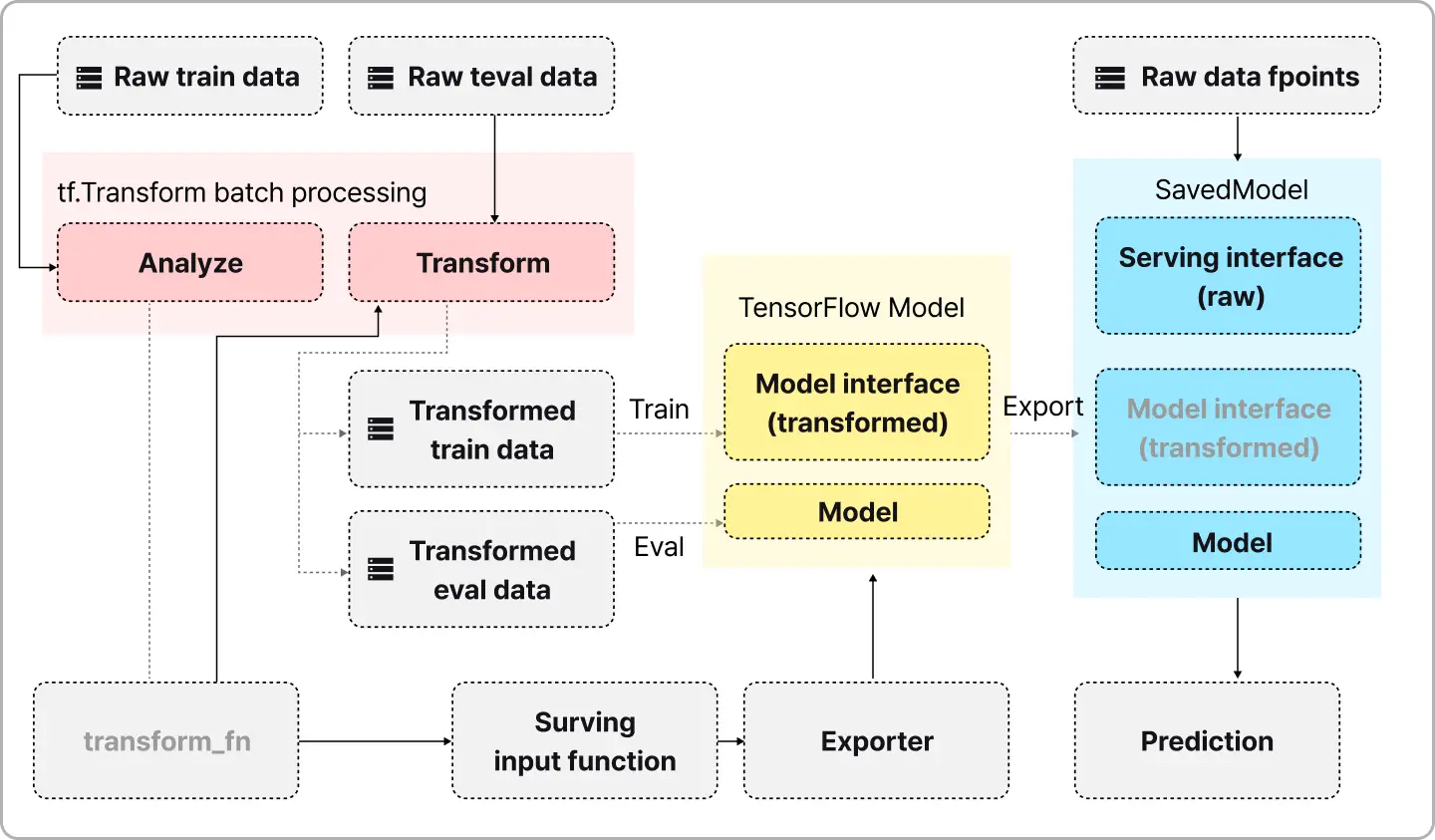
∙ AI 모델의 학습 성능이 과대평가되는 대표 원인(시간 정합성/누수)을 데이터 엔지니어 관점에서 설명하는 방법을 학습합니다.
∙ Skew 원인 패턴을 정리하는 방법을 학습합니다.
—————————————————————————————
∙ 검증 쿼리(Validation Query)로 누수 케이스를 탐지
∙ 라벨 시점 이전 데이터만을 사용하여 전처리를 단일화하고 지연/TTL 정책 정의
∙ 라벨 시점 이후 이벤트가 피쳐에 포함되었는지 탐지 쿼리를 작성

 학습 포인트
학습 포인트
—————————————————————————————
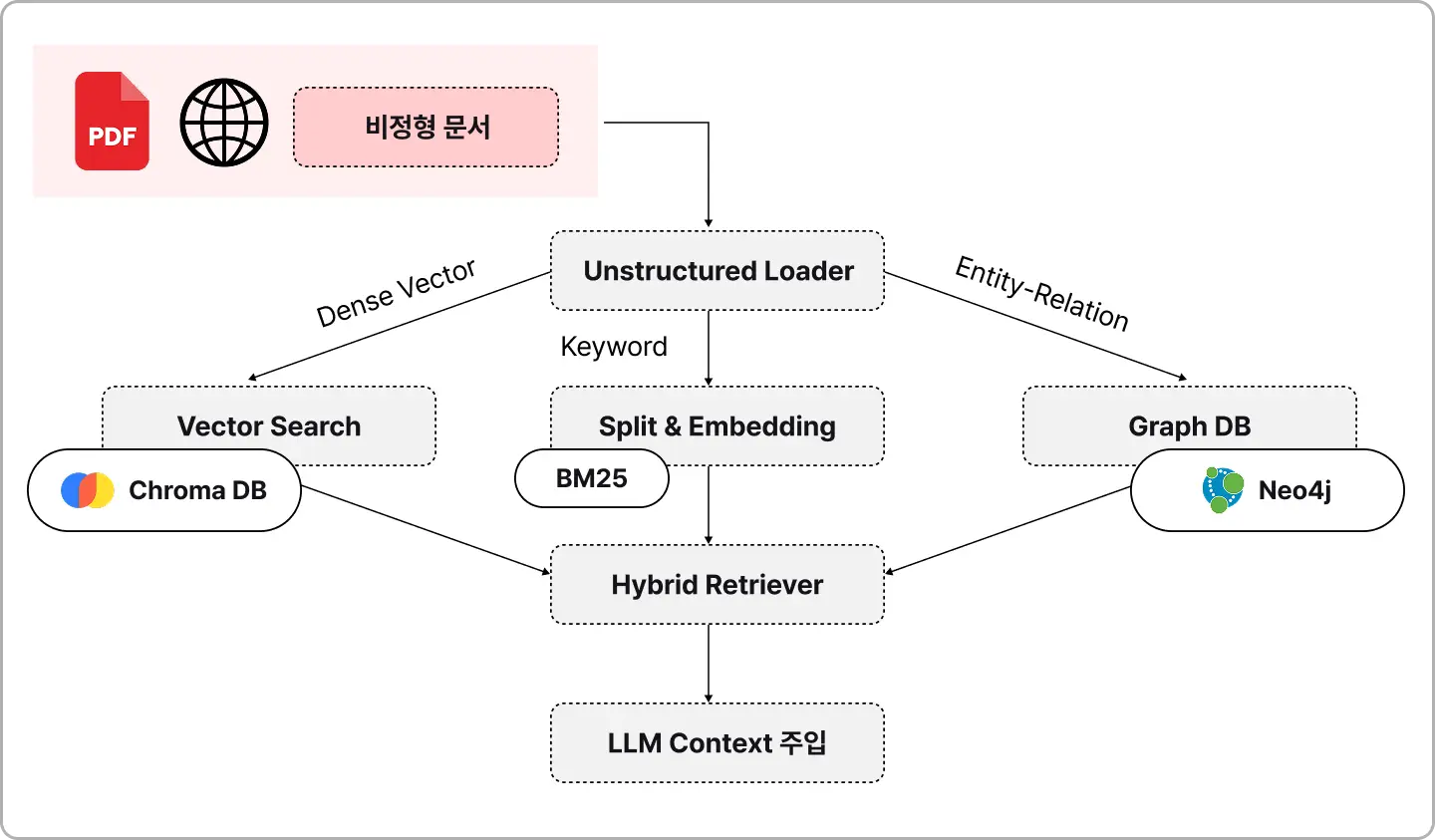
∙ 단순 의미 검색만으로 해결이 어려운 키워드 매칭과 복합 관계 추론 문제를 해결합니다.
∙ 여러 검색 기법을 앙상블하여 최적의 답변 근거를 찾아내는 검색 모듈을 개발합니다.
—————————————————————————————
∙ 문서의 의미(Vector)와 키워드(Sparse)를 동시에 색인
∙ 텍스트 내의 Entity 간 관계를 지식 그래프로 시각화하고 검색에 활용
∙ 여러 검색 결과 중 가장 관련성이 높은 문서를 상위로 재배치

