| 프로젝트 실습 개요
• 활용하는 모델 : beomi/Llama-3-Open-Ko-8B
• Fine-Tuning 방법론 : QLoRA(Single GPU 환경에서 제일 최적화 된 방법론)
• Data : Ko-Optimize Dataset
[번들용] LLM 모델 파인튜닝을 위한 GPU 최적화

ONLINE #GPU #NVIDIA #LLM 모델 파인튜닝 #LLM 모델 추론 #PEFT #메모리 최적화
LLM 모델 파인튜닝을 위한 GPU 최적화
LLM 모델을 활용하여 AI 서비스를 개발하면서 발생하는 대표 2가지 병목인 모델 학습 시 Fine-Tuning에서 발생하는 메모리 리소스 제약,
Inference를 할 때 발생하는 Latency 증가 문제를 해결해줄 수 있는 GPU 최적화 강의
 기본 정보
기본 정보
ㅤGPU 최적화 강의
• LLM 모델을 활용한 서비스의 핵심인 GPU 자원을
ㅤ다룰 수 있는 방법을 알려주는 강의
 강의 특징
강의 특징
LLM 모델 파인튜닝을 위한 GPU 최적화
* 특별 구성 묶음 상품의 경우 1+1이나 페이백, 쿠폰 등의 이벤트/프로모션과 중복 혜택 적용이 불가합니다.
AI/LLM 서비스 개발 시 발생하는 대표적인 병목 현상
이들의 공통점은?

목적에 맞는 AI/LLM 서비스를 개발하면서 고려해야 할 Fine-Tuning과 Inference를 효과적으로
수행하기 위한 GPU 최적화가 최근 AI/LLM 서비스 개발의 핵심 요소로 고려되고 있습니다.
글로벌 IT 빅테크 기업들의
AI/LLM 서비스 개발을 위한 GPU 최적화 트렌드
이미 글로벌 IT 빅테크 기업들은 맞춤형 AI/LLM 서비스를 위한 자체 GPU 생태계 개발에
박차를 가하며 본격적으로 GPU 생산 및 개발에 뛰어들고 있습니다.



그러나
기업들은 AI/LLM 서비스를 개발하면서
GPU 리소스 부족 문제를 겪고 있습니다.



출처 - 2024년 AI 인프라 현황 : 미래 전망, 주요 통찰력 및 비즈니스 벤치마크 공개 설문조사
그래서!
패스트캠퍼스와 이승유 개발자가 뭉쳤습니다!
Open Ko-LLM LedaderBoard에서 최장기간 성능 1위 모델 개발!
GPU 최적화 전문가 이승유의 LLM 모델 파인튜닝을 위한 GPU 최적화

AI/LLM 서비스를 개발하면서 모델 파인튜닝 과정에서
GPU 최적화가 필요한 이유는 무엇인가요?


AI/LLM 업계 전문가들이 인정하는
이승유 개발자에게 배우는 LLM 모델 파인튜닝을 위한 GPU 최적화


맞춤형 LLM 서비스 개발 과정에서 발생하는 가장 큰 병목, GPU 최적화를
해결하기 위해 이승유 개발자가 준비한 8가지 스폐셜 포인트!

강의 미리보기
아직 고민 중이신가요?
강의를 미리 보고 결정하세요!👇
POINT 1
GPU의 기초 개념을 이해하기 위한 LLM
GPU를 활용하여 LLM을 학습하는 이유와 Transformer의 Decoder 성능 증가 원리,
모델 크기가 커지면서 다량의 GPU 메모리가 필요함에 따른 효율적 관리 방법을 학습합니다.

GPU의 기초 개념을
이해하기 위한 LLM
이해하기 위한 LLM
ㆍ파라미터가 증가하면서 특정 Task에서 Fine-Tuning 시 성능이 크게 늘어나는 Transformer의 원리 이해
ㆍ큰 파라미터와 복잡한 연산을 풀기 위한 GPU 특징 학습
ㆍ대규모 병렬 & 행렬 연산 처리에 특화되어 LLM 학습 및 추론에 적합한 GPU 특징 학습
ㆍ큰 파라미터와 복잡한 연산을 풀기 위한 GPU 특징 학습
ㆍ대규모 병렬 & 행렬 연산 처리에 특화되어 LLM 학습 및 추론에 적합한 GPU 특징 학습

GPU와 CPU의 차이점
ㅤ
ㅤ
ㆍ그래픽 처리와 병렬 연산에 특화된 GPU와 범용적인 계산에 최적화 된 CPU 특징 학습
ㆍ여러 개의 코어로 병렬 처리를 하는 GPU와소수의 코어로 복잡한 연산을 수행하는 CPU 특징 학습
ㆍ각 독립적인 연산 유닛(ALU)로 구성 된 GPU의 빠른 데이터 접근과 대규모 데이터 처리 방법 원리의 이해 학습
ㆍ여러 개의 코어로 병렬 처리를 하는 GPU와소수의 코어로 복잡한 연산을 수행하는 CPU 특징 학습
ㆍ각 독립적인 연산 유닛(ALU)로 구성 된 GPU의 빠른 데이터 접근과 대규모 데이터 처리 방법 원리의 이해 학습

AI 연산의 90% 이상에
활용되는 NVIDIA GPU
활용되는 NVIDIA GPU
ㆍNVIDIA기 개발한 병렬 컴퓨팅 플랫폼 CUDA의 특징 학습
ㆍNVIDIA의 GPU와 CUDA 플랫폼을 활용한 LLM의 방대한 데이터 처리 및 연산 방법 학습
ㆍLocal & Cloud 환경에서 NVIDIA GPU 플랫폼을 활용한 다양한 서비스 개발 사례 학습
ㆍNVIDIA의 GPU와 CUDA 플랫폼을 활용한 LLM의 방대한 데이터 처리 및 연산 방법 학습
ㆍLocal & Cloud 환경에서 NVIDIA GPU 플랫폼을 활용한 다양한 서비스 개발 사례 학습

Local & Cloud 환경에서
GPU 선택
GPU 선택
ㆍLocal GPU : 직접 하드웨어를 설치하여 사용하며, 높은 제어권과 성능을 제공하나 초기 비용이 높고 제한적인 확장성의 특징을 보여주고 있는 Local GPU 학습
ㆍCloud GPU : 클라우드 서비스 제공업체가 원격 데이터 센터에 설치한 GPU를 임대하며, 초기 비용 없이 유연한 자원 확장과 최신 하드웨어 접근이 가능하나 자원 관리와 데이터 보안 통제력이 상대적으로 낮은 Cloud GPU 학습
ㆍCloud GPU : 클라우드 서비스 제공업체가 원격 데이터 센터에 설치한 GPU를 임대하며, 초기 비용 없이 유연한 자원 확장과 최신 하드웨어 접근이 가능하나 자원 관리와 데이터 보안 통제력이 상대적으로 낮은 Cloud GPU 학습

