
SPECIAL POINT 01
파운데이션 LLM 개발
필수 3가지 핵심 개념 학습!
지식 습득 부족, 호환성 부족 문제를 타파할 수 있는
파운데이션 LLM 개발 방법 학습
복제:초격차 패키지 : LLM 모델 개발 Signature
주요 국가 별 초거대 LLM 보유 현황
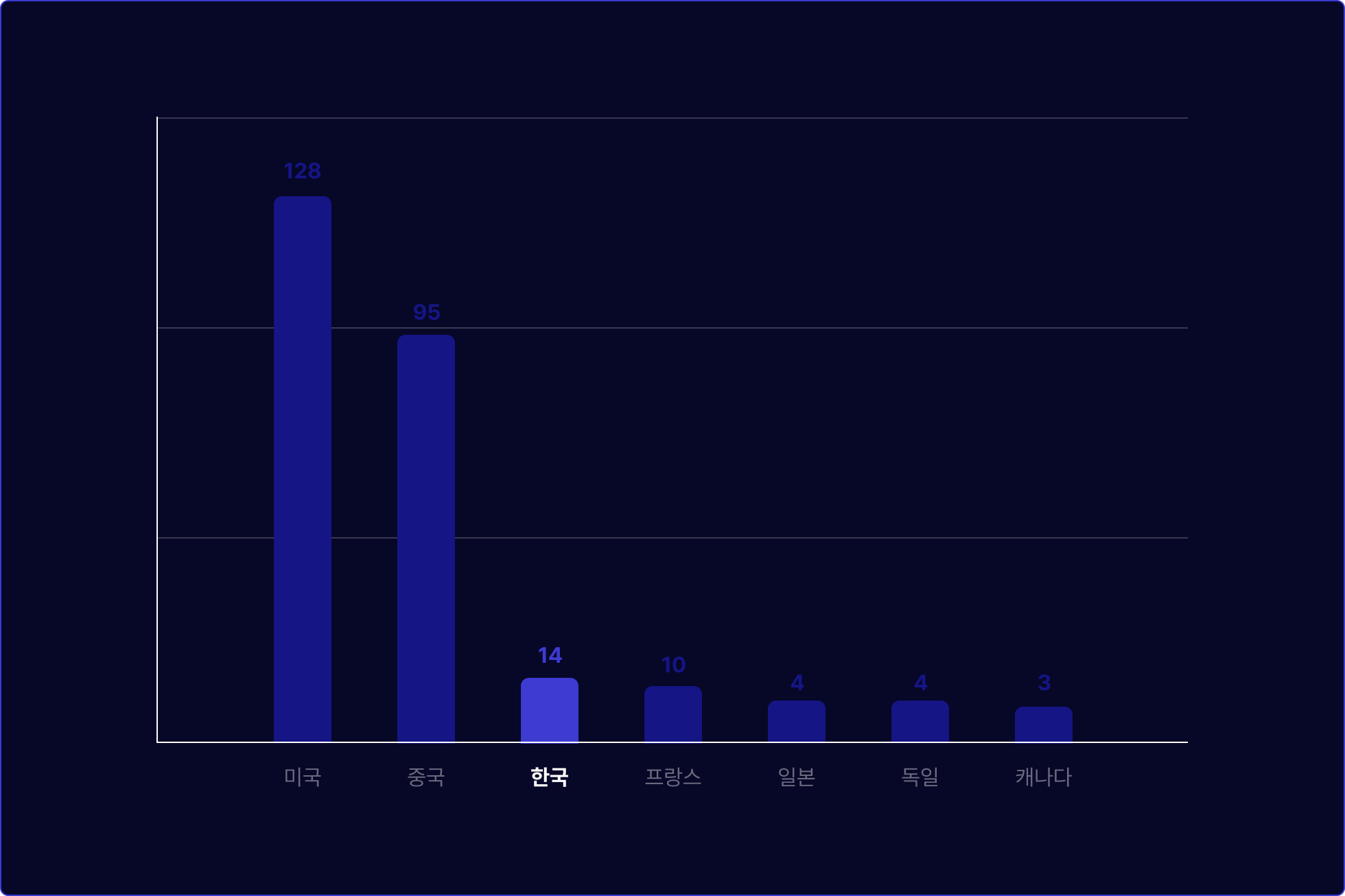
출처 : 글로벌 초거대 AI 모델 현황 분석 (2024, 소프트웨어정책연구소)
글로벌 LLM 경쟁에서 뒤쳐진 지금,
파운데이션 LLM 개발 역량은 그 어느 때보다 더욱 중요합니다.




핵심 3가지 기술로 파운데이션 LLM을 개발할 수 있는
학습 커리큘럼을 준비하였습니다.
이 모든 과정을 컴팩트하게 끝내줄 단 하나의 강의
초격차 패키지 : LLM 모델 개발 Signautre
국내 최초
파운데이션 LLM 개발 과정 학습을 위한
4가지 SPECIAL 포인트!
SPECIAL POINT 02
현직 대기업 LLM 엔지니어 &
AI 연구원 직강 GS ITM, 대기업, 국내 리더보드 최장기 파인튜닝
1위 모델 개발 경험 연구원 강사님과 함께하는 강의
AI 연구원 직강 GS ITM, 대기업, 국내 리더보드 최장기 파인튜닝
1위 모델 개발 경험 연구원 강사님과 함께하는 강의

SPECIAL POINT 03
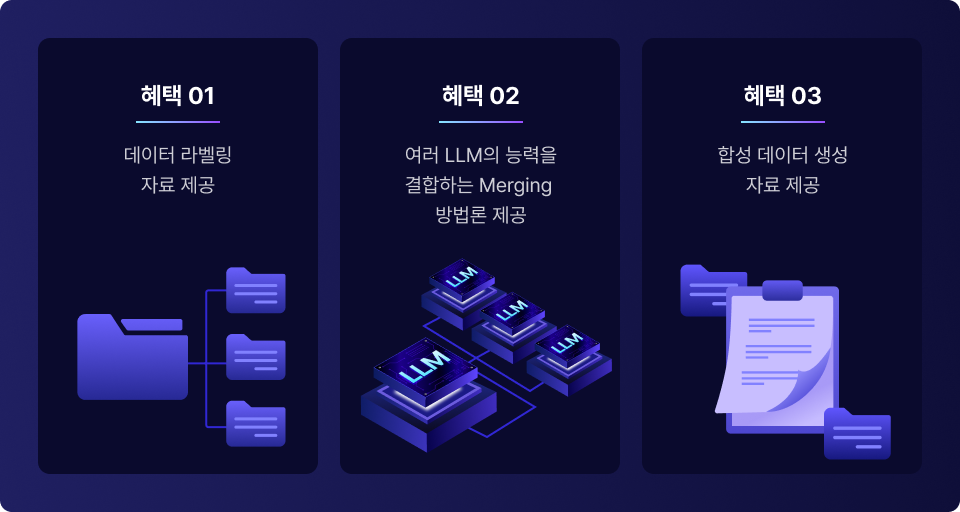
기본기를 다질 수 있는
탄탄한 부가자료 혜택까지! 파운데이션 LLM을 개발하면서 모델 성능을
한끗 더 높여줄 수 있는 3가지 부가 자료 제공
탄탄한 부가자료 혜택까지! 파운데이션 LLM을 개발하면서 모델 성능을
한끗 더 높여줄 수 있는 3가지 부가 자료 제공
강의 마지막 오픈 일정인 12월 26일에 공개합니다.
SPECIAL POINT 04
학습 중 궁금한 점이 있다면
언제든 질문할 수 있는 무한 질의응답 실습 중 에러가 나거나 이해가 되지 않는다면 바로 질문 해 보세요!
질의응답 운영 일정 : 2025년 10월 2일부터 2028년 7월 29일까지
언제든 질문할 수 있는 무한 질의응답 실습 중 에러가 나거나 이해가 되지 않는다면 바로 질문 해 보세요!
질의응답 운영 일정 : 2025년 10월 2일부터 2028년 7월 29일까지
파운데이션 LLM 개발 과정이 궁금하셨다면?
지금 이 영상 무조건 꼭 보셔야 합니다!
트레일러
커리큘럼 소개
4가지 핵심 포인트로 배우는
파운데이션 LLM 개발
범용 상황에서 높은 성능을 보이는 1B Reasoning LLM을 개발하기 위해
사전학습 과정부터 경량화, GPU 활용 방법까지 LLM을 체계적으로 설계




