
Computer Vision Signature 초격차 패키지 Online.
패키지 상품

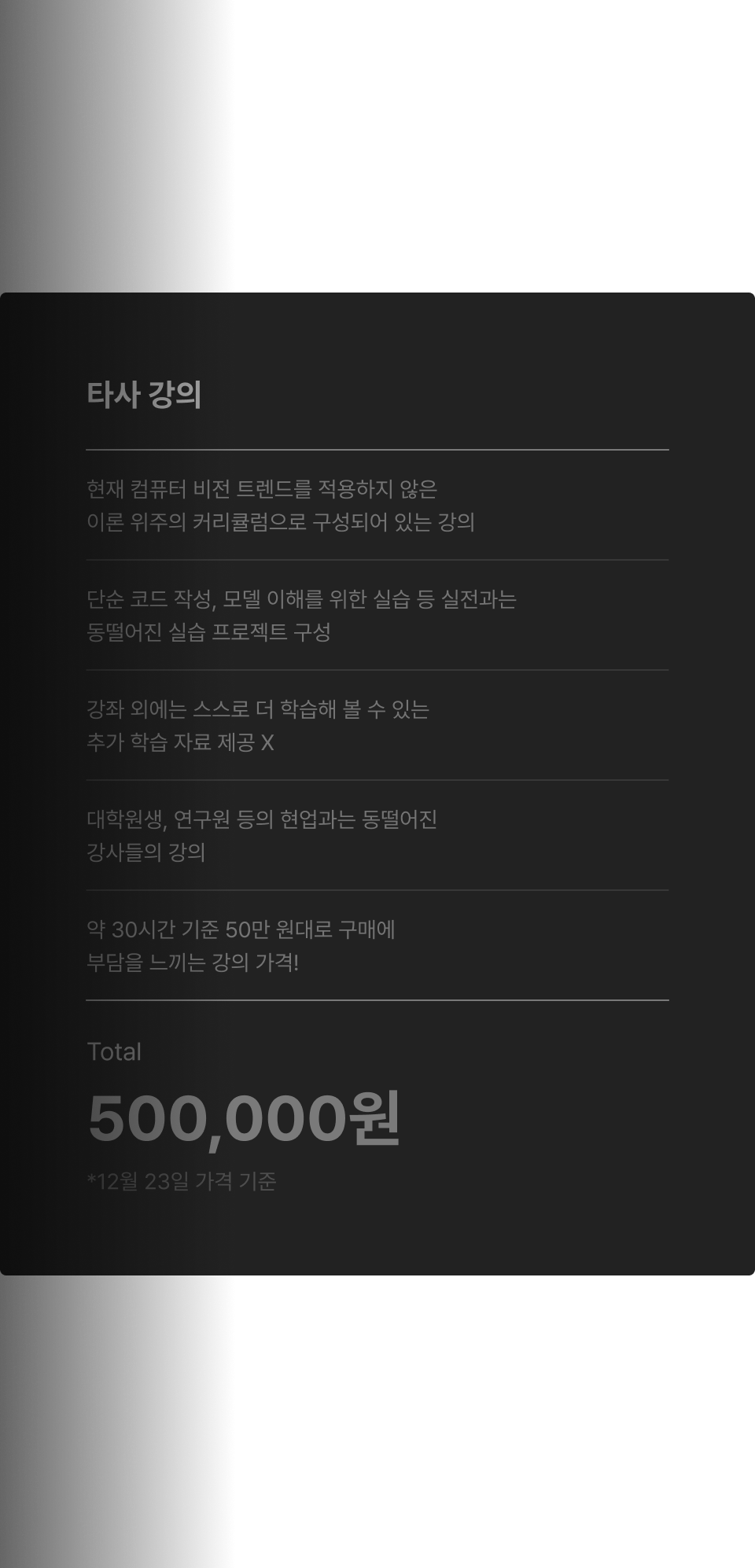
판매 기간이 종료된 상품입니다.
FASTCAMPUS COMPUTER VISION HALL OF FAME



10년간 쌓아온 컴퓨터 비전 교육 노하우로
비.교.불.가 커리큘럼 구성
Fastcampus Only
Computer Vision Signature
3가지 Special 포인트!

전 세계가 주목하는 컴퓨터 비전 기술 총 집합!
자율주행, AR/VR, 멀티모달 로봇 등 AI 업계에서 활용되고 있는
컴퓨터 비전 핵심 기술을 모두 학습합니다.
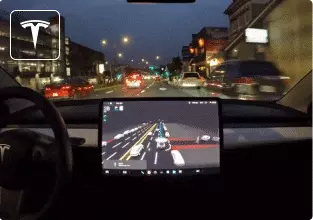
Tesla의 비밀병기, FSD 컴퓨터 Tesla는 컴퓨터 비전 기술 기반의 FSD(Full Self Driving) 기능을 기술로 5단계 자율주행(운전자 없는 자동차) 기능을 개발하고 있습니다.

Apple이 개발한 Vision Pro Apple은 세계 최초로 디지털 콘텐츠와 물리적인 세계를 매끄럽게 상호작용할 수 있는 Vision Pro라는 공간 컴퓨팅 기기를 개발하였습니다.

OpenAI 모델을 탑재한 휴머노이드, Figure o1 OpenAI의 멀티모달 인공지능 모델을 결합한 휴머노이드 로봇 Figure o1는 테스터의 음성과 함께 상황을 종합적으로 인식할 수 있었습니다.
전 세계가 주목하는 컴퓨터 비전 기술의 핵심은?

Signature 패키지에서만 경험할 수 있는 3개의 최종 프로젝트
현재 컴퓨터 비전 분야에서 가장 큰 2가지 화두인 Multimodal과 Spatial AI를
응용하여 3개의 최종 프로젝트를 직접 구현합니다.

오늘의 집, IKEA Kreative 등에 활용되는
객체를 렌더링하는 프로젝트 구현
가상의 객체를 3차원 공간 내에
증강시킬 수 있는 프로젝트 구현

Vision-Language 모델을 활용하여
멀티모달 로봇 프로젝트 구현
멀티모달 모델을 활용하여 로봇의 상위제어 명령을
도출할 수 있는 프로젝트 구현

Meta Quest의 AR/VR
헤드셋 트랙킹 소프트웨어 프로젝트 구현
현실에서의 움직임을 3차원 공간에서
바로 반영할 수 있는 프로젝트 구현

기본기를 다질 수 있는 탄탄한 학습 부가자료까지 한 번에!
강의로는 2% 부족하다면?
패캠이 챙겨주는 실전 경험과 트렌드까지 모두 한 번에!

2025. 01. 24 ~ 2028. 01. 24까지 제공합니다.

2025.05.02에 공개합니다.
컴퓨터 비전 엔지니어가 되기 위해 6가지 필수 핵심 포인트
2D 컴퓨터 비전부터 멀티모달, Spatial AI까지 한 번에!




POINT 01
딥러닝을 활용한 2D 컴퓨터 비전
컴퓨터 비전 기술을 이해하기 위한 신경망의 주요 흐름을
학습하고 2D 컴퓨터 비전의 핵심인 객체 검출과 분할 학습