 학습 포인트
학습 포인트
—————————————————————————————
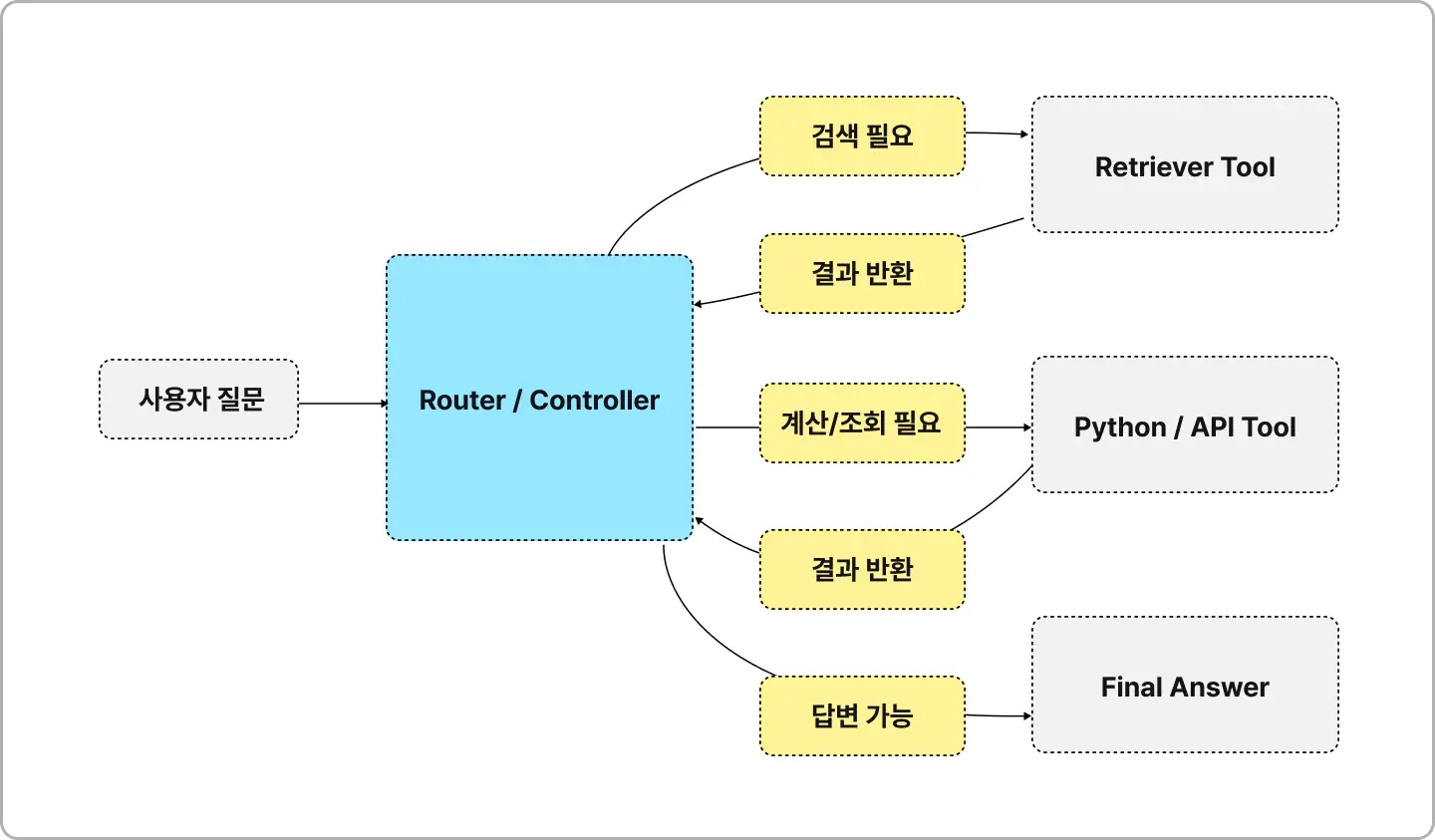
∙ 사용자의 의도를 파악하여 ‘검색’ , ‘계산’, ‘ API 호출’ 등 필요한 행동(Action)을 스스로 결정하고 수행하는 에이전트를 개발합니다.
—————————————————————————————
∙ 대화의 흐름과 상태(State)를 제어하여 복잡한 로직을 순한(Loop) 구조로 설계
∙ LLM에게 함수(Function) 명세를 주입하고 실행 결과를 LLM에게 피드백
∙ 에이전트가 중요한 결정을 내리기 전 사람의 승인을 받는 Human-in-the-loop를 구현

Part 1. AI 시대의 데이터 엔지니어링 (2개)


Part 2. AI 학습/추론 중심 데이터파이프라인 설계 (2개)


Part 3. Semantic & Context 기반 데이터 설계 (2개)


Part 4. 실시간 & 대규모 데이터 분산 처리 설계 (2개)


Part 5. 실전 RAG 및 Agent 구축 (12개)