내 상황에 맞는 적절한
GPU를 선택하는 기준은?
GPU를 선택하는 기준은?
ㆍ기획하고자 하는 서비스의 종류
ㆍ높은 연산 능력과 CUDA 코어 수
ㆍ충분한 VRAM 용량
ㆍ다수의 GPU를 클러스터링 할 수 있는 확장성과 효율성
ㆍ효율적인 전력 소비와 발열 관리 능력
ㆍ가격 대비 성능을 고려하여 선택하는 방법 학습
ㆍ높은 연산 능력과 CUDA 코어 수
ㆍ충분한 VRAM 용량
ㆍ다수의 GPU를 클러스터링 할 수 있는 확장성과 효율성
ㆍ효율적인 전력 소비와 발열 관리 능력
ㆍ가격 대비 성능을 고려하여 선택하는 방법 학습

Local GPU와 Cloud GPU 환경 간 차이점을 이해하고
개발하고자 하는 LLM 서비스에 맞는 GPU를 선택하는 방법을 학습합니다.

POINT 2
Single-GPU 환경에서 GPU 최적화 기법 학습
QLoRA, PEFT 등의 방법을 활용하여 Single GPU 환경에서
LLM 모델을 학습하면서 메모리를 절약하는 방법을 배웁니다.


Single GPU 환경에서 가장 높은 성능을 발휘하는 PEFT 노하우 학습!

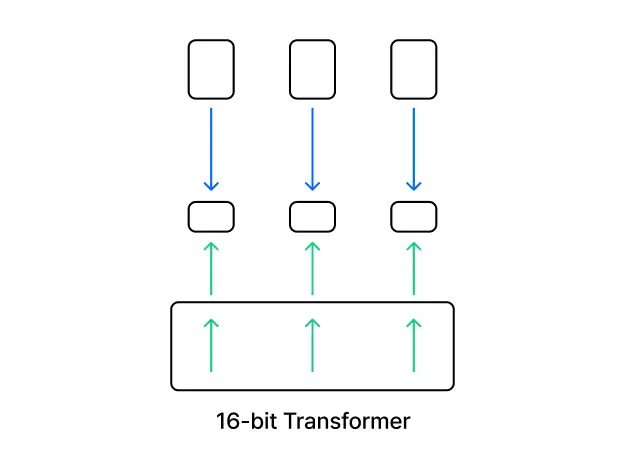
1. LoRA
(Low-Rank Adaptation)
(Low-Rank Adaptation)
ㆍ모델의 파라미터 공간을 저차원 공간으로 투영하여 Fine-Tuning하는 기법입니다.
ㆍ모델의 파라미터를 변경하지 않고 저차원 공간에서 추가된 파라미터를 학습하여 효율성을 높이는 방법을 학습합니다.
ㆍ모델의 파라미터를 변경하지 않고 저차원 공간에서 추가된 파라미터를 학습하여 효율성을 높이는 방법을 학습합니다.
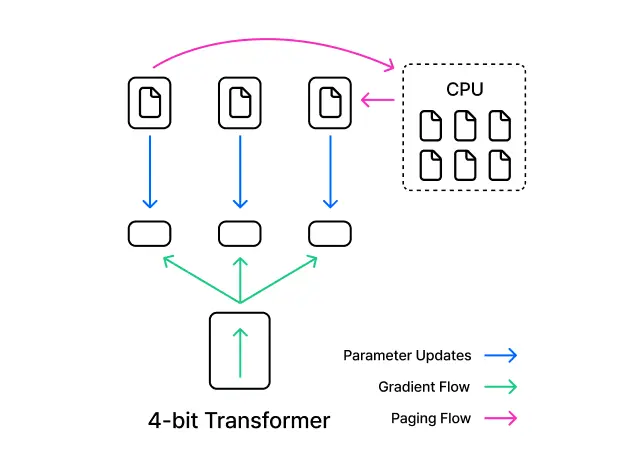
2. QLoRA
(Quantized Low-Rank Adaptation)
(Quantized Low-Rank Adaptation)
ㆍLoRA를 적용할 모델의 파라미터를 양자화하여 메모리 사용과 계산 성능을 개선하는 방법을 학습합니다.
ㆍ큰 모델을 활용하면서 제한된 리소스 환경에서 특히 가장 많이 활용되는 GPU 최적화 기법으로 활용되고 있습니다.
ㆍ큰 모델을 활용하면서 제한된 리소스 환경에서 특히 가장 많이 활용되는 GPU 최적화 기법으로 활용되고 있습니다.
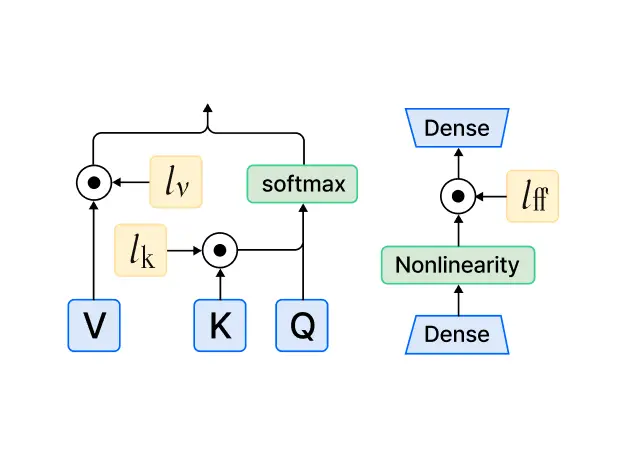
3. IA3 (Infused Adapter by Inhibiting &
Amplifying Inner Activations)
Amplifying Inner Activations)
ㆍ모델의 내부 활성화 값을 조절하여 특정 부분을 억제하거나 증폭시키는 방법을 학습합니다.
ㆍ모델의 기존 구조를 크게 변경하지 않고도 성능을 향상시키기 위해 고안되었으며, 특정 레이어 & 노드에 rescale 해주는 벡터를 추가합니다.
ㆍ모델의 기존 구조를 크게 변경하지 않고도 성능을 향상시키기 위해 고안되었으며, 특정 레이어 & 노드에 rescale 해주는 벡터를 추가합니다.
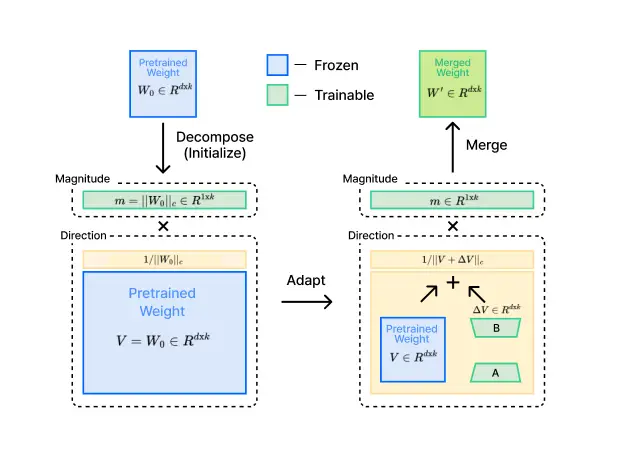
4. DoRA (Weight-Decomposed Low-
Rank Adaptation)
Rank Adaptation)
ㆍ학습된 모델의 가중치를 크기와 방향으로 분해하여, 방향 성분에 대한 LoRA 방식을 적용하는 방법을 학습합니다 .
ㆍ학습 가능한 파라미터 수를 최소화하면서 모델의 정확도를 유지하거나 개선하는 데 중점을 두는 기법입니다.
ㆍ학습 가능한 파라미터 수를 최소화하면서 모델의 정확도를 유지하거나 개선하는 데 중점을 두는 기법입니다.
5. MoRA
(Model Order Reduction Adaptation)
(Model Order Reduction Adaptation)
ㆍ정방 행렬을 사용하여 더 높은 순위의 파라미터를 업데이트 가능하게 하는 방법을 학습합니다.
ㆍ특히 수학적 추론이나 지속적인 사전 학습이 필요한 복잡한 작업에서 뛰어난 성능을 발휘합니다.
ㆍ특히 수학적 추론이나 지속적인 사전 학습이 필요한 복잡한 작업에서 뛰어난 성능을 발휘합니다.