POINT 1
파운데이션 모델 개발의 시작점,
3단계로 끝내는 Pre-Training



1단계 : 파운데이션 모델 아키텍쳐
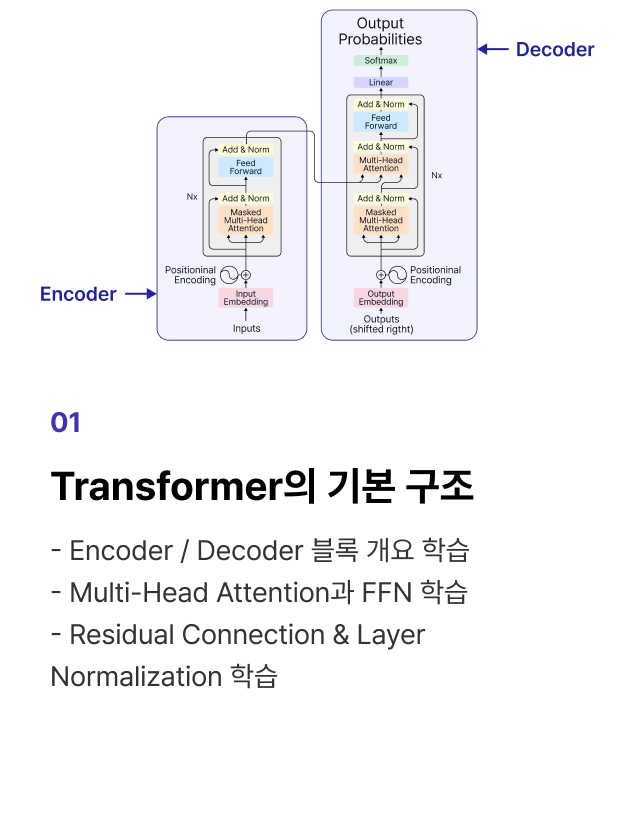
Transformer의 기본 구조 학습
Transformer 구조 기반의 파운데이션 모델 원리와
최신 아키텍쳐 설계 기법을 학습합니다.
개념 학습 Pre-Training 기초 모델 구조의 이해와 최신 아키텍처 설계 기법을 학습합니다.
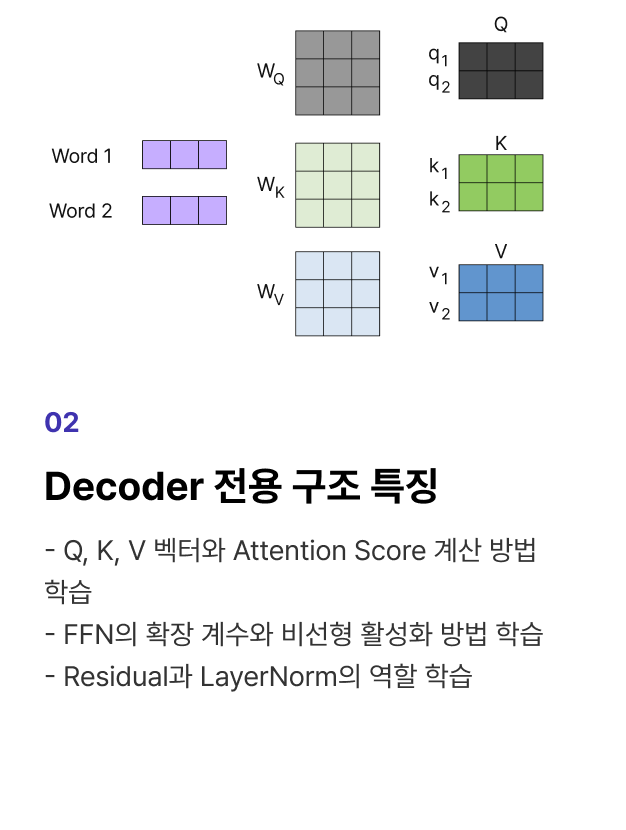

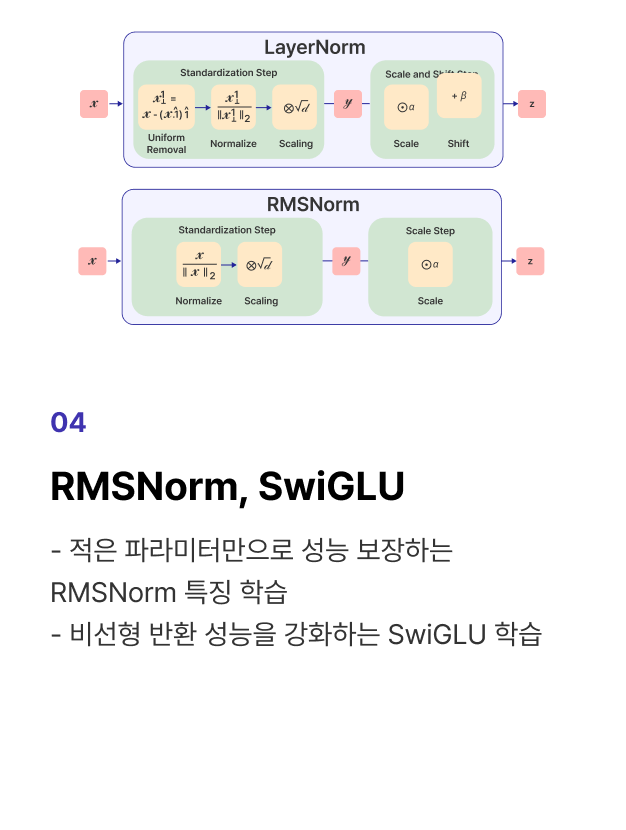

프로젝트 실습 Pre-Training 모델의 뼈대를 구현할 수 있는 1B Config 설계
| 프로젝트 목표
Config 설계란 LLM이 어떤 ‘사고 구조’ 를 가질 지 설정하는 설계도입니다.
Hugging Face Tiny Llama로 모델의 구조가
학습과 성능에 어떤 영향을 미치는 지 알아볼 수 있는 Config 설계 실습을 진행합니다.
| 프로젝트 실습 과정

2단계 : 데이터 구조·생성·정제
Pre-Training을 위한
데이터 셋의 구조와 특성 학습
언어 판별, 노이즈 & 중복 제거 등 전처리 기법으로 데이터 품질을 높이고
토크나이저 설계 방법을 학습합니다.
개념 학습과 실습 적용 Pre-Training 데이터 파이프라인을 구축하는 방법을 학습합니다.
01
Pre-Training
데이터 셋의 특징
▶ 학습 내용 보기
02
데이터의 구조 설계
▶ 학습 내용 보기
03
데이터 수집(CommonCrawl,
CCNet 파이프라인)
▶ 학습 내용 보기
04
Pre-Training
데이터 전처리 (1)
▶ 학습 내용 보기
05
Pre-Training
데이터 전처리 (2)
▶ 학습 내용 보기
06 Deduplication(MinHash, LSH, K-Shingle)
▶ 학습 내용 보기
07
개인정보와 저작권 필터링
▶ 학습 내용 보기
08 토크나이저 설계 (SentencePiece, BPE)
▶ 학습 내용 보기
09
데이터 셋 품질 관리
▶ 학습 내용 보기
3단계 : Pre-Training
일반화 성능 확보에 핵심인
Pre-Training 모델 설계
데이터 수집부터 전처리, 토크나이저 구축, 소규모 모델 학습까지
Pre-Training 파이프라인 개발 방법을 학습합니다.
개념 학습 Pre-Training 기초 모델 구조의 이해와 최신 아키텍처 설계 기법을 학습합니다.

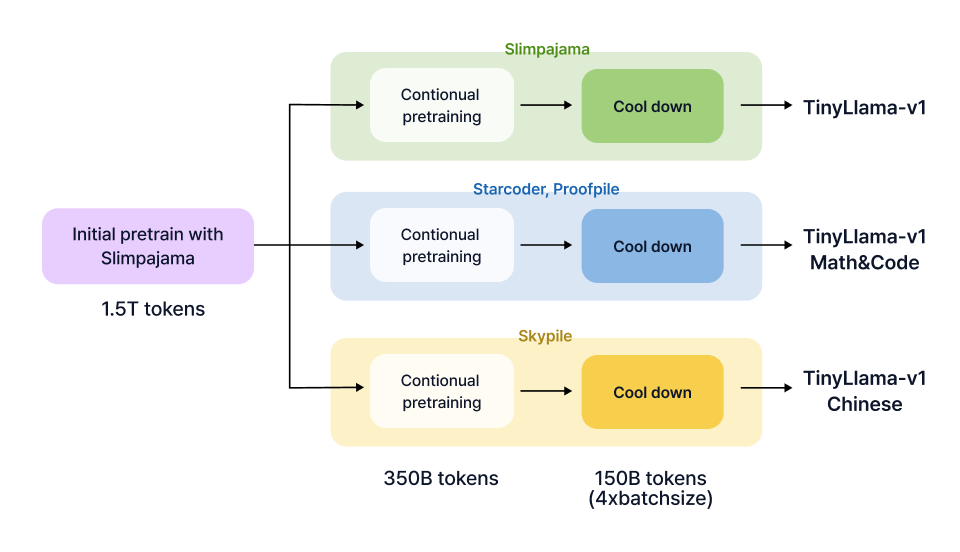
프로젝트 실습 TinyLlama Config로 mini 모델 Pre-Training 파이프라인 구축
| 프로젝트 목표
Colab과 GPU 환경에서 각각 Pre-Training 모델을 학습하고,
정량/정성 지표를 활용해 Pre-Training 모델을 평가 & 개선하는 방법을 학습합니다.
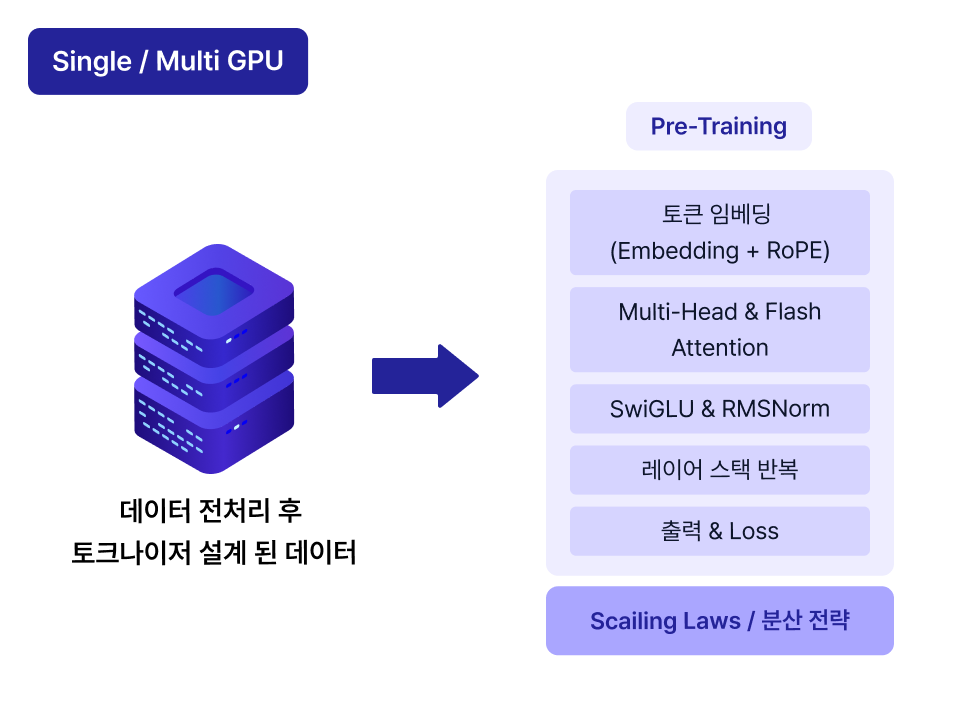
| 프로젝트 실습 과정