파이널 프로젝트
AI 서비스 인프라 개발의 핵심을 꿰뚫는
4개의 엔터프라이즈급 파이널 프로젝트
강사님들과 논의하면서 현 시점 기업에서 반드시 필요한
데이터 엔지니어링 대표 4가지 프로젝트를 구성하였습니다.
Final Project 01.
실시간 온라인 추론 파이프라인 개발
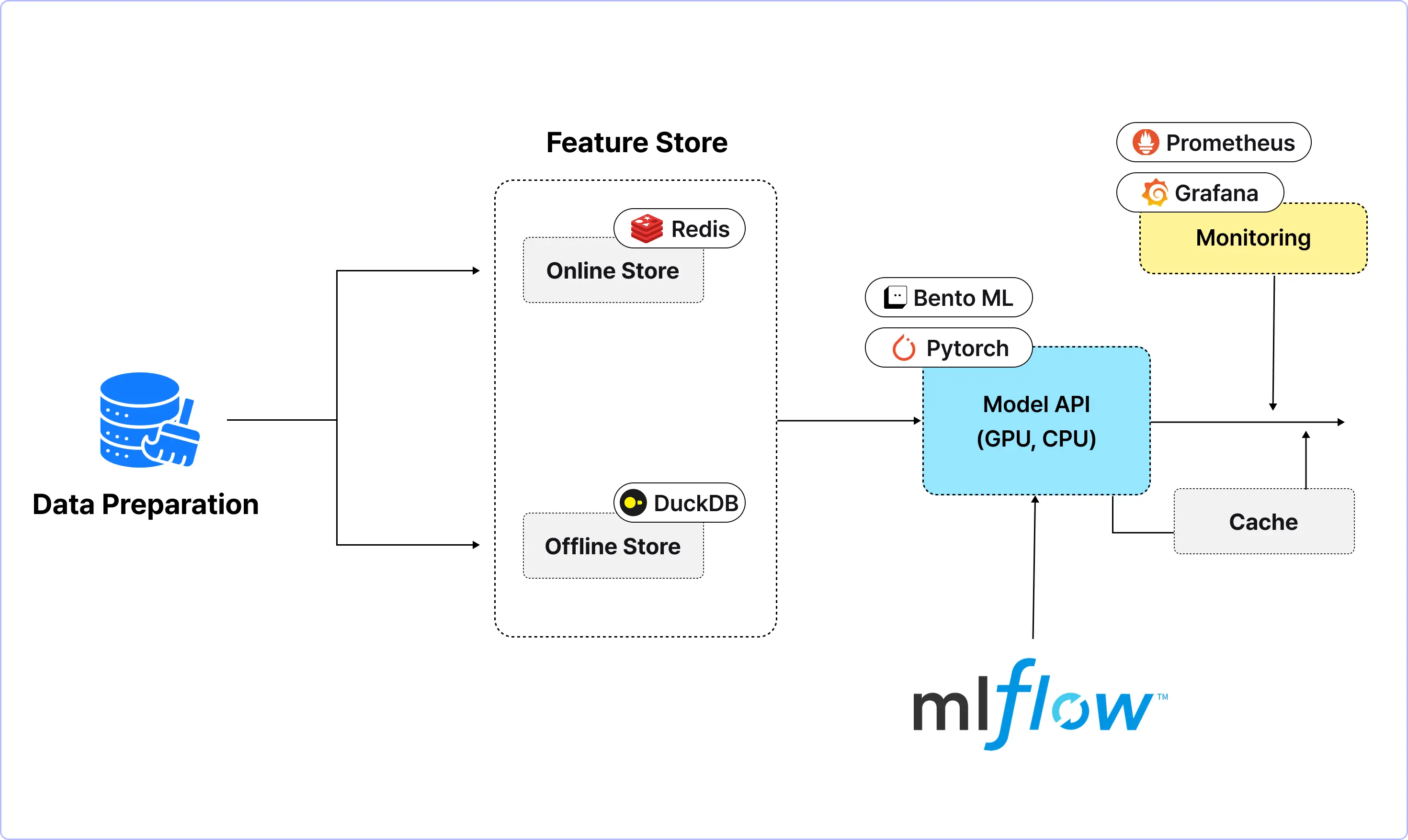
l 프로젝트 실습 흐름




l 프로젝트 실습 내용
프로젝트 목표
· Offline(DuckDB)에서 피처를 생성하고, Online(Redis)으로 버전/TTL 정책과 함께 적재
· Online Serving 패턴(동기 API/이벤트 기반)을 선택하고, 저지연(캐시/폴백) 목표를 설계
· SLO(P99 지연·에러율·처리량)로 대시보드/알람을 만들고, 장애에 대한 대응을 포함
· Offline(DuckDB)에서 피처를 생성하고, Online(Redis)으로 버전/TTL 정책과 함께 적재
· Online Serving 패턴(동기 API/이벤트 기반)을 선택하고, 저지연(캐시/폴백) 목표를 설계
· SLO(P99 지연·에러율·처리량)로 대시보드/알람을 만들고, 장애에 대한 대응을 포함
Why?
· 대부분의 AI 서비스는 저지연, 안정 운영이 핵심
· 실무에서 장애가 나는 이유(지연/누락/폭주/품질 저하)를 설계로 예방하는 방법 학습
· 대부분의 AI 서비스는 저지연, 안정 운영이 핵심
· 실무에서 장애가 나는 이유(지연/누락/폭주/품질 저하)를 설계로 예방하는 방법 학습
주요 Key Point
· 학습/서빙 데이터 불일치 예방: 누수·시간 정합성 검증 쿼리
· 피처 버전/TTL/캐시 설계로 “정확도 vs 지연” 트레이드오프 관리
· 폭주 상황 대비: 레이트리밋/백프레셔/기능 저하(폴백) 설계
· 관측성: 메트릭 기반 SLO 대시보드 + 알람 + 런북
· 학습/서빙 데이터 불일치 예방: 누수·시간 정합성 검증 쿼리
· 피처 버전/TTL/캐시 설계로 “정확도 vs 지연” 트레이드오프 관리
· 폭주 상황 대비: 레이트리밋/백프레셔/기능 저하(폴백) 설계
· 관측성: 메트릭 기반 SLO 대시보드 + 알람 + 런북
Final Project 02.
메타 데이터를 근거로 답변하는 LLM 봇 개발
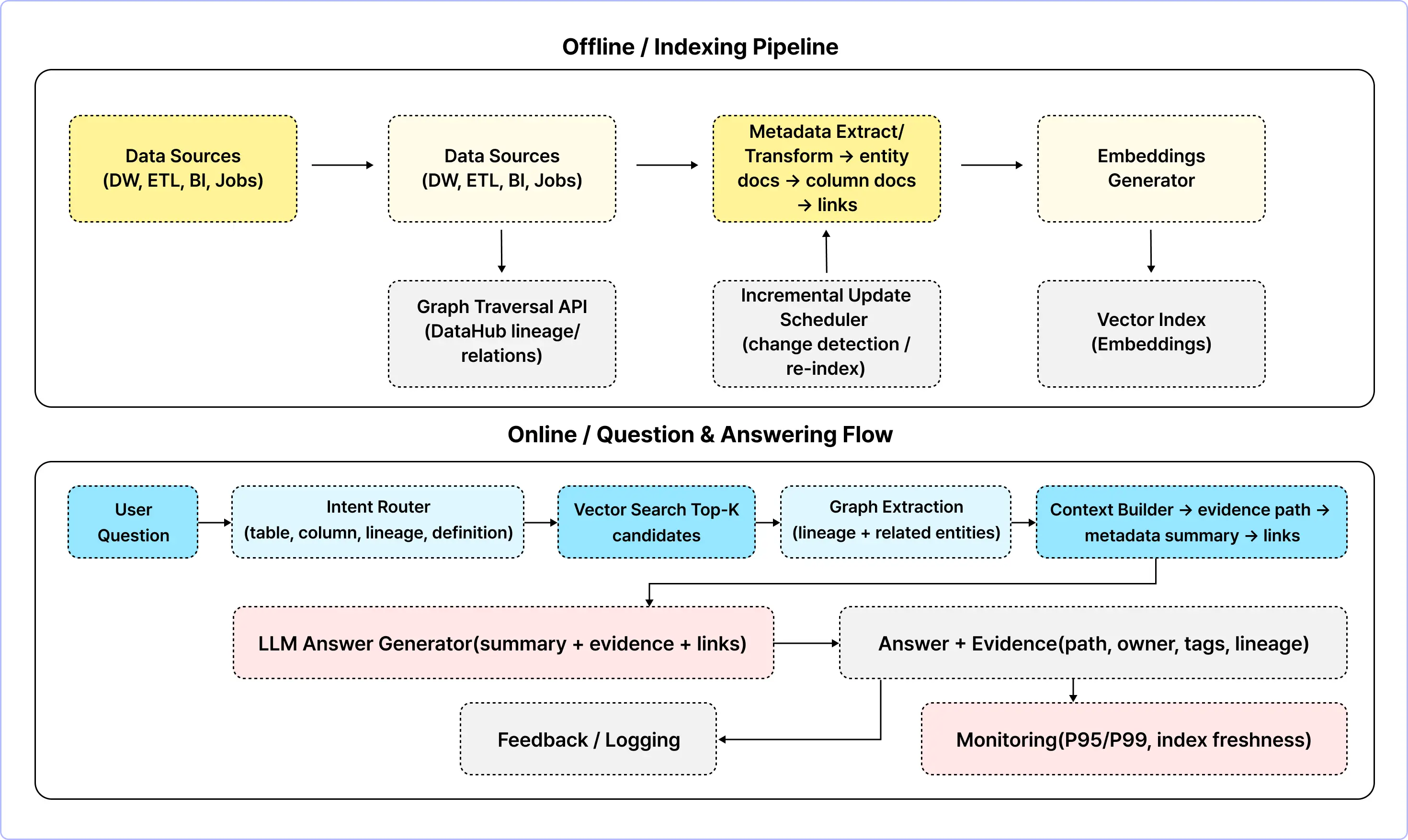
l 프로젝트 실습 흐름




