
지금이 가장 저렴해요!✨
본 강의는 3월 9일에 신규 런칭한 강의로
사전 구매하신 분들께 얼리버드 혜택을 제공하고 있습니다.
휴머노이드 보행 제어
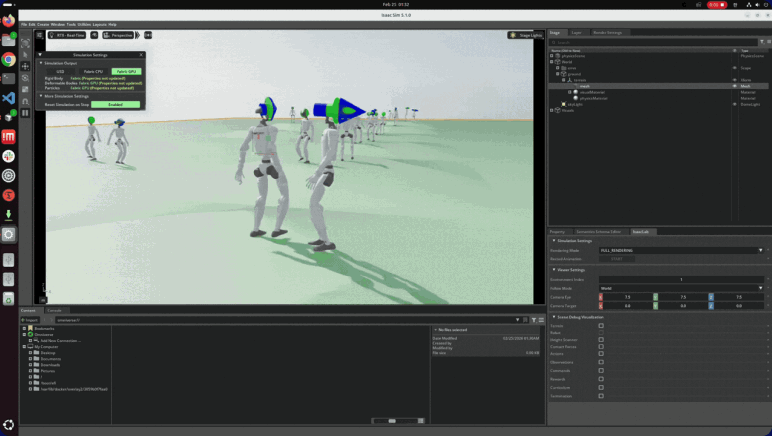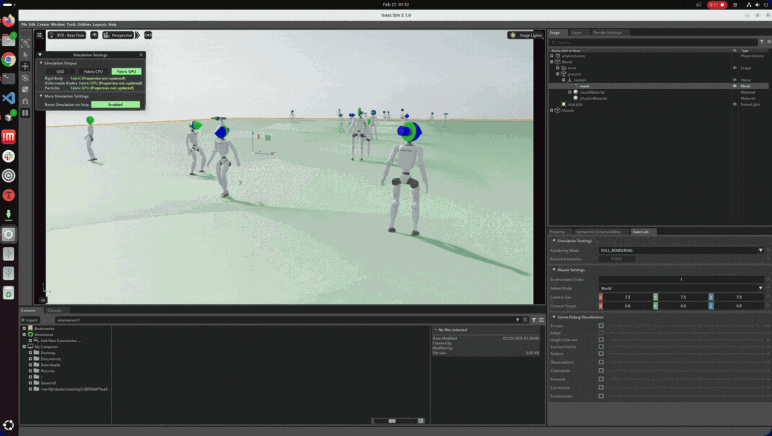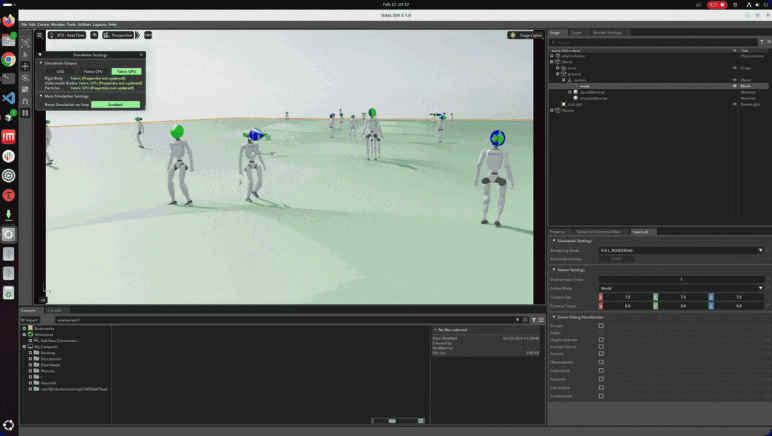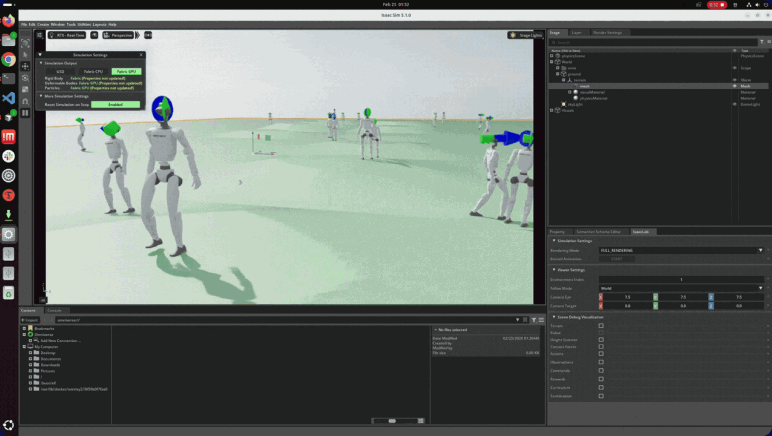
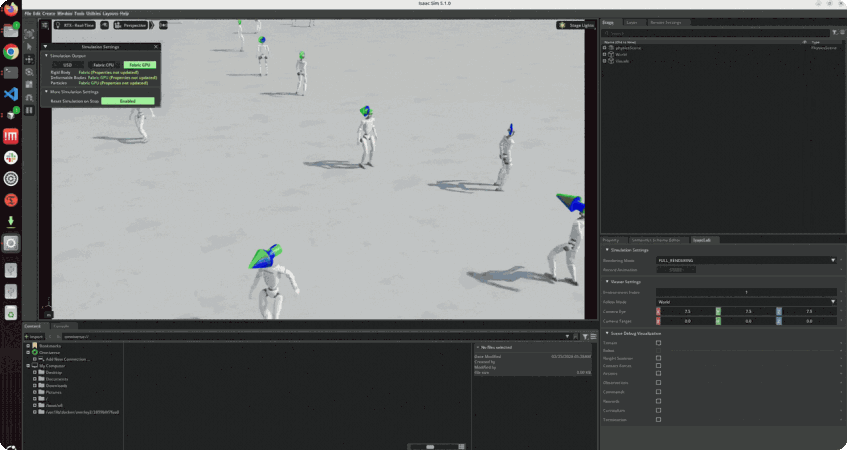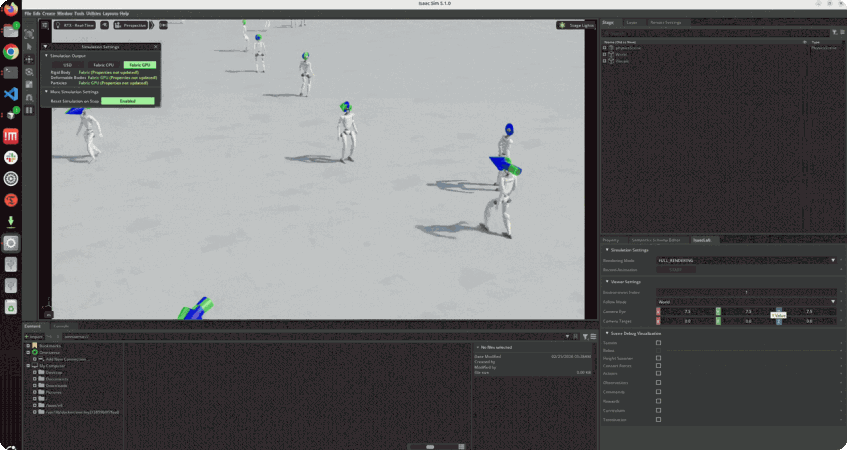