POINT 2
Reasoning LLM 개발을 위해
3단계로 끝내는 Post-Training



1단계 : CPT
Pre-Training 후,
특정 분야 능력을 강화하기 위한 CPT 학습
Reasoning에 특화 된 CPT 데이터 셋 설계와
LLM 성능 강화를 위한 학습 방법론을 이해합니다.
프로젝트 실습 Standard & Reasoning CPT 학습 모델 구축 및 평가
| 프로젝트 목표
CPT가 Post-Training 과정에서 왜 필요한지 이해할 수 있습니다.
그 후, Reasoning 성능을 올리기 위한
CPT 적용 방법과 LLM 성능 강화 및 평가 방법을 학습하여 Robust한 CPT 모델을 개발합니다.
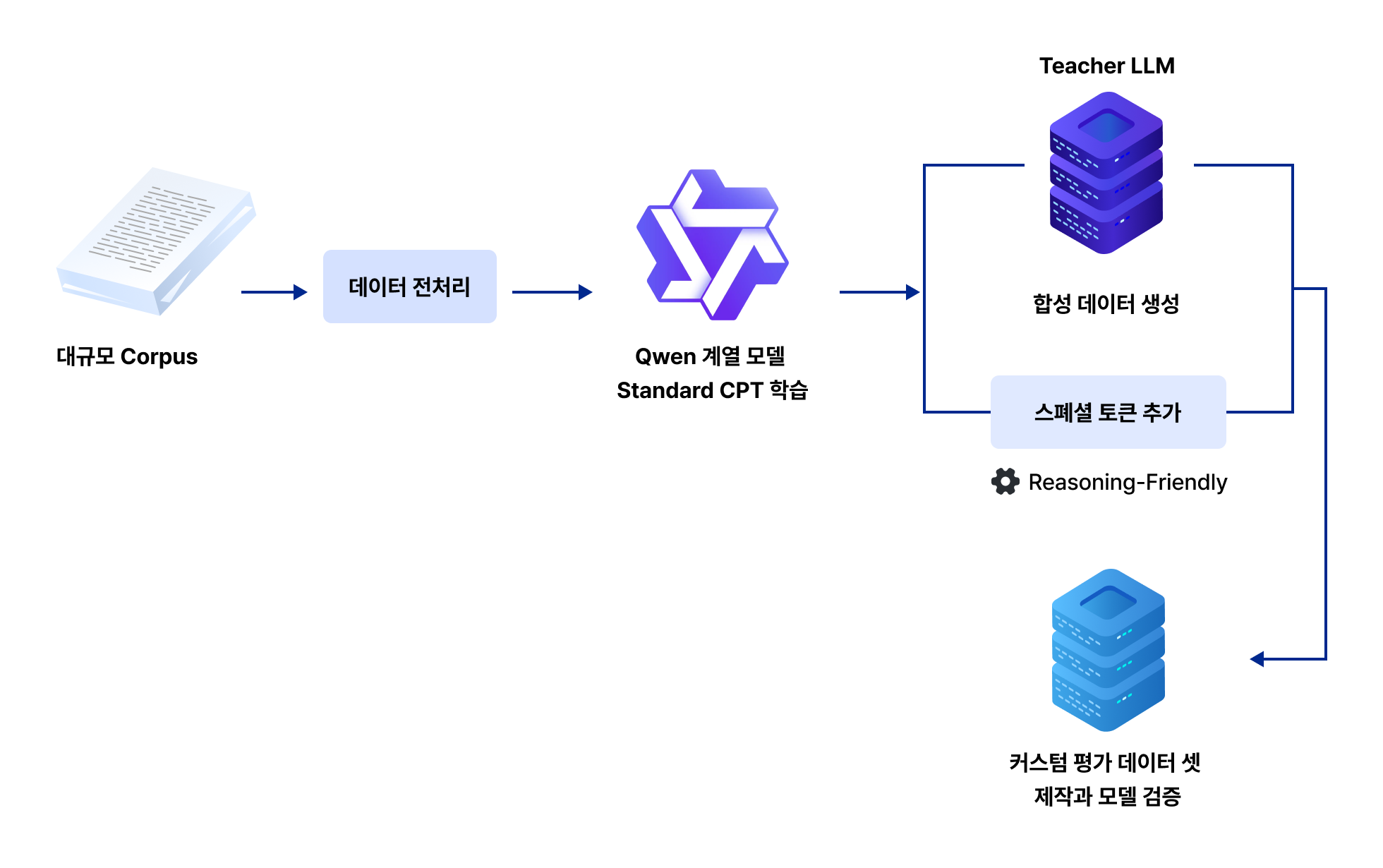



2단계 : SFT
지시에 따라 일관된 답변을 생성하는 SFT 학습
Reasoning에 특화 된 SFT 데이터 셋 설계와
LLM 성능 강화를 위한 학습 방법론을 이해합니다.
개념 학습 SFT의 개념과 데이터 셋 설계 목적을 이해합니다.



프로젝트 실습 정답의 도출 과정을 논리적으로 추론하는 Reasoning SFT 모델 구축 및 평가
| 프로젝트 목표
단순히 최종 답을 주는 것이 아니라 문제 풀이 과정을 Step-by-step으로 해결 가능한 SFT 모델을 개발합니다.
또한 합성 데이터를 생성하고 Particle Supervision 등의 방법으로 품질을 개선하는 방법도 같이 학습합니다.

3단계 : DPO
샘플링 없이도
직접 선호 최적화로 답변을 생성하는 DPO
Reasoning에 특화 된 DPO 데이터 셋 설계와
LLM 성능 강화를 위한 학습 방법론을 이해합니다.
개념 학습 사람의 직접 선호도에 맞춰 모델을 학습하는 DPO의 개념 학습



프로젝트 실습 추론 과정의 품질을 고려하여 모델을 학습하는 Reasoning DPO 모델 구축 및 평가
| 프로젝트 목표
Synthetic Preference 데이터를 구축하고 Good/Bad Reasoning Path를 생성하여
높은 품질의 Reasoning DPO 모델을 구축합니다.
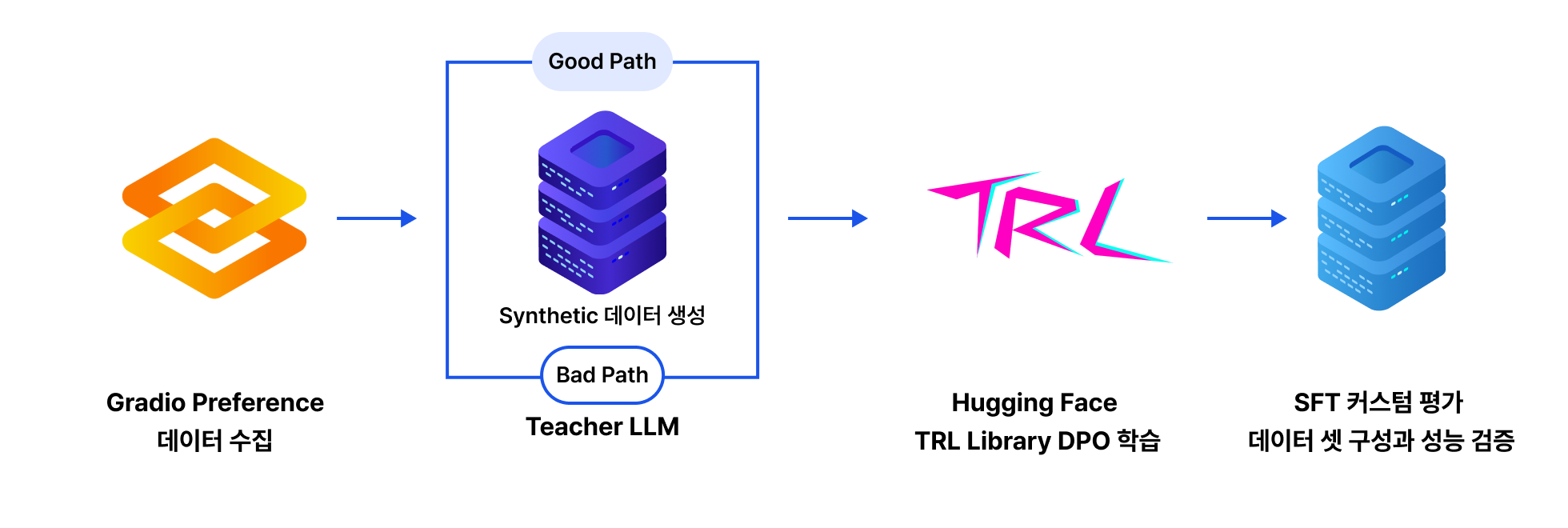
POINT 3
Reasoning LLM을 사용 단계에서
4단계로 최적화하는 방법 학습




1단계 : Inference
학습 된 LLM으로 텍스트를 생성하는 Inference
학습 된 LLM으로 사용자가 질문을 하였을 때
답변을 직접 생성하는 방법을 학습합니다.
개념 학습 (1) LLM이 다음 단어를 예측하고 문장을 생성하는 Decoding Strategy

