| 프로젝트 소개
HuggingFace에서 도메인 데이터를 수집하고,
SFT 파인튜닝과 정량·정성 평가까지의 기본 흐름을 학습합니다.
HuggingFace에서 도메인 데이터를 수집하고,
SFT 파인튜닝과 정량·정성 평가까지의 기본 흐름을 학습합니다.

도메인 특화 데이터부터 파인튜닝, 추론 전략, 최신 논문까지 — LLM 개발의 전 과정을 한 번에 끝내는 올인원 사이클!

파인튜닝, 한 번 돌려본다고 성능이 오르는 것이 아닙니다.
진짜 내 ‘도메인’에 맞는 LLM을 만들고 싶다면,
다음 세 가지를 스스로 판단할 수 있어야 합니다.
도메인 특화 파인튜닝 성능을 위한 3가지 필수 요소


도메인 특화 LLM을 제대로 만들기 위해선 단순히 모델을 학습시키는 것을 넘어,
데이터 설계, 전략 선택, 반복 개선까지 실전에서 다뤄봐야 합니다.








01. 프로젝트
도메인 파인튜닝의 모든 것
성능 개선 올-사이클 4개 프로젝트



| 프로젝트 사이클 미리보기






| Project 01
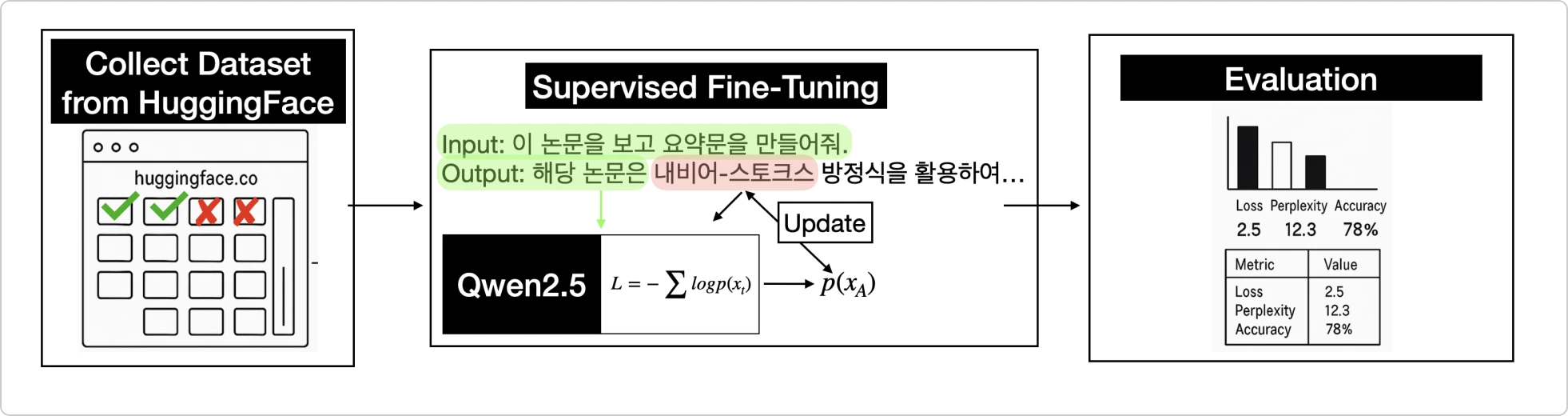
공개 데이터로 시작하는 생성 모델 파인튜닝
| Project 02
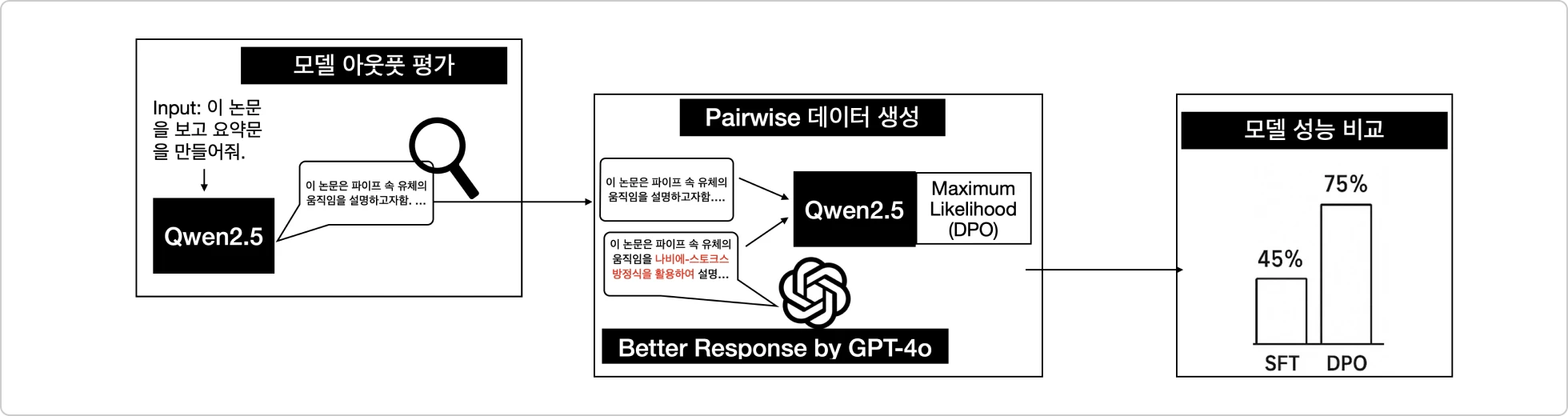
데이터 재설계와 DPO로 성능 끌어올리기