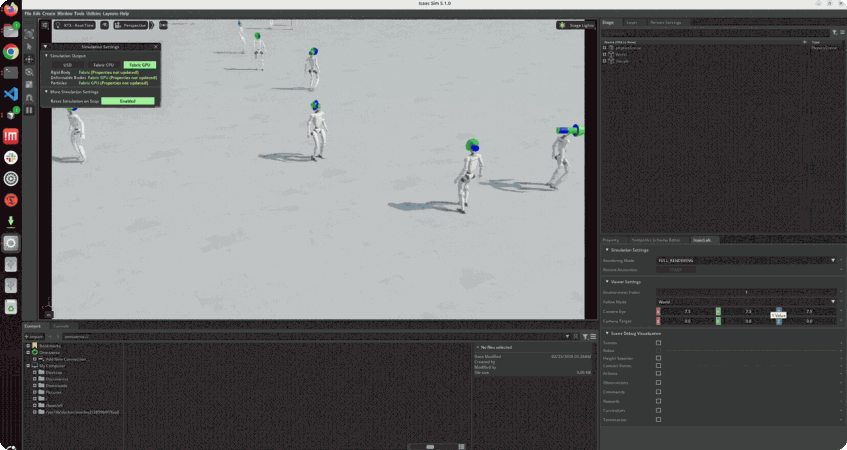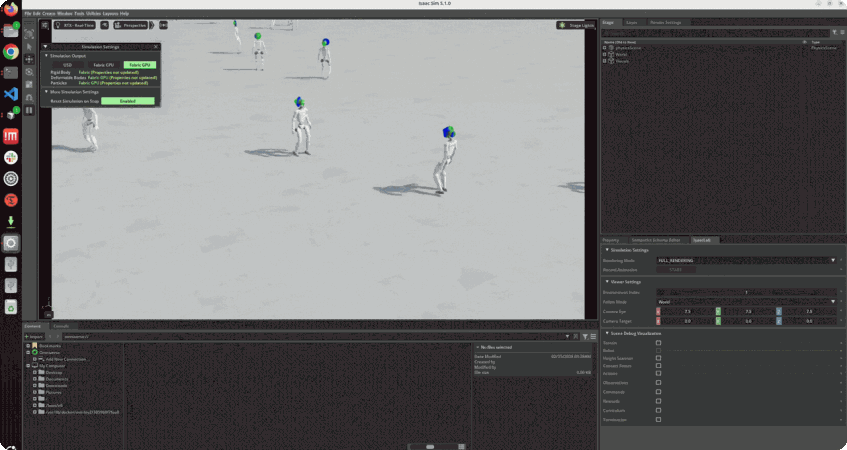
NVIDIA Isaac Sim
강화학습
얼리버드
4월 1일 ~ 30일까지
정가 600,000원
판매가 380,000원
12개월 할부 적용시
36%
월 31,666원
정가
600,000원
휴머노이드 로봇 제어의 뼈대가 되는 기술,
보행 제어(Locomotion)
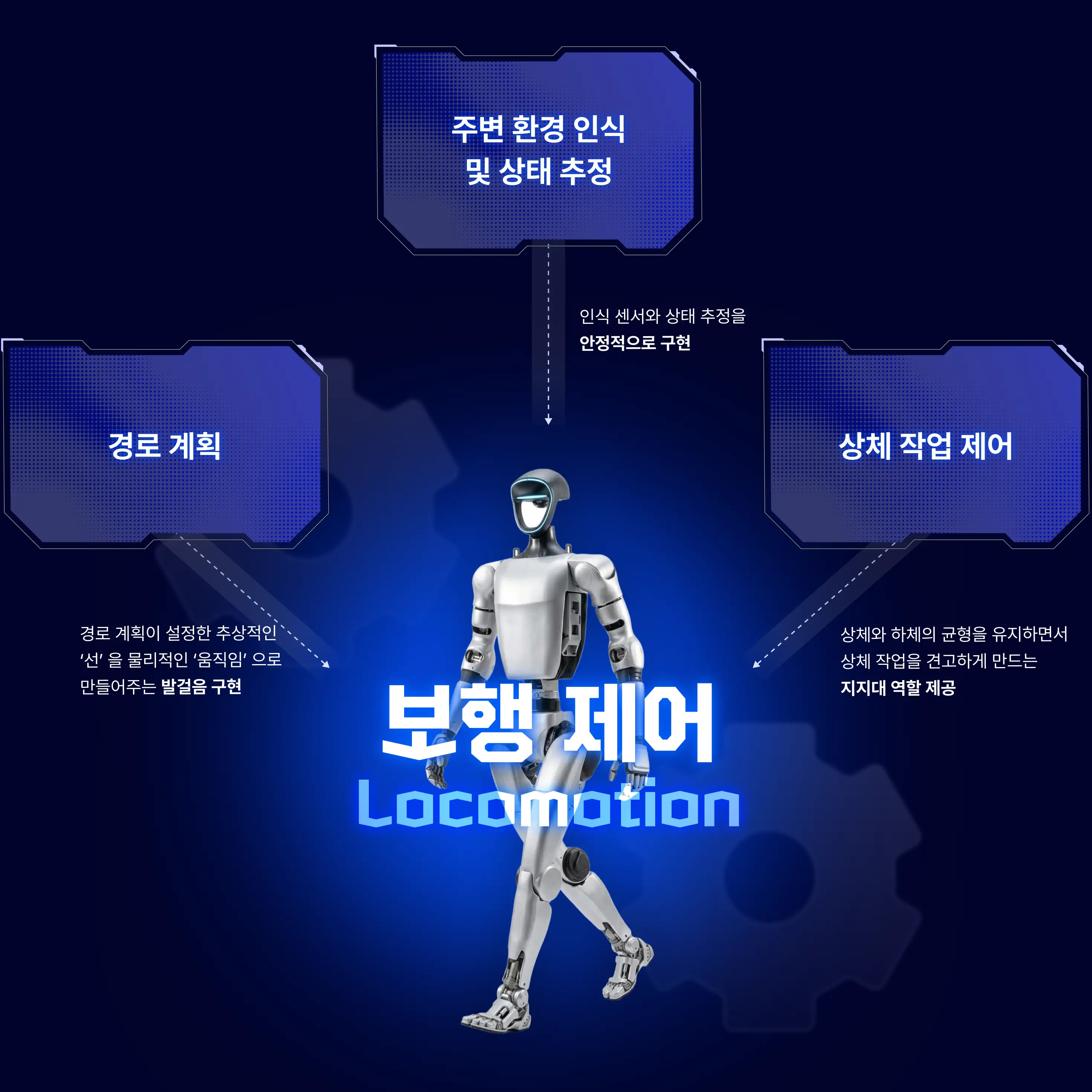
사람처럼 자연스럽게 움직이는
휴머노이드 보행 제어 3가지 핵심은?










