
오픈소스 LLM으로 인프라 투자 없이 고성능 AI 모델 개발하기
점차 다가올 AI 서비스의 핵심 경쟁력은,
LLM의 고성능 추론 능력에 달려 있습니다.

DeepSeek 출현 이후 고성능 추론 기술이 AI 업계의 판도를 바꾸며,
OpenAI와 Meta를 비롯한 글로벌 기업들의 새로운 패러다임이 되고 있습니다.




이런 흐름에 따라 글로벌 기업의 리더들도
고성능 AI 서비스 개발에 필요한 LLM 추론 성능을 높이기 위해
공격적인 투자를 감행하며 촉각을 곤두세우고 있습니다.
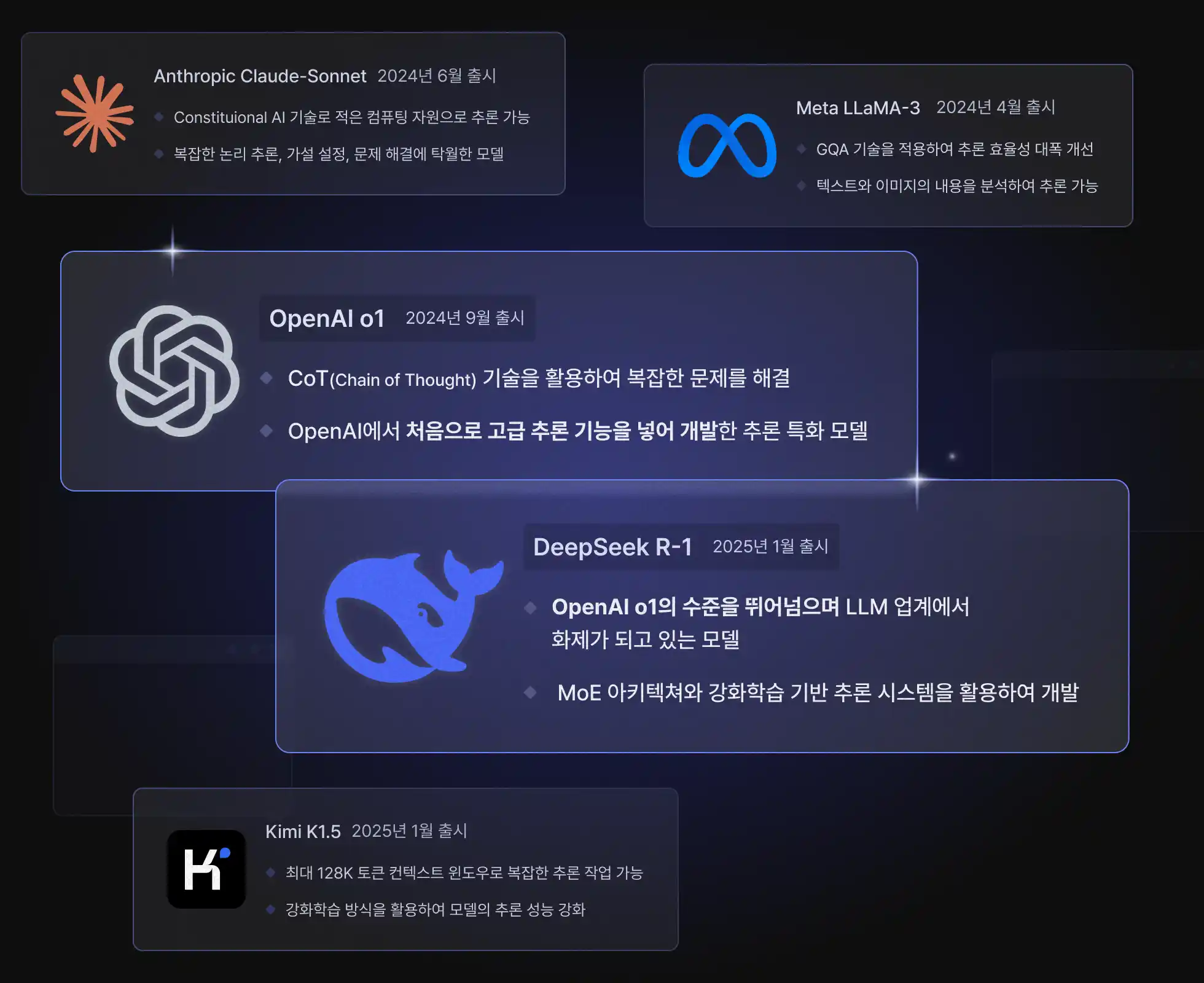
최근 화제가 되고 있는
OpenAI vs DeepSeek


Open-Ko & Open LLM 리더보드 최장기 1위 달성자 이승유와 함께하는
‘오픈소스 LLM으로 인프라 투자 없이 고성능 AI 모델 개발하기’