Middle Project 1 >>
Single GPU 환경에서 GPU 최적화로 LLM 모델 Fine-Tuning을 위한 QLora Fine-Tuning 프로젝트 실습
Single GPU(제한된) 환경에서 가장 높은 모델 성능을 낼 수 있는 QLoRA 기법을 활용하여
GPU를 최적화할 수 있는 LLM 모델 Fine-Tuning 실습을 진행합니다.
| 학습 포인트
• Single GPU, 즉 리소스가 명확하게 제한된 환경에서 Fine-Tuning을 진행하기 위한 Optimizer, Batch Size, Tensor Type, Length 등 주요 요소를 고려하여 하이퍼파라미터 최적화 방법을 학습합니다.
• LLM 모델에서 Single GPU를 활용한 연산 과정을 거칠 때, 다량의 연산량으로 인해 모델의 속도가 느려질 수 있기에 모델의 Input/Output 통로에서 연산량을 최소화하는 Flash Attention 기법을 학습합니다.
• Single GPU, 즉 리소스가 명확하게 제한된 환경에서 Fine-Tuning을 진행하기 위한 Optimizer, Batch Size, Tensor Type, Length 등 주요 요소를 고려하여 하이퍼파라미터 최적화 방법을 학습합니다.
• LLM 모델에서 Single GPU를 활용한 연산 과정을 거칠 때, 다량의 연산량으로 인해 모델의 속도가 느려질 수 있기에 모델의 Input/Output 통로에서 연산량을 최소화하는 Flash Attention 기법을 학습합니다.
| 프로젝트 실습 과정

POINT 3
Multi-GPU 환경에서 GPU 최적화 기법 학습
LLM 모델의 크기가 커지고, 데이터의 양이 방대해지면서 제한된 하드웨어에 맞추거나 학습 시간을
단축하기 위한 여러 GPU 환경에서 LLM 모델을 학습할 수 있는 분산 학습 방법을 학습합니다.