Boston Dynamic부터 SANTUARY AI까지
휴머노이드 보행 제어 기술 표준 조합이 되어 가고 있는 강화학습(PPO) X NVIDIA Isaac Sim



수강 대상

NVIDIA Isaac Sim을 활용하여 휴머노이드 보행(Locomotion) 시스템을 개발하고 싶은 로보틱스 엔지니어
모바일 로봇을 넘어 휴머노이드 환경에서 로봇 시스템의 이동 제어 방법을 학습하고 싶어하는 로보틱스 엔지니어
강화학습, 휴머노이드 보행 시스템을 연구하고 있는 학/석사생
Q & A
Question.1
강의를 수강하고 나서
어떤 지식을 학습할 수 있나요?
강의를 수강하고 나서
어떤 지식을 학습할 수 있나요?
· Isaac lab 기반 휴머노이드 환경 구축 기술
NVIDIA Isaac Lab 시뮬레이터 내에 Unitree G1 로봇을 배치하고
물리 파라미터를 최적화하는 방법을 학습합니다.
또한 로봇이 외부 명령에 즉각 반응하도록 하는 인터페이스 구현 능력을 갖추게 됩니다.
· PPO 알고리즘을 활용한 보행 정책 학습
로코모션 분야의 표준인 PPO 알고리즘을 활용하여 보행 정책을 설계하고
전체 학습 루프를 구축해 봅니다. 학습 로그를 분석하여 모델의 성능을 최적화하는
디버깅 노하우를 습득합니다.
· 전신 협응(Whole-Body) 및 보상 설계 능력
상체와 하체의 유기적인 움직임을 반영한 관측(Obs) 및 행동(Action) 데이터를
설계하는 법을 배웁니다. 로봇의 보행 스타일을 결정하는 다양한 보상 항목들을
직접 설계하며 행동을 디자인하는 경험을 쌓습니다.
· 강건한 Locomotion을 위한 Sim-to-Real 전략
환경 랜덤화(Domain Randomization) 기법을 통해 외란에 강한
일반화 성능을 확보하는 방법을 배웁니다. 시뮬레이션 모델을 실제 물리 환경에
성공적으로 적용하기 위한 핵심 전이 전략을 다룹니다.
NVIDIA Isaac Lab 시뮬레이터 내에 Unitree G1 로봇을 배치하고
물리 파라미터를 최적화하는 방법을 학습합니다.
또한 로봇이 외부 명령에 즉각 반응하도록 하는 인터페이스 구현 능력을 갖추게 됩니다.
· PPO 알고리즘을 활용한 보행 정책 학습
로코모션 분야의 표준인 PPO 알고리즘을 활용하여 보행 정책을 설계하고
전체 학습 루프를 구축해 봅니다. 학습 로그를 분석하여 모델의 성능을 최적화하는
디버깅 노하우를 습득합니다.
· 전신 협응(Whole-Body) 및 보상 설계 능력
상체와 하체의 유기적인 움직임을 반영한 관측(Obs) 및 행동(Action) 데이터를
설계하는 법을 배웁니다. 로봇의 보행 스타일을 결정하는 다양한 보상 항목들을
직접 설계하며 행동을 디자인하는 경험을 쌓습니다.
· 강건한 Locomotion을 위한 Sim-to-Real 전략
환경 랜덤화(Domain Randomization) 기법을 통해 외란에 강한