| 프로젝트 사이클 미리보기






| Project 03
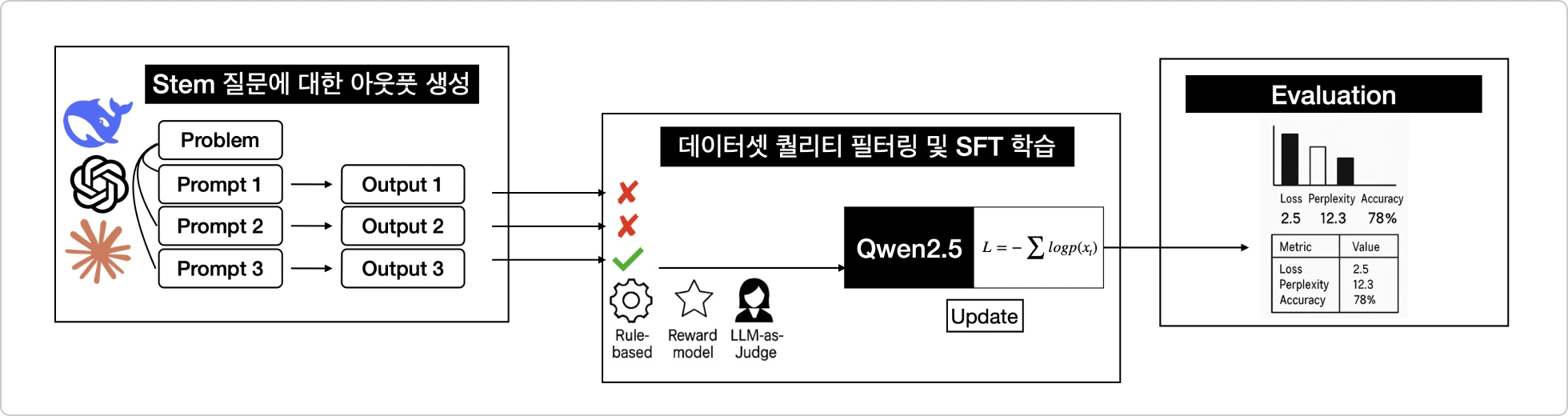
프롬프트 기반 데이터 생성으로 수학·코딩 모델 튜닝하기
| Project 04
추론 최적화를 위한 ORPO 기반 고급 튜닝 실습하기
기간 한정 패키지
도메인 특화 LLM부터 Multi-Agent 자동화까지,
이 두 강의로 한 번에 마스터할 수 있어요!
▼ 지금 패키지로 구매 시 최대 25% 할인 ▼



02. 데이터셋
좋은 성능을 내기 위한 필수 요소
구매자 전원 ‘340만원 상당’ 데이터셋 제공



제대로 만들려면 약 340만 원 드는 학습 데이터셋...
직접 만들기엔 GPU도, 시간도, 비용도 부족하시다구요?
이 강의에서는 그 모든 과정을 단축했습니다.
도메인별 전략에 맞춰 강사님이 직접 구축한 학습용 데이터셋을 그대로 제공합니다.