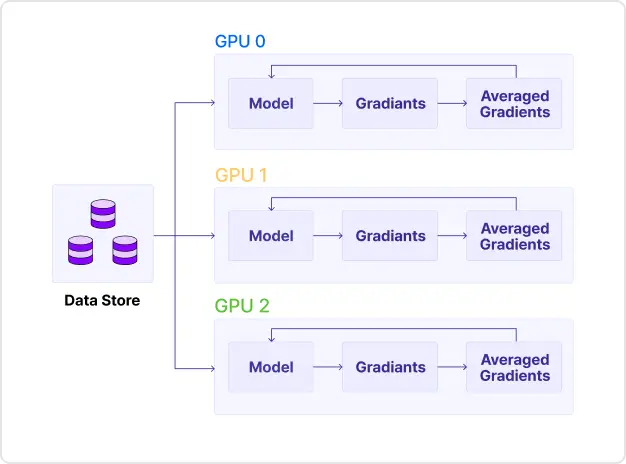
01
Data Parallel
ㆍLLM 모델을 동일하게 복사하여 여러 GPU에 분배하고, 각 GPU에서 입력 데이터의 서로 다른 배치를 처리하는 방법을 학습합니다.
ㆍGPU의 독립적인 forward와 backward를 수행하고 Gradient를 합쳐 모델의 가중치를 업데이트 하는 방법을 학습합니다.
ㆍGPU의 독립적인 forward와 backward를 수행하고 Gradient를 합쳐 모델의 가중치를 업데이트 하는 방법을 학습합니다.
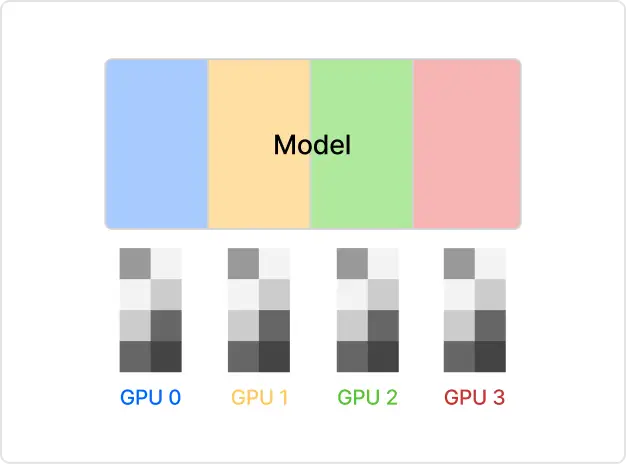
02
Model Parallel 기법 (1) Tensor Parallel
ㆍ개별 행렬 연산을 여러 장치에 분할하여 각 장치가 동시에 계산을 수행하도록 하는 방법을 학습합니다.
ㆍ모델의 각 Layer를 분할하여 GPU가 부분적으로 연산을 수행 후 GPU 별 연산 결과를 합쳐 연산을 완료하는 방법을 학습합니다.
ㆍ모델의 각 Layer를 분할하여 GPU가 부분적으로 연산을 수행 후 GPU 별 연산 결과를 합쳐 연산을 완료하는 방법을 학습합니다.
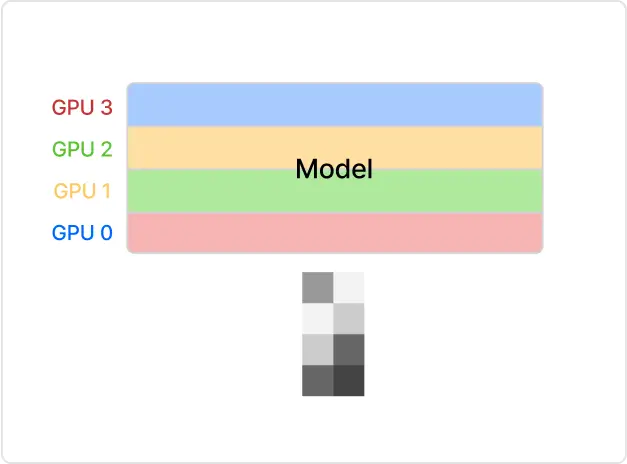
03
Model Parallel 기법 (2) Pipeline Parallel
ㆍ모델의 연산을 여러 GPU에 걸쳐 파이프라인로
분할하여 각 GPU가 LLM 모델의 특정 Layer를 처리하고 다음 GPU로 출력을 전달하는 방법을 학습합니다.
ㆍ모델의 각 단계가 병렬로 처리되어 대기 시간을 줄이고 연산을 효율적으로 분배할 수 있습니다.
ㆍ모델의 각 단계가 병렬로 처리되어 대기 시간을 줄이고 연산을 효율적으로 분배할 수 있습니다.
04
Distributed Data Parallel
ㆍ여러 노드와 GPU에서 LLM 모델을 병렬로 학습하는
방법을 학습합니다.
ㆍ각 노드에서 입력 데이터를 분산 처리 후, 그라디언트를 합산하고 모델 파라미터를 동기화하여 일관된 모델 업데이트 방법을 학습합니다.
ㆍ각 노드에서 입력 데이터를 분산 처리 후, 그라디언트를 합산하고 모델 파라미터를 동기화하여 일관된 모델 업데이트 방법을 학습합니다.
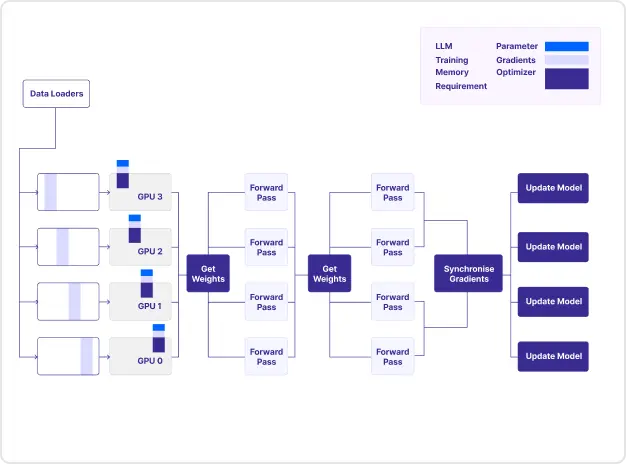
05
Fully Sharded Data Parallel
ㆍLLM 모델의 파라미터, 옵티마이저 상태, 그라디언트를 각 GPU에 나눠 저장하여 메모리 사용을 최적화하는
방법을 학습합니다.
ㆍ메모리 사용량을 줄이면서 모델의 각 파라미터를 GPU에서 독립적으로 업데이트 하는 방법을 학습합니다.
ㆍ메모리 사용량을 줄이면서 모델의 각 파라미터를 GPU에서 독립적으로 업데이트 하는 방법을 학습합니다.
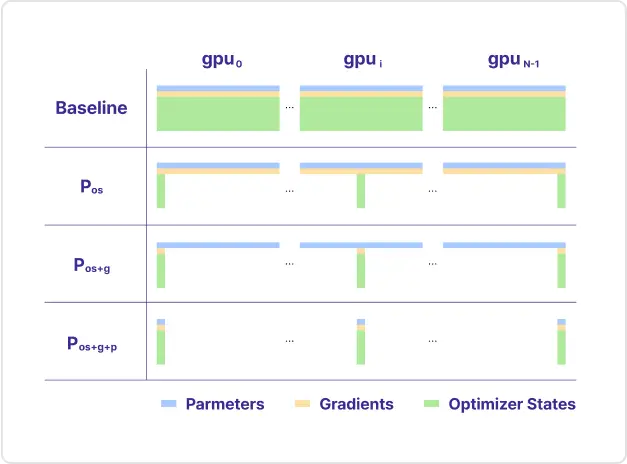
06
Zero Redundancy Optimizer
ㆍ대규모 모델을 학습하면서 메모리 효율성을
극대화하기 위한 최적화 방법을 학습합니다.
ㆍ모델의 파라미터, 옵티마이저 상태, 그라디언트를 각 GPU에 나눠 저장하여 메모리 중복을 최소화하는 방법을 학습합니다.
ㆍ모델의 파라미터, 옵티마이저 상태, 그라디언트를 각 GPU에 나눠 저장하여 메모리 중복을 최소화하는 방법을 학습합니다.
GPU 최적화와 분산처리 기법을 수행하기 위해 활용되는
2가지 대표 라이브러리도 학습합니다!