“ 실제 고성능 LLM을 구축하고
활용할 수 있는 실용적인 역량을 기를 수
있도록 강의를 구성했습니다. “
활용할 수 있는 실용적인 역량을 기를 수
있도록 강의를 구성했습니다. “
최근 LLM(대형 언어 모델) 분야는 빠른 발전을 거듭하며, OpenAI O1, Llama 3, DeepSeek R1, Claude 3.5 Sonnet 등 최신 모델들이
등장하고 있습니다. 이러한 모델들은 단순한 성능 개선을 넘어, 보다 효율적인 학습과 추론, 최적화된 비용 관리, 그리고 실질적인 활용성을 고려한 설계로 빠르게 진화하고 있습니다.
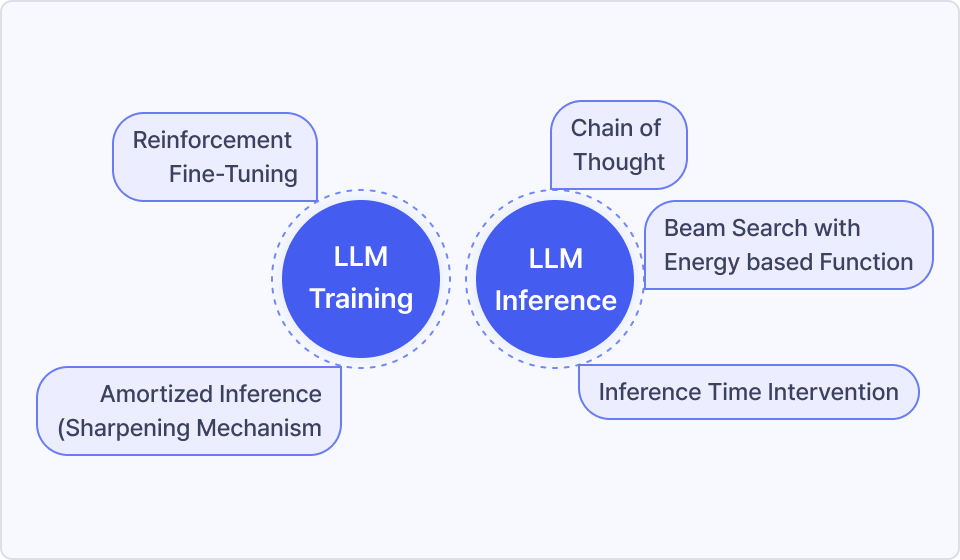
하지만, 이러한 변화 속에서 최신 기술을 정확하게 이해하고, 이를 실무에 적용하는 것은 쉽지 않은 도전입니다. 그래서 이번 강의에서는 Test Time Scaling(TTS), Chain of Thought(CoT), Reinforcement Fine-Tuning, Sharpening Mechanism 등 최신 연구에서 다루고 있는 핵심 기법들을
학습하고, 이를 직접 구현하며 실무에서 활용할 수 있도록 강의 내용을
구성하였습니다. 또한, Inference와 Training 별로 Cost를 최적화하는 방법을 이해하고, 모델을 효율적으로 운영할 수 있는 방안도 함께 다루게
됩니다. 단순히 이론을 배우는 것이 아니라, 실제로 고성능 LLM을 구축하고 활용할 수 있는 실용적인 역량을 기를 수 있도록 강의를 준비하였습니다.


인프라 투자를 최소한으로 줄이면서 오픈소스 LLM으로
DeepSeek R-1 급 성능의 LLM 모델을 개발할 수 있습니다.
2개의 파이널 프로젝트를 구현하면서 Deepseek R-1 급
성능을 보여주는 LLM 모델을 개발할 수 있습니다.
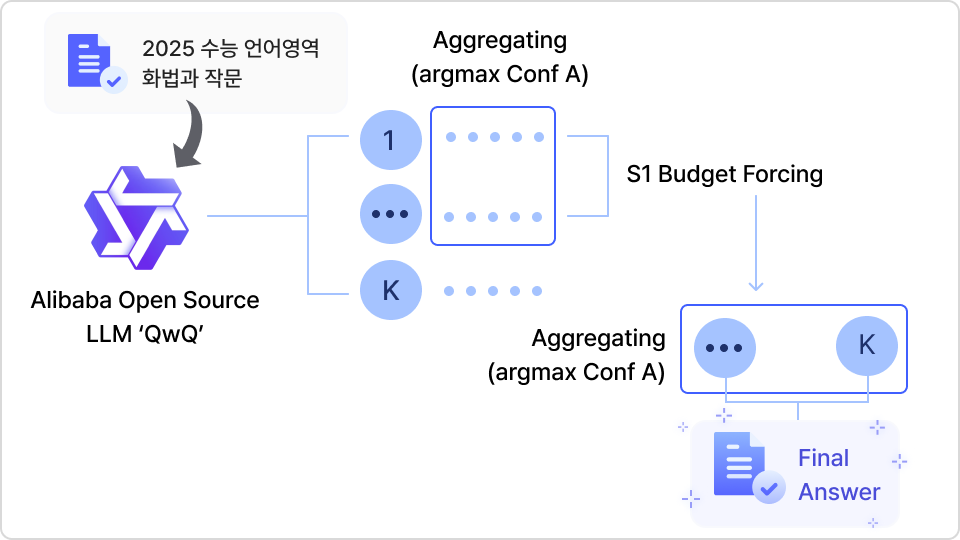
Final Porject 1.
인프라 투자 없이 오픈소스 LLM을 활용! DeepSeek R-1
벤치마크 수준 스코어링 기록해볼 수 있는 프로젝트 실습
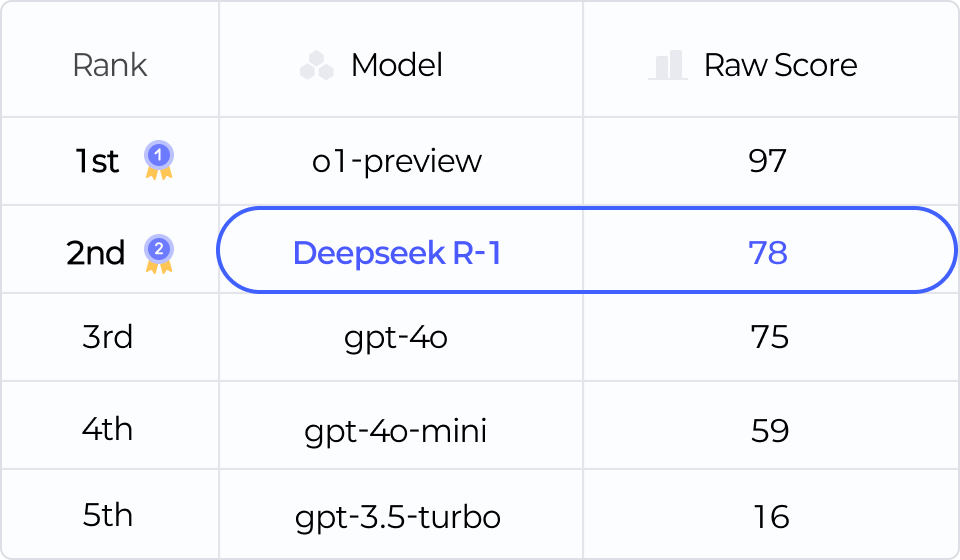
Test Time Scaling(Inference Cost 극대화) 기법으로 LLM의 답변 정확도를 높여 2025 수능 언어 영역 화법과 작문에서 DeepSeek R-1 벤치마크 수준의 스코어링을 기록해볼 수 있습니다.
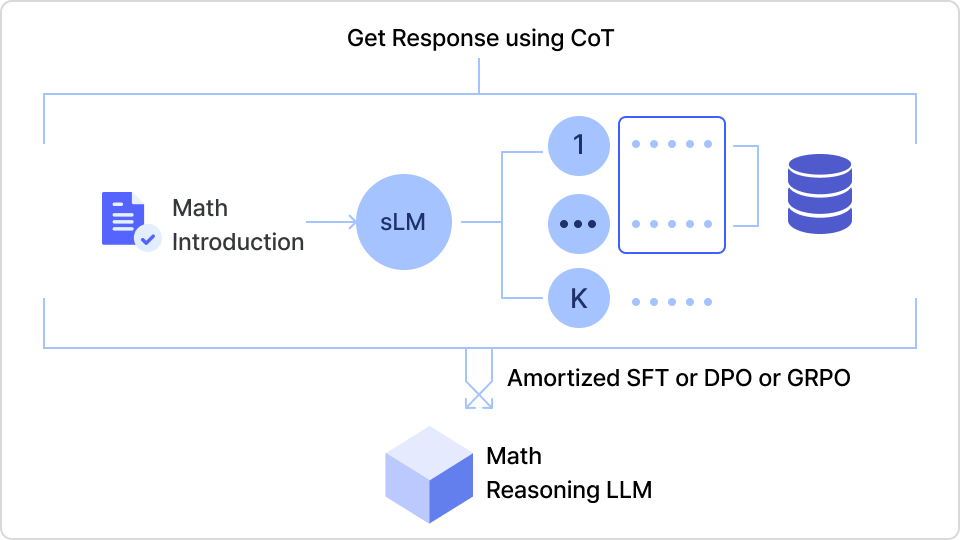
Final Project 2.
Test Time Scaling 기법을 적용한 LLM에 RL을 적용!
고성능 파운데이션 모델급 성능을 보여주는 추론 LLM 개발
증류 가능한 sLM에 RL(강화학습) 방식을 적용하여 LLM 모델 추론 성능을 높이는 방법을 학습하면서 DeepSeek R-1과 동일한 성능을 보이는 LLM 모델을
직접 실습하면서 개발해볼 수 있습니다.
이승유 강사님과
패스트캠퍼스가 준비한
오픈소스 LLM으로 인프라 투자 없이
고성능 AI 모델 개발하기 핵심 4가지 학습 포인트