*해당 데이터셋 직접 학습 시 Batch API MAX 기준으로 산정된 가격입니다.
*25.05 기준 환율 적용된 가격입니다.
*데이터셋은 Hugging Face를 통해 Parquet 형식으로 제공되며, 프로젝트 파트 공개 일정에 맞춰 순차적으로 업로드될 예정입니다.
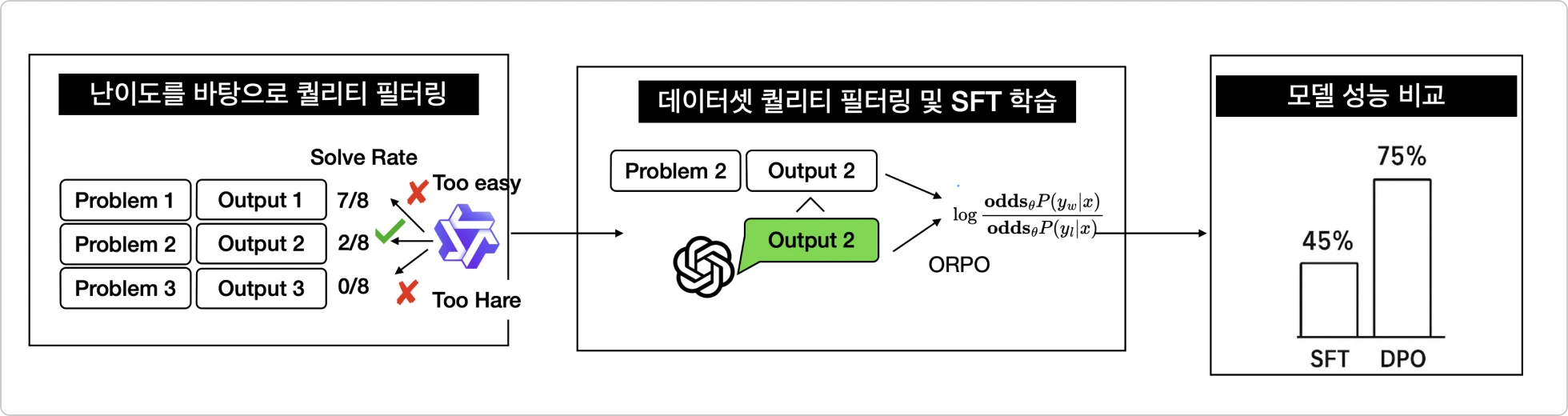
03. 파인튜닝 기법
실전 성능 튜닝에 특화된 효율을 찾아서!
총 11개 전략적 파인튜닝 기법

SFT는 사전 정의된 정답 데이터를 기반으로 모델을 학습시키는 가장 기본적인 파인튜닝 방식
CFT는 모델의 출력을 평가하고 피드백을 반영하여 더 나은 결과를 유도하는 파인튜닝 방식
* 해당 기법들은 프로젝트 및 논문 리뷰를 통해 학습합니다.

11개의 파인튜닝 기법, 우리 강의에서 어떻게 다뤄주나요?