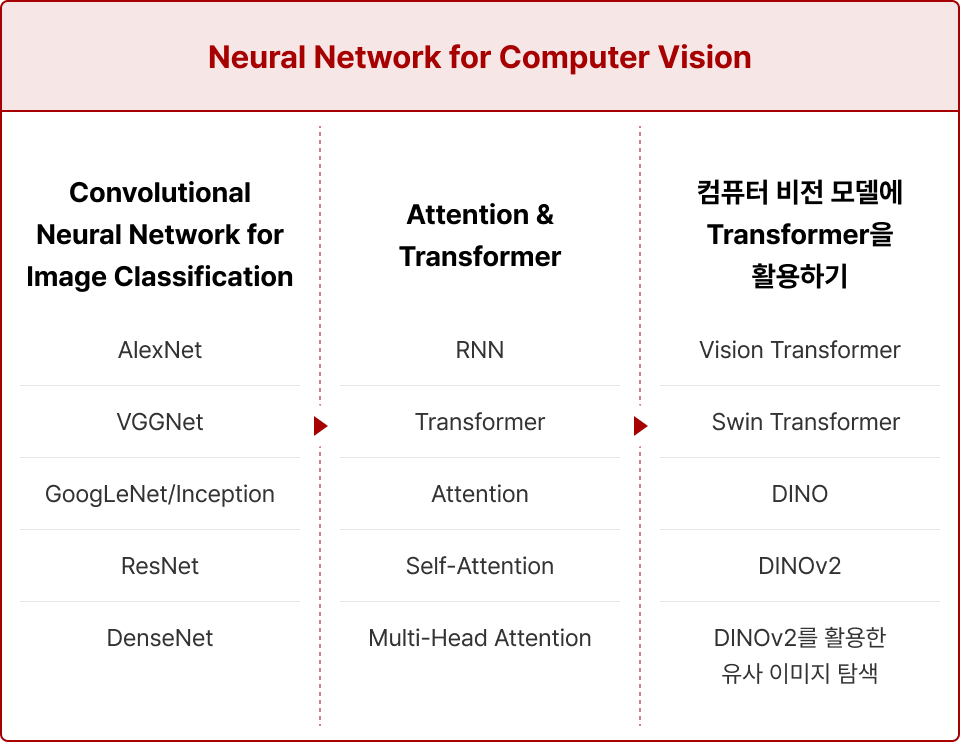
Neural Network for Computer Vision
컴퓨터 비전 기술의 Backbone이 되는 CNN과 ViT를 학습하고,
시각적인 특징을 잡아낼 수 있는 방법을 학습합니다.
시각적인 특징을 잡아낼 수 있는 방법을 학습합니다.
컴퓨터 비전을 위한 뉴럴 네트워크 학습
컴퓨터 비전의 시작이라고 할 수 있는 CNN 신경망부터 현재 기업들이 컴퓨터 비전
모델에서 적극적으로 활용하고 있는 ViT 모델까지 모두 학습할 수 있습니다.
1. CNN for Computer Vision
CNN이 등장하게 된 계기부터 이미지 분류 수행을 위해 발전해 왔던 CNN의 구조를 순차적으로 학습하며 CNN 모델의 발전 과정 및 핵심 활용 기법을 학습합니다.
2. Attention & Transformer
ViT의 근간이 되는 Transformer 모델을 학습하고 Transformer의 핵심인 Self-Attention을 활용하여 CNN 없이도 컴퓨터 비전 분야에서 높은 모델 성능을 낼 수 있는 방법을 학습합니다.
3. 컴퓨터 비전 분야에 Transformer 활용하기
Transformer가 적용된 ViT부터 발전된 최신 모델까지 모두 학습해 보고, 최신 모델인 DINO v2로 시각적인 특징을 잡아낼 수 있는 방법을 학습하기 위한 유사 이미지 분류 실습을 진행합니다.
Middle Project 1 | DINO v2를 활용하여 유사 이미지 탐색 실습

| 실습 내용
ViT 모델 중 현재 SOTA라고 할 수 있는 DINO v2 모델을 활용하여
이미지가 특징을 학습할 수 있게끔 분류 실습을 진행합니다.
이미지가 특징을 학습할 수 있게끔 분류 실습을 진행합니다.

Object Detection
컴퓨터 비전 기술에서 특징을 사전에 추출하고 주어진 이미지/영상에서
해당 특징을 검출하는 방법을 학습합니다.
해당 특징을 검출하는 방법을 학습합니다.
Object Detection 학습을 위해 반드시 알아둬야 할 3가지 모델 학습


복잡한 상황에서 Detection 해볼 수 있는 대표 2가지 모델 학습

Rotated Object Detection
객체가 회전하는 상황에서 회전 정도를 검출하여
차량을 탐지하는 방법을 학습합니다.

Class Agnostic Object Detection
별도의 분류 없이 혹은 기존에 검출하지 않은 객체를
검출하는 방법을 학습합니다.
Semantic Segmentation
장면을 완벽하기 이해하기 위해 식별된 객체들의 모든 픽셀을
각 클래스로 분류하는 방법을 학습합니다.
각 클래스로 분류하는 방법을 학습합니다.
과거와 현재 각 대표적으로 쓰이고 있는 Segmentation 모델 학습

객체 구분 및 분할의 정확성을 올린 Mask R-CNN 해상도 처리 정확도가 떨어지는 문제를 해결하기 위해 RolAlign을 도입해서 분할 정확도 성능을 높일 수 있던 방법을 학습합니다.

Zero-Shot Learning을 활용한 SAM(Segemnt Anything) 사전 학습을 통해 기존 Segmentation 모델이 사전에 정의되지 않았던 객체까지 구분하여 분할하는 방법을 학습합니다.
Segmentataion 최신 모델 SAM을 활용한 2가지 프로젝트 실습
Middle Project 2 | Image Inpainting 실습

| 실습 내용 마스킹 없는 Inpainting을 최초로 시도한 방법으로써 텍스트 프롬프트만으로 이미지를 분할하는 실습을 진행합니다.
Middle Project 3 | OCR-SAM 실습

| 실습 내용 별도의 텍스트 검출 모델 없이도 정확하게 텍스트 영역을 분리하여 문자를 인식할 수 있는 실습을 진행합니다.

Human Pose Estimation
컴퓨터 비전 기술에서 사진 혹은 영상 속 사람의 신체 관절이 어떻게 구성되어 있는지
위치를 추정하여 파악할 수 있는 방법을 학습합니다.
위치를 추정하여 파악할 수 있는 방법을 학습합니다.

Classification을 활용하여 좌표를 예측하는 RTM-Pose Gaussian Label Smoothing 방법을 사용하여 포즈의 X,Y 축을
분류해 포즈를 추정하는 방법을 학습합니다.
분류해 포즈를 추정하는 방법을 학습합니다.

ViT를 백본으로 사용하고 가벼운 디코더를 활용한 ViT Pose ViT의 구조를 활용하여 특별한 도메인 지식 없이도 전역적 특성
추출 능력으로 더 자세하게 포즈를 추정하는 방법을 학습합니다.
추출 능력으로 더 자세하게 포즈를 추정하는 방법을 학습합니다.

학습 데이터가 없어도 자세 추정이 가능한 Pose Anything 객체의 각 Key Point 간 연결을 고려한 GNN 접근 방식을 활용하여 포즈를 추정하는 방법을 학습합니다.
Middle Project 4 | 신체의 운동 자세 추정하기
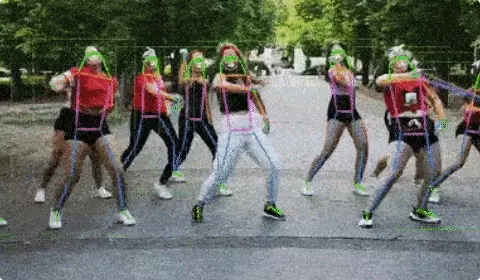
| 실습 내용
운동하는 사람의 자세를 포즈 출력 값으로 활용하여
실시간으로 자세를 분석할 수 있는 실습을 진행합니다.
2D 컴퓨터 비전의 특징을 이해하였다면 이를 바탕으로
객체 검출 & 분할을 응용하여 실습해볼 수 있는 Final Project를 진행합니다.


SAMURAI 모델을 활용하여 끊김 없이
객체를 추적해볼 수 있는 프로젝트 구현 객체 궤적의 이력을 고려하고 시각적으로 유사한 객체를 구별하면서
일관성있게 추적할 수 있는 실습을 진행합니다.
객체를 추적해볼 수 있는 프로젝트 구현 객체 궤적의 이력을 고려하고 시각적으로 유사한 객체를 구별하면서
일관성있게 추적할 수 있는 실습을 진행합니다.
POINT 02
3차원 공간 정보를 추정하여 모델을 생성하는 3D 컴퓨터 비전
현재 IT 업계가 가장 주목하는 자율주행, AR/VR, 로봇 네비게이션 등 최신 기술에
필수적으로 활용되는 3D 컴퓨터 비전 기술 학습

Feature Detection & 3D Pose Estimation
컴퓨터 비전 기술에서 3차원 포즈 추정 및 복원 방법의 근간이 되는
이미지 특징점을 추출 및 매칭하는 방법을 학습합니다.
이미지 특징점을 추출 및 매칭하는 방법을 학습합니다.
두 이미지 사이의 3차원 포즈 변화를 추정할 수 있는 방법 학습




다시점 이미지를 활용한 2가지 이미지 매칭 및 포즈 추정 실습
Middle Project 1 | 두 이미지 간 상대적인 포즈 변화 추정 실습

| 실습 내용
이미지 매칭과 포즈 추정을 결합하여 두 이미지 간
상대적인 포즈 변화를 추정하는 실습을 진행합니다.
Middle Project 2 | 영상 속 특징점 추출과 매칭 실습

| 실습 내용
매칭이 어려운 다양한 이미지 별 두드러지는 특징을
뽑아내어 이미지를 매칭하는 실습을 진행합니다.

3D Object Detection
3차원 큐브 형태로 객체를 검출하는 방법을 이해하고, 카메라 이미지로부터
3차원 형태의 객체를 검출하는 방법을 학습합니다.
3차원 형태의 객체를 검출하는 방법을 학습합니다.

1개의 Bounding Box에서 정보를 얻어 객체를 표현하는 SMOKE 객체 단일 Keypoint 추정과 회귀를 통해 얻은 3D 변수를 결합하고 3D Bounding Box를 예측하여 객체를 검출하는 방법을 학습합니다.