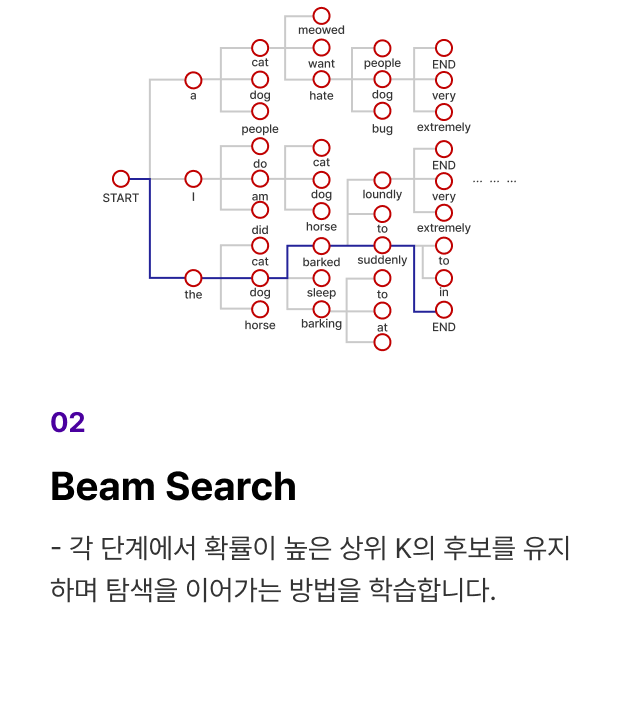
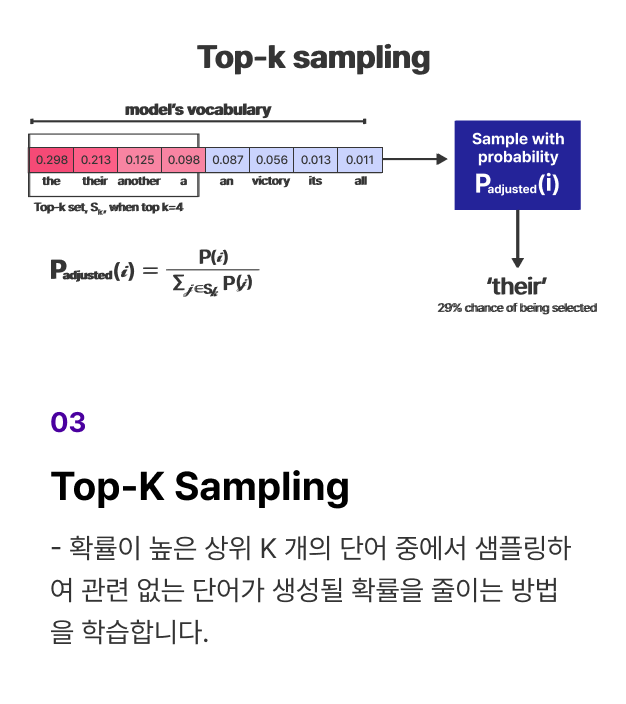
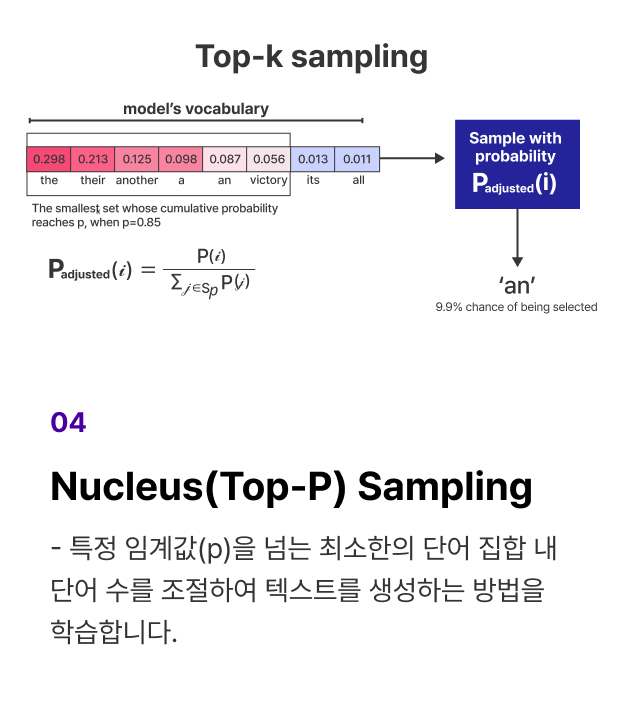


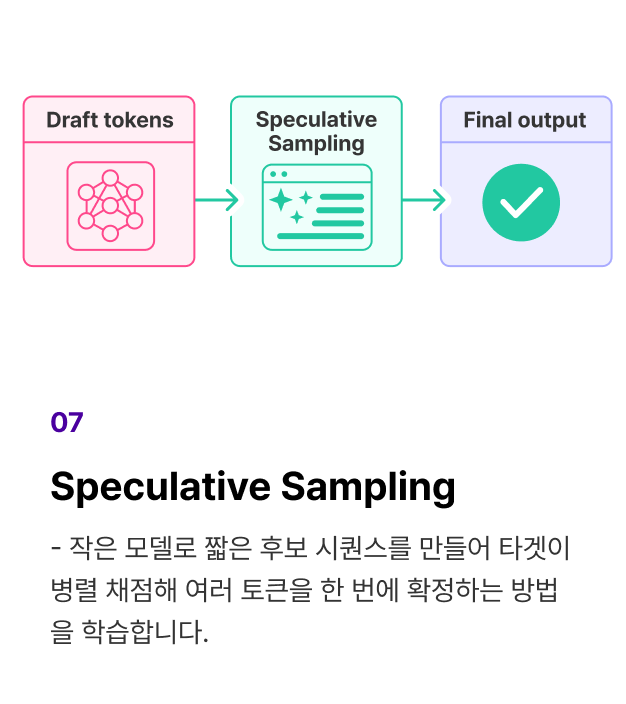
개념 학습 (2) LLM의 추론 속도를 높이고 메모리 사용량을 줄이는 Inference 최적화 전략
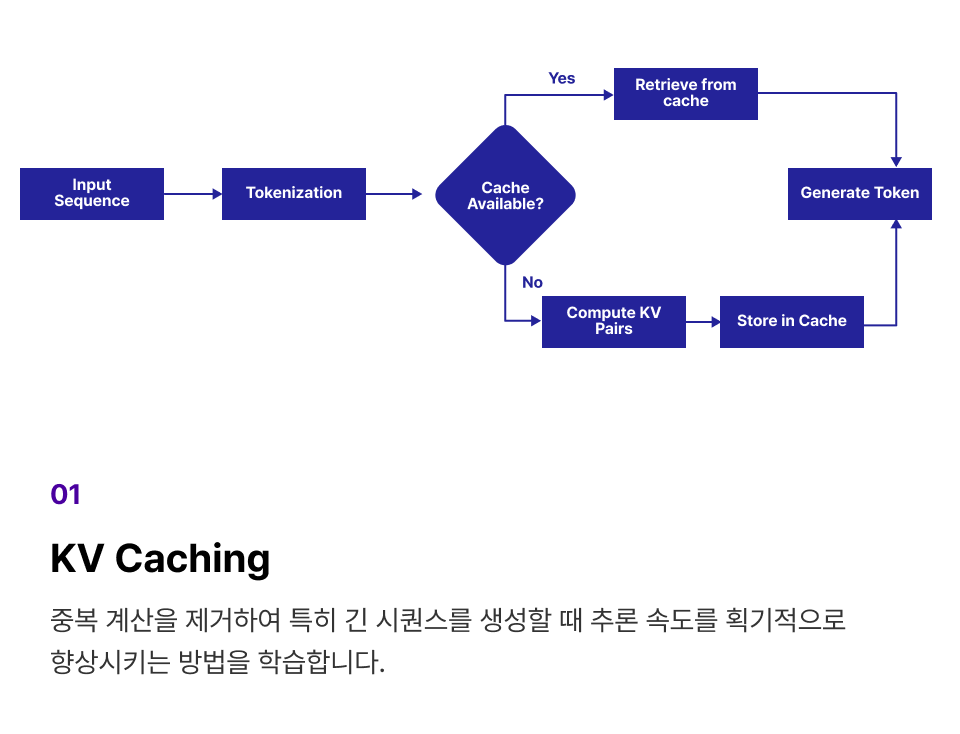
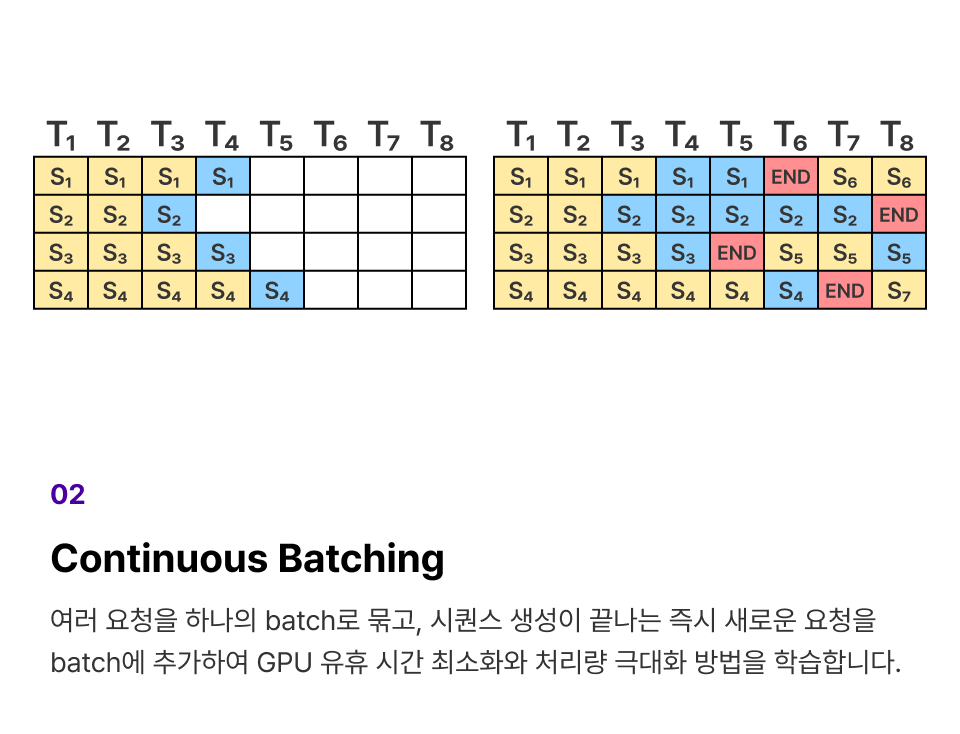
프로젝트 실습 LLM Decoding과 Inference를 최적화하기 위한 Decoding 구현
| 프로젝트 목표
여러 Decoding 전략을 구현하면서 파라미터 변화에 따른 텍스트 생성 결과의 차이를 학습합니다.
KV Caching 유무에 따른 추론 속도 차이를 측정하여 최적화를 진행합니다.
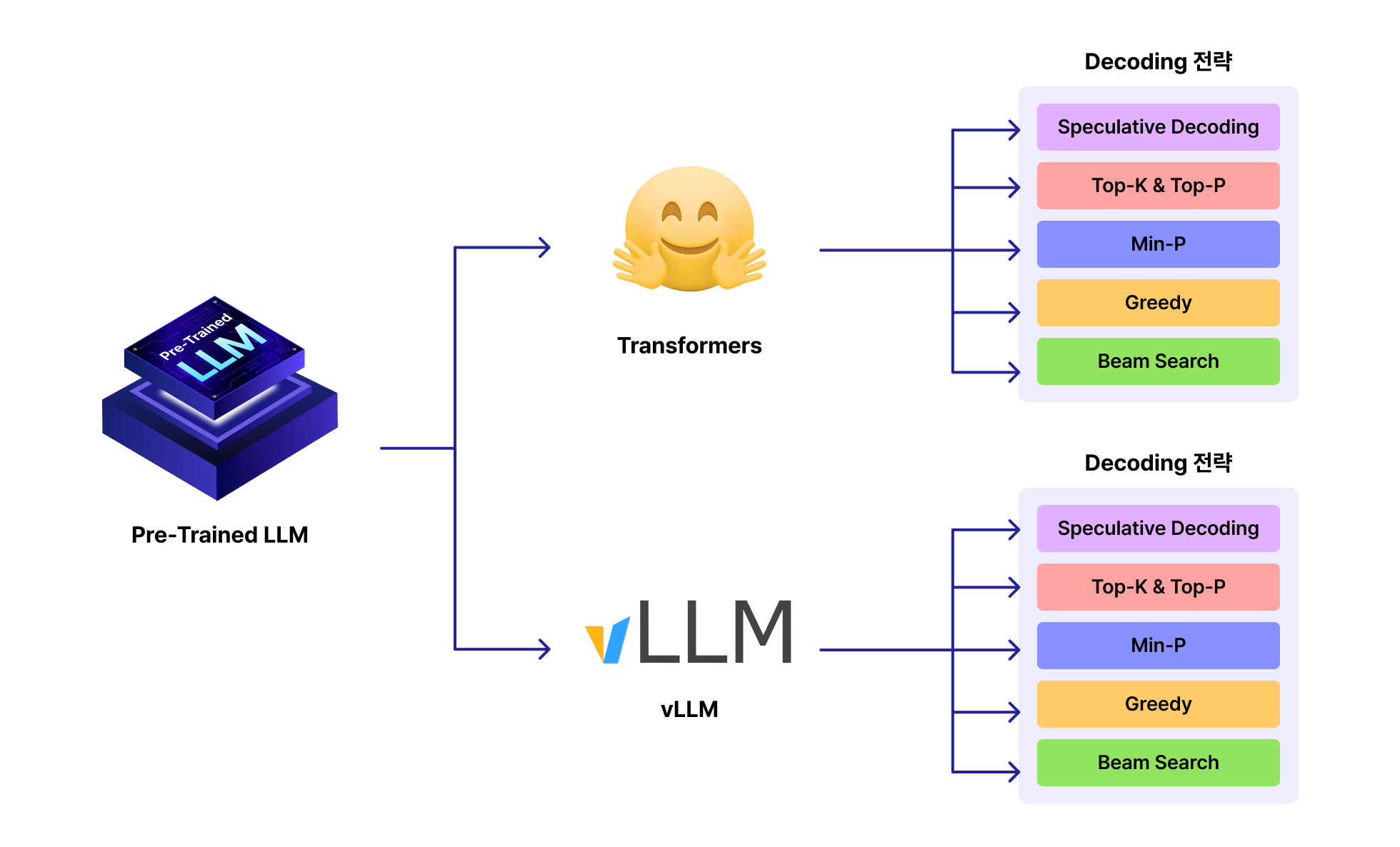
2단계 : Reinforcement Learning
사람의 피드백으로 LLM을 정렬하는 강화학습
RLHF의 개념부터 최신 선호도 최적화 기법을 학습합니다.
개념 학습 LLM을 사람이 선호하는 방식으로 정렬하는 강화학습

