1. Orientation
2. Stat & Geo Perspective for Deep Learning
3. Review: Introduction to NLP
4. 자연어 생성이란?
올인원 패키지 : 김기현의 딥러닝을 활용한 자연어생성 (끝장 패키지 포함)

코스 프로모션 배너 전용입니다.
0일
0시간
0분
0초
코스 프로모션 배너 전용입니다.
자연어처리 전문가 김기현 강사님과 함께하는
국내 유일 자연어생성 중심 커리큘럼!
seq2seq, Transformer, 기계번역 등 HOT한 주제 다-모았다!
최신 자연어생성(NLG)의 핵심 및 응용을 확실하게 배워가세요!
딥러닝 자연어생성은 관련 분야 경력 10년의
데이터 사이언티스트와 함께 마스터해봐요.

한눈에 보는 강사님 포트폴리오.

11번가 글로벌 기계번역 시스템

자동 통역기 지니톡

로봇팔 이상탐지 시스템

이커머스 추천 시스템
딥러닝을 활용한 통번역기 연구/개발
한국전자통신연구원(ETRI) 자동통역기 연구/개발 (2011~2015)
- 음성인식을 위한 언어모델 연구
- 언어모델 구축을 위한 데이터 수집 및 전처리
SK플래닛 기계번역시스템 연구/개발 (2017~2018)
- PyTorch를 활용하여 신경망 기계번역 시스템 자체 개발 및 상용화
- 11번가 글로벌 사이트에 배포 및 서비스
이커머스 추천 시스템 연구/개발
티켓몬스터 추천시스템 연구/개발 (2016~2017)
- 딥러닝을 활용한 대체재, 보완재 추천 시스템 연구/개발 및 적용 배포
이상탐지 시스템 연구/개발
마키나락스 이상탐지 시스템 연구/개발 (2018~)
- Operational AI: 지속적으로 학습하는 Anomaly Detection 시스템 만들기 NAVER DEVIEW 2019
- RaPP: Novelty Detection with Reconstruction along Projection Pathway ICLR 2020 Poster
지금 이 강의를 들으면,
자연어처리 전문가와 함께
직접 기계 번역기를 만들 수 있습니다!
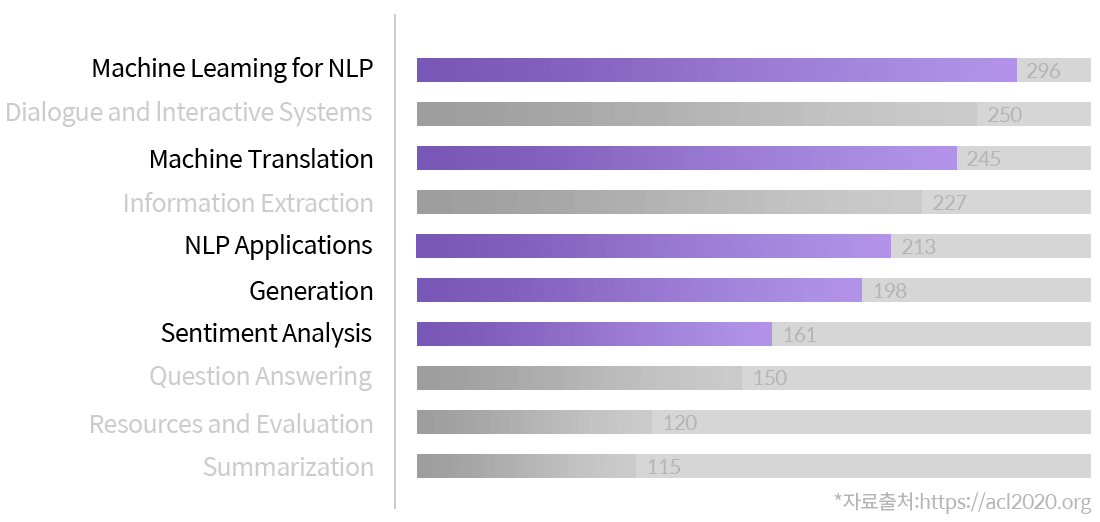
매년 3,000개가 넘는 논문이 쓰여지며
빠르게 발전하고 있는 자연어처리 분야!
올해 국제전산언어협회(ACL)에서 개최하는 컨퍼런스 ACL2020에
가장 많이 제출된 논문 주제 TOP 10은 아래와 같습니다.