Middle Project 2 >>
Multi-GPU 환경에서 GPU 최적화를 위해 활용되는 대표 2가지 분산학습 프로젝트 실습
메모리 제한으로 인한 하드웨어의 한계를 벗어나 다수의 GPU를 활용하여 학습시간을 단축시킬 수 있는
분산학습을 활용하여 대규모 AI 서비스 운영에 필요한 GPU 최적화 프로젝트 실습을 진행합니다.
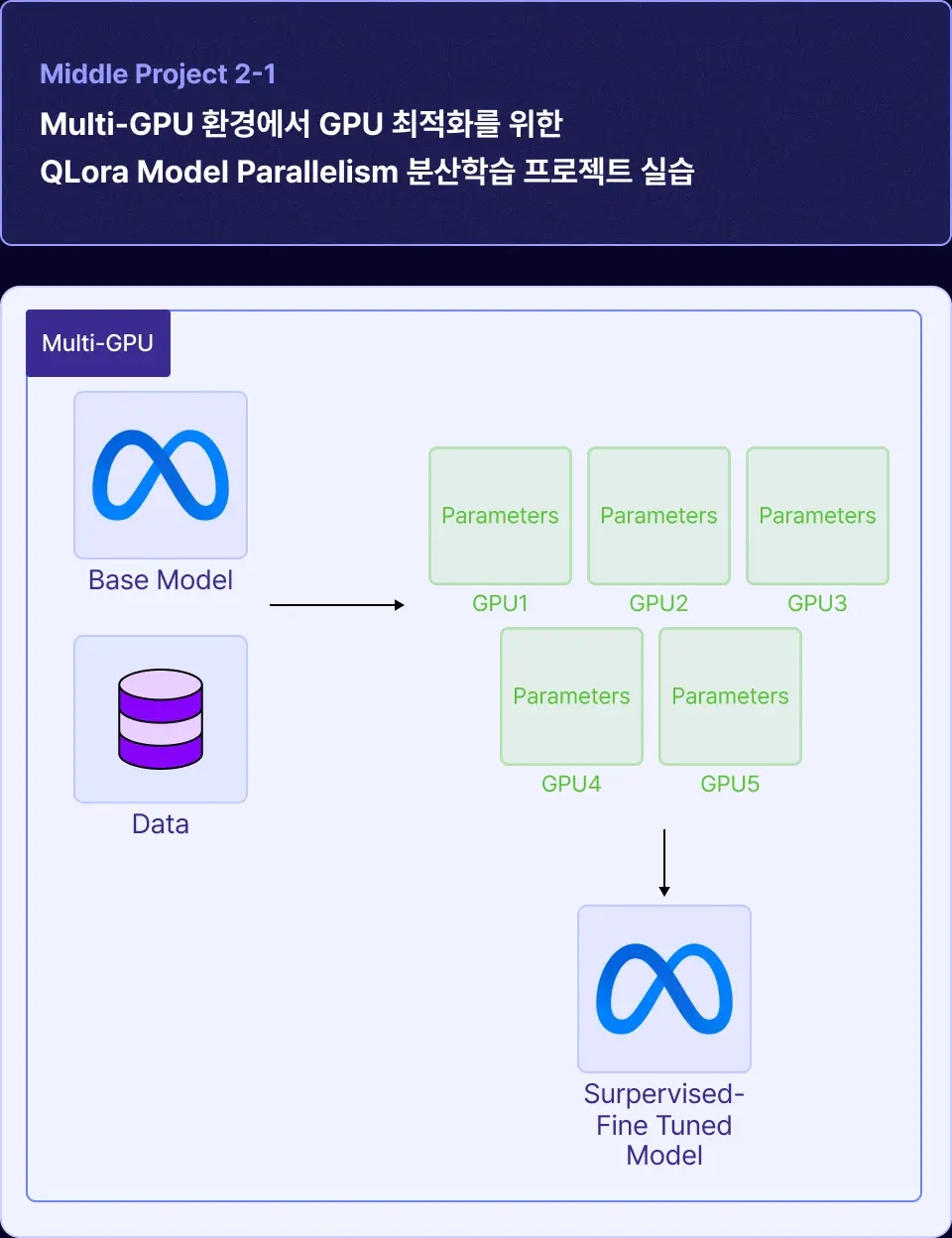
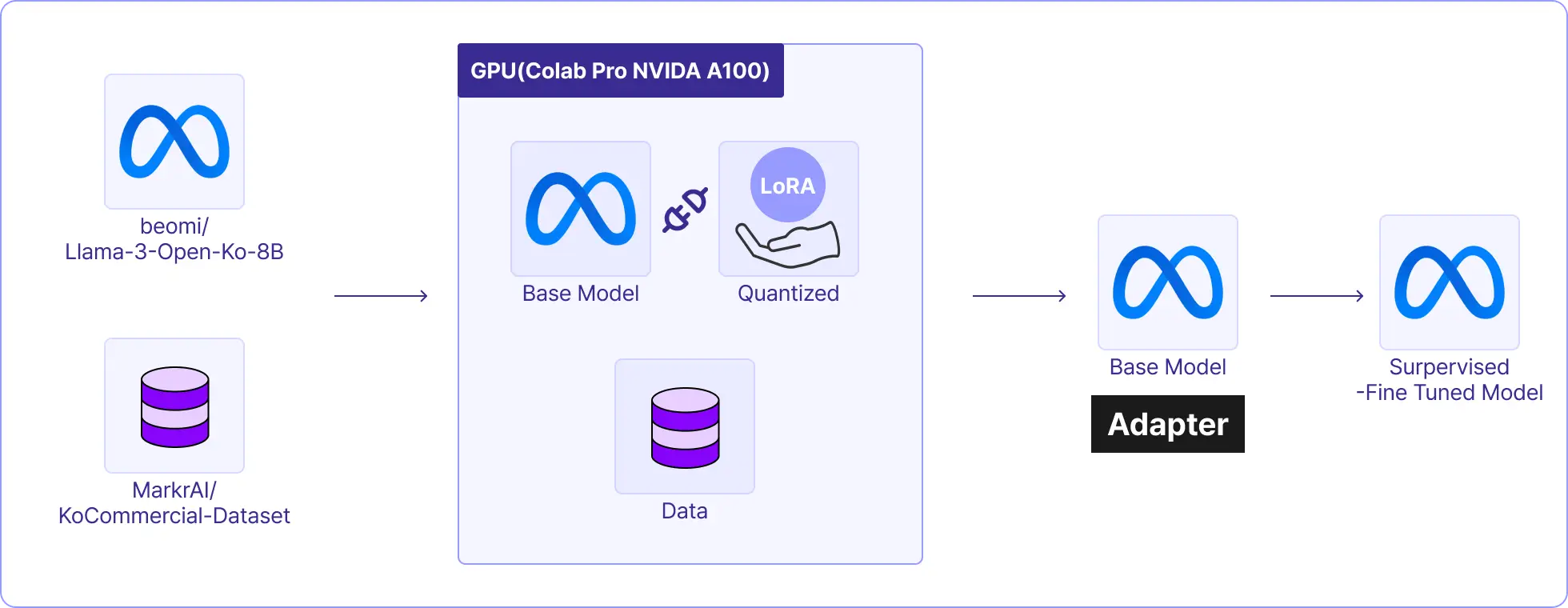
| 프로젝트 실습 개요
• 활용하는 모델 : beomi/Llama-3-Open-Ko-8B
• 분산학습 방법론 : QLoRA
• Data : Ko-Optimize Dataset
| 학습 포인트
• Single-GPU 환경에서 모델의 파라미터를 적재할 수 없는 경우 Multi-GPU 환경에서 1개 LLM 모델의 파라미터를 다수의 GPU에 분산하는 Model Parallelism 방법을 학습합니다.
• Model Parallelism 방법은 Transformer 라이브러리에서 쉽게 적용 가능하기에 Multi-GPU 최적화 기법에서 주로 쓰이는 기법입니다.
• 기존 최적화 기법들이 모델을 수직 분할하는 것과 다르게 MP 방법론은 모델을 수평 분할하여 분산시키면서 통신 오버헤드를 감소하고 병렬 처리 성능을 극대화하는 방법을 학습합니다.
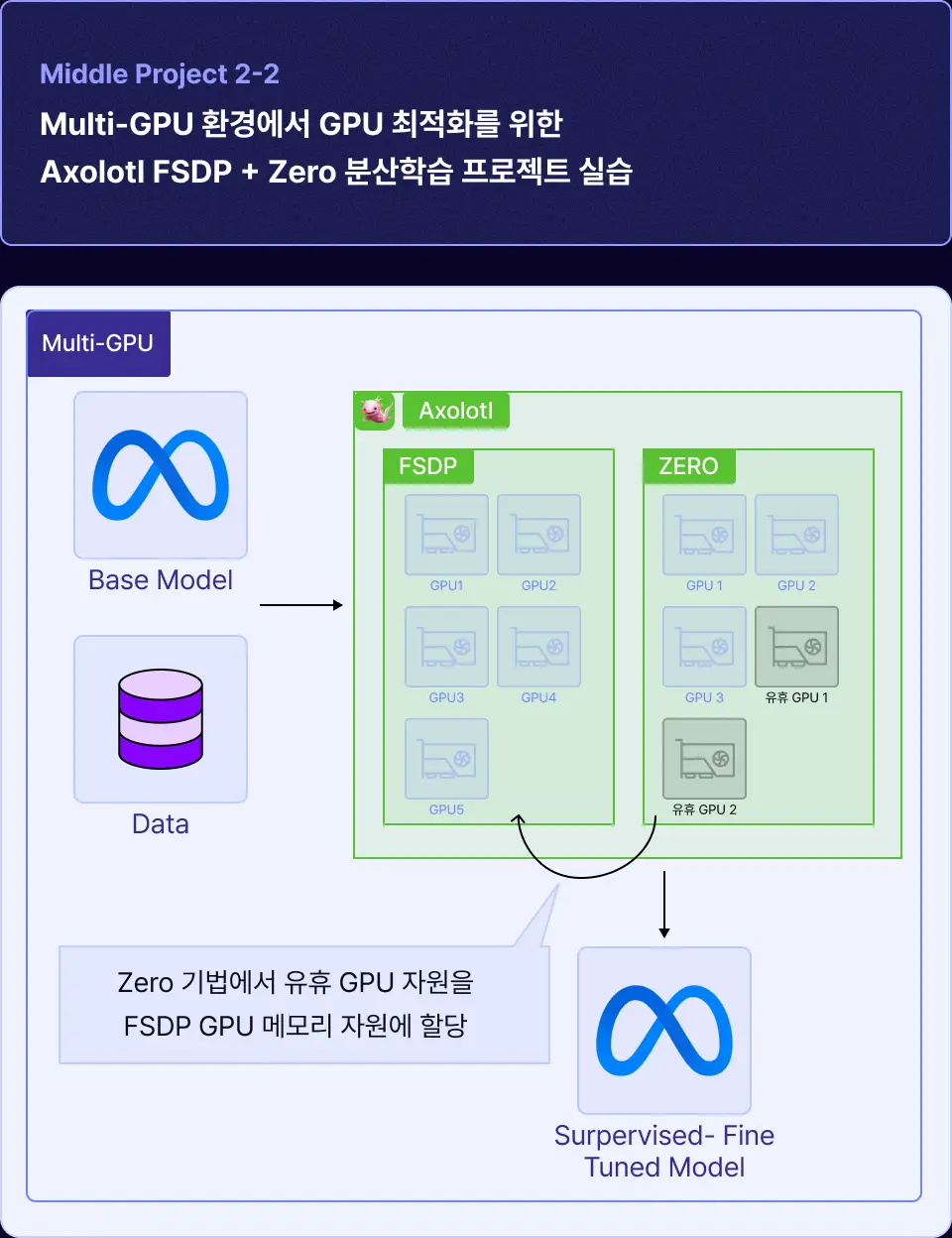
| 프로젝트 실습 개요
• 활용하는 모델 : beomi/Llama-3-Open-Ko-8B
• 분산학습 방법론 : Full Fine-Tuning
• Data : Ko-Optimize Dataset
| 학습 포인트
• Multi-GPU 환경에서 다수의 LLM 모델 각각의 파라미터, 그라디언트, 옵티마이저를 각 GPU에 분산하고 파인튜닝을 최적화할 수 있는 Axolotl 환경에서 구동하는 방법을 학습합니다. (대규모 데이터 셋 환경에서 장점)
• 그러나 Forward 과정에서 모델의 각 Layer를 통과할 때마다 All Gather 연산과 그라디언트를 계산하기 위해 GPU에 저장되어 있는 파라미터를 가져오다 보니 메모리 부담이 심할 때가 있습니다.
• 활용하고 있지 않는 학습 영역에서 메모리를 할당하고 있지 않는 Zero 기법의 특징을 같이 이용하여 GPU 부담을 줄이고 최적화하는 방법을 학습합니다.
Special Project
3개의 프로젝트로 끝내는 GPU Fine-Tuning & Inference 최적화
Multi-GPU 환경에서 각각 LLM 모델의 메모리 최적화와 Latency 증강을 위한
3개의 Final 프로젝트 실습으로 GPU 활용 방법을 완벽하게 학습할 수 있습니다.
Final Project 1 >>
한정된 GPU 메모리 환경에서 Fine-Tuning 성능을 극대화하기 위한 SFT+DPO Fine-Tuning 프로젝트 실습
개인화 된 맞춤 서비스 구성을 위한 SFT 기법과 직접 선호 최적화 DPO 기법을 활용하여
실전 AI 서비스 개발에 적합한 LLM 모델을 구성하는 방법을 직접 실습을 통해 구현합니다.
Step 01
LLM 오픈소스 모델 별 특징 파악