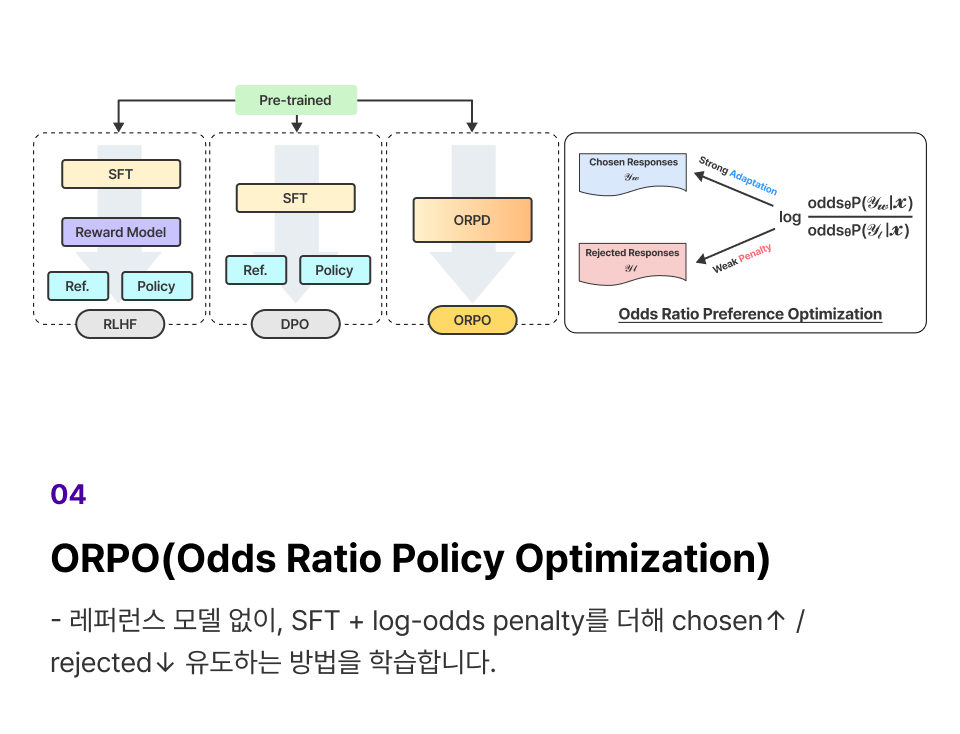
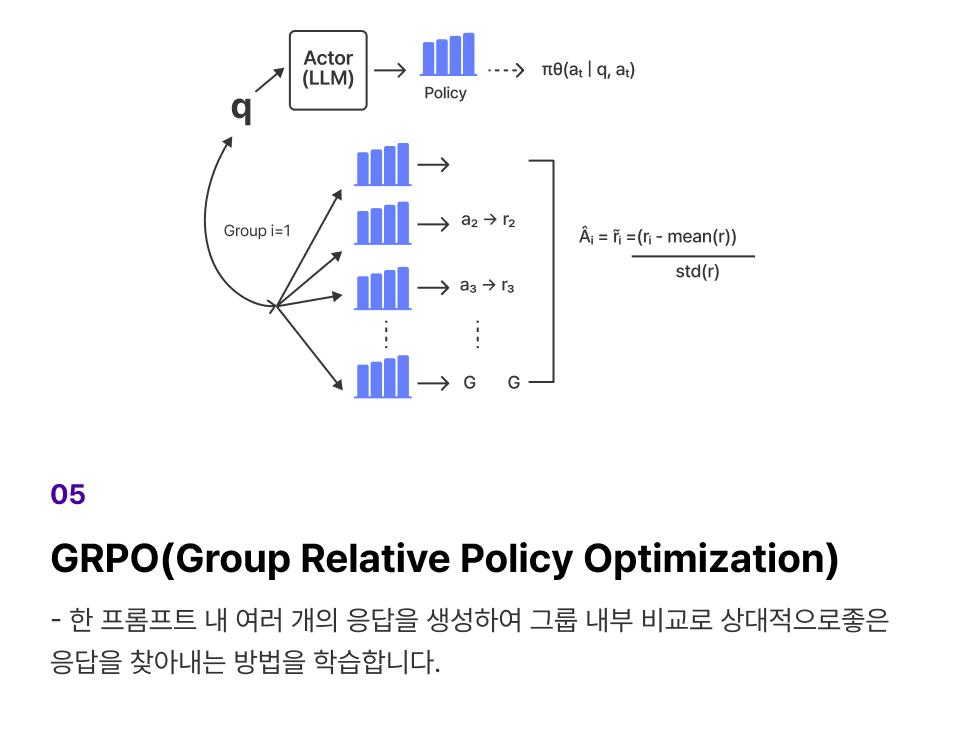
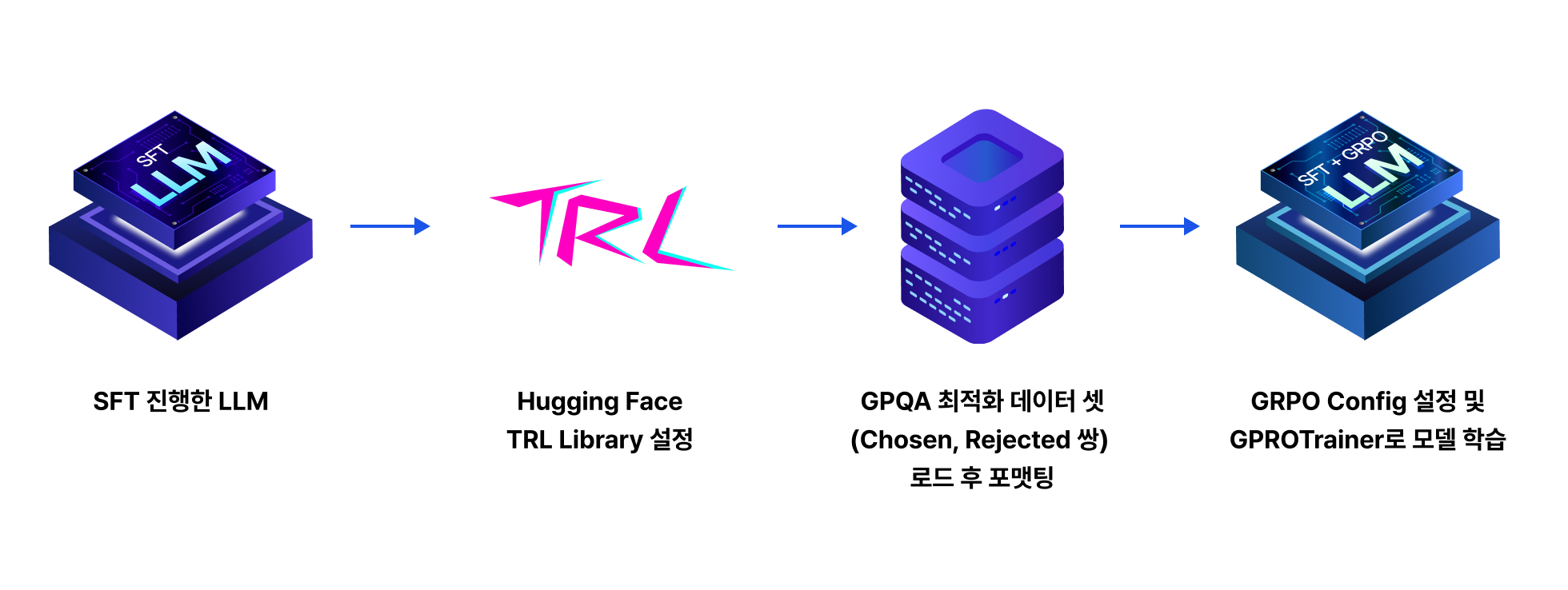
프로젝트 실습 GRPO 기법으로 LLM 출력 성능 향상
| 프로젝트 목표
SFT를 마친 모델에 GRPO를 적용하여 LLM 출력 응답의 규칙(형식/길이)과
정답형(정확도) 보상으로 출력 응답의 품질을 높이는 방법을 학습합니다.
3단계 : Test Time Scaling
모델이 더 깊이 사고하고
다각도로 검토를 수행하는 TTS
모델의 가중치를 변경하지 않고 추론 시점에 계산을 추가하여
성능을 높이는 방법을 학습합니다.
개념 학습 오직 추론 시점에서만 더 많은 계산을 수행하여 모델 성능을 올리는 TTS