본 강의는 자연어처리 기술을 온전히
활용하기 위한 High-Level 커리큘럼으로
자연어생성과 자연어처리 심화 개념에 대한
전반적인 내용을 학습하실 수 있습니다.
Seq2seq* 모델에 대한 깊이 있는 학습
자연어처리 정점 및 핵심 기술인 seq2seq에 대한 이론과 Machine Translation 와 같은 실습을 통해 자연어생성에 대해 학습합니다.
언어모델(LM*) 에 대한 이해
기계번역과 음성인식, OCR, 그리고 자연어생성에 중요한 역할을 하는 LM에 대해 학습합니다. 이는 챗봇과 같은 선진기술의 바탕이 됩니다.
BERT의 핵심 기술, Transformer에 대한 학습
BERT는 활용도가 높은 사전 훈련 기반 딥러닝 언어모델입니다. BERT모델의 기반이 된 Transformer에 대한 심도 있는 이론 및 실습을 진행합니다.
대학원 수준의 자연어생성 성능 극대화
단순히 모델을 활용하는 것이 아닌, 강화학습&듀얼러닝 등을 활용하여 기계번역과 자연어생성의 성능을 극한으로 끌어올리기 위한 이론과 실습을 모두 수행합니다.
*seq2seq : Sequence to Sequence의 약칭
* LM : Language Modeling의 약칭

실습 포함 모든 수업은
PyTorch로 진행합니다!
이런 생각, 한 번쯤 해봤다면?
바로 당신을 위한 강의입니다!
자연어처리를 기계번역, AI Core에 응용하고 싶다!
챗봇 개발을 위해 문장요약/생성, 문서의미파악 등 기술을 배우고 싶다!
빠른 속도로 발전하는 자연어처리의 최신 연구 동향을 알고싶다!
Text generation, 강화학습을 적용한 자연어생성 등 심화 내용을 알고싶다!
자연어처리 분야 경력 10년 전문가의
노하우를 담은 NLG 실무 프로젝트
본 강의 수강 후 우리는?

자연어처리에서 최신 딥러닝 기술인 seq2seq 이해를 바탕으로
복잡한 architecture를 구현할 수 있는 역량을 갖춥니다.
복잡한 architecture를 구현할 수 있는 역량을 갖춥니다.

강화학습과 듀얼러닝을 바탕으로 자연어생성 성능을 향상시키는 방법을 이해합니다.