l 프로젝트 실습 내용
프로젝트 목표
· DataHub를 “카탈로그 UI”가 아니라 “질의 가능한 지식 베이스”로 전환
· 텍스트(설명/문서) + 그래프(Lineage) 하이브리드 검색(RAG)을 구현
· 답변은 반드시 근거(경로/링크/메타)를 포함하고, 갱신/평가/관측성을 설계
· DataHub를 “카탈로그 UI”가 아니라 “질의 가능한 지식 베이스”로 전환
· 텍스트(설명/문서) + 그래프(Lineage) 하이브리드 검색(RAG)을 구현
· 답변은 반드시 근거(경로/링크/메타)를 포함하고, 갱신/평가/관측성을 설계
Why?
· 조직이 커질수록 데이터 찾는 시간이 폭증하고, 지식이 사람 머리에만 남아 병목
· 데이터를 찾고 이해하는 비용을 줄여, 분석/개발 리드타임을 단축하는 방법 학습
· 특히 컬럼이 어디 있는지/어떤 데이터가 파생인지/누가 오너인지는 실무에서 매일 발생하는 질문이라 ROI가 큼
· 조직이 커질수록 데이터 찾는 시간이 폭증하고, 지식이 사람 머리에만 남아 병목
· 데이터를 찾고 이해하는 비용을 줄여, 분석/개발 리드타임을 단축하는 방법 학습
· 특히 컬럼이 어디 있는지/어떤 데이터가 파생인지/누가 오너인지는 실무에서 매일 발생하는 질문이라 ROI가 큼
주요 Key Point
· 엔티티별 문서 스키마 설계(테이블/컬럼/잡/대시보드)
· 증분 업데이트(변경분만 재색인)로 운영 비용 절감
· Graph + RAG로 “왜 이 테이블/컬럼인지” 근거 강화
· 환각 방지: 모르면 모른다고, 후보 3개 비교 제시
· 엔티티별 문서 스키마 설계(테이블/컬럼/잡/대시보드)
· 증분 업데이트(변경분만 재색인)로 운영 비용 절감
· Graph + RAG로 “왜 이 테이블/컬럼인지” 근거 강화
· 환각 방지: 모르면 모른다고, 후보 3개 비교 제시
Final Project 03.
복합적인 논리 관계를 풀어내는 RAG 솔루션 개발
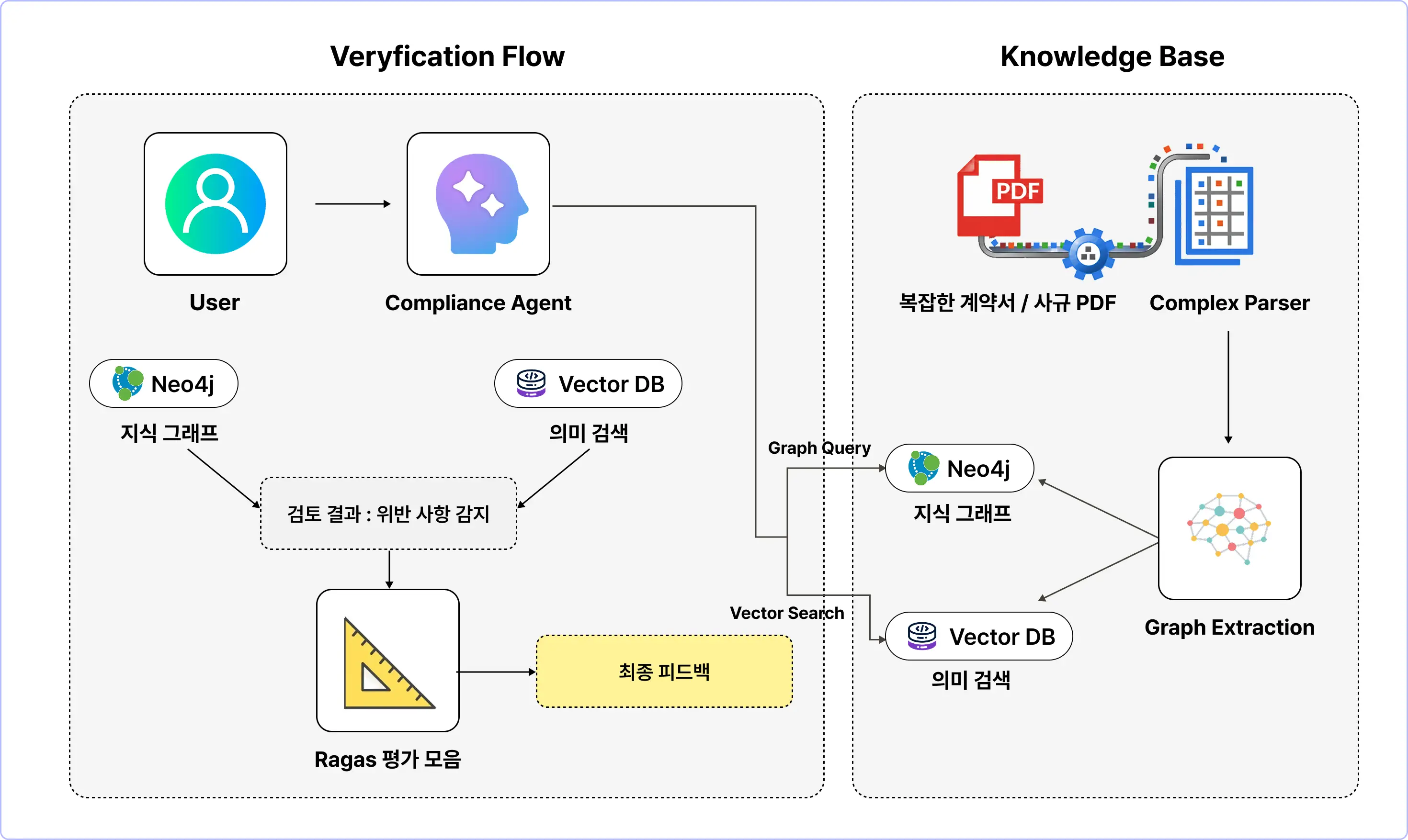
l 프로젝트 실습 흐름