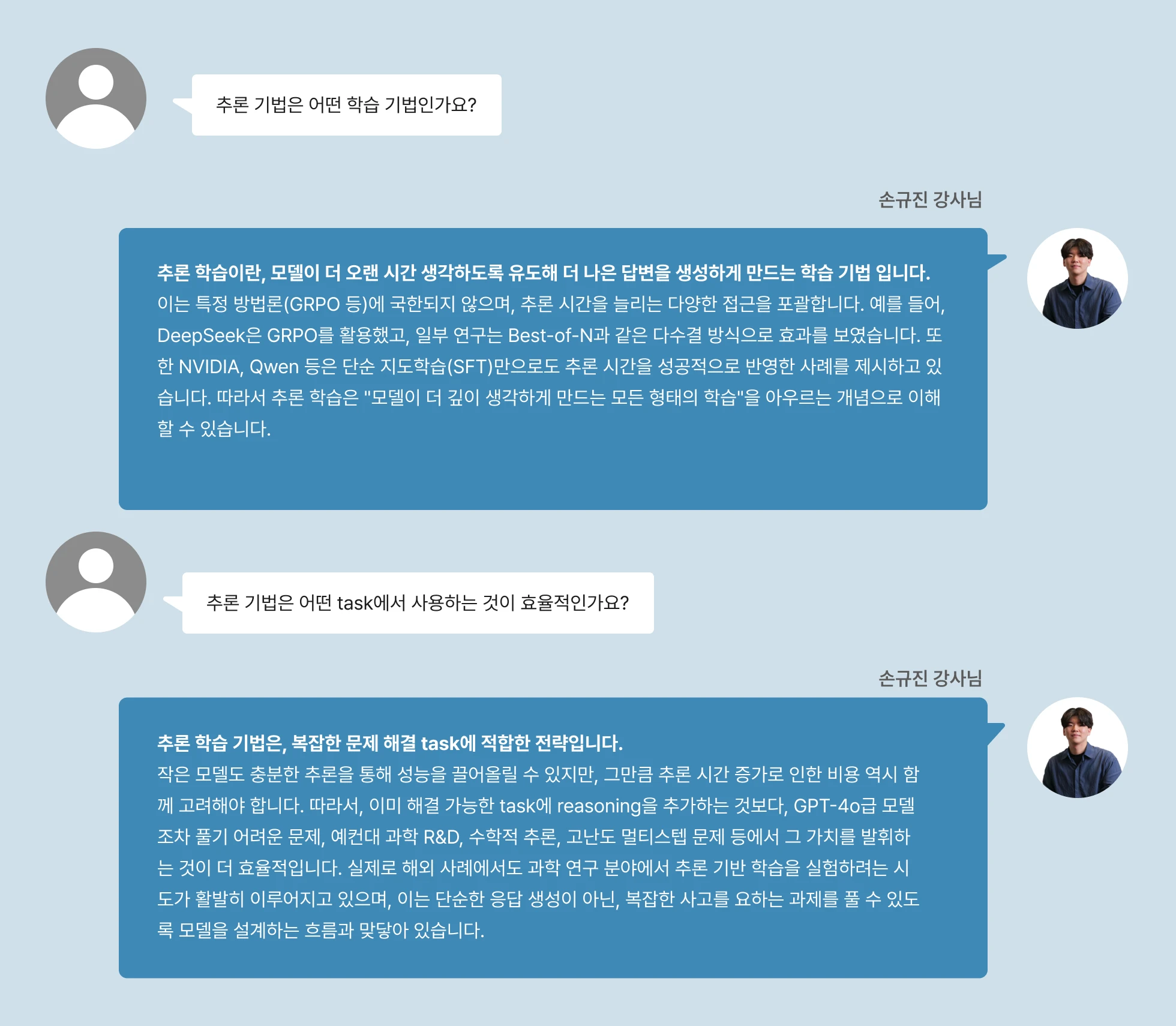
04. 추론 학습
고난이도 문제 해결을 위한 해결사! 그러나 잘못 쓰면 오류가?
도메인 특성에 따른 추론 학습 톺아보기

이 강의에서는 단순히 추론 기법을 따라 하는 것이 아니라,
왜 reasoning이 필요한가 / 어떤 도메인에서 유효한가 / 어떤 경우에는 비효율적인가를 비교·판단하도록 설계되어 있습니다.

추론!
잘 쓰면 정확도와 설득력을 모두 잡고,
잘못 쓰면 혼란과 오류를 유도해요.
그래서 우리 강의에선?

05. 논문 리뷰
LLM 실무와 이론, 모두를 꿰뚫는 논문의 힘!
총 50편+ 의 최신 논문 리뷰






빠르게 바뀌는 LLM 트렌드에 대비할 수 있도록
새롭게 등장하는 최신 논문 리뷰 영상 업데이트

학습 범위를 넘어서 더 깊이 있는 이해를 원하는 분들을 위해
별도 부록으로 엄선된 추천 논문 2편 리뷰가 추가 제공됩니다.
*일부 논문은 강의에 필요한 핵심 내용만 발췌해 다룹니다.
*추가로 업데이트 되는 논문은 25년 6월부터 26년 6월까지, 총 2번 진행됩니다.
이 커리큘럼과 프로젝트를
모두 가르쳐 줄 수 있는 ‘진짜 실력자’ 강사님
06. 강사 소개
Ko-R1-1.5B 모델을 국내 최초 개발한
실전형 LLM 전문가 손규진 강사님


안녕하세요, OneLineAI에서 인공지능 연구를 하고 있는 손규진입니다.
| LLM의 실무 전문가 손규진님의 다양한 강연 활동
![ImageSlide2025 [모두팝] R1 파헤치기, Ko-R1 개발기](https://cdn.day1company.io/prod/uploads/202505/195013-1456/강사소개-04.webp)
![ImageSlide2024 [모두팝] 한국어 언어모델 "잘" 평가하기](https://cdn.day1company.io/prod/uploads/202505/195146-1456/강사소개-05.webp)

실무에서 진짜 인정 받는 실력과 강의력을 모두 갖춘 개발자 손규진님!
AI 분야의 찐 실력자 분들의 추천사를 확인하세요.


07. 특별 혜택
본 강의 수강생 분들께만 드리는 혜택!