Point 01
글로벌 Top 4 LLM이 두드러지는 성능을
보여주고 있는 이유 학습
최근 화제가 되고 있는 OpenAI o1, DeepSeek R-1부터 Meta, Anthropic 등
글로벌 AI 기업들이 개발한 LLM의 추론 구조를 학습합니다.
글로벌 AI 기업들이 개발한 LLM의 추론 구조를 학습합니다.
Point 02
LLM을 직접 훈련하면서 AI 서비스의
성능을 높일 수 있는 방법 학습
Training / Inference 단에서 추론 성능을 높이는 방법을 적용하여
고성능 AI 서비스를 개발하기 위한 방법을 학습합니다.
고성능 AI 서비스를 개발하기 위한 방법을 학습합니다.
Point 03
오픈소스 LLM 모델로 DeepSeek R-1 급
벤치마크 수준의 성능을 낼 수 있는 프로젝트 실습
오픈소스 LLM으로 2025 수능 언어영역 화법과 작문 문제를 풀이합니다.
Inference Cost를 극대화하여 DeepSeek R-1이 달성한 점수까지 점수를
끌어올려 높은 추론 성능을 보여줄 수 있는 프로젝트 실습을 진행합니다.
Inference Cost를 극대화하여 DeepSeek R-1이 달성한 점수까지 점수를
끌어올려 높은 추론 성능을 보여줄 수 있는 프로젝트 실습을 진행합니다.
Point 04
이승유 강사님과
직접 주고 받는 질의응답 커뮤니티
강의 수강 후 궁금한 점은 언제든 질문 가능한 질의응답 및 고퀄리티 AI
서비스 개발 노하우를 얻어갈 수 있는 수강생 전용 커뮤니티 운영!
운영 기간(2025년 3월 14일 ~ 2028년 3월 14일)
서비스 개발 노하우를 얻어갈 수 있는 수강생 전용 커뮤니티 운영!
운영 기간(2025년 3월 14일 ~ 2028년 3월 14일)






현 시점 개발자들이 가장 궁금해 할 핵심만 뽑아서 준비했습니다!
지금 바로 확인하세요!



Point 01
OpenAI o1부터 Claude까지, 글로벌 Top 4 LLM을
활용한 고성능 AI 모델 개발 방법 학습
현재 시장에서 가장 많은 선택을 받고 있는 LLM 모델들의 추론 구조와
이를 활용하여 AI 모델 개발 시 높은 성능을 낼 수 있는 방법을 학습합니다.

Slowly Thinking, Inference 비용을 높여서 CoT 기법을 적용한 OpenAI o1
| 학습 목표
강화학습(RL) 방식을 활용하여 까다로운 문제를 더 간단한 단계로 세분화하여 모델
추론 능력을 극적으로 향상시킬 수 있는 방법을 학습합니다.
| 주요 학습 내용
- CoT(Chain of Thought) Boosting 기법으로 단일 추론과 비교 시 더
정확하고 안정적인 결과를 도출하는 방법을 학습합니다.
- 특정 문제에 더 많은 추론을 요구할 경우 동적으로 리소스를 할당하여 성능을
최적화하는 방법을 학습합니다.

강화학습과 MoE 아키텍쳐를 활용하여 OpenAI o1 추론
성능을 능가하는 모델을 개발해 낸 DeepSeek R-1
| 학습 목표
오픈 소스로 시작해서 OpenAI o1급 모델 성능을 낼 수 있었던 DeepSeek의
모델 추론 성능 개선 방법을 학습합니다.
| 주요 학습 내용
- 그룹 내 상대적인 우위를 기반으로 보상 모델을 업데이트해서 계산 복잡도를
줄이는 GRPO 기법을 학습합니다.
- 대형 모델의 추론 능력을 소형 모델로 전이하면서 모델이 높은 성능을 유지할 수 있는 방법을 학습합니다.