일반화 성능을 확보하는 방법을 배웁니다. 시뮬레이션 모델을 실제 물리 환경에
성공적으로 적용하기 위한 핵심 전이 전략을 다룹니다.
Question.2
필요한
선수지식이 있을까요?
필요한
선수지식이 있을까요?
· Linux 환경 숙련도 : 명령어 사용 및 환경 변수 설정 등을 스스로 처리
· Python 코드 독해 및 수정 역량 : 클래스 구조를 읽고 로직을 직접 수정 및 구현
· 딥러닝 및 머신러닝 기초 개념 : 신경망의 기본 구조와 학습 원리 이해 필요
· Python 코드 독해 및 수정 역량 : 클래스 구조를 읽고 로직을 직접 수정 및 구현
· 딥러닝 및 머신러닝 기초 개념 : 신경망의 기본 구조와 학습 원리 이해 필요
Question.3
개발 환경
개발 환경
· Ubuntu 22.04 LTS
· NVIDIA Isaac Lab
· Visual Studio Code
· 하드웨어 : NVIDIA RXT 30/40 시리즈 이상(VRAM 16 GB 이상 권장)
· NVIDIA Isaac Lab
· Visual Studio Code
· 하드웨어 : NVIDIA RXT 30/40 시리즈 이상(VRAM 16 GB 이상 권장)
01 ㅣ 강의 핵심 포인트
Point 1.
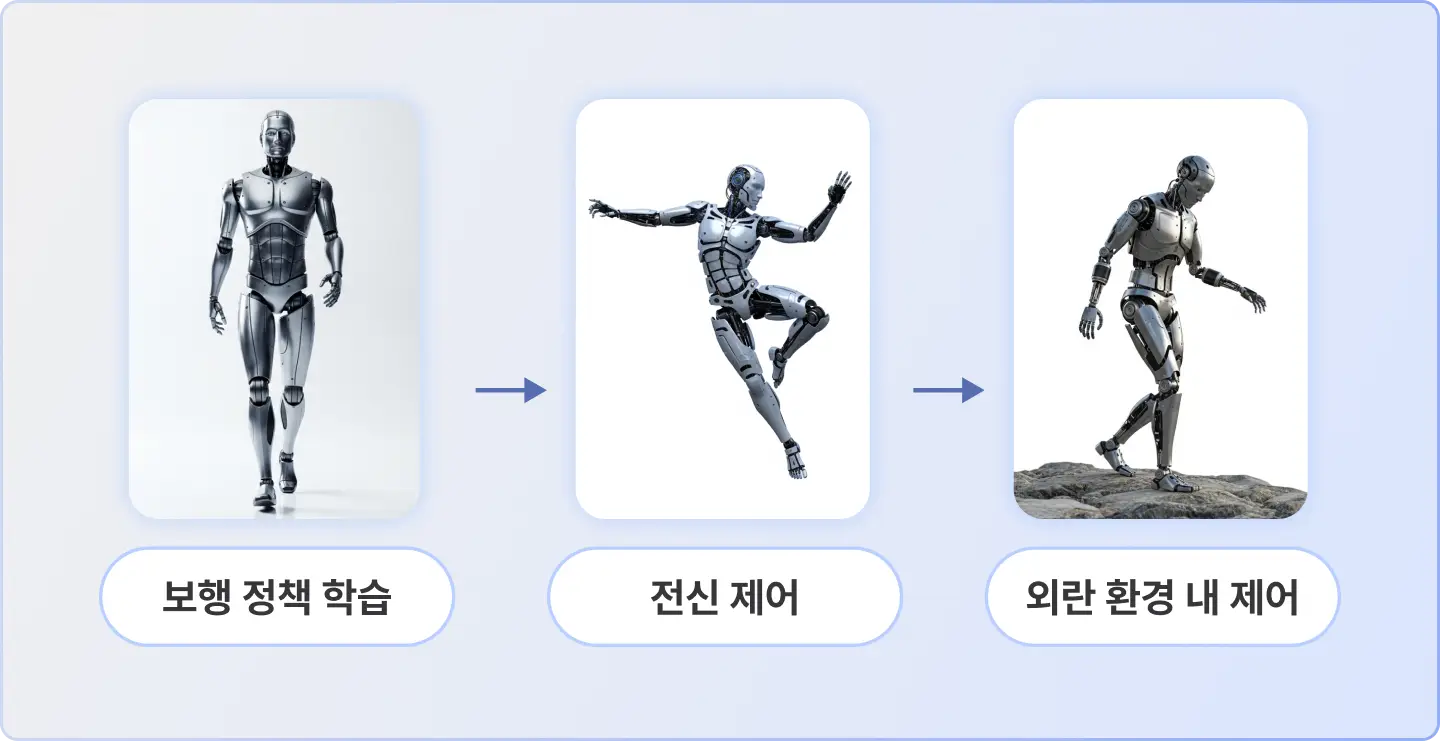
강화학습(PPO) x NVIDIA Isaac Sim을 활용한
휴머노이드 보행 제어 3단계 학습
PPO의 개념과 이를 응용하여 평지부터 다양한 외란과 지형 변화에서도 안정적으로 보행 가능한 휴머노이드 제어 방법 학습
강화학습(PPO) x NVIDIA Isaac Sim을 활용한
휴머노이드 보행 제어 3단계 학습
PPO의 개념과 이를 응용하여 평지부터 다양한 외란과 지형 변화에서도 안정적으로 보행 가능한 휴머노이드 제어 방법 학습
Point 2.
평지부터 외란 및 지형 변화 속 보행까지 모두 구현하는 4가지 프로젝트 실습 진행
강화학습 환경 내에서 로봇의 관절과 자유도 표현부터 강한 환경 변화 속 보행 유지까지 모두 구현해볼 수 있는 프로젝트 실습 진행
평지부터 외란 및 지형 변화 속 보행까지 모두 구현하는 4가지 프로젝트 실습 진행
강화학습 환경 내에서 로봇의 관절과 자유도 표현부터 강한 환경 변화 속 보행 유지까지 모두 구현해볼 수 있는 프로젝트 실습 진행

Point 3.
Sim-to-Real 간극을 매우기 위한
합성 데이터 생성 방법 학습
Isaac Lab의 시뮬레이션 데이터 증강을 통해 수천 대의 휴머노이드가 동시에 학습하며 행동 패턴을 확장하는 방법 학습
Sim-to-Real 간극을 매우기 위한
합성 데이터 생성 방법 학습
Isaac Lab의 시뮬레이션 데이터 증강을 통해 수천 대의 휴머노이드가 동시에 학습하며 행동 패턴을 확장하는 방법 학습