실전 수준의 기계 번역 프로그램을 직접 만들어볼 수 있습니다.
최신 기술 동향을 모두 담은
알짜배기 커리큘럼.
01. Orientation
자연어생성 클래스를 소개합니다.
02. Language Modeling
자연어생성의 기본 of 기본, 언어모델
1. 들어가며
2. 언어모델 수식
3. n-gram
4. Smoothong and Discounting
5. Interpolation and Backoff
6. Perplexity
7. n-gram 정리
8. RNN을 활용한 LM
9. Perplexity and Cross Entropy
10. Autoregressive and Teacher Forcing
11. 정리하며
2. 언어모델 수식
3. n-gram
4. Smoothong and Discounting
5. Interpolation and Backoff
6. Perplexity
7. n-gram 정리
8. RNN을 활용한 LM
9. Perplexity and Cross Entropy
10. Autoregressive and Teacher Forcing
11. 정리하며
03. Data Preparation
기계번역을 위한 데이터 준비
1. AI-Hub 소개
2. 실습: 번역 말뭉치 신청 및 다운로드
3. 실습: 데이터 살펴보기
4. Review: Preprocessing
5. 실습: Tokenization
6. 실습: Subword Segmentaion
2. 실습: 번역 말뭉치 신청 및 다운로드
3. 실습: 데이터 살펴보기
4. Review: Preprocessing
5. 실습: Tokenization
6. 실습: Subword Segmentaion
04. Sequence-to-Sequence
자연어생성의 꽃, 기계번역
1. Machine Translation 소개
2. Sequence to Sequence
3. Encoder
4. Decoder
5. Generator
6. Attention
7. Masking
8. Input Feeding
9. Teacher Forcing
10. 실습: 실습 소개
11. 실습: Encoder 구현하기
12. 실습: Attention 구현하기
13. 실습: Decoder 구현하기
14. 실습: Generator 구현하기
15. 실습: 각 모듈 통합하여 구현하기
16. Appendix: Gradient Accumulations
17. Appendix: Automatic Mixed Precision
18. 실습: Trainer 구현하기
19. 실습: Data Loader 구현하기
20. 실습: train.py 구현하기
21. 실습: continue_train.py 구현하기
22. 정리하며
2. Sequence to Sequence
3. Encoder
4. Decoder
5. Generator
6. Attention
7. Masking
8. Input Feeding
9. Teacher Forcing
10. 실습: 실습 소개
11. 실습: Encoder 구현하기
12. 실습: Attention 구현하기
13. 실습: Decoder 구현하기
14. 실습: Generator 구현하기
15. 실습: 각 모듈 통합하여 구현하기
16. Appendix: Gradient Accumulations
17. Appendix: Automatic Mixed Precision
18. 실습: Trainer 구현하기
19. 실습: Data Loader 구현하기
20. 실습: train.py 구현하기
21. 실습: continue_train.py 구현하기
22. 정리하며
05. Evaluations
자연어생성의 추론방법
1. 들어가며
2. Greedy & Sampling
3. Length & Coverage Penalty
4. 실습: 실습 소개
5. 실습: 추론 코드 작성하기
6. 실습: translate.py 구현하기
7. 실습: 결과 확인
8. 정리하며
2. Greedy & Sampling
3. Length & Coverage Penalty
4. 실습: 실습 소개
5. 실습: 추론 코드 작성하기
6. 실습: translate.py 구현하기
7. 실습: 결과 확인
8. 정리하며
06. Evaluations
자연어생성 모델 평가 방법 소개 및 실무경험 공유
1. 들어가며
2. Perplexity and BLEU
3. TIP: 프로젝트 경험담
4. 실습: BLEU 구하는 방법
5. 정리하며
2. Perplexity and BLEU
3. TIP: 프로젝트 경험담
4. 실습: BLEU 구하는 방법
5. 정리하며
07. Beam Search
과거의 차선이 현재의 최선이 된다고?! Beam-Search 알고리즘
1. Introduction
2. Beam Search 소개
3. 실습: 실습 소개
4. 실습: Beam Search 함수 구현
5. 실습: 결과 확인
6. 정리하며
2. Beam Search 소개
3. 실습: 실습 소개
4. 실습: Beam Search 함수 구현
5. 실습: 결과 확인
6. 정리하며
08. Transformer