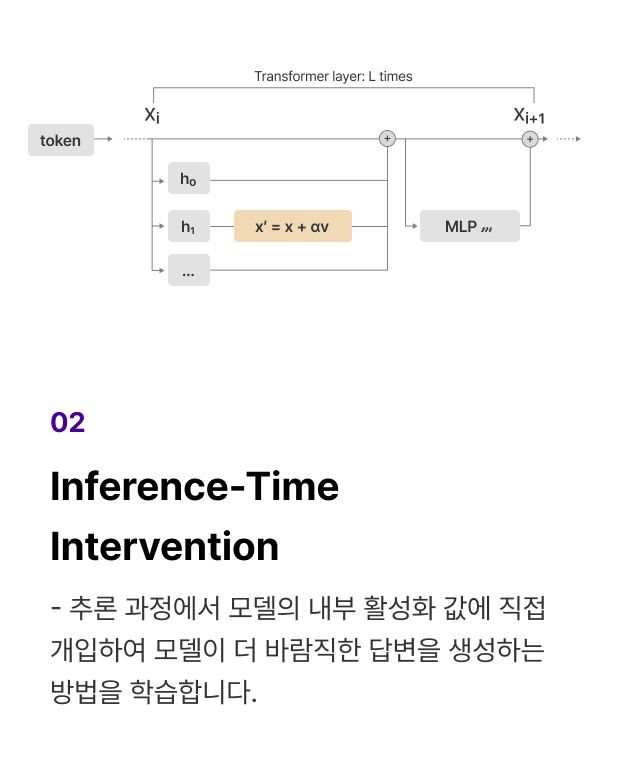

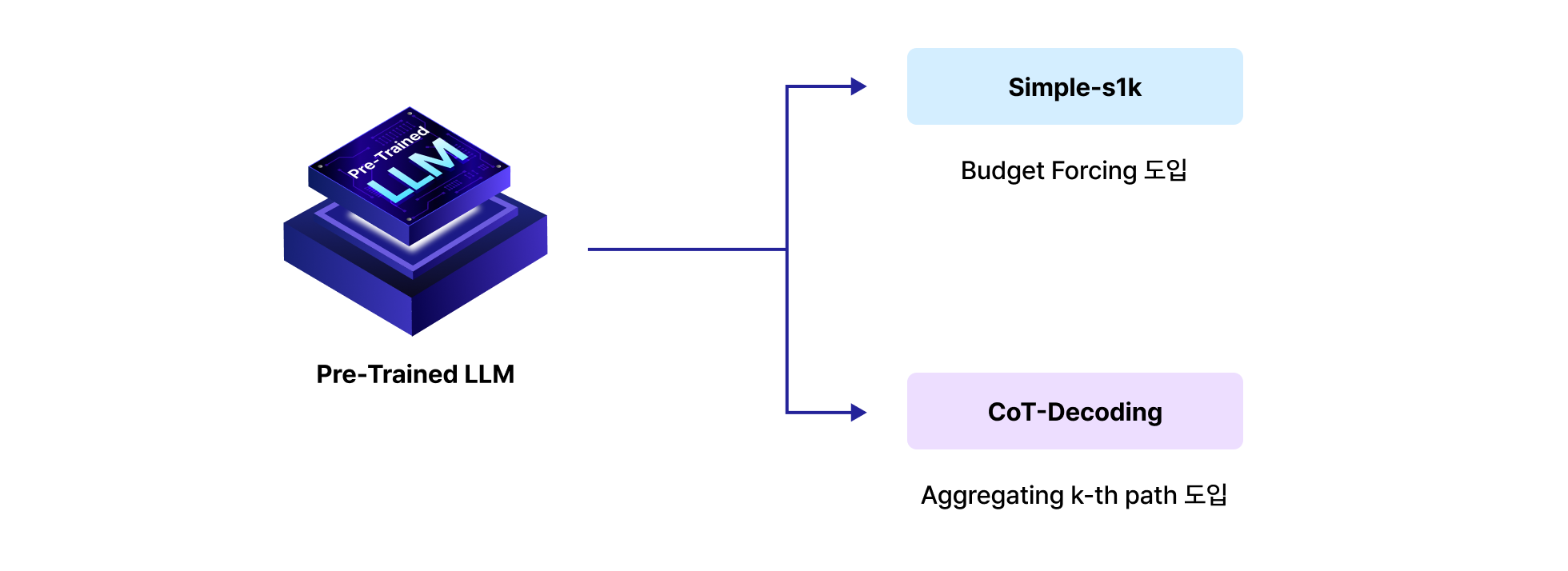
프로젝트 실습 CoT-Decoding과 Simple S1 구현
| 프로젝트 목표
GPQA Diamond 벤치마크에서 일반 디코딩과 CoT-Decoding의 성능을 비교하고,
S1을 구현하여 추론 시점에 모델의 생각 토큰 예산을 의도적으로 조절하여 성능을 올립니다.
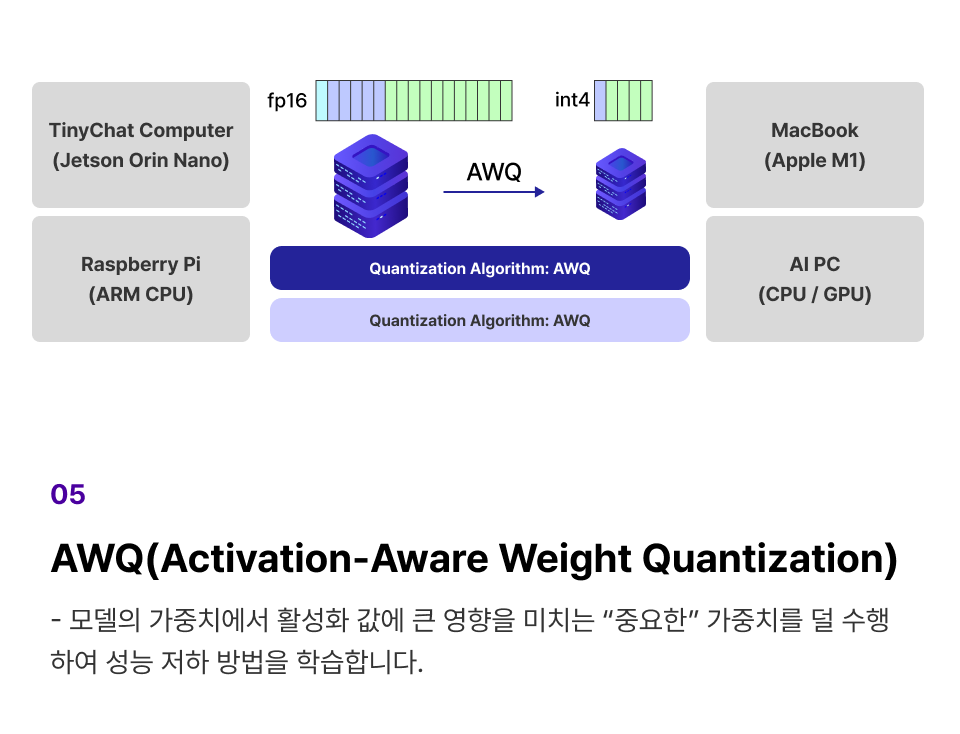
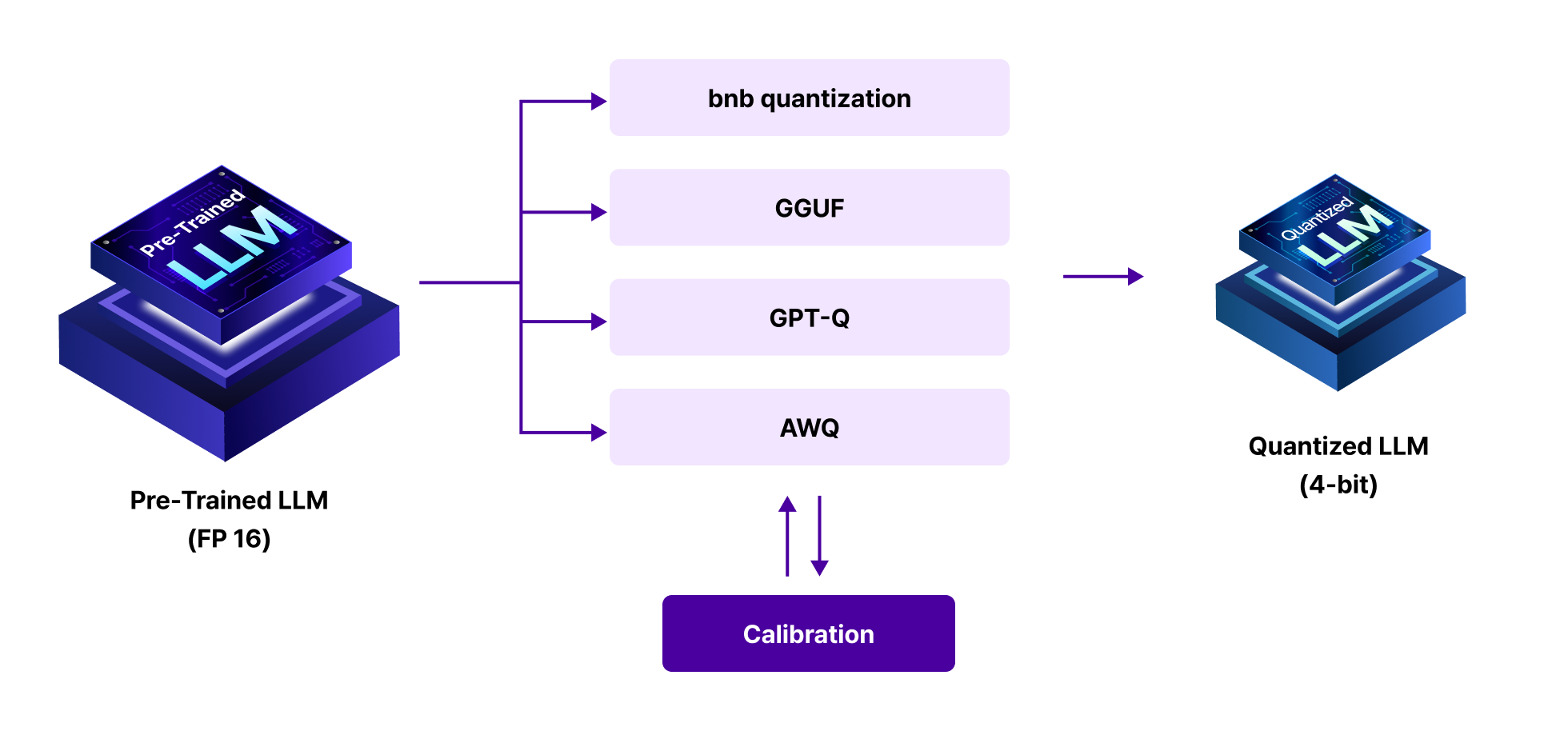
4단계 : Quantization
모바일 기기 & 엣지 디바이스에서
LLM 활용을 위한 Quantization
LLM의 크기를 줄여 메모리 사용량과 계산 비용을 줄이는 방법을 학습합니다.
개념 학습 (1) Quantization에 활용되는 대표 2가지 방법 PTQ, QAT 개념 학습
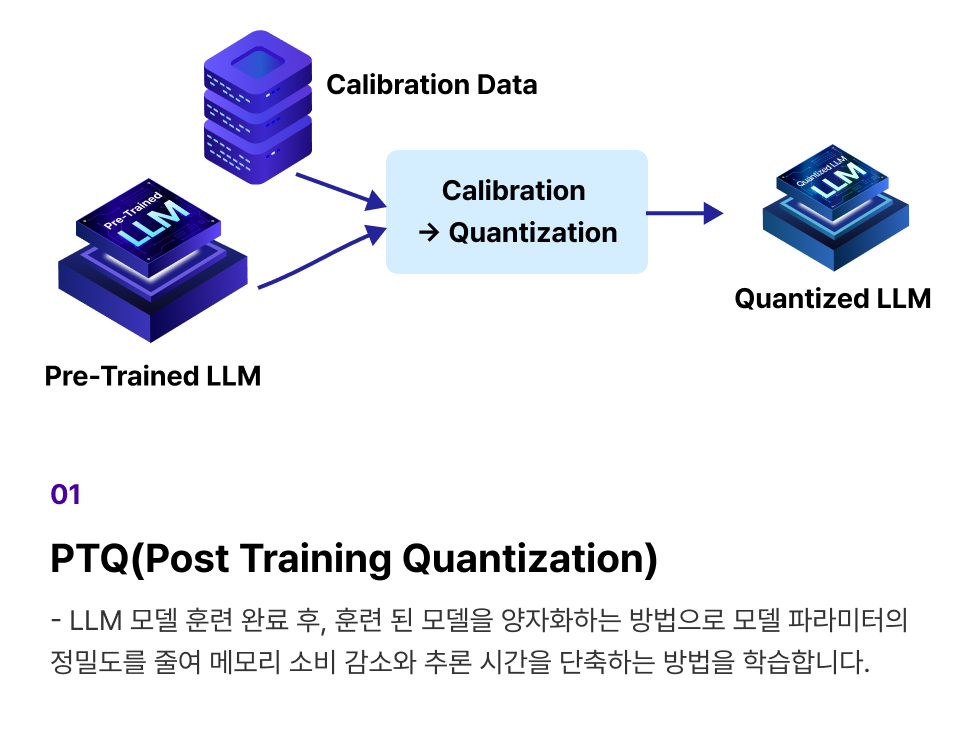
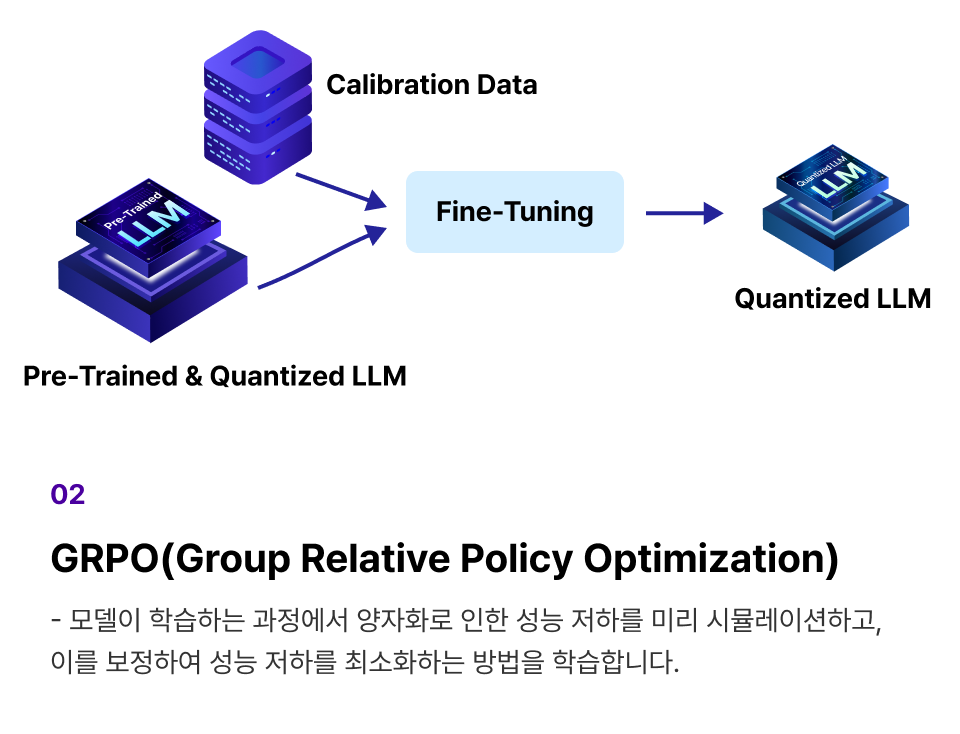
개념 학습 (2) 최신 Quantization 5가지 방법론 학습