Point 4.
학습 중 궁금한 점이 있다면
언제든 질문할 수 있는 무한 질의응답
실습 중 에러가 나거나 이해가 되지 않는다면 바로 질문 해 보세요! 질의응답 운영 일정 : 2026년 4월 10일부터 2029년 6월 5일까지
학습 중 궁금한 점이 있다면
언제든 질문할 수 있는 무한 질의응답
실습 중 에러가 나거나 이해가 되지 않는다면 바로 질문 해 보세요! 질의응답 운영 일정 : 2026년 4월 10일부터 2029년 6월 5일까지

02ㅣ 커리큘럼
Physical AI 환경에서 학습 기반의 휴머노이드
보행 제어를 위한 4가지 포인트 학습

Point 01
휴머노이드 Locomotion을 위한
강화학습 환경 구축
휴머노이드 로봇 보행을 단순 제어가 아닌 강화학습 관점에서
“학습 문제” 로 정의하여 사고하는 방법을 학습합니다.
핵심 개념
강화학습 환경에서 휴머노이드 Locomotion 구현을 위한 4가지 구성 요소 학습






 학습 포인트
학습 포인트
∙ 로봇의 물리적인 상태(좌표, 속도)와 센서 정보를 하나의 유기적인 상태 벡터(State Vector)로 결합하여 G1 로봇 구조를 분석
 주요 실습 내용
주요 실습 내용
∙ Isaac Lab 환경에 G1 휴머노이드 로봇을 정확하게 임포트
∙ 강화학습 모델에 입력되는 관측 데이터와 명령 인터페이스 규격 확인
Point 02
PPO로 휴머노이드
보행 정책 학습하기
로봇이 스스로 균형을 잡고 걷기까지의 학습 과정을 배웁니다.
핵심 개념 (1)
PPO가 휴머노이드 보행 제어 표준이 된 배경 학습




핵심 개념 (2)
PPO의 대표 2가지 특징으로 배우는 Locomotion 적합성 학습


PPO의 대표 2가지 특징으로 보행 정책의 변화 폭을 제한하며
안정적인 Locomotion을 구현하는 방법을 학습합니다.


핵심 개념 (3)
PPO로 휴머노이드 로봇 보행을 최적화시키기 위한 2가지 요소 학습

Policy, Value, Advantage 사이 관계 학습
· 행동 결정, 상태 평가, 행동 효율성을 판단하는 Policy, Value, Advantage 간 관계를 학습합니다.
· 학습 로그, 손실 함수, 수렴 그래프의 의미를 학습합니다.
· 학습 로그, 손실 함수, 수렴 그래프의 의미를 학습합니다.

보상 함수 설계와 행동 디자인 방법 학습
· 속도 추종, 균형 유지 등 보상 요소들이 실제 보행 동작에 미치는 영향을 분석합니다.
· 특정 보상 항목 수정 시 휴머노이드 보행 스타일이 어떻게 달라지는지 확인합니다.
· 계산 효율성을 위해 사전 학습 정책을 활용하며 보행 정책을 구현하는 방법을 학습합니다.
· 특정 보상 항목 수정 시 휴머노이드 보행 스타일이 어떻게 달라지는지 확인합니다.
· 계산 효율성을 위해 사전 학습 정책을 활용하며 보행 정책을 구현하는 방법을 학습합니다.

 학습 포인트
학습 포인트
∙ 정책 업데이트 폭을 제한하여 목표하는 보행 학습 도중 보행 패턴 망가짐을 방지
∙ 보상 함수 설계로 휴머노이드 보행 동작 구현
주요 실습 내용
∙ 평지에서 안정적으로 걷는 보행 동작 설계
∙ 명령 속도에 반응하는 Command-Conditioned Locomotion 구현
Point 03
전신(Whole-Body)
Locomotion 학습
휴머노이드 로봇의 상체와 하체를 유기적으로 연결하여 강화학습으로 보행하는 방법을 학습합니다.
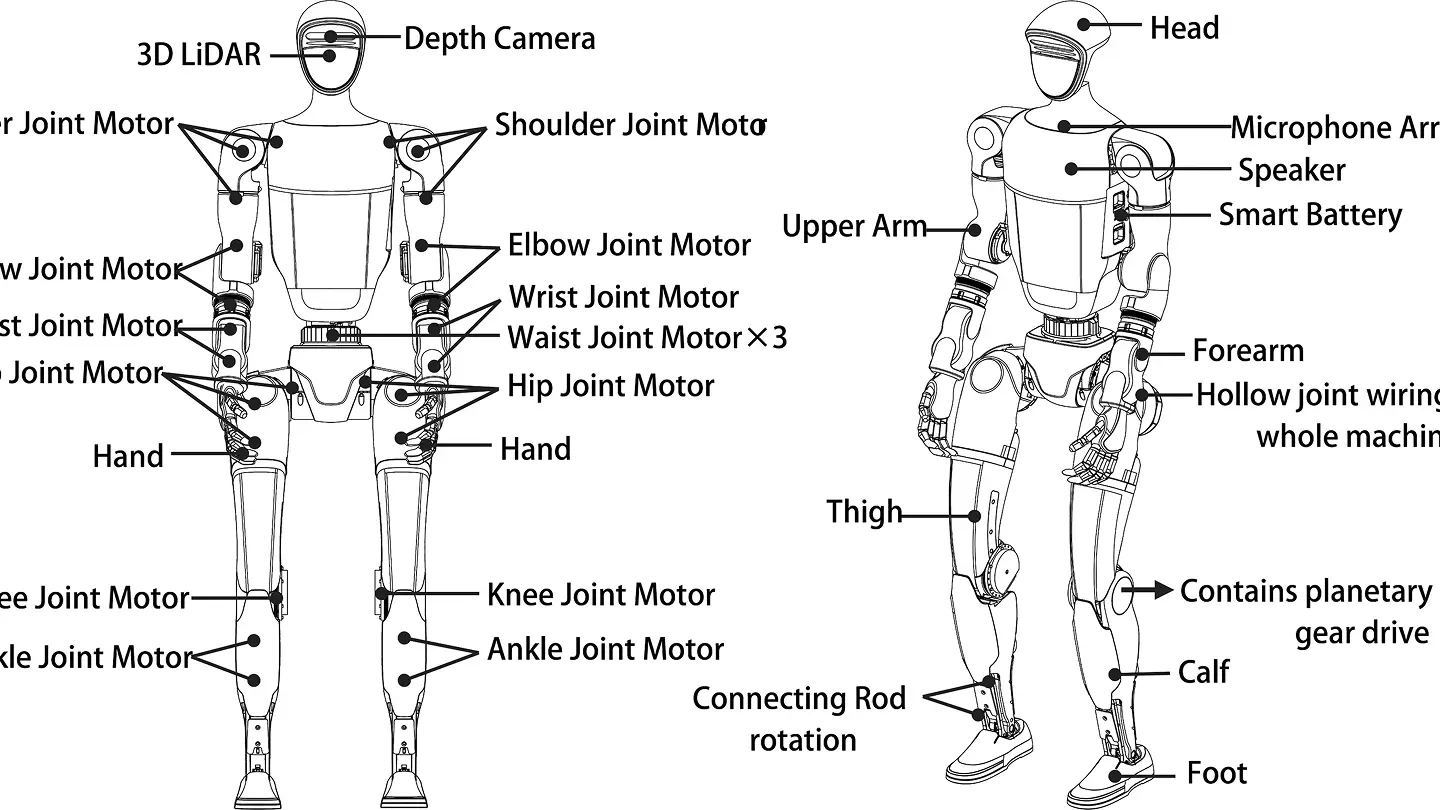
연결된 동역학 시스템의 구조
상하체가 하나의 질량 분포 시스템으로 작동하며 발생하는 동역학적 특성과 보행 중 발생하는 미세한 불균형이 상체의 질량과 움직임에 의해 어떻게 증폭될 수 있는지, 그리고 이를 억제하기 위한 전신 제어의 필요성을 이해합니다.