l 프로젝트 실습 내용
프로젝트 목표
· 수백 페이지의 사규나 계약서 내에서, 서로 충돌하는 조항이나 특정 엔티티(갑/을 관계)의 의무 조항을 정확히 찾아내고 검토해주는 엔터프라이즈급 RAG 솔루션 구축
· 수백 페이지의 사규나 계약서 내에서, 서로 충돌하는 조항이나 특정 엔티티(갑/을 관계)의 의무 조항을 정확히 찾아내고 검토해주는 엔터프라이즈급 RAG 솔루션 구축
Why?
· 엔터프라이즈 AI의 최대 장벽인 할루시네이션 문제를 해결하는 방법 학습
· 문서 내의 ‘관계’를 이해하는 AI를 구축하는 방법 학습
· 엔터프라이즈 AI의 최대 장벽인 할루시네이션 문제를 해결하는 방법 학습
· 문서 내의 ‘관계’를 이해하는 AI를 구축하는 방법 학습
프로젝트 목표
· Graph RAG (Advanced): "제3조 2항이 제15조와 충돌하는가?"와 같은 복합적인 논리 관계를 풀기 위해 지식 그래프(Neo4j) 필수 활용
· Eval-Driven Development: 생성된 검토 결과가 정확한지 Ragas를 통해 신뢰성(Faithfulness)을 정량적으로 평가 및 개선
· Hallucination Control: 잘못된 법률 조언을 하지 않도록 Guardrails(가드레일) 적용
· Graph RAG (Advanced): "제3조 2항이 제15조와 충돌하는가?"와 같은 복합적인 논리 관계를 풀기 위해 지식 그래프(Neo4j) 필수 활용
· Eval-Driven Development: 생성된 검토 결과가 정확한지 Ragas를 통해 신뢰성(Faithfulness)을 정량적으로 평가 및 개선
· Hallucination Control: 잘못된 법률 조언을 하지 않도록 Guardrails(가드레일) 적용
Final Project 04.
정형 + 비정형 데이터를 결합하여 AI Agent 개발
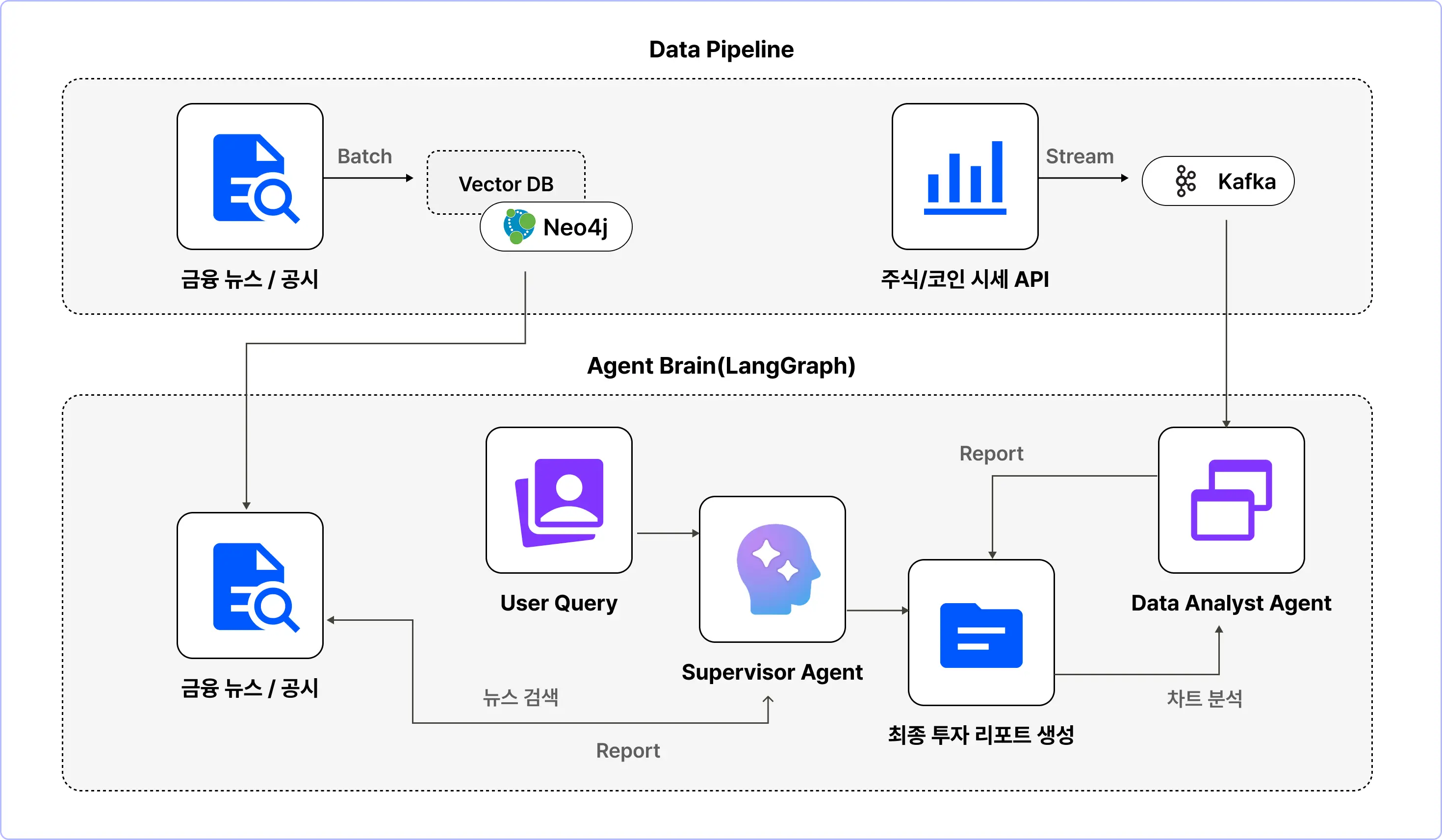
l 프로젝트 실습 흐름




l 프로젝트 실습 내용
프로젝트 목표
· 실시간으로 변하는 정형 데이터(주가)와 비정형 데이터(뉴스)를 결합하여, 사용자가 "현재 삼성전자 상황 어때?"라고 물으면 차트 분석과 최신 뉴스를 종합해 인사이트를 제공하는 AI 에이전트 개발
· 실시간으로 변하는 정형 데이터(주가)와 비정형 데이터(뉴스)를 결합하여, 사용자가 "현재 삼성전자 상황 어때?"라고 물으면 차트 분석과 최신 뉴스를 종합해 인사이트를 제공하는 AI 에이전트 개발
Why?
· 현업에서 현재 가장 수요가 많은 ‘데이터 분석 자동화’ 구현
· LLM이 DB에 접근하여 데이터를 쿼리하고 시각화까지 수행하는 방법 학습
· 현업에서 현재 가장 수요가 많은 ‘데이터 분석 자동화’ 구현
· LLM이 DB에 접근하여 데이터를 쿼리하고 시각화까지 수행하는 방법 학습
프로젝트 목표
· Hybrid Data Source: 실시간 시계열 데이터(Kafka/Spark)와 정적 텍스트 데이터(RAG)의 결합
· Multi-Agent System: '차트 분석가' 에이전트와 '뉴스 리서처' 에이전트가 협업하는 구조 설계
· Code Interpreter: 에이전트가 직접 Python 코드를 생성해 그래프를 그리고 통계치를 계산
· Hybrid Data Source: 실시간 시계열 데이터(Kafka/Spark)와 정적 텍스트 데이터(RAG)의 결합
· Multi-Agent System: '차트 분석가' 에이전트와 '뉴스 리서처' 에이전트가 협업하는 구조 설계
· Code Interpreter: 에이전트가 직접 Python 코드를 생성해 그래프를 그리고 통계치를 계산