GQA(Grouped Quary Attention)를 적용하여 추론 속도를 빠르게 진행하면서 성능을 유지하는 Meta LLaMA-3
| 학습 목표
대규모 언어 모델에서 방대한 양의 문맥 표현력과 빠른 추론 속도를 모두 활용하기 위해 MQA와 MHA의 장점을 결합한 GQA 방법론을 활용한 추론 구조를 학습합니다.
| 주요 학습 내용
- 사전 학습(Pre-Training) 과정과 LLM 훈련 시 Context Length를 고려하여
긴 문맥을 처리하는 방법을 학습합니다.
- LLM에서 Inference 성능을 유지하면서 메모리 절약이 가능하여 효율적인
trade-off를 조절하는 방법을 학습합니다.

설명 가능적 특성을 활용하여 LLM을 분석하고 해석 가능한 Feature로 분해하여 모델을 구성한 Claude-Sonnet
| 학습 목표
LLM 모델이 내부 구조를 잘 이해하고 예측을 제어하거나 수정하는 방식으로 모델 성능을 개선한 Claude-Sonnet의 추론 구조를 학습합니다.
| 주요 학습 내용
- 모델의 활성화 값을 분해해 각 특징이 단일 의미를 지닐 수 있는 방법을 학습합니다.
- Alignment Faking 현상을 이해하고 LLM 훈련 과정에서 이를 방지하기 위한
Alignment 검증 절차와 Red-Teaming 기법을 활용하는 방법을 학습합니다.
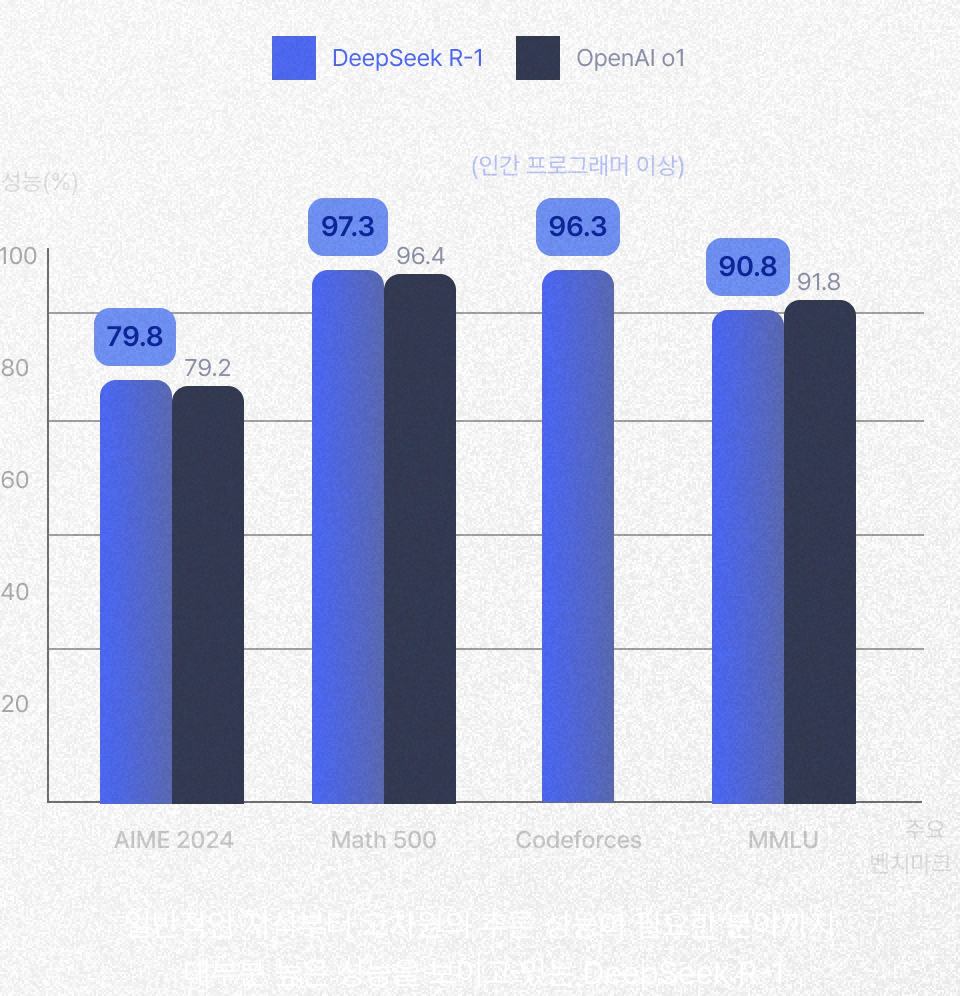
최근 DeepSeek R-1 모델 출현 이후에도 OpenAI o1 급 이상의 성능을 보이며
DeepSeek와 동일한 사고 추론 능력을 보유한 Kimi K 1.5 모델도 같이 학습 합니다.