전신 상태를 고려한 신경망의 입력과 출력
로봇의 상체 관절 상태를 포함한 관측 벡터와 행동 공간을 설계하면서 자연스러운 보행을 유도하는 데이터 구조를 학습합니다.

중복 자유도를 활용한 외란 대처
여러 관절 조합을 활용하는 중복 자유도 시스템의 특성을 통해 로봇이 이동할 예측 경로 내 안정적인 행동 분포를 형성하는 방법을 학습합니다.

상체 고정 및 전신 활용 보행 정책 사이 성능 비교
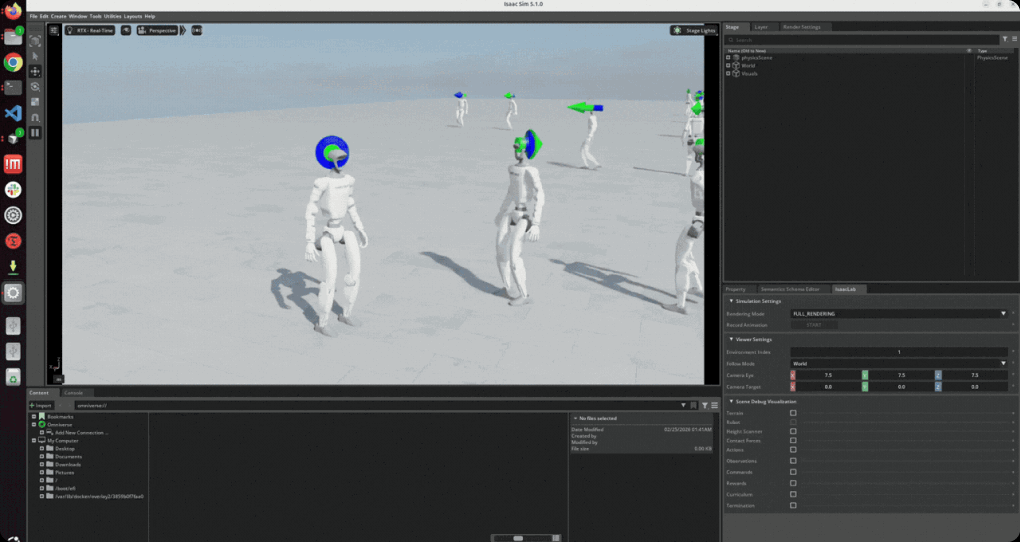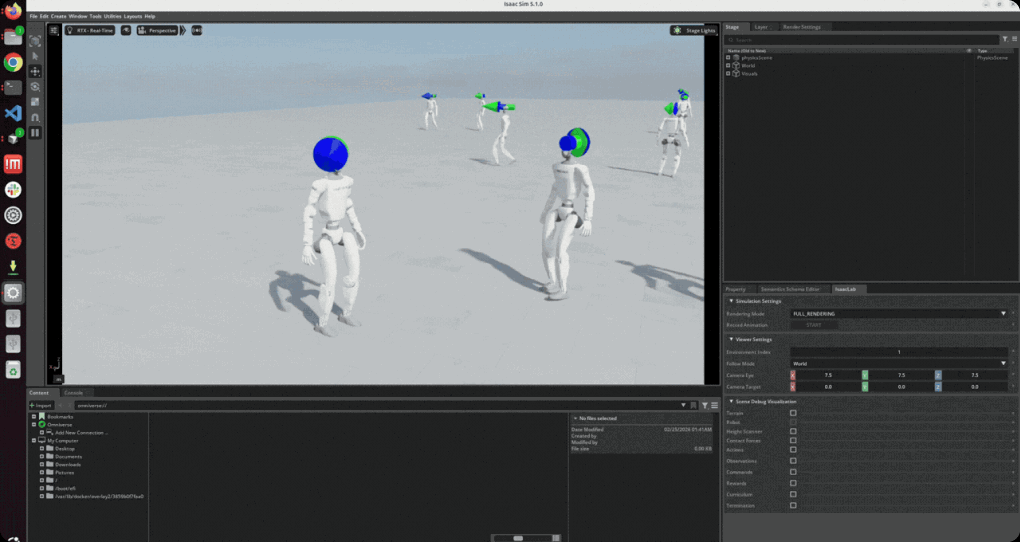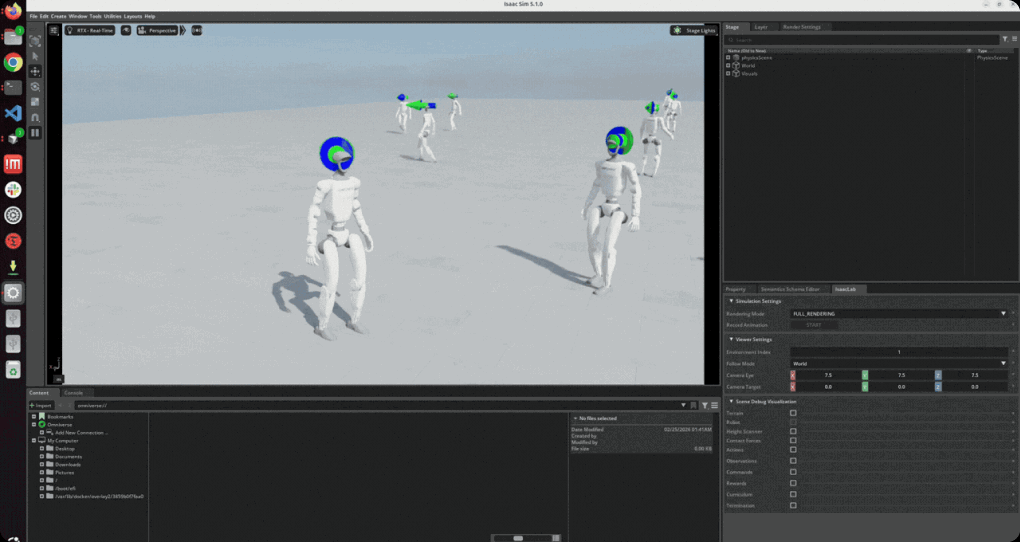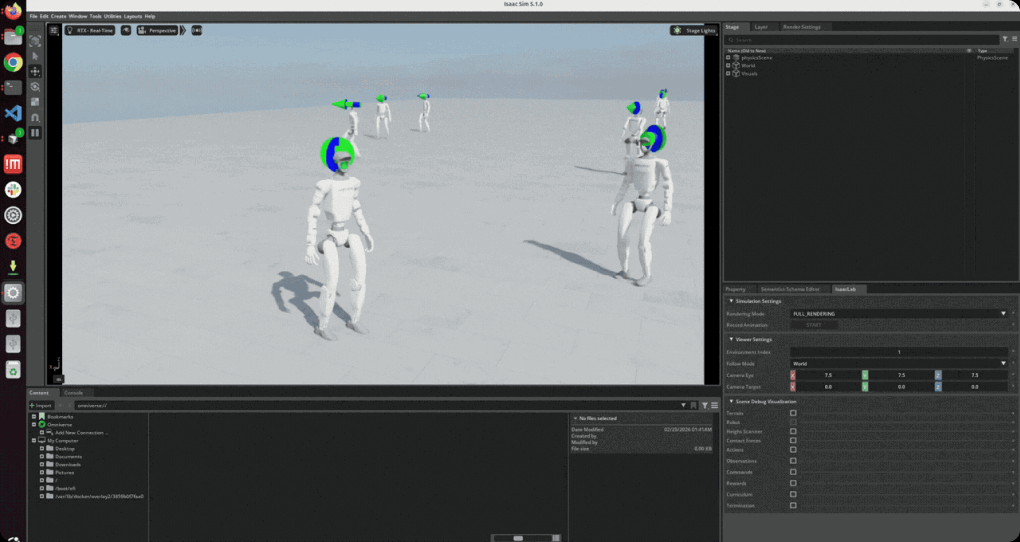
Isaac Sim 시뮬레이션 환경에서 로봇을 밀치거나 지형을 변화시켜 전신 균형 복원 과정을 확인하면서 전신 보행의 뛰어난 복원력을 확인합니다.