데이터 엔지니어링의 핵심 기술부터 최신 트렌드까지
완벽하게 잡아줄 9가지 부가 학습 자료 제공









수강생 한정 강의 관련 오픈 커뮤니티 질의응답까지!
강사님과 무한 질의응답이 가능합니다.
1) 실습 중 에러가 나면? 질의응답 채널을 통해 빠른 해결!
2) 강의를 듣다가 이해되지 않는 부분이 생기면 바로 질문하세요!
* 강사님께서 직접 질문에 답변해주시는 기간은 2026년 3월 6일 ~ 2029년 1월 25일까지 운영되며 그 이후에는 패스트캠퍼스 AI 기능을 활용하여 질문에 답변 받으실 수 있습니다.
* 강사님이 현업 중 답변 하시기에 답변까지 영업일 기준 7일 내외 시간이 소요될 수 있습니다.
* 강의와 무관한 질문에 대해서는 답변이 필수로 제공되지 않습니다.
강사님과 무한 질의응답이 가능합니다.
1) 실습 중 에러가 나면? 질의응답 채널을 통해 빠른 해결!
2) 강의를 듣다가 이해되지 않는 부분이 생기면 바로 질문하세요!
* 강사님께서 직접 질문에 답변해주시는 기간은 2026년 3월 6일 ~ 2029년 1월 25일까지 운영되며 그 이후에는 패스트캠퍼스 AI 기능을 활용하여 질문에 답변 받으실 수 있습니다.
* 강사님이 현업 중 답변 하시기에 답변까지 영업일 기준 7일 내외 시간이 소요될 수 있습니다.
* 강의와 무관한 질문에 대해서는 답변이 필수로 제공되지 않습니다.

한 번의 구매로 평생 소장!
한 번 결제로 평생 동안 무제한 반복 학습이 가능합니다.
바쁜 일정에 걱정할 필요 업싱, 원하는 때에 학습하고 필요할 때마다 복습하세요.
한 번 결제로 평생 동안 무제한 반복 학습이 가능합니다.
바쁜 일정에 걱정할 필요 업싱, 원하는 때에 학습하고 필요할 때마다 복습하세요.

강사소개
급변하는 데이터 엔지니어링 기술의 핵심만 뽑아
커리큘럼을 준비해 주신 두 분의 강사님들을 소개합니다.