딥러닝 자연어처리의 대표주자, Transformer
1. Transformer 소개
2. Multi-head Attention
3. Encoder
4. Decoder with Masking
5. Positional Encoding
6. Learning rate warm-up and linear decay
7. Appendix: Beyond the paper
8. 실습: 실습 소개
9. 실습: Multi-head Attention 구현하기
10. 실습: Encoder Block 구현하기
11. 실습: Decoder Block 구현하기
12. 실습: Transformer Class 구현하기
13. 실습: train.py & Trainer 구현하기
14. 실습: Search 함수 구현하기
15. 실습: Beam Search 리뷰
16. 실습: Beam Search 함수 구현하기
17. 실습: 결과 확인
18. 정리하며
2. Multi-head Attention
3. Encoder
4. Decoder with Masking
5. Positional Encoding
6. Learning rate warm-up and linear decay
7. Appendix: Beyond the paper
8. 실습: 실습 소개
9. 실습: Multi-head Attention 구현하기
10. 실습: Encoder Block 구현하기
11. 실습: Decoder Block 구현하기
12. 실습: Transformer Class 구현하기
13. 실습: train.py & Trainer 구현하기
14. 실습: Search 함수 구현하기
15. 실습: Beam Search 리뷰
16. 실습: Beam Search 함수 구현하기
17. 실습: 결과 확인
18. 정리하며
09. Advanced Topics on NLG
모델성능 극대화를 위한 다양한 방법 소개
1. Introduction
2. Mutilingual Machine Translation
3. Language Model Ensemble
4. Back Translation
5. Motivations for RL in NLG
6. RL Introduction
7. Policy Gradients
8. Minimum Risk Training (MRT)
9. TIP: 이 섹션에서 얻어갔으면 하는 것
10. 실습: 실습 소개
11. 실습: rl_trainer.py 구현하기
12. 실습: Reward 함수 구현하기
13. 실습: loss 구현하기
14. 실습: train.py 마저 구현하기
15. 실습: 결과 확인
16. 정리하며
2. Mutilingual Machine Translation
3. Language Model Ensemble
4. Back Translation
5. Motivations for RL in NLG
6. RL Introduction
7. Policy Gradients
8. Minimum Risk Training (MRT)
9. TIP: 이 섹션에서 얻어갔으면 하는 것
10. 실습: 실습 소개
11. 실습: rl_trainer.py 구현하기
12. 실습: Reward 함수 구현하기
13. 실습: loss 구현하기
14. 실습: train.py 마저 구현하기
15. 실습: 결과 확인
16. 정리하며
10. Advanced Machine Translations
병렬 코퍼스 학습 문제에서 성능 극대화를 위한 다양한 방법 소개
1. Dual Learning이란?
2. Dual Supervised Learning (DSL)
3. 실습: 실습 소개
4. 실습: LM 구현하기
5. 실습: LM Trainer 구현하기
6. 실습: Dual Learning Trainer 구현하기
7. 실습: loss 구현하기
8. 실습: dual_train.py 구현하기
9. 실습: translate.py 추가 구현하기
10. 실습: 결과 확인
11. Dual Learning for Machine Translation
12. Dual Unsupervised Learning (DUL)
13. Back Translation Review
14. 정리하며
2. Dual Supervised Learning (DSL)
3. 실습: 실습 소개
4. 실습: LM 구현하기
5. 실습: LM Trainer 구현하기
6. 실습: Dual Learning Trainer 구현하기
7. 실습: loss 구현하기
8. 실습: dual_train.py 구현하기
9. 실습: translate.py 추가 구현하기
10. 실습: 결과 확인
11. Dual Learning for Machine Translation
12. Dual Unsupervised Learning (DUL)
13. Back Translation Review
14. 정리하며
11. Summary
강의 마무리
1. Summary
-
상세 커리큘럼.
자세한 커리큘럼 및 내용은 여기서 확인하세요!
강의 미리 엿보기👀
코스 프로모션 배너 전용입니다.
0일
0시간
0분
0초
코스 프로모션 배너 전용입니다.