 학습 포인트
학습 포인트
∙ ‘다리’ 만 제어했을 때 보행 안정성이 충분하지 않은 이유 학습
∙ 전신 상태 관측에 포함된 정보만을 바탕으로 자행스러운 보행 구현
∙ 중복 자유도를 활용하여 시간에 따라 변화하는 동적 궤적 공간에서 안정적인 행동 분포 형성
주요 실습 내용
∙ 로봇을 밀치거나 지형을 변화시켜 전신 균형 복원 과정 구현
Point 04
정적 보행에서
현실 환경으로 확장하기
평지 보행을 넘어 외란 및 다양한 지형 변화 속에서
휴머노이드 보행 제어 방법을 학습합니다.
핵심 개념 (1)
현실 환경에서의 Locomotion 이해
현실 환경에서 외란 상황 시 충분히 발생할 수 있는 마찰 계수의 변화, 질량 오차 등 불확실성을 정의하고
로봇의 정책으로 균형을 복원하는 방법과 랜덤한 환경에서 정책 일반화 성능을 높이는 방법을 학습합니다.


핵심 개념 (2)
합성 데이터 생성
Isaac Lab으로 수천 대의 로봇으로부터 동시에 데이터를 수집하여 Sim-to-Real 간극을 매우기 위해
Auto-Labeling 기법을 활용하여 정책의 일반화 성능을 극대화하는 방법을 학습합니다.


핵심 개념 (3)
Sim-to-Real을 고려한 학습 설계
Isaac Sim에서 학습된 행동 정책이 실제 로봇에 적용하는 과정에서 발생하는 물리적 오차, 센서 불확실성 등
문제점과 하나의 정책이 평지, 불균일 지형 등 다양한 환경에서 동일하게 동작할 수 있는 ‘행동 생성 규칙’ 을 학습합니다.