Step 02
SFT + DPO 과정을 통해 최종 파인튜닝 모델 구성
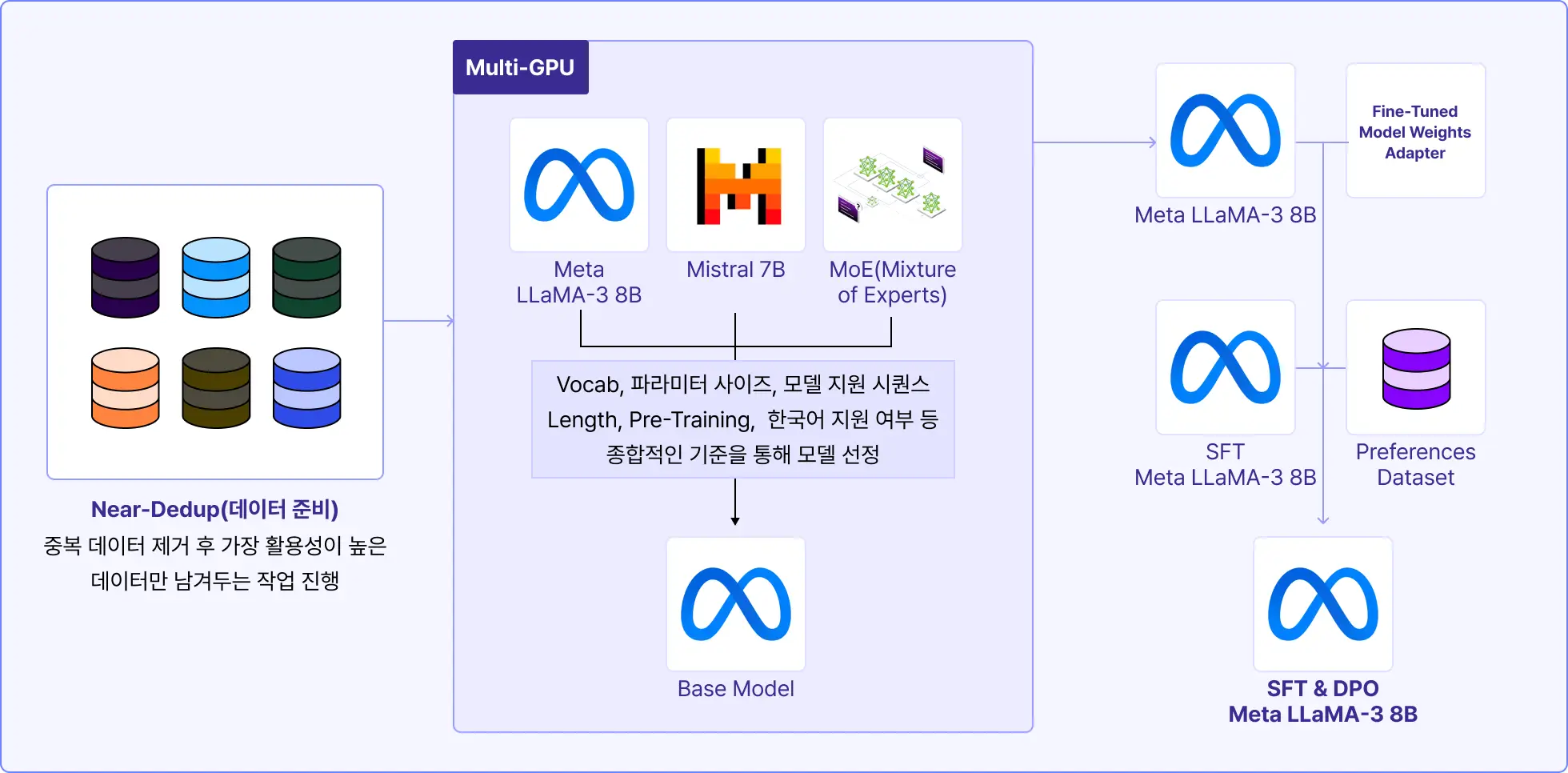
| 학습 포인트
• Near-Dedup 과정을 통해 중복된 데이터 셋을 제거하고 활용성이 높은 데이터만 남겨두는 방법을 학습합니다.
• 오픈소스 LLM 모델 선정을 위한 기준을 학습하며 SFT + DPO를 위한 베이스 모델을 선정합니다.
• 베이스 모델과 최종 Fine-Tuning 된 Weights 값의 Adapter를 병합하여 최종 SFT 모델을 생성합니다.
• 생성된 SFT 모델과 DPO 전용 데이터 셋을 만들어 직접적으로 사용자의 선호도를 반영한 DPO 모델을 생성하는 방법을 학습합니다.
Final Project 2 >>
Multi-GPU 환경에서 LLM 모델 Latency 최적화를 위한 Inference 프로젝트
개인화 된 맞춤 서비스 구성을 위한 SFT 기법과 직접 선호 최적화 DPO 기법을 활용하여
실전 AI 서비스 개발에 적합한 LLM 모델을 구성하는 방법을 직접 실습을 통해 구현합니다.
Step 01
LLM Inference에 대표적으로 활용되는 3가지 Infernece 라이브러리 학습