LEO 강사님
✦ Part 1,5,6
현) 국내 유명 대기업 N사 데이터 엔지니어
전) SI 기업 데이터 분석가
현) 국내 유명 대기업 N사 데이터 엔지니어
전) SI 기업 데이터 분석가
안녕하세요, 여러분.
저는 현재 판교 소재 대기업 데이터 부서에서 데이터 엔지니어로 근무하고 있습니다.
현재 데이터엔지니어링의 핵심은 “데이터가 어떻게 파이프라인을 타고 들어와서,
어떻게 벡터화되어 저장되고, 결국 AI 에이전트가 이를 어떻게 활용하는지” 흐름을 이해하는 것입니다.
많은 분들이 여전히 데이터 엔지니어링과 AI 모델링을 별개의 영역으로 나누어 학습하며
"데이터는 준비됐는데 AI 성능은 왜 안 나오지?"
"RAG를 만들었는데 왜 엉뚱한 답만 할까?" 와 같은 막막한 벽에 부딪히곤 합니다. 저는 여러분이 이 두 영역을 관통하는 대체 불가능한 'AI 데이터 아키텍트'로 성장할 수 있도록 돕고자 합니다. 이 강의를 수강하시면, 단순히 기능 구현을 넘어 '서비스가 가능한 수준'의 안목과 기술력을 얻게 됩니다. 교과서적인 이론보다는
"왜 현업에서는 단순 벡터 검색 대신 Hybrid Search와 Graph-RAG를 써야 하지?" "복잡한 에이전트 시스템을 통제하기 위해 LangGraph가 왜 필요하지?" 와 같이 실무에서 겪게 될 구체적인 문제들에 대한 명쾌한 해답과 해결책을 얻어가실 수 있습니다.
이 강의를 듣고 나시면 여러분은 파편화된 도구(Kafka, Spark, LangChain 등)의 사용법을 아는 수준을 넘어, 원천 데이터의 수집부터 최신 AI 에이전트 서비스의 배포와 평가까지, 전체 파이프라인을 스스로 설계하고 구축할 수 있는 '올라운더(All-rounder) 엔지니어로 확실하게 달라져 있을 것입니다.
Habi 강사님
✦ Part 2,3,4,6
현) 디지털 콘텐츠 구독 서비스 관련 기업 Data Engineer
전) 유니콘 커머스 스타트업 Data Engineer & MLOps Engineer
현) 디지털 콘텐츠 구독 서비스 관련 기업 Data Engineer
전) 유니콘 커머스 스타트업 Data Engineer & MLOps Engineer
안녕하세요, 여러분.
저는 현재 디지털 콘텐츠 구독 서비스 기업에서 Data Engineer로 근무하고 있습니다.
이 강의의 실습은 단순히 특정 도구의 명령어와 사용법을 외우는 ‘튜토리얼’이 아닙니다.
AI/LLM 시스템을 구축할 때 데이터 엔지니어가 필연적으로 마주치는 문제들을 “설계와 구현”으로 돌파하는 경험을 드리는 데 모든 초점을 맞췄습니다.
"데이터 형태는 문제가 없는데 왜 모델 성능은 떨어질까요?"
학습 데이터와 서빙 데이터의 불일치(Training-Serving Skew)는 현업에서 가장 빈번하고 치명적인 실패 지점입니다. 단순히 파이프라인을 연결하는 것을 넘어, 데이터 누수(Leakage)와 시간 정합성 문제를 검증 쿼리로 탐지하고, 신뢰할 수 있는 데이터 흐름을 설계하는 법을 학습합니다.
"Feature Store 제품만 도입하면 해결될까요?"
도구를 도입하는 것보다 중요한 건 원리입니다. 오프라인에서 만든 피처를 온라인 저장소로 옮길 때의 신선도(TTL), 버전 관리, 그리고 정합성 문제를 직접 다뤄봅니다. 이를 통해 단순한 '사용자'가 아니라 Offline/Online 분리의 의미를 꿰뚫는 엔지니어로 거듭납니다.
"트래픽이 튀면 시스템이 멈추는데 어떡하죠?"
Kafka나 Flink 같은 도구 자체가 정답은 아닙니다. 실무에서는 재처리 안전성(Idempotency), 백프레셔(Backpressure), 그리고 GPU 병목 같은 운영 이슈가 반드시 터집니다. 우리는 장애 상황에서도 서비스가 셧다운 되지 않도록 하는 SLO 관점의 운영 체크리스트와 최적화 패턴을 체득합니다.
이 강의를 듣고 나시면 여러분은 막연했던 LLM/RAG 시스템의 문맥 관리부터 실시간 분산 처리의 안정성 확보까지 AI 시대 데이터 엔지니어로서 무엇을 설계하고 어디까지 책임져야 하는지 또렷한 시야를 가진 '단단한 엔지니어'로 성장해 계실 겁니다.
Q&A
Question.1
어떤 분들이
수강하시면 좋을까요?
어떤 분들이
수강하시면 좋을까요?
· 2026년 데이터 엔지니어로 취업을 원하는 학/석사생
· 간단한 형태의 데이터 파이프라인 구축 경험이 있는 주니어 데이터 엔지니어
· AI와 ML 기반의 서비스 개발이 필요한 데이터 엔지니어
· 간단한 형태의 데이터 파이프라인 구축 경험이 있는 주니어 데이터 엔지니어
· AI와 ML 기반의 서비스 개발이 필요한 데이터 엔지니어
Question.2
강의를 수강하고 나서
어떤 지식을 학습할 수 있나요?
강의를 수강하고 나서
어떤 지식을 학습할 수 있나요?
AI 모델이 신뢰할 수 있는 데이터의 흐름을 직접 설계하고 검증
· 학습과 서빙에서 데이터가 불일치해서 모델 성능이 무너지는 대표적인 상황을 기준으로, 데이터 누수나 시간 정합성 문제를 검증 쿼리로 탐지하는 실습을 합니다. 이를 통해 “왜 데이터는 있는데 모델 성능이 안 나오는지”를 데이터 엔지니어 관점에서 진단할 수 있게 됩니다.
엔터프라이즈급 Modern Data Stack 도입하여 데이터 파이프라인 구축
· 저장소: 파일 시스템이 아닌, ACID 트랜잭션과 Time Travel을 지원하는
Delta Lake 기반의 레이크하우스 아키텍처를 구축합니다.
· 파이프라인: 배치를 넘어, CDC(Change Data Capture)와 Apache Kafka를 활용한 이벤트 기반 아키텍처(EDA)를 다룹니다.
· RAG: 벡터 검색을 넘어, Neo4j를 활용한 Graph-RAG와 Hybrid Search(BM25+Dense) 등 현업에서 검색 품질을 높이기 위해 사활을 거는
기술들을 깊이 있게 다룹니다.
Agentic Workflow 반영
· LangGraph 도입: 순환형 그래프 구조를 통해 상태(State)를 관리하고, 검색 봇/분석 봇 등 여러 에이전트가 협업하는 Multi-Agent System을 직접 구현합니다.
· 평가(Evaluation) 포함: 모델을 만드는 데서 끝나지 않고, Ragas 프레임워크를 통해 내 RAG 시스템의 신뢰성과 정확도를 정량적으로 채점하고 개선하는 LLM Ops/평가 영역까지 다룹니다. 이는 시중의 입문 강의에서는 찾아보기 힘든 고급 주제입니다.
· 학습과 서빙에서 데이터가 불일치해서 모델 성능이 무너지는 대표적인 상황을 기준으로, 데이터 누수나 시간 정합성 문제를 검증 쿼리로 탐지하는 실습을 합니다. 이를 통해 “왜 데이터는 있는데 모델 성능이 안 나오는지”를 데이터 엔지니어 관점에서 진단할 수 있게 됩니다.
엔터프라이즈급 Modern Data Stack 도입하여 데이터 파이프라인 구축
· 저장소: 파일 시스템이 아닌, ACID 트랜잭션과 Time Travel을 지원하는
Delta Lake 기반의 레이크하우스 아키텍처를 구축합니다.
· 파이프라인: 배치를 넘어, CDC(Change Data Capture)와 Apache Kafka를 활용한 이벤트 기반 아키텍처(EDA)를 다룹니다.
· RAG: 벡터 검색을 넘어, Neo4j를 활용한 Graph-RAG와 Hybrid Search(BM25+Dense) 등 현업에서 검색 품질을 높이기 위해 사활을 거는
기술들을 깊이 있게 다룹니다.
Agentic Workflow 반영
· LangGraph 도입: 순환형 그래프 구조를 통해 상태(State)를 관리하고, 검색 봇/분석 봇 등 여러 에이전트가 협업하는 Multi-Agent System을 직접 구현합니다.
· 평가(Evaluation) 포함: 모델을 만드는 데서 끝나지 않고, Ragas 프레임워크를 통해 내 RAG 시스템의 신뢰성과 정확도를 정량적으로 채점하고 개선하는 LLM Ops/평가 영역까지 다룹니다. 이는 시중의 입문 강의에서는 찾아보기 힘든 고급 주제입니다.
Question.3
필요한 선수지식과
최소 개발 환경
필요한 선수지식과
최소 개발 환경
· Python 프로그래밍(Pandas 활용 능력)
· Docker 및 클라우드 환경에 대한 이해(만약 없으시더라도 강의에서 다룰 예정이라 무방합니다.)
· 최소 사양 :
- CPU : Intel Core i3, AMD Ryzen 3, Apple M1
- RAM : 8GB
- GPU : 필요 없음(내장 그래픽 가능)
- 저장공간 : SSD 128GB 이상
- OS : Windows 10/11, macOS, Linux 무관
· 권장 사양 :
- CPU : Intel Core i5, Apple M1 이상