RL(강화학습)을 적극적으로 활용하여 LLM이 직접적으로
사용자의 피드백 기반 Policy를 최적화 한 Kimi K 1.5
사용자의 피드백 기반 Policy를 최적화 한 Kimi K 1.5
| 학습 목표
LLM 모델이 출력을 평가하는 Reward Modeling과 PPO 알고리즘으로 모델을
업데이트하는 Process Reward 방식으로 추론 성능 개선 방법을 학습합니다.
| 주요 학습 내용
- Reward Modeling 학습과 Adaptaive Learning Rate으로 모델의 베이스
아키텍쳐 구조를 먼저 학습합니다.
- RL을 활용한 Policy Optimization과 Kimi의 핵심 방법론인 ‘커리큘럼’ 을 활용하여 장기적으로 난이도를 올리는 방향으로 모델 추론 성능을 높이는 방법을 학습합니다.
Point 02
AI 서비스를 개발하면서 자원 조건에 따라
LLM의 답변 정확도를 높이는 전략 학습
LLM을 활용하여 AI 서비스를 개발하면서 추가로 자원을 들이지 않고
모델의 답변 정확도(추론 성능)를 높일 수 있는 방법을 학습합니다.
Method 01
Test Time Scaling 기법을 활용하여 Inference 효율로 모델 추론 성능을 극대화하는 방법을 학습합니다.
Pre-Training 과정에서 자원 부족으로 고품질의 AI 서비스 개발이 어려울 때 Inference Cost로 모델 추론 성능을 높이는 방법을 학습합니다.
Chain of Thought Reasoning
Without Prompting
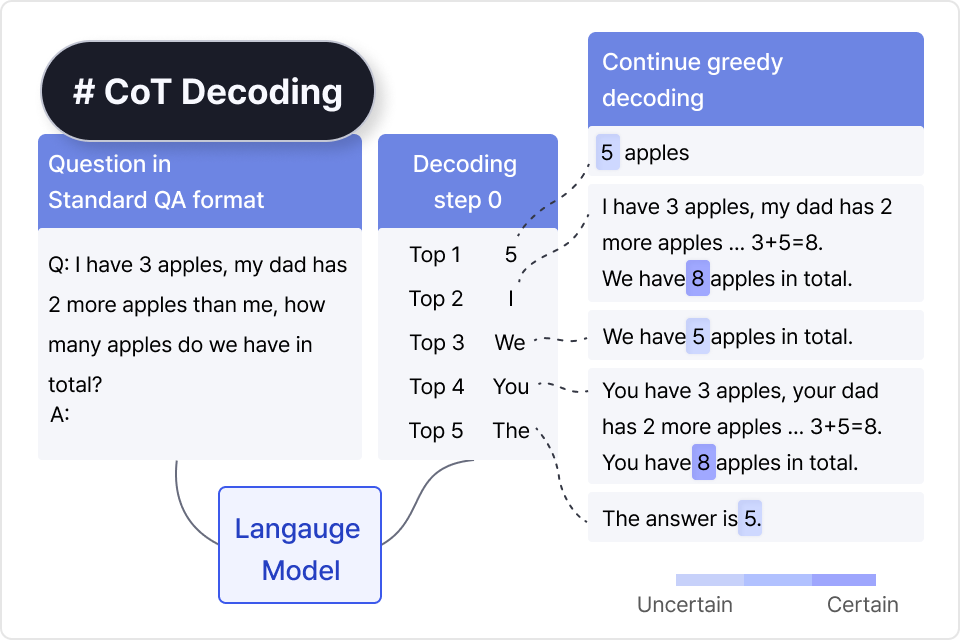
사용자의 입력을 기반으로 Top-K 개의 토큰을 하나 뽑아 내고, 뽑아낸 토큰을
기반으로 Greedy하게 답변을 생성해내는 방법을 학습합니다.
Without Prompting 사용자의 입력을 기반으로 Top-K 개의 토큰을 하나 뽑아 내고, 뽑아낸 토큰을 기반으로 Greedy하게 답변을 생성해내는 방법을 학습합니다.
| 학습 목표
LLM의 Decoding 과정에서 CoT Path를 찾음으로써 프롬프트 없이도 효과적으로
추론 성능을 올리는 방법을 학습합니다.
| 주요 학습 내용
- Decoding 과정에서 CoT를 적용하여 LLM의 Reasoning Ability를 향상시킬 수
있는 방법을 학습합니다.
- 답을 도출해내는 데 집중한 방법론으로, Top-K Decoding 방식을 학습합니다.

Linear AcT : Controlling Language and
Diffusion Models by Transporting Activations
LLM이 아웃풋 Token을 생성하기 위해 필요한 Activation의 Distribution을
Target Distribution으로 맵핑하여 특정 도메인 내 모델을 출력하는 방법을 학습합니다.
Diffusion Models by Transporting Activations LLM이 아웃풋 Token을 생성하기 위해 필요한 Activation의 Distribution을
Target Distribution으로 맵핑하여 특정 도메인 내 모델을 출력하는 방법을 학습합니다.
| 학습 목표
LLM의 신뢰성을 유지하기 위해 모델의 출력을 원하는 방향으로 유도하거나
특정 개념의 출현을 방지할 수 있는 방법을 학습합니다.
| 주요 학습 내용
- AcT(Activation Transport)를 활용하여 언어 모델의 독성 발화를 줄이고 특정
개념을 유도하게 하는 방법을 학습합니다.
- 모델의 활성화를 조정하여 원하는 출력 특성을 강화하거나 불필요한 특성
억제하는 방법을 학습합니다.
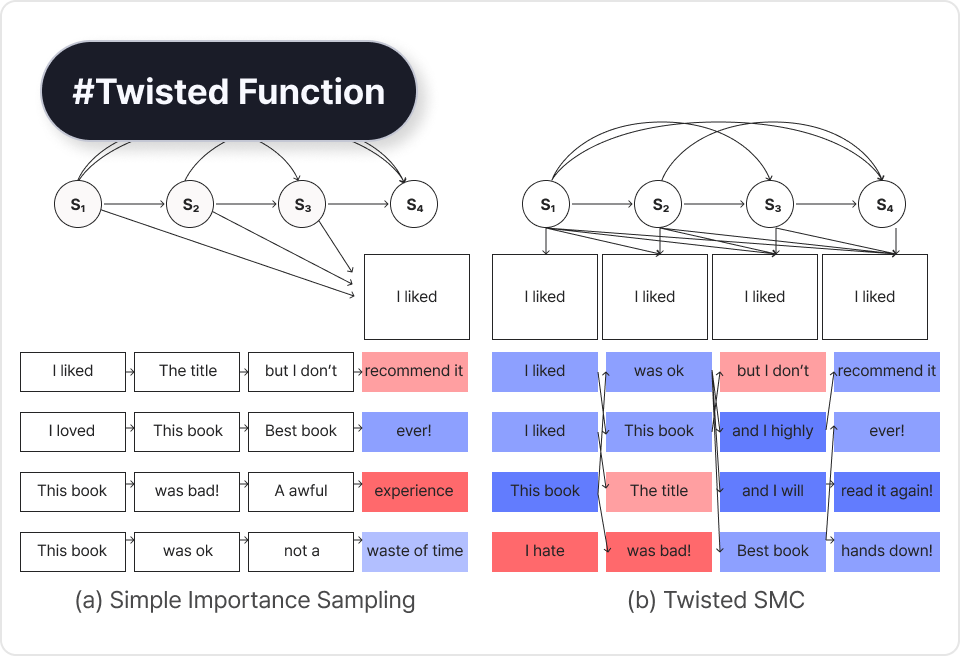
Probablistic Inference in Language Models via
Twisted Sequencial Monteo Carlo
LLM에서 발생하는 확률적 추론 문제를 해결하기 위해 추론 시점에서의 연산 시
더 좋은 결과가 기대되는 시퀀스에 집중하여 샘플링하는 방법을 학습합니다.
Twisted Sequencial Monteo Carlo LLM에서 발생하는 확률적 추론 문제를 해결하기 위해 추론 시점에서의 연산 시
더 좋은 결과가 기대되는 시퀀스에 집중하여 샘플링하는 방법을 학습합니다.
| 학습 목표
특정 훈련 없이, Token 단위에서 모델의 출력을 효과적으로 제어하여 출력을 조정할 수 있는 방법을 학습합니다.
| 주요 학습 내용
- Potential Function이라 불리는 Energy Based Function을 통해 만들 수 있는
Twist Function으로 모델 생성을 중간에 개입하여 특정 출력을 조정하는 방법을
학습합니다.
- Fine-Tuning 후, Catastropic Forgetting 현상을 방지하여 모델의 최적화 된 성능을
확보하는 방법을 학습합니다.