2D 이미지의 특징을 3D Voxel Grid로 표현하는 ImvoxelNet
3D Point Cloud나 LiDAR 데이터 없이도 이미지 기반 특징만을
활용하여 3D 환경에서 객체를 검출하는 방법을 학습합니다.
Middle Project 3 | 실내에 있는 객체를 3차원 형태로 검출하기

| 실습 내용
실내 2차원 형태의 이미지를 검출하였을 때, 위치, 크기, 회전 정보를
포함하여 3차원 Cuboid 형태로 검출하는 실습을 진행합니다.

3D Depth Estimation
3차원 공간을 이해할 수 있는 정보 중 하나인 Depth(깊이)를
답러닝을 활용하여 추출하는 방법을 학습합니다.
답러닝을 활용하여 추출하는 방법을 학습합니다.

1개의 이미지로 Depth를 추정하는
MonoDepth
Depth를 추정하기 위해 1개의 이미지만을 넣고
Disparity(시차)를 찾아나가는 과정을 학습합니다.

상대적 환경에서 정확도를 개선하는
ZoeDepth
각 이미지 픽셀별로 깊이 구간 별 중심을 예측하여
Depth를 추정해나가는 방법을 학습합니다.

스테레오 매칭 문제를 해결하여 깊이를
추정하는 RAFT-Stereo
3D Depth Estimation에서 핵심 병목 현상이었던 Disparity 추정 문제를 해결하는 방법을 학습합니다.
Middle Project 4 | 직접 촬영한 사진의 Depth를 추정해보자!

| 실습 내용
메타 데이터가 없이도 자연 상태의 이미지로 Depth Map을
생성하고 flying pixels 문제를 해결할 수 있는 실습을 진행합니다.

3D Reconstruction
여러 개의 이미지를 활용하여 3차원 복원을 생성하는 방법을 학습하고
딥러닝을 활용한 대표 3가지 3D 복원 기술을 학습합니다.
딥러닝을 활용한 대표 3가지 3D 복원 기술을 학습합니다.
3 Step으로 끝내는 3D 복원 기술의 핵심, SfM

 * PnP(Perspective-n-Point) : Camera intrinsic parameter, 3D points와 이에 대응하는 이미지상의 2D Projection points가 주어질 때 Camera pose를 구하는 문제
* PnP(Perspective-n-Point) : Camera intrinsic parameter, 3D points와 이에 대응하는 이미지상의 2D Projection points가 주어질 때 Camera pose를 구하는 문제
SfM을 응용하여 현재 가장 많이 활용되고 있는 대표 3가지 복원 방법 학습

2D-3D Mapping Network를 사용하여
3D 복원을 구현한 Dust3R
Transformer 모델을 활용하여 3D 공간에서
이미지 매칭 문제를 해결하는 방법을 학습합니다.

End to End로 더 강인한 3D 복원 방법을
구현한 VGGSfM
이미지 트래킹에서 도출되는 포즈 추정부터 Solver까지 모두 엮어 3D 복원하는 방법을 학습합니다.

3D 환경에서 이미지 매칭 문제를
다룬 MASt3R
DUSt3R의 개선 된 모델로, 이미지 매칭을 3D로
다루면서 복원 퀄리티를 높이는 방법을 학습합니다.
Neural Rendering
Neural Rendring의 대표 2가지 기술인 NeRF와 3D Gaussian Splatting을
학습하고 새로운 시점에 대한 렌더링부터 3차원 모델 복원 방법을 학습합니다.
학습하고 새로운 시점에 대한 렌더링부터 3차원 모델 복원 방법을 학습합니다.
Volume Rendering 기법을 활용하는 NeRF
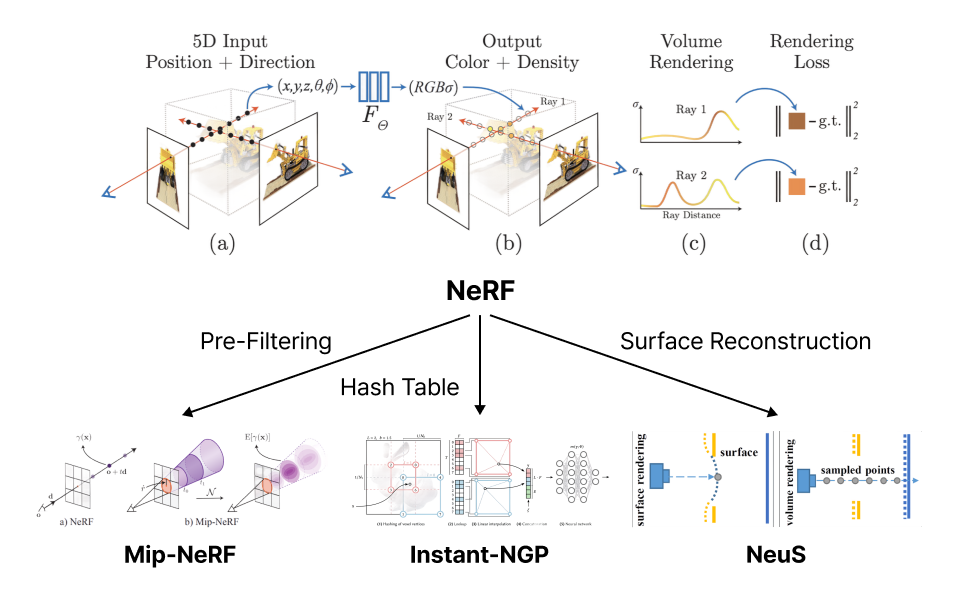
일반 카메라로 촬영한 이미지를 공간 상의 색과 밀도가 누적된 결과로 표현하고, 이를 역으로 활용하여 공간의 모습을 추정하는 방법을 학습합니다.
· NeRF와 각 파생된 MipNeRF, Instant-NGP, NeuS 모델들의 특징 학습
· (실습) nerfstudio로 내가 찍은 사진들로부터 3차원 랜더링 결과를 뽑아보기
100FPS 이상 빠른 렌더링 속도를 보여주는 3D Gaussian Splatting

각 이미지 screen마다 모든 3D Gaussian을 projection한 후, 작은 단위의 tile로 나눠 각 tile마다 color & opacity accumlation을 병렬로 실행해볼 수 있는 방법을 학습합니다.
· 연산량 측면에서 획기적인 효율성을 가져온 3D Gaussian Splatting 특징 학습 · Speed / Quality / Memory 측면에서 변화를 가져온 대표적인 모델 학습 · (실습) gsplat을 통해 내가 찍은 사진들로 3차원 렌더링 결과를 뽑아보기
3D 컴퓨터 비전의 특징을 이해하였다면 이를 바탕으로
3차원 객체 검출 및 복원을 응용해볼 수 있는 Final Project를 진행합니다.


Neural Rendering을 활용하여 3차원 복원과
Depth 추정하기 (InstantSplat)