Step 02
Multi-GPU 환경에서 LLM 모델 Latency 최적화를 위한 2개의 Inferece 파이널 프로젝트

| 학습 포인트
• Transformer 라이브러리에서 FP16, 양자화 기법 등 메모리 최적화 기법을 사용하여
Multi-GPU 환경에서 메모리를 최적화하는 방법을 학습합니다.
• 메모리 사용을 줄임으로써 고성능 GPU가 아닌 환경에서도 모델을 양자화하여 Inference를 효율적으로 진행하는 방법을 학습합니다.
• 메모리 사용을 줄임으로써 고성능 GPU가 아닌 환경에서도 모델을 양자화하여 Inference를 효율적으로 진행하는 방법을 학습합니다.

| 학습 포인트
• LLM 모델의 추론 속도를 최적화하기 위한 vLLM 라이브러리의 활용 방법과 GPU의 계산 자원을 활용하는 방법을 학습합니다.
• Transformer 라이브러리가 가지고 있던 병목 현상을 줄이면서 추론 시간 단축, 실시간 응답, 리소스 사용 효율성을 극대화하는 방법을 학습합니다.
• 기존 추론 속도보다 더 빠르면서도 다수의 응답을 처리할 수 있는 Inference 방법을 학습합니다.
• Transformer 라이브러리가 가지고 있던 병목 현상을 줄이면서 추론 시간 단축, 실시간 응답, 리소스 사용 효율성을 극대화하는 방법을 학습합니다.
• 기존 추론 속도보다 더 빠르면서도 다수의 응답을 처리할 수 있는 Inference 방법을 학습합니다.
Plus Point
Fine-Tuning에 특화된 GPU 최적화 심화 기법 학습
LLM 모델의 Fine-Tuning에 최적화 된 GPU 최적화 Tip을 학습하여
추가로 모델 성능을 올릴 수 있는 방법도 같이 학습합니다.
 학습 Case 1. Fine-Tuning 성능을 높이기 위한 전처리 노하우 3가지!
학습 Case 1. Fine-Tuning 성능을 높이기 위한 전처리 노하우 3가지!



학습 Case 2. 적절한 Prompt Template을 활용하여 Fine-Tuning
POINT 01
Fine-Tuning 과정에서 Prompt Template를
활용해야 하는 이유는?
활용해야 하는 이유는?
LLM 모델을 Fine-Tuning하면서 Prompt Template를 활용해야 하는 이유는 LLM Task의 명확한 작업 이행, 일관성 유지, 문제 해결 능력 향상, 모델이 이미 학습한 지식을 끌어내어 사용할 수 있기에 모델 성능 증강을 위한 Prompt Template를 사용할 줄 알아야 합니다.
POINT 02
대표적으로 활용되는 Prompt Template는
어떤 Template들이 있을까요?