S1 :
Simple Test-Time Scaling
Budget Forcing 개념을 도입하여 모델의 테스트 시점에서 데이터와 연산량을 조절하여
모델의 성능을 최적화하는 방법을 학습합니다.
Simple Test-Time Scaling Budget Forcing 개념을 도입하여 모델의 테스트 시점에서 데이터와 연산량을 조절하여 모델의 성능을 최적화하는 방법을 학습합니다.
| 학습 목표
소량의 데이터를 효과적으로 선별하였을 때, 강력한 추론 능력을 학습할 수 있는지
검증할 수 있는 방법을 학습합니다.
| 주요 학습 내용
- 기존 LLM을 재 훈련하지 않아도 모델의 성능(정확도)를 향상시킬 수 있는 방법을
학습합니다.
- Budget Forcing 기법을 활용하여 LLM이 사용하는 Test-Time 컴퓨팅 양을
제어하는 방법을 학습합니다.
Method 02
Train Time Scaling 기법을 활용하여 Train 자원을 쏟아 모델 추론 성능을 극대화하는 방법을 학습합니다.
자원이 충분한 상황에서 더 고품질의 AI 서비스를 개발하기 위해 Training Cost로 모델 추론 성능을 높이는 방법을 학습합니다.

Reinforcement Fine-Tuning
초기에 사람이 선호하는 방향으로 모델을 튜닝하여 학습했던 방식부터
더 단순하고 적은 연산량으로 모델을 강화해나가는 방법을 학습합니다.
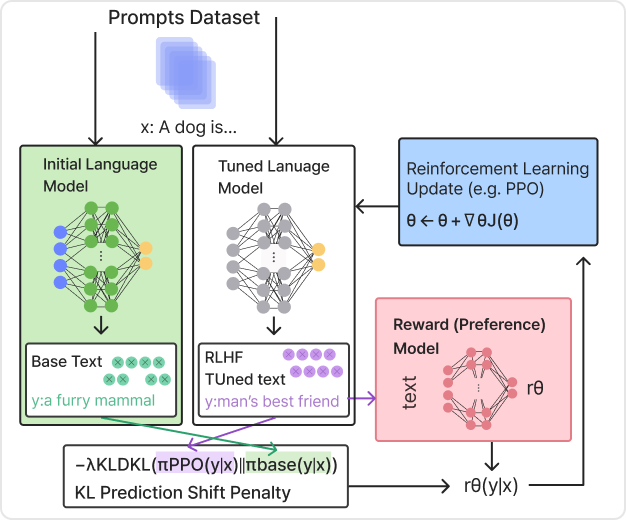
RLHF(Reinforcement Learning with Human Feedback)
| 학습 목표
보상 모델을 사용하여 정책(Policy)을 최적화 해
모델 성능을 올리는 방법을 학습합니다.
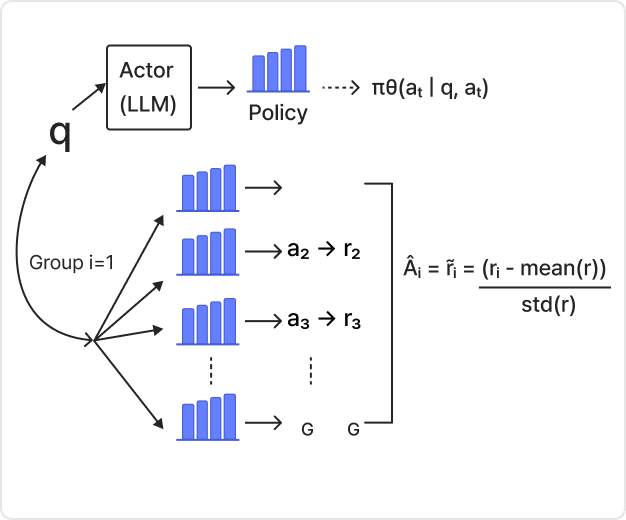
GRPO(Group Relative Policy
Optimization)
| 학습 목표
상대적 선호도 그룹 데이터를 활용하여 보상 모델을
별도로 학습할 필요 없이 직접 최적화하여 모델
성능을 올리는 방법을 학습합니다.
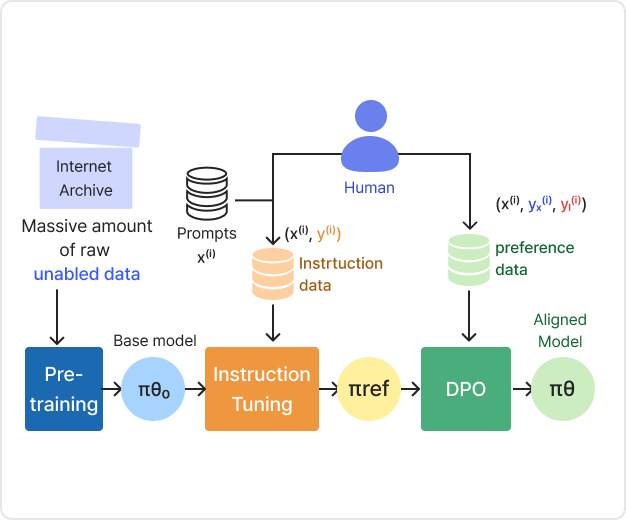
DPO
(Direct Preference Optimization)
| 학습 목표
보상 모델을 사용하지 않고, 모델 자체를 선호도
데이터로 직접 학습하여 연산량을 줄이면서
모델
성능을 높이는 방법을 학습합니다.
sharpening Mechanism
추가적인 데이터 없이 특정 질문 시, 라벨링 없이 LLM이 스스로 내밷은 답을
학습하여 모델 성능을 높여 나가는 방법을 학습합니다.
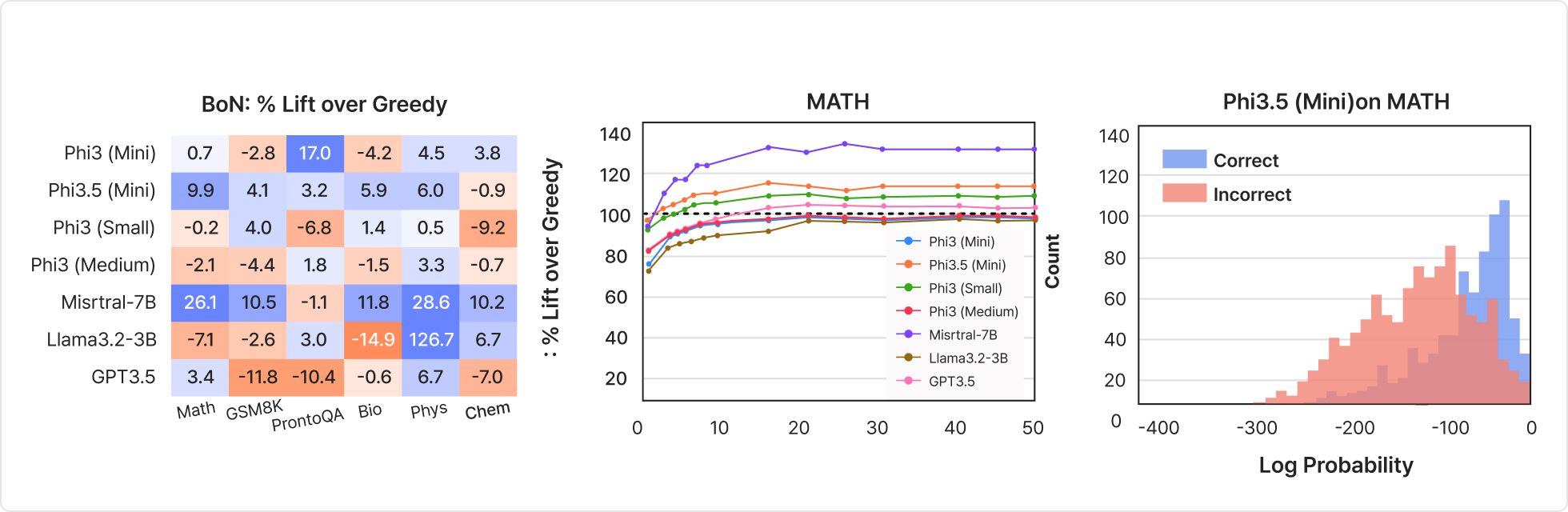