실내의 3차원 공간을 복원하고
객체를 검출하기 (EFM3D)
POINT 03
여러 센서와 입력 데이터를 동시에 처리하는 멀티모달
단순 이미지와 영상 분석을 넘어서 텍스트와 제어 모달을 결합하여
다양한 데이터를 종합적으로 처리할 수 있는 멀티모달 모델 학습
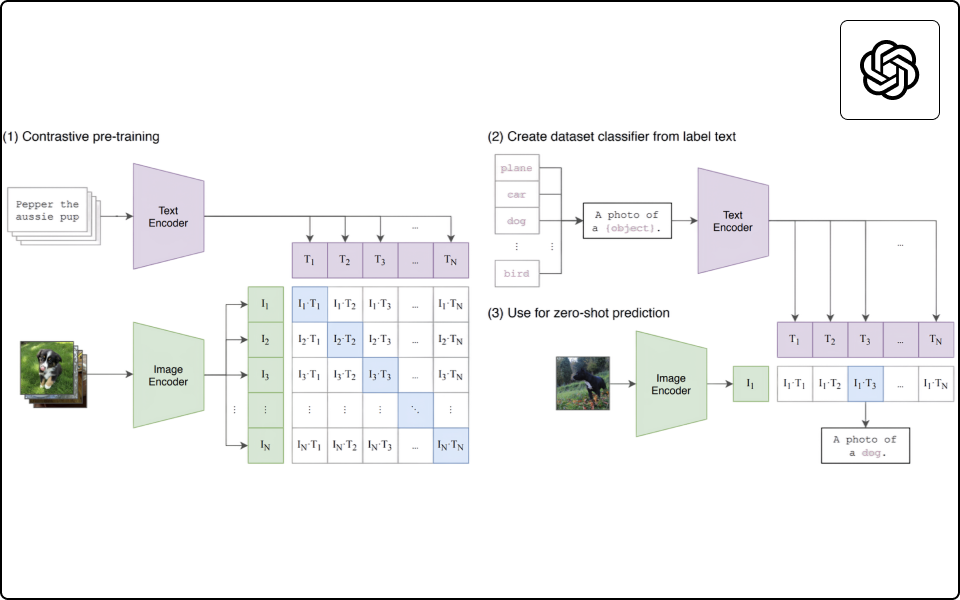
CLIP (CONTRASTIVE LANGUAGE-IMAGE PRE-TRAINING)
· 이미지와 텍스트의 벡터화를 이해하고, 두 Space 간 상관성을 학습
· (실습) 이미지와 텍스트 간 유사성 비교해보기
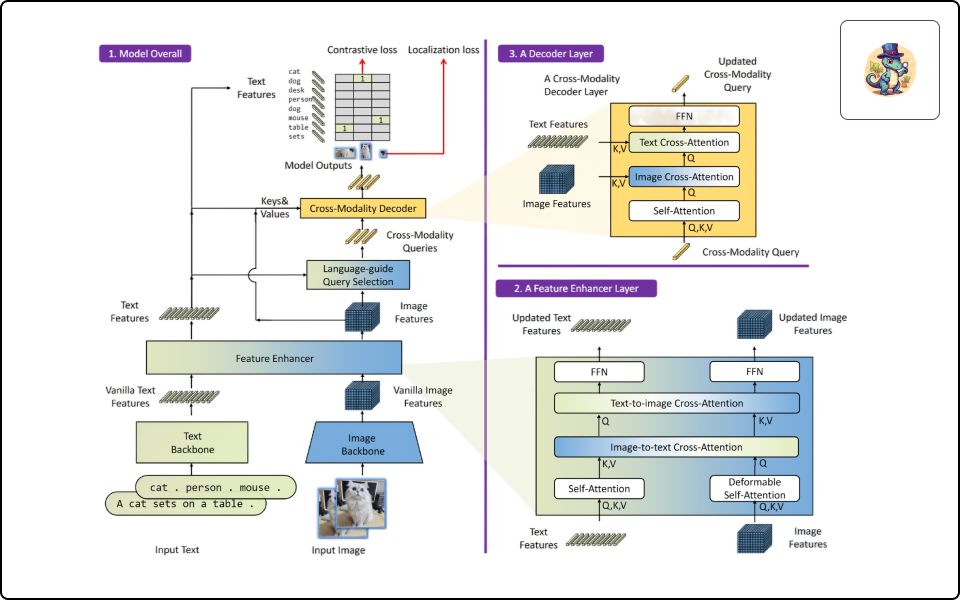
Grounding DINO
· 라벨링 작업 없이 텍스트만으로 객체를 검출하는 방법 학습
· (실습) 텍스트로부터 Annotated Data 없이 Zero-Shot Object Detection 구현하기
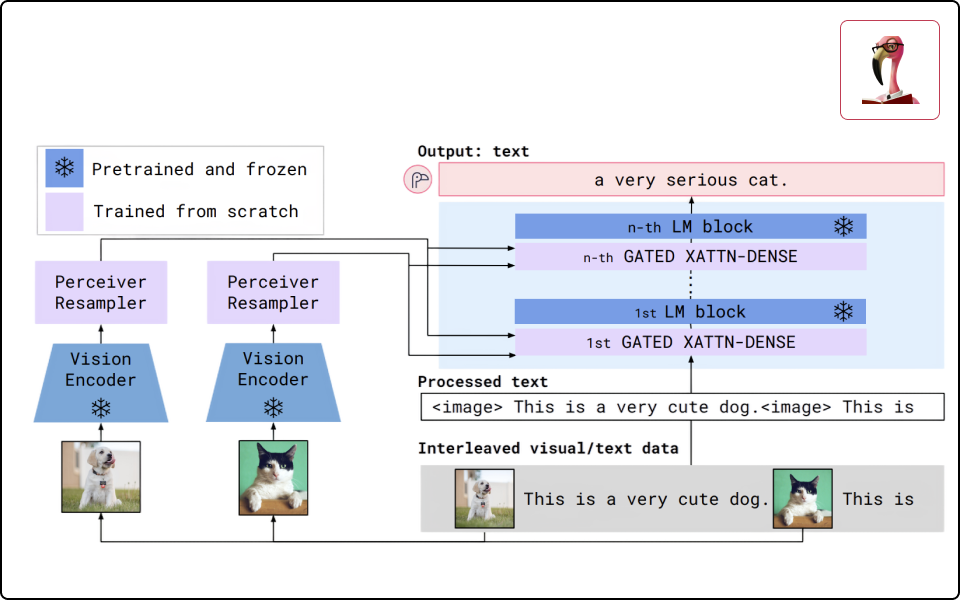
Flamingo
텍스트를 출력하는 Flamingo
· LLM에서 아이디어를 차용하여 Few Shot Learning으로 범용적 사용이 가능한 특징 학습
· 이미지와 텍스트를 모두 입력으로 받아 텍스트를 출력할 수 있는 방법 학습
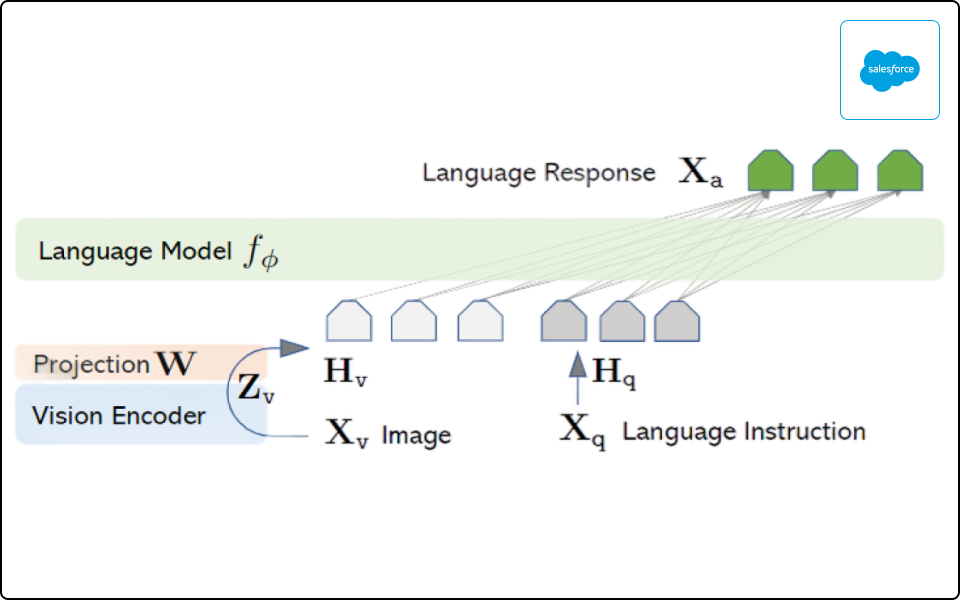
LLaVA
· 이미지의 단순 설명이 아닌 질의응답과 대화를 하며 범용적인 Task 수행이 가능한 Assistnat로서의 특징 학습
· (실습) LLaVA를 활용하여 이미지 Description 생성하기
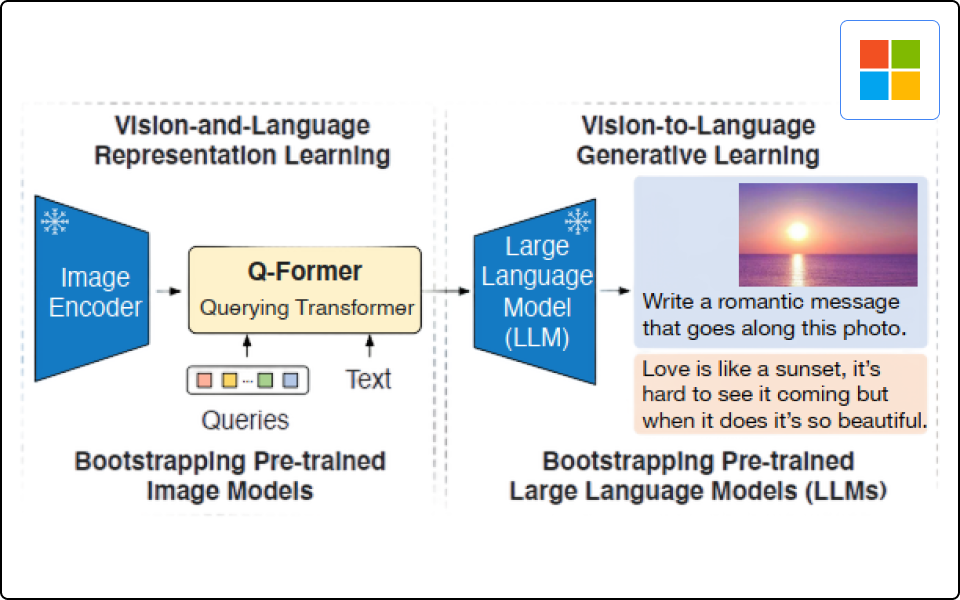
BLIP
· Unimodal을 활용하여 멀티모달 모델로써 목적에 맞게 모델을 활용하는 방법 학습
· Q-Former로 LLM이 학습 과정에서 이미지 정보를 전달하여 데이터를 Align하는 방법 학습
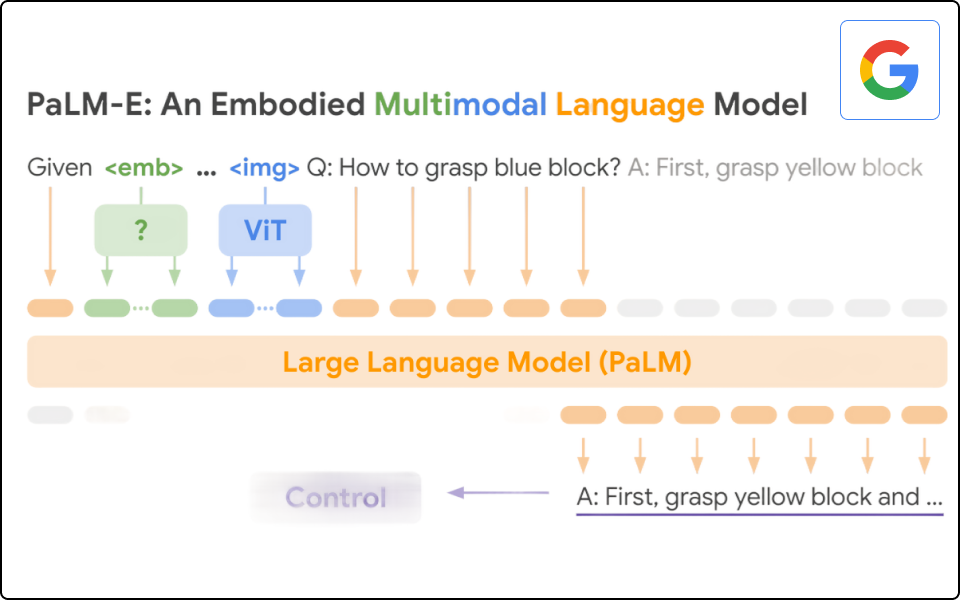
PaLM-E
· 텍스트 Input 데이터 외에도 로봇 센서 데이터의 raw stream을 수집할 수 있던 특징 학습
· 이미지 & 텍스트 입력을 똑같은 공간으로 변환하는 encoder의 원리 학습
POINT 04
카메라 센서로 주변 환경을 인식하는 Visual SLAM
3D 공간을 정확하게 이해하고 또 공간과 상호작용하기
위해 공간 속 위치를 파악하는 방법을 학습