- RAM : 16GB
- GPU : 필요 없음
- 저장공간 : SSD 256GB 이상
- OS : Windows / Mac 모두 쾌적
* 프로그램은 별도로 제공하지 않습니다.
* 툴이나 프로그램 사용 환경과 버전 업데이트에 따라, 강의 내 화면(UI) 구성이나 기능이 실제 수강 시점과 다를 수 있습니다.
* 본 강의는 촬영 시점의 버전을 기준으로 학습 흐름과 개념 전달에 중점을 두었으며, 이후 버전 업데이트에 따른 내용 수정이나 추가는 제공되지 않습니다.
· Docker 및 클라우드 환경에 대한 이해(만약 없으시더라도 강의에서 다룰 예정이라 무방합니다.)
· 최소 사양 :
- CPU : Intel Core i3, AMD Ryzen 3, Apple M1
- RAM : 8GB
- GPU : 필요 없음(내장 그래픽 가능)
- 저장공간 : SSD 128GB 이상
- OS : Windows 10/11, macOS, Linux 무관
· 권장 사양 :
- CPU : Intel Core i5, Apple M1 이상
- RAM : 16GB
- GPU : 필요 없음
- 저장공간 : SSD 256GB 이상
- OS : Windows / Mac 모두 쾌적
* 프로그램은 별도로 제공하지 않습니다.
* 툴이나 프로그램 사용 환경과 버전 업데이트에 따라, 강의 내 화면(UI) 구성이나 기능이 실제 수강 시점과 다를 수 있습니다.
* 본 강의는 촬영 시점의 버전을 기준으로 학습 흐름과 개념 전달에 중점을 두었으며, 이후 버전 업데이트에 따른 내용 수정이나 추가는 제공되지 않습니다.
Question.4
수업에서 배운 내용으로 현업에서
어떻게 활용할 수 있을까요?
수업에서 배운 내용으로 현업에서
어떻게 활용할 수 있을까요?
· 수강생들은 배운 내용을 바탕으로 엔터프라이즈급 AI 데이터 플랫폼 구축부터 LLM 서비스 개발까지, 전 과정에 즉시 투입 가능한 역량을 얻게 됩니다. 최신 아키텍처인 Lakehouse와 CDC를 활용해 파편화된 데이터를 통합하고, Kafka 기반의 실시간 파이프라인을 구축하여 AI 모델에 가장 신선한 데이터를 공급하는 데이터 백본(Backbone)을 설계할 수 있습니다.
· RAG(검색 증강 생성)를 도입할 때 가장 큰 난관인 '답변의 정확도 저하'와 '환각(Hallucination)' 문제를 해결할 수 있는 강력한 무기를 갖게 됩니다. 강의에서 다루는 Hybrid Search(BM25+Dense)와 Reranking, 그리고 문맥의 관계성을 파악하는 Graph-RAG(Neo4j) 기술을 통해, 실무에서 요구하는 높은 신뢰성의 검색 시스템을 구현할 수 있습니다.
· 단순 챗봇 개발을 넘어 복잡한 비즈니스 로직을 처리해야 할 때 LangGraph를 활용한 Multi-Agent 시스템 설계 능력이 빛을 발하게 됩니다. 여러 AI 에이전트의 상태(State)를 제어하고 협업시키는 오케스트레이션 기술과 Ragas를 이용한 정량적 평가 프로세스를 적용함으로써, 수강생들은 '데모 수준'이 아닌 '실제 상용 서비스 수준'의 견고한 AI 애플리케이션을 완성할 수 있습니다.
· RAG(검색 증강 생성)를 도입할 때 가장 큰 난관인 '답변의 정확도 저하'와 '환각(Hallucination)' 문제를 해결할 수 있는 강력한 무기를 갖게 됩니다. 강의에서 다루는 Hybrid Search(BM25+Dense)와 Reranking, 그리고 문맥의 관계성을 파악하는 Graph-RAG(Neo4j) 기술을 통해, 실무에서 요구하는 높은 신뢰성의 검색 시스템을 구현할 수 있습니다.
· 단순 챗봇 개발을 넘어 복잡한 비즈니스 로직을 처리해야 할 때 LangGraph를 활용한 Multi-Agent 시스템 설계 능력이 빛을 발하게 됩니다. 여러 AI 에이전트의 상태(State)를 제어하고 협업시키는 오케스트레이션 기술과 Ragas를 이용한 정량적 평가 프로세스를 적용함으로써, 수강생들은 '데모 수준'이 아닌 '실제 상용 서비스 수준'의 견고한 AI 애플리케이션을 완성할 수 있습니다.
데이터 엔지니어링 Signature : AI 모델 학습과 추론을 위한 데이터 파이프라인 개발
커리큘럼
파트 7개클립 152개
- Part 1. AI 시대의 데이터 엔지니어링37 클립
- Part 2. AI 학습/추론 중심 데이터 파이프라인 설계18 클립
- Part 3. 시멘틱 & 컨텍스트 기반 데이터 설계21 클립
- Part 4. 실시간 & 대규모 데이터 분산 처리 설계25 클립
- Part 5. 실전 RAG 및 에이전트 구축41 클립
- Final Project 1: 실시간 온라인 추론 파이프라인5 클립
- Final Project 2: 지능형 데이터 디스커버리 봇5 클립
영상공개 일정
해당 강의는 총 5회에 걸쳐 공개됩니다.
1차2026.03.06(금)
2차2026.03.27(금)
3차2026.04.24(금)
4차2026.05.22(금)
최종2026.06.05(금)
커뮤니티
수강생들은 어떤 질문을 하고, 어떤 이야기를 나누고 있을까요?
패스트캠퍼스 커뮤니티에서 다른 수강생들과 함께 궁금했던 주제에 대해 다양한 관점과 답변을 찾아보세요.
커뮤니티 바로가기학습 규정 및 환불 규정
학습 규정
* 본 상품은 동영상 형태의 강의를 수강하는 상품입니다.
* 상황에 따라 사전 공지 없이 할인이 조기 마감되거나 연장될 수 있습니다.
* 수강 신청 및 결제를 완료하시면, 마이페이지를 통해 바로 수강이 가능합니다.
총 학습기간:
정상 수강기간(유료 수강기간) 최초 30일, 무료 수강 기간은 31일 일차 이후로 무제한이며, 유료 수강기간과 무료 수강기간 모두 동일하게 시청 가능합니다.
본 패키지는 약 36시간 분량으로, 일 1시간 내외의 학습 시간을 통해 정상 수강 기간(=유료 수강 기간) 내에 모두 수강이 가능합니다.
수강시작일: 수강 시작일은 결제일로부터 기간이 산정되며, 결제를 완료하시면 마이페이지를 통해 바로 수강이 가능합니다. (사전 예약 강의는 1차 강의 오픈일)
패스트캠퍼스의 사정으로 수강시작이 늦어진 경우에는 해당 일정 만큼 수강 시작일이 연기됩니다.
일부 강의는 아직 모든 영상이 공개되지 않았습니다. 각 상세페이지 하단에 공개 일정이 안내되어 있습니다.
주의 사항
상황에 따라 사전 공지 없이 할인이 조기 마감되거나 연장될 수 있습니다.
천재지변, 폐업 등 서비스 중단이 불가피한 상황에는 서비스가 종료될 수 있습니다.
본 상품은 기수강생 할인, VIP CLUB 제도 (구 프리미엄 멤버십), 기타 할인 이벤트 적용이 불가할 수 있습니다.
커리큘럼은 제작 과정에서 일부 추가, 삭제 및 변경될 수 있습니다.
쿠폰 적용이나 프로모션 등으로 인해 5만원 이하의 금액으로 강의를 결제할 경우, 할부가 적용되지 않습니다.
환불 규정
환불금액은 정가가 아닌 실제 결제금액을 기준으로 계산됩니다.
쿠폰을 사용하여 강의를 결제하신 후 취소/환불 시 쿠폰은 복구되지 않습니다.
수강시작 후 7일 이내, 5강 미만 수강 시에는 100% 환불 가능합니다.
수강시작 후 7일 이내, 5강 이상 수강 시 전체 강의에서 수강한 강의의 비율에 해당하는 수강료를 차감 후 환불 가능합니다.
수강시작 후 7일 초과 시 정상 수강기간 대비 잔여일에 대해 아래 환불규정에 따라 환불 가능합니다.
환불요청일 시 기준
: 수강시작 후 1/3 경과 전, 실 결제금액의 2/3에 해당하는 금액 환불
: 수강시작 후 1/2 경과 전, 실 결제금액의 1/2에 해당하는 금액 환불
: 수강시작 후 1/2 경과 후, 환불 금액 없음
* 보다 자세한 환불 규정은 홈페이지 취소/환불 정책에서 확인 가능합니다.
패스트캠퍼스 정책 안내
[패스트캠퍼스 아이디 공유 금지 정책]
패스트캠퍼스의 모든 온라인 강의에서는 1개의 아이디로 여러명이 공유하는 형태를 금지하고 있습니다.
동시접속에 대한 기록은 내부 시스템을 통해 자동으로 누적되며, 이후 서비스 이용이 제한될 수 있습니다.
[기기제한 정책]
패스트캠퍼스 온라인 강의 시청을 위해서는 ID별 최대 4개의 기기를 등록할 수 있으며, 기기 등록은 온라인 강의장 접속 시 자동 등록됩니다.
최대 갯수를 초과하였을 경우 등록된 기기 해제가 필요합니다.
[저작권 정책]
패스트캠퍼스의 모든 강의는 무단 배포 및 가공하는 행위, 캡쳐 및 녹화하여 공유하는 행위, 무단으로 판매하는 행위 등 일체의 저작권 침해 행위를 금지합니다.
부정 사용이 적발될 경우 저작권법 위반에 의한 법적인 제재를 받으실 수 있습니다.
국내 7개 카드사 12개월 무이자 할부 지원! (간편 결제 제외)