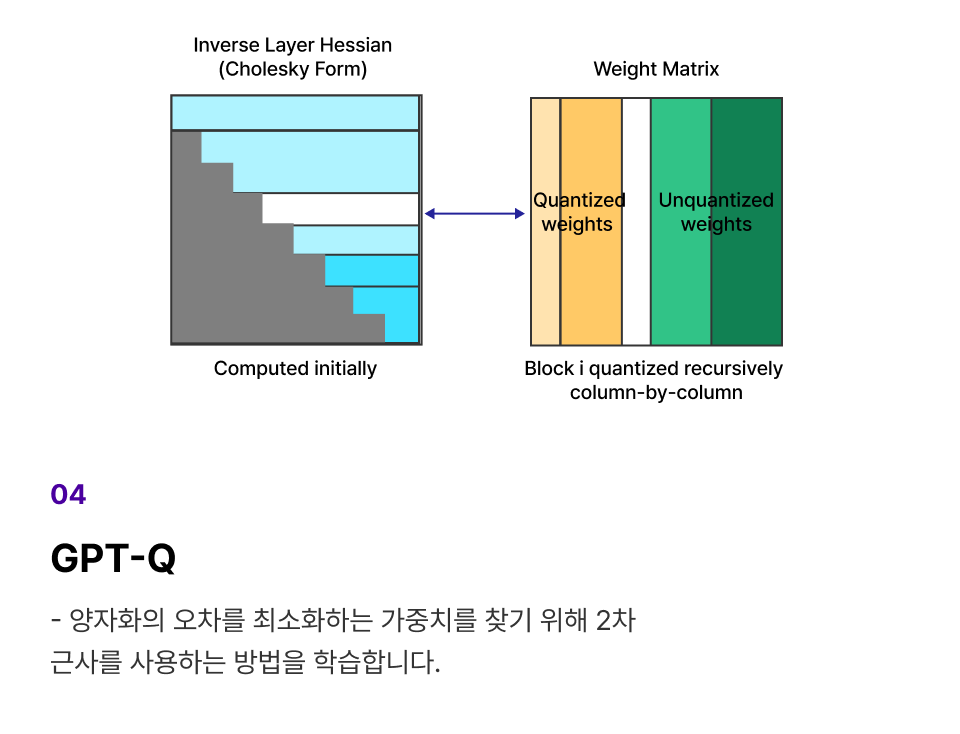
프로젝트 실습 학습 된 모델에 여러 PTQ 기법을 적용하여 원본 모델과 양자화 모델 비교
| 프로젝트 목표
GPQA Diamond 벤치마크에서 일반 디코딩과 CoT-Decoding의 성능을 비교하고,
S1을 구현하여 추론 시점에 모델의 생각 토큰 예산을 의도적으로 조절하여 성능을 올립니다.
POINT 4
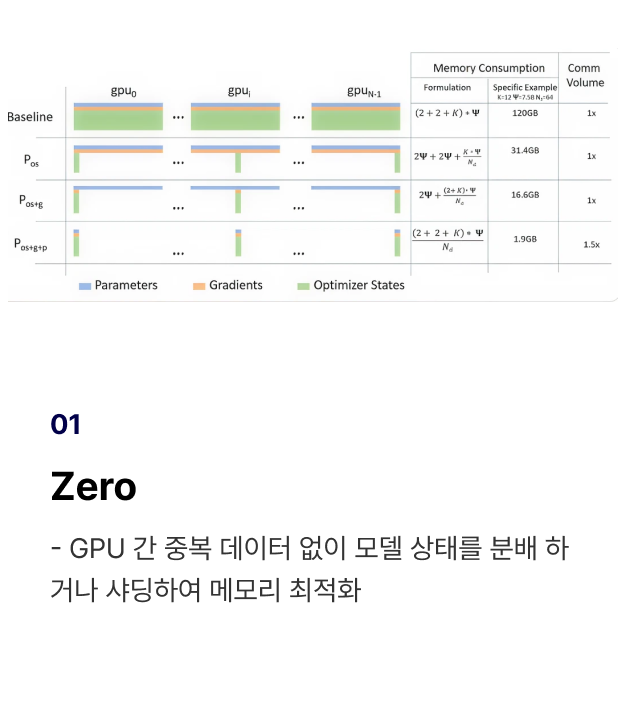
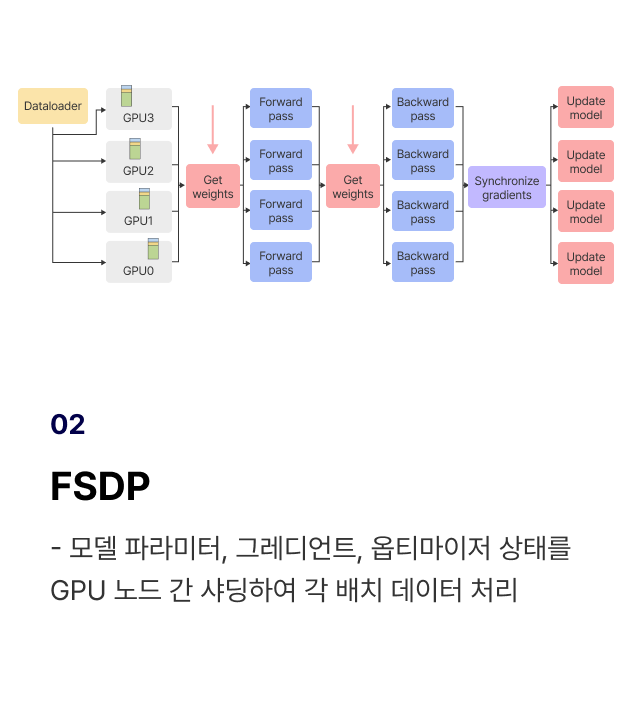
LLM 모델 학습을 위한
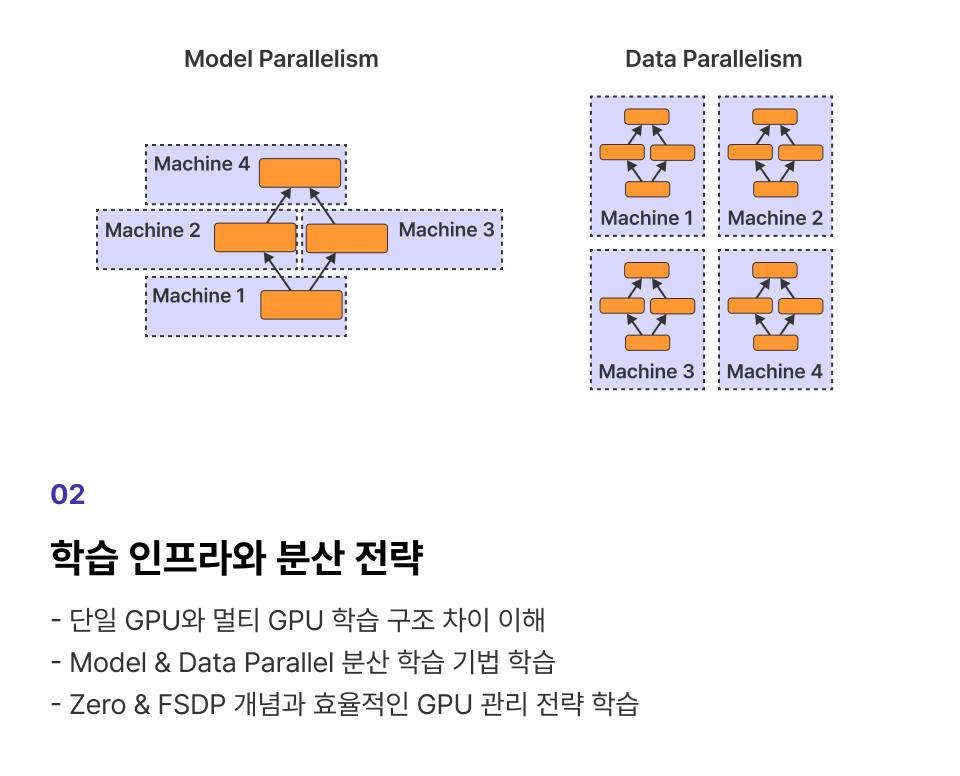
대표 2가지 형태 GPU 학습
GPU를 활용하여 LLM을 학습하는 이유와 모델 크키, 보유 자원에 따른
대표 2가지 GPU 사용 방법을 학습합니다.
개념 학습 (1) 대표 2가지 형태의 GPU의 특징과 내 상황에 맞는 GPU 선택 기준 학습