SLAM을 동작하기 위해 반드시 알아야 할 개념 학습
| SLAM이 구현되기 위한 각 과정을 살펴보고 Visual SLAM의 기본이 되는 3D 회전과 이동과 카메라 투영 방법을 학습합니다.
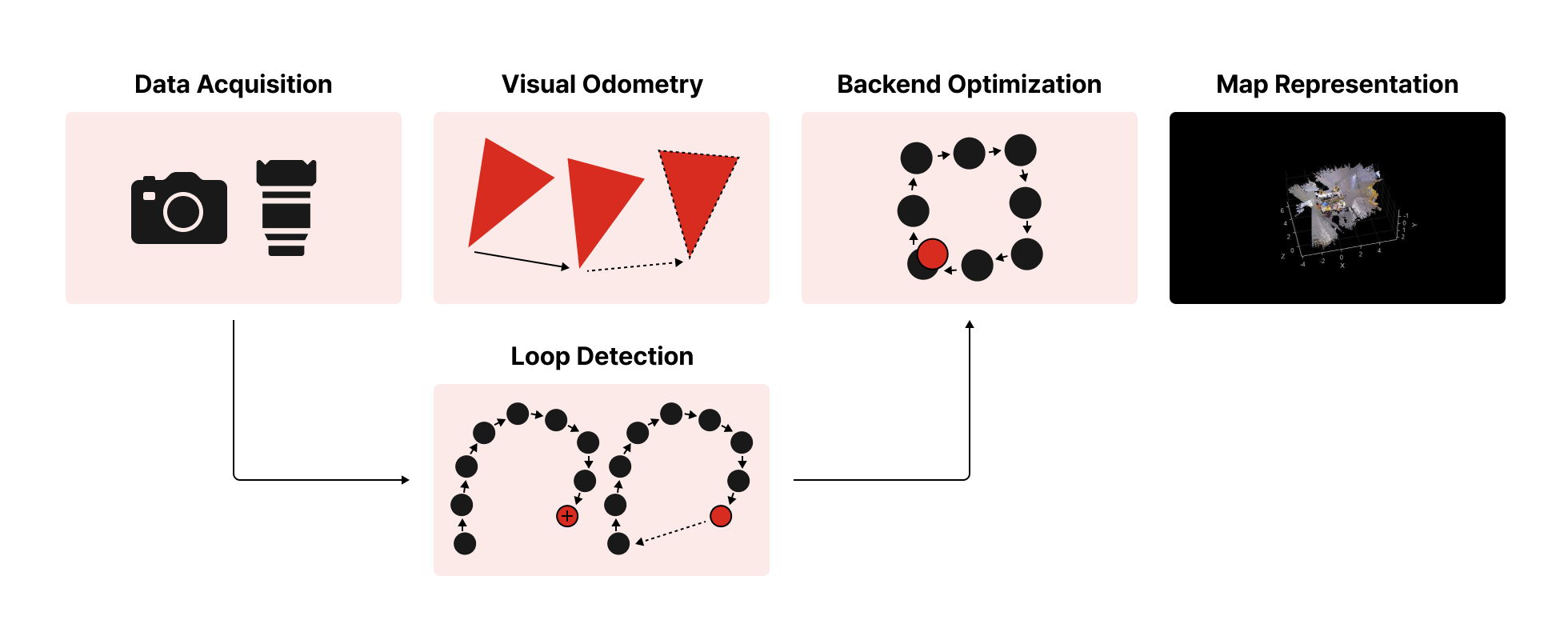
Front-End(카메라의 움직임을 추정하고 local map을 생성)
카메라 센서 데이터 수집 / 전처리(노이즈 제거)

2D/3D Vision
· 시각적 주행 거리 측정
· 센서의 상대적인 움직임을 예측
· 센서의 상대적인 움직임을 예측
Loop Closer Detection
· 현재 센서 위치가 이전 방문 위치인지 판단
· 비연속적인 데이터로 상대적 움직임 예측
· 비연속적인 데이터로 상대적 움직임 예측
Back-End(Front의 센서 위치와 주변 환경 정보 기반 최적화)
Backend Optimization
Optimized Map Representation
· 최적화된 정보를 기반으로 시나리오에
적합한 환경지도 생성
적합한 환경지도 생성

영상 처리와 다중시점 기하학
| Visual SLAM을 구현하기 위해 필수적으로 알아둬야 할 영상처리 기법과 모션 추정 방법을 학습합니다.

Local Feature Detection 두 개의 이미지 사이에서 공통된 3D 공간인 Local Feature를 검출하는 방법을 학습합니다.

Local Feature Matching 두 개의 이미지 사이에서 공통된 3D 공간인 Local Feature 간의 매칭을 학습합니다.
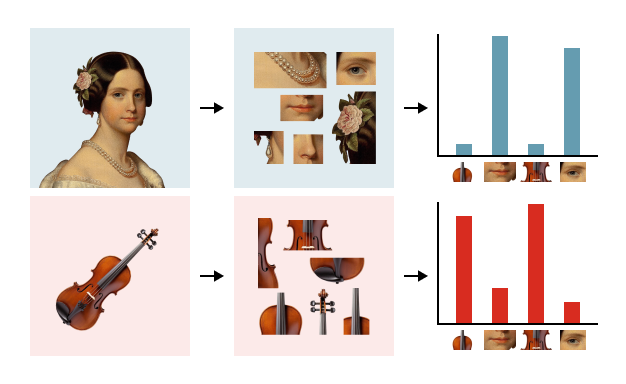
Global Feature Detection Loop Closure & 위치 인식에 활용되는 Global Feature의 개념에 대해 학습합니다.