지금 보고 있는 자연어처리 입문 강의만 구매하고 싶다면?👇
(자동)
자연어생성의 A-Z.
패스트캠퍼스에서 시작하세요!

잠깐! 수강 신청 전 Check List!
✅CNN, RNN을 활용하여 Text Categorization, Sentiment Analysis를 할 수 있다.
✅PyTorch를 활용한 Text Classification를 할 수 있다.
✅LSTM과 GRU 사이의 차이점과 기존 RNN과의 차이점을 말할 수 있다.
🙋♂️Check List에 모두 'YES!' 라고 대답할 수 있다면 본 강의를 수강하셔도 좋습니다.
그렇지 않다면 김기현의 딥러닝을 활용한 자연어처리 입문 올인원패키지를 먼저 수강해주세요!
데이터 사이언티스트가 되기 위해 필요한 역량.
어떻게 갖춰야 하는지 몰라서 힘드셨나요?
데이터 사이언스 교육의 명가, 패스트캠퍼스에서는 고민하지 않으셔도 됩니다.
여러분은 방향만 정하세요, 커리어 로드맵은 저희가 준비할께요!
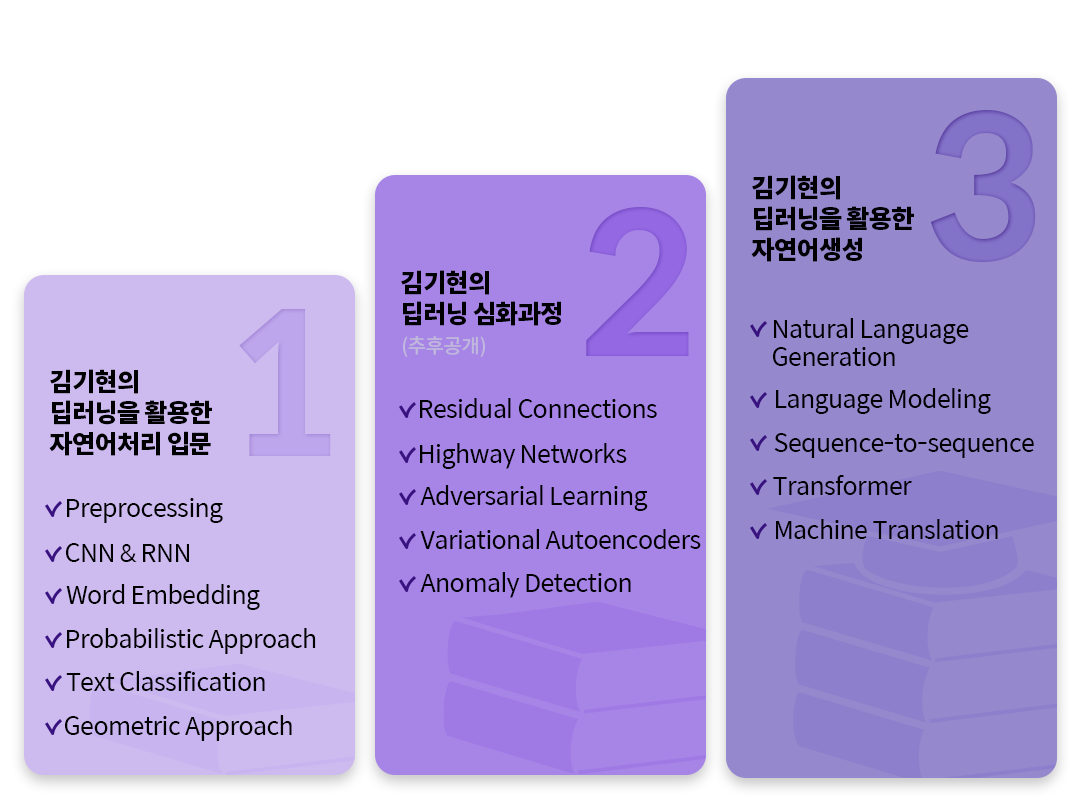
딥러닝 자연어생성 공부는
패스트캠퍼스와 함께하세요.
결제 후, 언제 어디서나 하루 10분 공부 시작.



탄탄한 커리큘럼 구성.
전문지식을 쌓으실 수 있도록 더욱 촘촘하게 구성하였습니다.

실무 활용도 100%.
이론뿐만 아니라 실습도 병행하므로 내 업무에 활용할 수 있습니다.

원하는 장소 어디서나.
원하는 장소에서 원하는 시간에 공부해보세요.
내가 마음먹은 곳 어디든 나만의 강의장이 됩니다.

무제한으로 반복 학습.
이해가 잘 되지 않는 내용도 몇 번이고 반복 재생하여 학습할 수 있습니다.
믿고 배울 수 있는 패스트캠퍼스!
여러분의 실무 스킬 성장을 책임집니다.

실무 교육 분야를 선도하다.
패스트캠퍼스는 2014년부터 현재까지 실무에 꼭 필요한 내용만 강의하고 있습니다.


오프라인의 노하우를 온라인으로 담았다.
오프라인 강의로 쌓은 모든 노하우를 담아서 2018년에 첫 온라인 강의를 만들었습니다.


많은 분들과 성장한 온라인 강의.
예비 직장인부터 단체 수강까지 많은 분들이 자신의 성장을 위해 투자하고 있습니다.


최신 트렌드를 반영한 올인원 패키지.
입문자부터 실무에 필요한 스킬셋까지 꼼꼼하게 채워줄 수 있도록 현직자들의 실무 노하우를 온라인으로 담았습니다.
다양한 강의를 통해 내 실력을 쌓아보세요.
코스 프로모션 배너 전용입니다.
0일
0시간
0분
0초
코스 프로모션 배너 전용입니다.
(자동)