* 정리본은 강의 전체 오픈 시 github 형태로 제공됩니다.
* 질의응답은 패스트캠퍼스 커뮤니티에서 진행됩니다. (25.05.26~28.05.25)
QUESTION 1.
QUESTION 2.
QUESTION 3.
QUESTION 4.
커리큘럼
파트 3개클립 76개
패스트캠퍼스 커뮤니티에서 다른 수강생들과 함께 궁금했던 주제에 대해 다양한 관점과 답변을 찾아보세요.
커뮤니티 바로가기학습 규정 및 환불 규정
* 본 상품은 동영상 형태의 강의를 수강하는 상품입니다.
* 상황에 따라 사전 공지 없이 할인이 조기 마감되거나 연장될 수 있습니다.
총 학습기간:
정상 수강기간(유료 수강기간) 최초 30일, 무료 수강 기간은 31일 일차 이후로 무제한이며, 유료 수강기간과 무료 수강기간 모두 동일하게 시청 가능합니다.
본 패키지는 약 19시간 분량으로, 일 1시간 내외의 학습 시간을 통해 정상 수강 기간(=유료 수강 기간) 내에 모두 수강이 가능합니다.
수강시작일: 수강 시작일은 결제일로부터 기간이 산정되며, 결제를 완료하시면 마이페이지를 통해 바로 수강이 가능합니다. (사전 예약 강의는 1차 강의 오픈일)
패스트캠퍼스의 사정으로 수강시작이 늦어진 경우에는 해당 일정 만큼 수강 시작일이 연기됩니다.
일부 강의는 아직 모든 영상이 공개되지 않았습니다. 각 상세페이지 하단에 공개 일정이 안내되어 있습니다.
상황에 따라 사전 공지 없이 할인이 조기 마감되거나 연장될 수 있습니다.
천재지변, 폐업 등 서비스 중단이 불가피한 상황에는 서비스가 종료될 수 있습니다.
본 상품은 기수강생 할인, VIP CLUB 제도 (구 프리미엄 멤버십), 기타 할인 이벤트 적용이 불가할 수 있습니다.
커리큘럼은 제작 과정에서 일부 추가, 삭제 및 변경될 수 있습니다.
쿠폰 적용이나 프로모션 등으로 인해 5만원 이하의 금액으로 강의를 결제할 경우, 할부가 적용되지 않습니다.
환불금액은 정가가 아닌 실제 결제금액을 기준으로 계산됩니다.
쿠폰을 사용하여 강의를 결제하신 후 취소/환불 시 쿠폰은 복구되지 않습니다.
수강시작 후 7일 이내, 5강 미만 수강 시에는 100% 환불 가능합니다.
수강시작 후 7일 이내, 5강 이상 수강 시 전체 강의에서 수강한 강의의 비율에 해당하는 수강료를 차감 후 환불 가능합니다.
수강시작 후 7일 초과 시 정상 수강기간 대비 잔여일에 대해 아래 환불규정에 따라 환불 가능합니다.
환불요청일 시 기준
: 수강시작 후 1/3 경과 전, 실 결제금액의 2/3에 해당하는 금액 환불
: 수강시작 후 1/2 경과 전, 실 결제금액의 1/2에 해당하는 금액 환불
: 수강시작 후 1/2 경과 후, 환불 금액 없음
* 보다 자세한 환불 규정은 홈페이지 취소/환불 정책에서 확인 가능합니다.
[패스트캠퍼스 아이디 공유 금지 정책]
패스트캠퍼스의 모든 온라인 강의에서는 1개의 아이디로 여러명이 공유하는 형태를 금지하고 있습니다.
동시접속에 대한 기록은 내부 시스템을 통해 자동으로 누적되며, 이후 서비스 이용이 제한될 수 있습니다.
[기기제한 정책]
패스트캠퍼스 온라인 강의 시청을 위해서는 ID별 최대 4개의 기기를 등록할 수 있으며, 기기 등록은 온라인 강의장 접속 시 자동 등록됩니다.
최대 갯수를 초과하였을 경우 등록된 기기 해제가 필요합니다.
[저작권 정책]
패스트캠퍼스의 모든 강의는 무단 배포 및 가공하는 행위, 캡쳐 및 녹화하여 공유하는 행위, 무단으로 판매하는 행위 등 일체의 저작권 침해 행위를 금지합니다.
부정 사용이 적발될 경우 저작권법 위반에 의한 법적인 제재를 받으실 수 있습니다.
국내 7개 카드사 12개월 무이자 할부 지원! (간편 결제 제외)