개념 학습 (2) Multi-GPU 환경에서 대표적으로 활용될 수 있는 3가지 분산학습 전략 학습
부가 혜택
기본기와 디테일을 다질 수 있는
부가 혜택까지 추가로 드려요!



파운데이션 LLM 개발을 위한 모든 커리큘럼과
프로젝트를 가르쳐줄 수 있는 ‘실력파’ 강사님들과 함께합니다.


QUESTION 1
어떤 분들이
수강하시면 좋을까요?
수강하시면 좋을까요?
- 파운데이션 LLM 개발을 목표로 하고 있는 AI Engineer
- LLM을 연구하고 있는 대학원생/연구원
- LLM을 연구하고 있는 대학원생/연구원
QUESTION 2
강의를 수강하고 나서
어떤 지식을 학습할 수 있나요?
어떤 지식을 학습할 수 있나요?
1. Pre-Training 파트
데이터 처리와 모델 학습 경험을 얻어 가실 수 있습니다. 단순히 모델을 불러다 쓰는 과정이 아닌 직접 모델을 개발하고 데이터 파이프라인을 설계할 수 있는 역량을 학습하실 수 있습니다.
Pre-Training 과정에서 학습한 모델을 평가 지표로 검증하고 결과를 해석하여 모델을 선택할 수 있는 눈과 설계 역량을 얻어가실 수 있습니다.
2. Post Training 파트
대규모 텍스트 코퍼스 전처리와 합성 데이터 생성 방법을 학습하실 수 있습니다. 그 과정에서 CPT, SFT, DPO 등 학습 과정을 거쳐 모델 성능을 향상시킬 수 있는 노하우를 학습합니다.
그리고 Loss 처리에서도 CPT, SFT, DPO의 Loss 함수를 이해하고 Post Training 모델 평가 방법과 성능 개선 역량을 얻어가실 수 있습니다.
3. Inference / Quantization 파트
개발된 LLM을 실제 사용하는 측면에서 출력의 품질을 높이기 위한 심화 기법들을 학습합니다.
데이터 처리와 모델 학습 경험을 얻어 가실 수 있습니다. 단순히 모델을 불러다 쓰는 과정이 아닌 직접 모델을 개발하고 데이터 파이프라인을 설계할 수 있는 역량을 학습하실 수 있습니다.
Pre-Training 과정에서 학습한 모델을 평가 지표로 검증하고 결과를 해석하여 모델을 선택할 수 있는 눈과 설계 역량을 얻어가실 수 있습니다.
2. Post Training 파트
대규모 텍스트 코퍼스 전처리와 합성 데이터 생성 방법을 학습하실 수 있습니다. 그 과정에서 CPT, SFT, DPO 등 학습 과정을 거쳐 모델 성능을 향상시킬 수 있는 노하우를 학습합니다.
그리고 Loss 처리에서도 CPT, SFT, DPO의 Loss 함수를 이해하고 Post Training 모델 평가 방법과 성능 개선 역량을 얻어가실 수 있습니다.
3. Inference / Quantization 파트
개발된 LLM을 실제 사용하는 측면에서 출력의 품질을 높이기 위한 심화 기법들을 학습합니다.
QUESTION 3
필요한
선수지식이 있을까요?
선수지식이 있을까요?
- 기초 머신러닝 · 딥러닝 지식 : 지도학습, 비지도학습, 딥러닝의 기본 구조
- 자연어처리의 기본 개념 : 토큰화, 임베딩, 언어 모델링
- 라이브러리 사용법 : Transformers, TRL, Im-eval-harness
- Pytorch와 Python 활용 방법
- 프롬프트 엔지니어링과 간단한 파인튜닝 경험도 있으면 더 좋습니다.
- 자연어처리의 기본 개념 : 토큰화, 임베딩, 언어 모델링
- 라이브러리 사용법 : Transformers, TRL, Im-eval-harness
- Pytorch와 Python 활용 방법
- 프롬프트 엔지니어링과 간단한 파인튜닝 경험도 있으면 더 좋습니다.
QUESTION 4
개발 환경
1. Pre-Training 파트
- Google Colab
- Python 3.1 이상
- Pytorh(torch), Hugging Face transformers, Hugging Face datasets
- Peft, Sentencepiece
- 선택 : faiss-cpu, langchain, accelerate, bitsandbytes
2. Post Training 파트
- Google Colab
- Hugging Face Transformers
- TRL & Im-eval-harness 라이브러리
- Gradio
- 선택 : 로컬 A 100 GPU, 클라우드 머신(Azure, AWS, GCP 등)
3. Inference / Quantization 파트
- Google Colab
- VS Code
- CUDA Device가 적용된 리눅스 환경 권장
- Google Colab
- Python 3.1 이상
- Pytorh(torch), Hugging Face transformers, Hugging Face datasets
- Peft, Sentencepiece
- 선택 : faiss-cpu, langchain, accelerate, bitsandbytes
2. Post Training 파트
- Google Colab
- Hugging Face Transformers
- TRL & Im-eval-harness 라이브러리
- Gradio
- 선택 : 로컬 A 100 GPU, 클라우드 머신(Azure, AWS, GCP 등)
3. Inference / Quantization 파트
- Google Colab
- VS Code
- CUDA Device가 적용된 리눅스 환경 권장