| 주요 학습 내용
- Test Time Scaling에서 소요되는 Inference 자원을 Train 자원으로 변환하여 Train 자원만으로 LLM 모델 성능을 높여 나가는 방법을 학습합니다.
- Test Time Scaling에서 소요되는 Inference 자원을 Train 자원으로 변환하여 Train 자원만으로 LLM 모델 성능을 높여 나가는 방법을 학습합니다.
| 학습 내용
- Reward로 Logprobs를 활용하고 가장 높은 Reward의 Sequence를 추려 Labeling해 학습하는 방법을 학습합니다.
- Reward가 가장 높은 답변을 Greedy Decoding으로 생성하고 LLM의 Test-Time을 Train-Time에 전가하여 활용하는 방법을 학습합니다.
- Reward로 Logprobs를 활용하고 가장 높은 Reward의 Sequence를 추려 Labeling해 학습하는 방법을 학습합니다.
- Reward가 가장 높은 답변을 Greedy Decoding으로 생성하고 LLM의 Test-Time을 Train-Time에 전가하여 활용하는 방법을 학습합니다.
Point 03
인프라 투자 없이 저성능의 LLM을 DeepSeek R-1 급으로
끌어올리기 위한 2개의 인프라 투자 없이 파이널 프로젝트 구현
Test Time Scaling 기법으로 벤치마크 내 DeepSeek R-1급 이상의 스코어링을 기록하고
sLM에 GRPO 기법을 적용하여 DeepSeek R-1과 동일한 성능의 모델을 개발하는 프로젝트를 구현합니다.
Final Project 01
인프라 투자 없이 QwQ 오픈소스 모델로 DeepSeek R-1 급 성능 따라잡기
2025년 수능 언어영역 화법과 작문 문제를 오픈소스 모델 QwQ로 풀면서
penAI LLM이 기록한 점수보다 높은 점수를 달성해볼 수 있습니다.
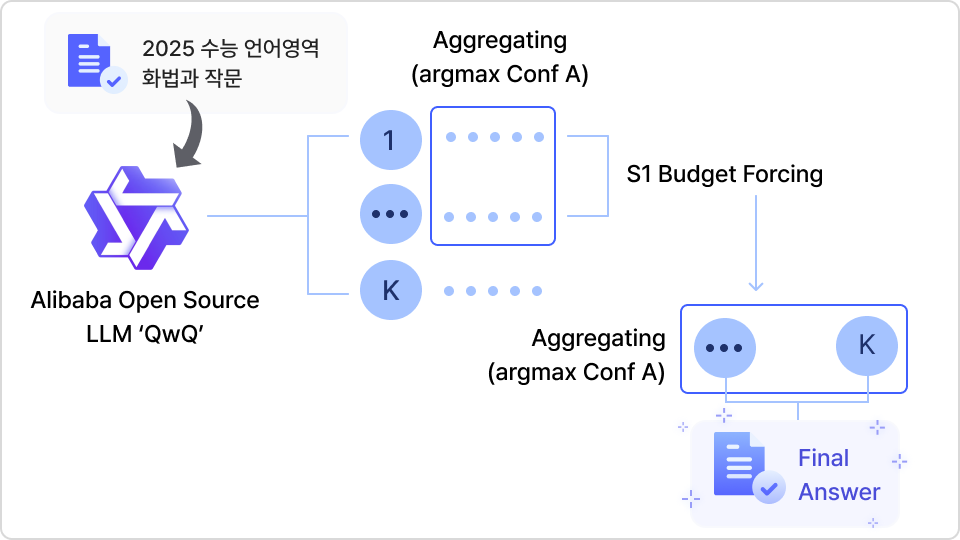
실습 구현 목표
∙ 학습(Training)에 자원을 하나도 들이지 않고 Test Time Scaling 기법만을 활용하여 DeepSeek R-1 급 이상의 점수(78점)을 능가할 수 있는 모델을 만들어볼 수 있습니다.
주요 학습 내용
∙ Chain of Thought(CoT) without Prompting과 S1 방법론을 활용하여 LLM의
추론 능력을 효과적으로 개선하는 방법을 학습합니다.
주요 학습 내용
∙ Chain of Thought(CoT) without Prompting과 S1 방법론을 활용하여 LLM의
추론 능력을 효과적으로 개선하는 방법을 학습합니다.