 학습 포인트
학습 포인트
∙ 밀침(phsh) 등과 같은 외란으로 인한 정책 행동과 균형 매커니즘 변화 확인
∙ 환경 랜덤화를 통한 보행 정책 일반화 성능 향상
∙ Sim-to-Real을 고려한 설계 방법 학습
주요 실습 내용
∙ 물리 파라미터 랜덤화 적용 후 학습 결과 비교 분석
∙ 외란(push)을 주어 균형 회복 능력 검증과 경사면 및 불균일 지형에서 적응형 보행 구현
Point 04
강화학습과 NVIDIA Isaac Sim 기반
휴머노이드 보행 제어를 직접 알려주실 강사님을 소개합니다.
휴머노이드, 처음이라도 친절하게 알려드리겠습니다.
안녕하세요, 이번 강의를 진행하게 된 임현택이라고 합니다.
이번 강의에서는 최근 글로벌 휴머노이드 개발 기업들이 모두 표준으로 채택하고 있는 강화학습(PPO)과 NVIDIA Isaac Sim을 활용하여 휴머노이드 보행 제어 기술을 구현할 수 있는 강의를 준비하였습니다.
최근 Figure AI, NVIDIA, Tesla 등 글로벌 기업들의 휴머노이드 개발이 본격화되기 시작하면서 로봇 업계에서도 휴머노이드를 개발하면서 보행을 안정적으로 구현하는 기술에 대해 관심도가 높아지기 시작하였습니다.
그래서 이번 강의는
✓ 휴머노이드 개발 시 가장 대표적으로 활용되는 NVIDIA Isaac SIM 시뮬레이터 활용 방법부터
✓ 최근 글로벌 휴머노이드 보행 표준으로 받아들여지고 있는 PPO를 활용한 보행 정책 학습 과정
✓ 상체와 하체의 유기적인 움직임을 반영하고 강건한 Locomotion을 위한 Sim to Real 전략까지
이렇게 대표적인 3가지 기술을 학습하면서 시뮬레이션 환경에서 휴머노이드 로봇의 움직임을 목표에 맞게 디자인할 수 있는 역량을 배우시게 될 수 있습니다.
안녕하세요, 이번 강의를 진행하게 된 임현택이라고 합니다.
이번 강의에서는 최근 글로벌 휴머노이드 개발 기업들이 모두 표준으로 채택하고 있는 강화학습(PPO)과 NVIDIA Isaac Sim을 활용하여 휴머노이드 보행 제어 기술을 구현할 수 있는 강의를 준비하였습니다.
최근 Figure AI, NVIDIA, Tesla 등 글로벌 기업들의 휴머노이드 개발이 본격화되기 시작하면서 로봇 업계에서도 휴머노이드를 개발하면서 보행을 안정적으로 구현하는 기술에 대해 관심도가 높아지기 시작하였습니다.
그래서 이번 강의는
✓ 휴머노이드 개발 시 가장 대표적으로 활용되는 NVIDIA Isaac SIM 시뮬레이터 활용 방법부터
✓ 최근 글로벌 휴머노이드 보행 표준으로 받아들여지고 있는 PPO를 활용한 보행 정책 학습 과정
✓ 상체와 하체의 유기적인 움직임을 반영하고 강건한 Locomotion을 위한 Sim to Real 전략까지
이렇게 대표적인 3가지 기술을 학습하면서 시뮬레이션 환경에서 휴머노이드 로봇의 움직임을 목표에 맞게 디자인할 수 있는 역량을 배우시게 될 수 있습니다.

주요 진행 프로젝트 및 저서
· AI/Robotics 기술 관련 특허 다수 출원 및 등록
· 글로벌 빅테크 및 국내 대기업 등과의 협업 경험
· 오픈이노베이션 프로그램 및 기술 얼라이언스 등 다양한 사업화 경험 보유
· AI/Robotics 기술 관련 특허 다수 출원 및 등록
· 글로벌 빅테크 및 국내 대기업 등과의 협업 경험
· 오픈이노베이션 프로그램 및 기술 얼라이언스 등 다양한 사업화 경험 보유
전문 분야
· Robot Foundation Research(RFM) Research
· Humanoid / Manipulator Teleoperation
· Robot Control Interface Integration
· Classical Control & Dynamic Expertise
· Edge AI Model Optimization
· Robot Foundation Research(RFM) Research
· Humanoid / Manipulator Teleoperation
· Robot Control Interface Integration
· Classical Control & Dynamic Expertise
· Edge AI Model Optimization
패키지 상품
자율주행을 위한 기술부터 휴머노이드 보행 제어까지!
한 번에 끝내세요.

총 2과목
 자율주행을 위한 컴퓨터비전과 라이다 & 센서퓨전까지 초격차 패키지 Online.정가 1,100,000원
자율주행을 위한 컴퓨터비전과 라이다 & 센서퓨전까지 초격차 패키지 Online.정가 1,100,000원 NVIDIA Isaac Sim과 강화학습을 활용한 휴머노이드 보행 제어 정가 600,000원
NVIDIA Isaac Sim과 강화학습을 활용한 휴머노이드 보행 제어 정가 600,000원
ROS 2, SLAM & Navigation2를 기반으로 시뮬레이터 실무 프로젝트부터 휴머노이드 환경(RL)에서의 로봇 이동 제어까지
직접 구현하며 배우고 싶은 분들께 추천드립니다.
가격1,700,000원
할인 판매가63% 할인612,560원
12개월 할부월 51,047원

총 2과목
- NVIDIA Isaac Sim과 강화학습을 활용한 휴머노이드 보행 제어 정가 600,000원
 자율주행 로봇을 위한 ROS 2 & SLAM & Nav2 한번에 끝내기정가 1,000,000원
자율주행 로봇을 위한 ROS 2 & SLAM & Nav2 한번에 끝내기정가 1,000,000원
자율주행(ADAS & DMS) 필수 기술&실전 프로젝트부터
휴머노이드 환경(RL)에서 로봇 이동 제어 방법까지
배우고 싶은 분들께 추천드립니다.
가격1,600,000원
할인 판매가61% 할인612,560원
12개월 할부월 51,047원
04 부가혜택
강의 수강생들만을 위해 패스트캠퍼스가 준비한
특별 혜택까지 모두 놓치지 말고 가져가세요!


NVIDIA Isaac Sim과 강화학습을 활용한 휴머노이드 보행 제어
[특별 구성] 센서 퓨전 & 보행 로봇 제어 패키지
[특별 구성] ROS 2 & 보행 로봇 제어 패키지