Optical Flow 영상 내 물체의 움직임 패턴을 의미하며 프레임 간 픽셀 이동 방향과 거리 분포를 학습합니다.
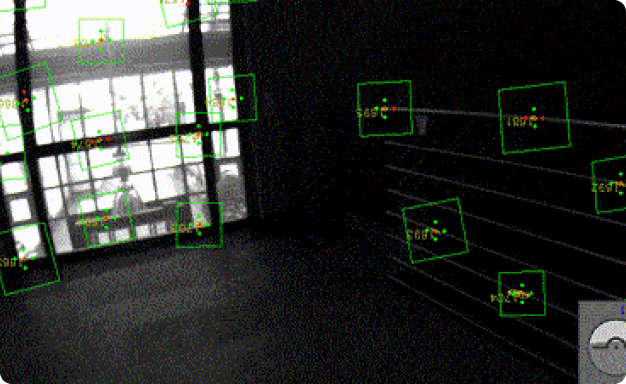
Direct Tracking Local Feature 패치의 변화를 기준으로 카메라의 이동량을 추론하는 방법을 학습합니다.
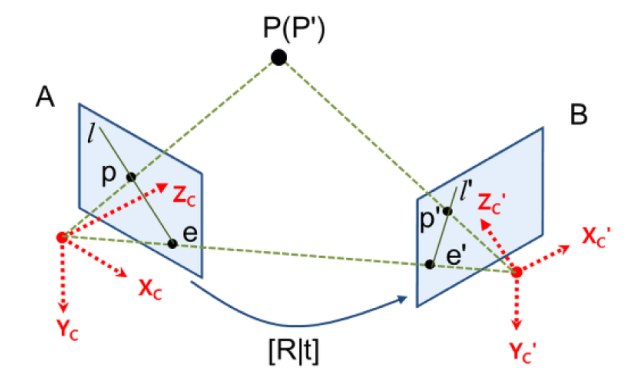
Epipolar Geometry 두 이미지의 매칭쌍으로 카메라의 이동행렬간 관계를 정의하는 방법을 학습합니다.

Homography 특정 Projection 지점으로 하나의 평면에서 다른 평면으로 점들을 매핑하는 방법을 학습합니다.
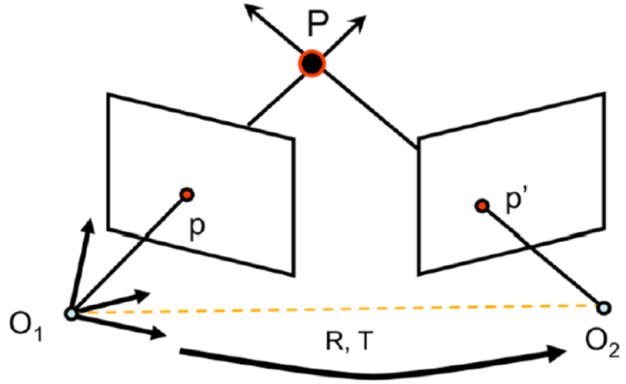
Essential Matrix 정규화된 이미지 평면에서 매칭 쌍들 사이의 기하학적 관계를 다루는 방법을 학습합니다.
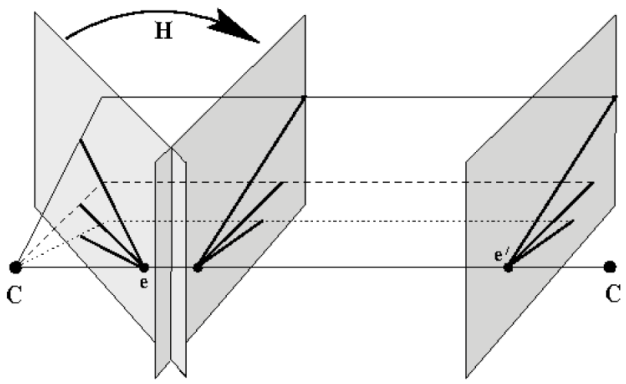
Fundamental matrix 카메라 파라미터를 포함한 두 이미지의 실제 픽셀 좌표 사이 기하학적 관계를 다루는 방법을 학습합니다.
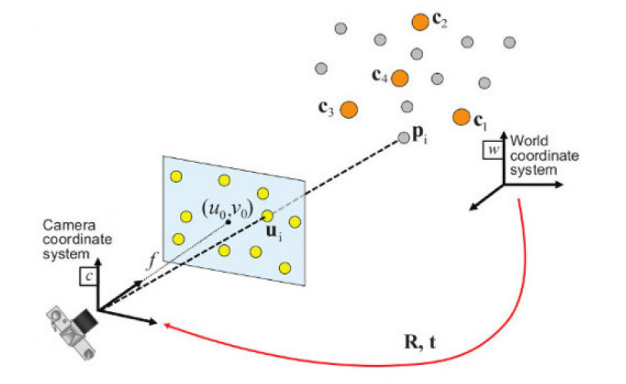
PnP 매칭된 Feature들로 3D 랜드마크를 생성하고
카메라 움직임을 추론하는 방법을 학습합니다.
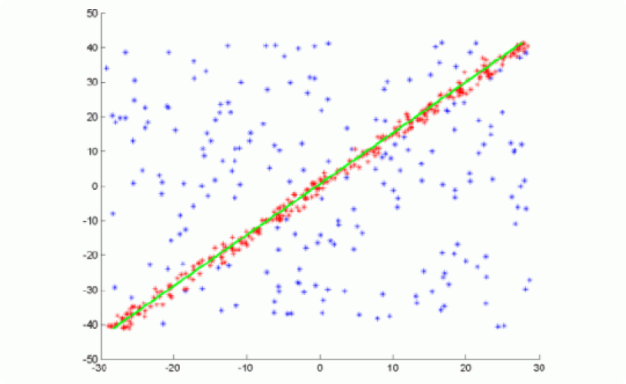
RANSAC 각 센서 이상치 데이터 속 잘못된 매칭을 걸러내는 방법을 학습합니다.

비선형 최적화
| 여러 시퀀스에서 얻은 이미지들의 동일한 지점을 관찰하여 노이즈 데이터를 처리하는 방법을 학습합니다.
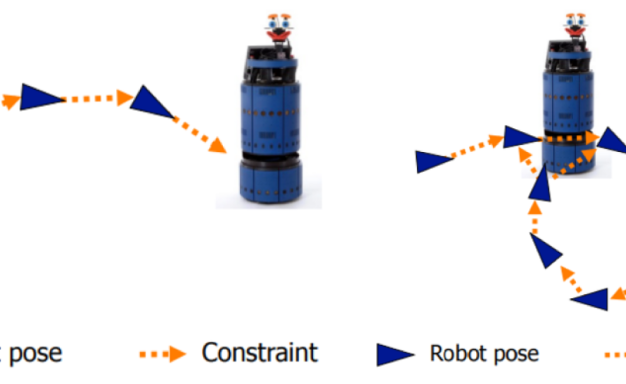
Graph Based SLAM 그래프 구조를 활용하여 3D 랜드마크와 카메라의 포즈를 관리하는 방법을 학습합니다.
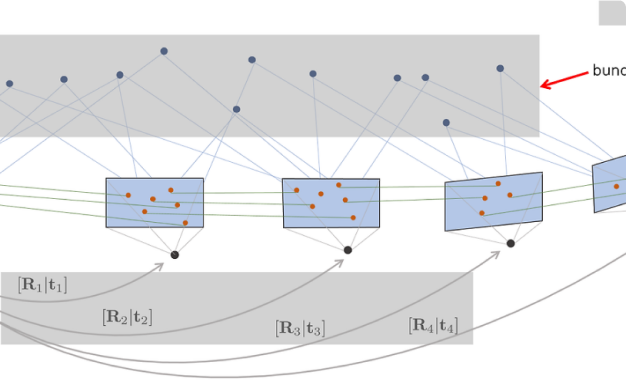
Bundle Adjustment 3D 랜드마크와 카메라의 포즈를 동시에 최적연산할 수 있는 방법을 학습합니다.
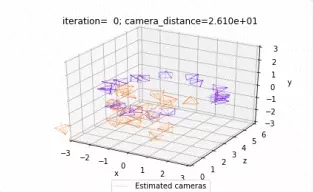
3D 랜드마크와 카메라의 포즈를 동시에 최적연산할 수 있는 방법을 학습합니다. 비선형 공간에서 최적의 카메라 포즈와 랜드마크 위치를 파악할 수 있는 방법을 학습합니다.

Visual SLAM Architecture
| Visual Odometry 알고리즘에서 포즈를 계산하는 대표 2가지 방법론을 학습합니다.

이미지 상에서 특징점을 추출한 후 카메라가 이동함에 따라 변하는 특징점의 위치를 추적하여 카메라의 포즈를 계산하는 방법을 학습합니다.
[ 방법론 개요 ]
이미지에서 특징이 될만한 기하학적 요소(점, 선, 면)들들 추출해내고 해당 정보들로 Pose Estimation을 진행 후 환경을 재구성합니다.
[ 구체 학습 내용 ]
Feature와 그에 대한 Descriptor를 뽑아 seq image와 매칭을 하고 이를 통해 Front-End에서 트랙킹하는 방법을 학습합니다.
[ 방법론 개요 ]
이미지에서 특징이 될만한 기하학적 요소(점, 선, 면)들들 추출해내고 해당 정보들로 Pose Estimation을 진행 후 환경을 재구성합니다.
[ 구체 학습 내용 ]
Feature와 그에 대한 Descriptor를 뽑아 seq image와 매칭을 하고 이를 통해 Front-End에서 트랙킹하는 방법을 학습합니다.