Final Project 02
TTS로 생성한 LLM 모델을 학습하여 DeepSeek R-1 수준의 고급 추론 모델 개발하기
TTS로 생성한 최적의 결과물에 Sharpening Mecanism을 적용하여
DeepSeek R-1과 같은 LLM 모델을 만들어볼 수 있습니다.
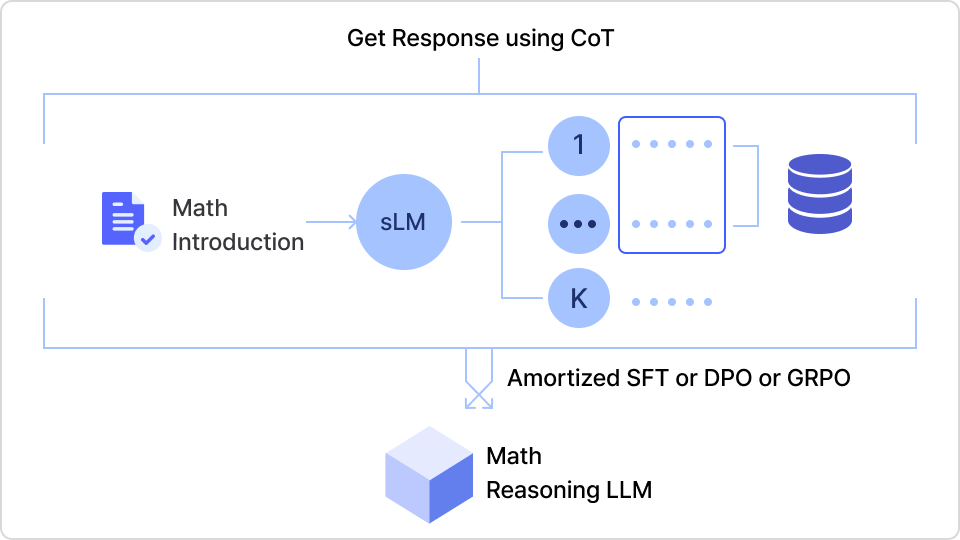
실습 구현 목표
∙ Test Time Scaling으로 구성해 낸 모델에 Train Time Scaling 기법을 같이 적용하여 학습 자원 활용만으로 DeepSeek R -1 수준의 모델을 만들어볼 수 있습니다.
주요 학습 내용
∙ 학습 초기부터 대규모 데이터가 아닌 그룹 상대 정책 최적화 방식으로 생성한 학습
샘플 기반 소형 밀집 모델을 Fine-Tuning하여 결론적으로 낮은 자원 소모량만으로도
높은 추론 성능을 기대해볼 수 있는 LLM을 개밸할 수 있는 역량을 기를 수 있습니다.
주요 학습 내용
∙ 학습 초기부터 대규모 데이터가 아닌 그룹 상대 정책 최적화 방식으로 생성한 학습
샘플 기반 소형 밀집 모델을 Fine-Tuning하여 결론적으로 낮은 자원 소모량만으로도
높은 추론 성능을 기대해볼 수 있는 LLM을 개밸할 수 있는 역량을 기를 수 있습니다.
강의 미리보기
Q&A
Question. 1
어떤 분들이
수강하시면 좋을까요?
수강하시면 좋을까요?
- LLM을 활용하여 AI 서비스를 개발하려고 하시는 개발자
- 기본적인 코딩과 LLM에 대한 기초 개념에 대한 이해가 있는 개발자
Question. 2
해당 주제를 학습할 때 겪는
대표적인 어려움은 무엇인가요?
대표적인 어려움은 무엇인가요?
LLM의 구조와 학습 방식이 복잡하며, 단순히 모델을 사용하는 것과 이를
최적화하는 것은 차원이 다른 문제입니다. 특히, 모델의 크기가 커질수록 학습 비용이
급격히 증가하고, 성능을 향상시키기 위한 방법론을 이해하고 적용하는 것이
쉽지 않습니다. 또한, 최신 기법들은 논문에서 소개되지만, 이를 실제로 코드에 적용하는
과정에서 많은 시행착오가 필요하며, 정확한 방법론을 적용하지 않으면 재현의
어려움이 있습니다.
Question. 3
필요한
선수지식이 있을까요?
선수지식이 있을까요?
- LLM 모델 구조의 기초 개념에 대한 이해
Question. 4
개발 환경
- Test Time Scaling 기법을 활용하여 Linux 기반 H 100 8장의 GPU 서버 활용
- Mac & Windows 모든 환경에서 수강 가능
오픈소스 LLM으로 인프라 투자 없이 고성능 AI 모델 개발하기