학습 Case 3. LLM 모델의 하이퍼파라미터 설정 시 주요하게 봐야 할 2가지 포인트


학습 Case 4. LLM 모델의 성능을 평가할 수 있는 대표 2가지 판단 요소
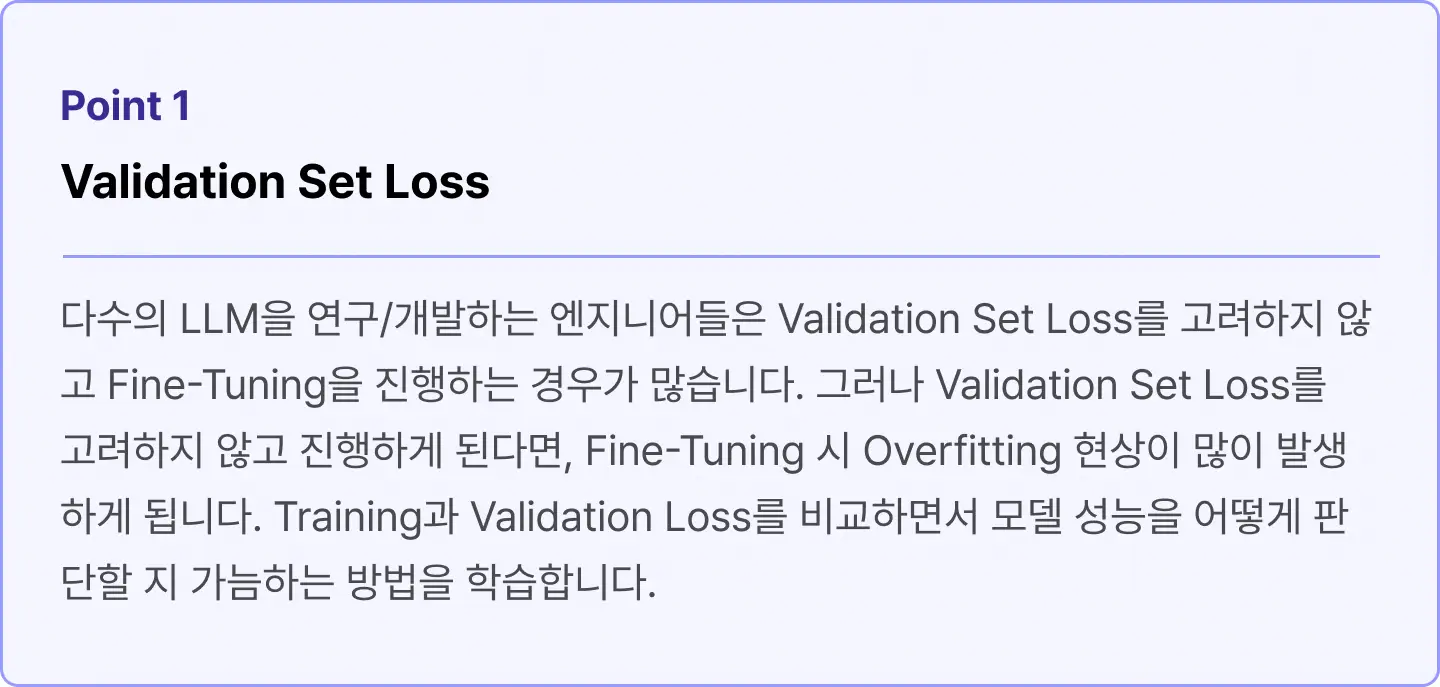

LLM 모델 성능 증가를 위한 추가 판단 기준
LLM 모델 성능을 올리기 위해 꼭 Tokenizer를
확장하는 것이 중요한가요?
LLM 모델 성능을 올리기 위해 꼭 Tokenizer를
확장하는 것이 중요한가요?
Tokenizer를 확장하면 GPU의 메모리 측면에서 효과를 볼 수 있으나 다만 성능이 하락하게 되는 경우가 있어 무조건 Tokenizer를 확장하는 것이 좋다고 이야기 할 수는 없습니다. 현실적인 Tip은 메모리 이득이 30% 이상일 경우 Tokenizer를 확장하는 것이 모델 성능 향상에 도움을 줄 수 있습니다.
커리큘럼
아래의 모든 강의를 초격차 패키지 하나로 모두 들을 수 있습니다.
지금 한 번만 결제하고 모든 강의를 평생 소장하세요!
Part 01. LLM과 GPU의 기초
Part 02. Single GPU 환경에서의 Fine-Tuning
Part 03. Multi-GPU 환경에서의 분산 학습
Part 04. GPU 최적화 기법 심화
Part 05. Fine-Tuning & Inference 프로젝트 실습 및 응용
LLM 모델 파인튜닝을 위한 GPU 최적화
상세 커리큘럼
자세한 커리큘럼 및 내용은 여기서 확인하세요!
Question 1
어떤 분들이
수강하시면 좋을까요?
어떤 분들이
수강하시면 좋을까요?
AI/LLM 서비스를 개발하고 배포하기 위해서는 GPU 자원을 최적화하는 것이
가장 중요합니다. 이 강의에서는 GPU 자원을 활용하여 AI Application을
개발하고자 하는 AI Engineer & 개발자분들께서 수강하신다면 효율적인
LLM 서비스 개발을 하실 수 있을 것이라 생각합니다.
Question 2
해당 주제를 학습하면서 겪는
가장 대표적인 어려움은 무엇인가요?
해당 주제를 학습하면서 겪는
가장 대표적인 어려움은 무엇인가요?
AI/LLM 서비스를 개발하면서 겪는 가장 큰 어려움은 바로 Fine-Tuning 과정에서
GPU 메모리 부족 문제가 발생하는 점입니다. 이 강의에서는 한정된 GPU 자원 속
Fine-Tuning 성능을 최적화하기 위한 방법들을 학습하며 자원 크기에 구애받지 않고
LLM의 성능을 높일 수 있는 방법을 학습합니다.
Question 3
강의를 수강한 후에 어떤 내용을 학습할 수 있나요?
강의를 수강한 후에 어떤 내용을 학습할 수 있나요?
단순한 Fine-Tuning Tip이 아닌, LLM Leadeboard & Ko-Leaderboard에서 최장기간
1순위 자리를 지키며 높은 성능을 낼 수 있었던 저만의 Fine-Tuning Tip과 GPU 최적화
기법을 학습하여 LLM 서비스 개발 및 배포 과정에서 한층 더 성장할 수 있는 계기가 될 것이라
확신합니다.
Question 4
개발 환경
개발 환경
• Google Colab 활용 Local GPU (유료)
• Cloud GPU(AICA)
• Cloud GPU(AICA)