카메라가 이동함에 따라 변하는 픽셀의 밝기 변화를 추적하여
카메라의 포즈를 계산하는 방법을 학습합니다.
[ 방법론 개요 ]
밝기 항상성, 작은 움직임, 공간 일광성 3가지 요소를 고려하여 밝기 변화를 통한 Photometric Error를 최소화하는 카메라의 포즈를 계산합니다.
[ 구체 학습 내용 ]
Photometric Error를 통해 Optical Flow를 구하는 방법과 이를 이용해서 Front-End에서 트랙킹하는 방법을 학습합니다.
[ 방법론 개요 ]
밝기 항상성, 작은 움직임, 공간 일광성 3가지 요소를 고려하여 밝기 변화를 통한 Photometric Error를 최소화하는 카메라의 포즈를 계산합니다.
[ 구체 학습 내용 ]
Photometric Error를 통해 Optical Flow를 구하는 방법과 이를 이용해서 Front-End에서 트랙킹하는 방법을 학습합니다.
POINT 05
3개의 최종 프로젝트로 끝내는 Computer Vision Signature
현재 컴퓨터 비전 분야에서 가장 대표적으로 적용되고 있는 멀티모달 & Spatial AI
기술을 응용하여 3개의 최종 프로젝트를 구현합니다.

3D Computer Vision 모델을 활용하여 가상의 객체를 랜더링하는 프로젝트
3차원 공간 내에 있는 임의의 객체를 동시에 복원 및 포즈 추정함으로써
가상의 객체를 실제 객체 주변으로 증상시킬 수 있는 방법 학습
가상의 객체를 실제 객체 주변으로 증상시킬 수 있는 방법 학습

객체의 위치 추정 기술을 활용하여
실제 공간에서 AR 객체를 증강
Foundation 모델로 사전 데이터 셋에 없는 객체에 대해서도
Robust하게 3차원 복원 및 포즈 추정할 수 있는 방법을 학습합니다.
내가 원하는 객체의 3차원 정보를 획득하여 해당 정보를 기반으로
가상의 객체를 증강시킬 수 있는 방법을 학습합니다.


Vision-Language 모델을 활용하여 멀티모달 로봇 상위제어 명령 도출 프로젝트
로봇이 작업 공간 내에 있는 시각적인 정보를 바탕으로 이를 인지하고,
동작 명령을 내리기 위한 상위 제어 명령어를 도출할 수 있는 방법 학습
동작 명령을 내리기 위한 상위 제어 명령어를 도출할 수 있는 방법 학습

시뮬레이션 환경에서 로봇을
상위제어 하기 위한 명령 도출
시뮬레이터를 활용하여 로봇이 현재 공간의 정보와 그 주변 객체를
이해하고, 명령어가 들어왔을 때 시각 & 언어 정보를 조합하여 현재 공간에서
로봇이 수행할 수 있는 상위 제어 명령을 도출하는 방법을 학습합니다.


Visual SLAM을 활용한 실시간 VR 자세 추정 프로젝트
실시간으로 가상 환경에서 자연스러운 움직임을 구현하기 위한
실시간 저지연 자체 추정을 구현할 수 있는 방법 학습
실시간 저지연 자체 추정을 구현할 수 있는 방법 학습

3차원 공간에서 현실의 움직임을
바로 투영할 수 있는 시스템 구현
Visual SLAM 기술의 특성을 활용하여 Meta Quest의 VR 고글에
탑재된 실시간 헤드셋 자세 추정과 트랙킹 알고리즘을 동일하게 구현하고
실시간으로 현실의 움직임을 3차원 공간에 투영하는 방법을 학습합니다.

궁금증은 언제든지 질의응답 게시판에 질문하세요!
현직 컴퓨터 비전 엔지니어와의 무한 질의응답 1) 실습 중 에러가 나면? 질의응답 채널을 통해 빠른 해결!
2) 강의를 듣다가 이해되지 않는 부분이 생기면 바로 질문하세요!
* 해당 디스코드 커뮤니티는 2025년 01월 24일부터 2028년 04월 18일까지 운영됩니다.
* 강사님이 현업 중 답변 하시기에 답변까지 영업일 기준 7일 내외 시간이 소요될 수 있습니다.
* 강의와 무관한 질문에 대해서는 답변이 필수로 제공되지 않습니다.
현직 컴퓨터 비전 엔지니어와의 무한 질의응답 1) 실습 중 에러가 나면? 질의응답 채널을 통해 빠른 해결!
2) 강의를 듣다가 이해되지 않는 부분이 생기면 바로 질문하세요!
* 해당 디스코드 커뮤니티는 2025년 01월 24일부터 2028년 04월 18일까지 운영됩니다.
* 강사님이 현업 중 답변 하시기에 답변까지 영업일 기준 7일 내외 시간이 소요될 수 있습니다.
* 강의와 무관한 질문에 대해서는 답변이 필수로 제공되지 않습니다.

한 번의 구매로 평생 소장!
언제든, 몇 번이든 다시! 한 번 결제로 평생 동안 무제한 반복 학습이 가능합니다.
바쁜 일정에 걱정할 필요 업싱, 원하는 때에 학습하고 필요할 때마다 복습하세요.
언제든, 몇 번이든 다시! 한 번 결제로 평생 동안 무제한 반복 학습이 가능합니다.
바쁜 일정에 걱정할 필요 업싱, 원하는 때에 학습하고 필요할 때마다 복습하세요.
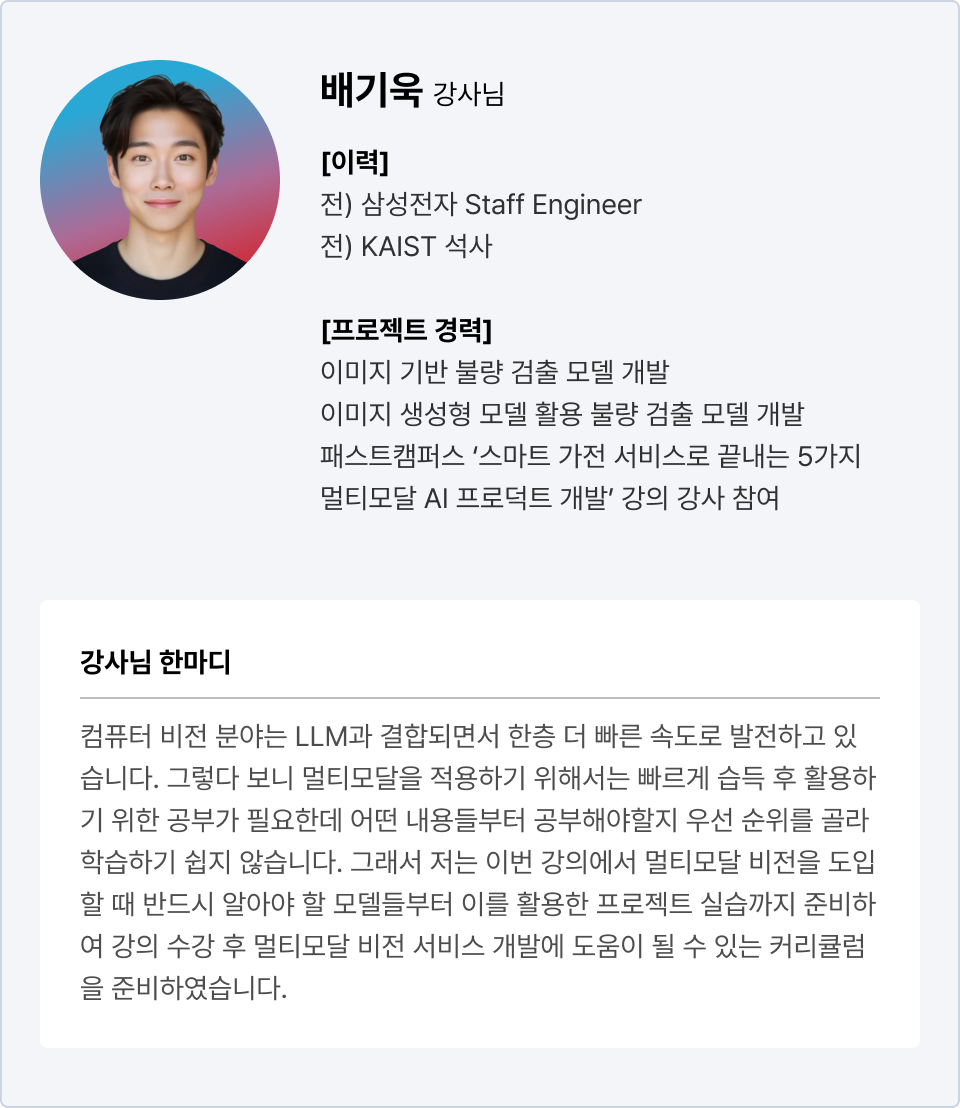
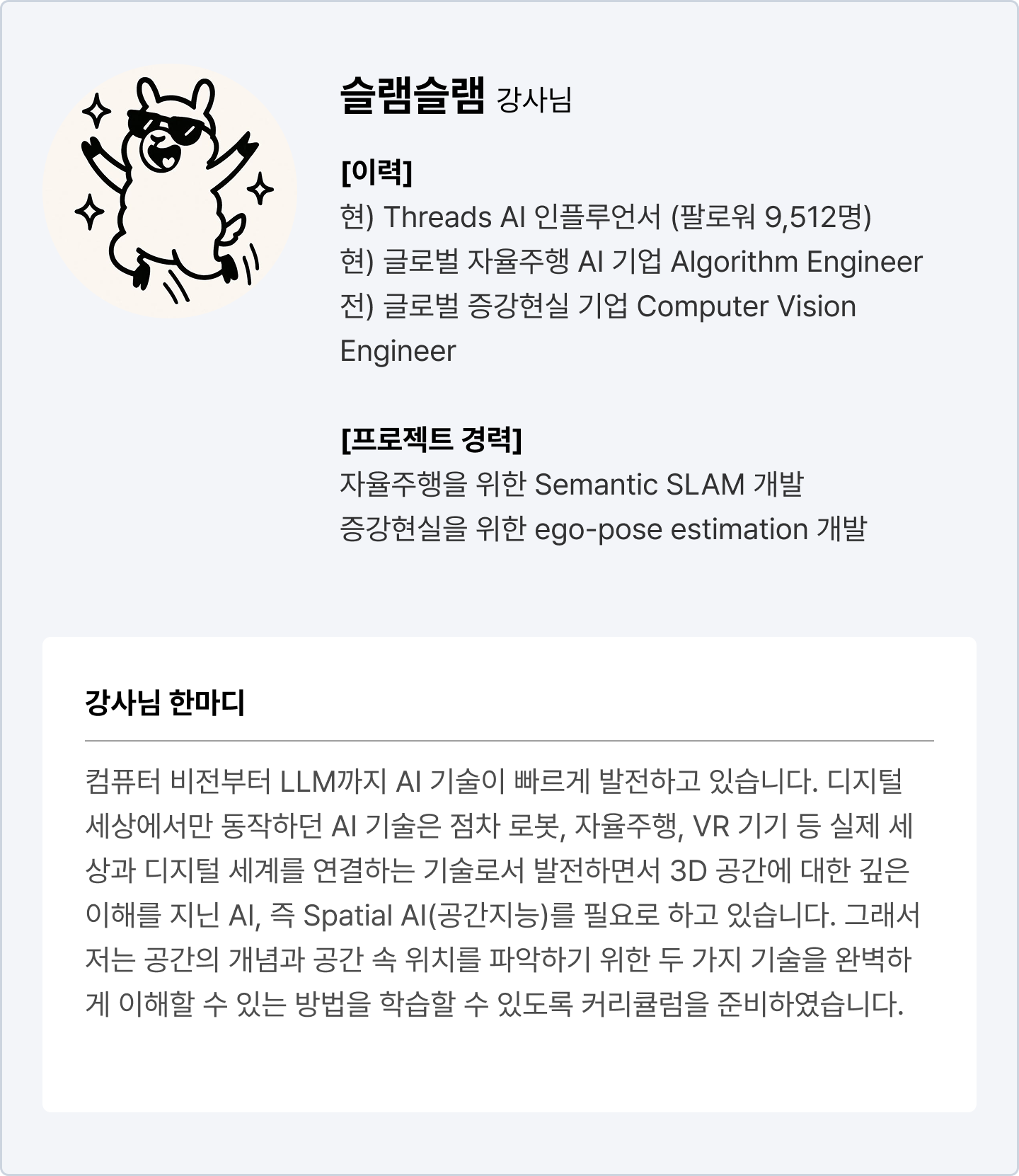
아무리 구성이 좋아도 누구나 가르친다면 의미 없죠!
풍부한 실무 경험을 보유하신 컴퓨터 비전 전문가분들을 모셨습니다!


Q&A
QUESTION 1
어떤 분들이
수강하시면 좋을까요?
수강하시면 좋을까요?
• 컴퓨터 비전 분야 석/박사 대학원생부터 컴퓨터 비전 엔지니어로 직무 전환을 희망하는 분
• 컴퓨터 비전 기술에 대한 Core와 응용 능력이 부족한 주니어 Computer Vision Engineer
• 컴퓨터 비전 기술에 대한 Core와 응용 능력이 부족한 주니어 Computer Vision Engineer
QUESTION 2
해당 주제를 학습할 때 겪는
대표적인 어려움은 무엇인가요?
대표적인 어려움은 무엇인가요?
최근 컴퓨터 비전 분야는 여전히 핵심적으로 알아두어야 할 모델 기반 Application부터
기술의 발전으로 3D 공간 인공지능, 멀티모달 등 다양한 분야에 적용되고 있습니다.
그렇다 보니, 학습 우선 순위 설정과 더불어 현재 산업계에서 원하는 방향성으로 나아가기 위해서 구체적으로 어떻게 학습해야 할 지 고민하시는 분들이 많습니다.
그래서 패스트캠퍼스에서는 반드시 알아두어야 할 컴퓨터 비전 모델들부터 최신 기술들을 경험할 수 있는 프로젝트 구현 실습까지 Step by Step으로 따라오실 수 있게 준비하였습니다.
강의를 수강하시고 나면 단순 2D 기반의 인지 시스템 뿐만 아니라, 현실 환경에서 구조를 표현하고 공간을 분석할 수 있는 기술 역량을 충분히 쌓을 수 있다고 자부할 수 있습니다.
그렇다 보니, 학습 우선 순위 설정과 더불어 현재 산업계에서 원하는 방향성으로 나아가기 위해서 구체적으로 어떻게 학습해야 할 지 고민하시는 분들이 많습니다.
그래서 패스트캠퍼스에서는 반드시 알아두어야 할 컴퓨터 비전 모델들부터 최신 기술들을 경험할 수 있는 프로젝트 구현 실습까지 Step by Step으로 따라오실 수 있게 준비하였습니다.
강의를 수강하시고 나면 단순 2D 기반의 인지 시스템 뿐만 아니라, 현실 환경에서 구조를 표현하고 공간을 분석할 수 있는 기술 역량을 충분히 쌓을 수 있다고 자부할 수 있습니다.
QUESTION 3
필요한
선수지식이 있을까요?
선수지식이 있을까요?
• 컴퓨터 비전의 근간을 이루는 핵심 알고리즘(CNN, Transformer 등)의 이해
• Python
• C++(Visual SLAM Part에서는 SLAM을 이해하기 위한 기초 C++ 강의를 포함합니다.)
• OpenCV (권장이지만 필수는 아닙니다.)
• Python
• C++(Visual SLAM Part에서는 SLAM을 이해하기 위한 기초 C++ 강의를 포함합니다.)
• OpenCV (권장이지만 필수는 아닙니다.)
QUESTION 4
개발 환경
Part 1. 2D Computer Vision & Part 2. 3D Computer Vision
• Python
• Pytorch 프레임워크
• Anaconda
• GPU가 지원되는 PC(최소 3050, Vram의 경우 최소 8gb부터 가능하며,
12gb 정도면 여유롭게 실습 가능합니다.)
• Ubnutu Desktop(Windows 사용자 분들은 WSL2 설치)
Part 3. Multimodal
• GPU가 지원되는 PC (강의 초반부에 CLOUD 기반 GPU 활용 방법이 안내되어 있습니다.)
• Cloud Platform(eg. GCP / 유료)
• Python
Part 4. Visual SLAM
• Ubnutu Desktop
• C++ Compiler
• Python
• Pytorch 프레임워크
• Anaconda
• GPU가 지원되는 PC(최소 3050, Vram의 경우 최소 8gb부터 가능하며,
12gb 정도면 여유롭게 실습 가능합니다.)
• Ubnutu Desktop(Windows 사용자 분들은 WSL2 설치)
Part 3. Multimodal
• GPU가 지원되는 PC (강의 초반부에 CLOUD 기반 GPU 활용 방법이 안내되어 있습니다.)
• Cloud Platform(eg. GCP / 유료)
• Python
Part 4. Visual SLAM
• Ubnutu Desktop
• C++ Compiler