ㅣ프로젝트 실습 개요
•활용하는 LLM 모델 : LLaMA-3
• Fine-Tuning 방법론 : QLoRA
(8bit 이하의 양자화를 적용하여 적은 메모리 자원에서 Fine-Tuning 가능)
• Data : MarkrAI/kOpen-HQ-Hermes-2.5-60K
[번들용] LLM 모델 파인튜닝을 위한 Quantization

ONLINE #LLM #Quantization #LLM 파인튜닝 #LLM 모델 추론 #PEFT #모델 사이즈 감소
LLM 모델 파인튜닝을 위한
Quantization
LLM 모델을 활용하여 AI 서비스를 개발하면서 발생하는 대표 2가지 병목인 모델 학습 시 Fine-Tuning에서 발생하는 메모리 리소스 제약,
Inference를 할 때 발생하는 Latency 증가 문제를 해결해줄 수 있는 LLM Quantization 강의
 기본 정보
기본 정보
• LLM 모델의 가중치와 활성화 값을 줄여 메모리 절약과 연산 속도를 올리는 방법을 알려주는 강의
 강의 특징
강의 특징
고성능 LLM 모델 활용 시 발생하는
두 가지 고질적인 문제점
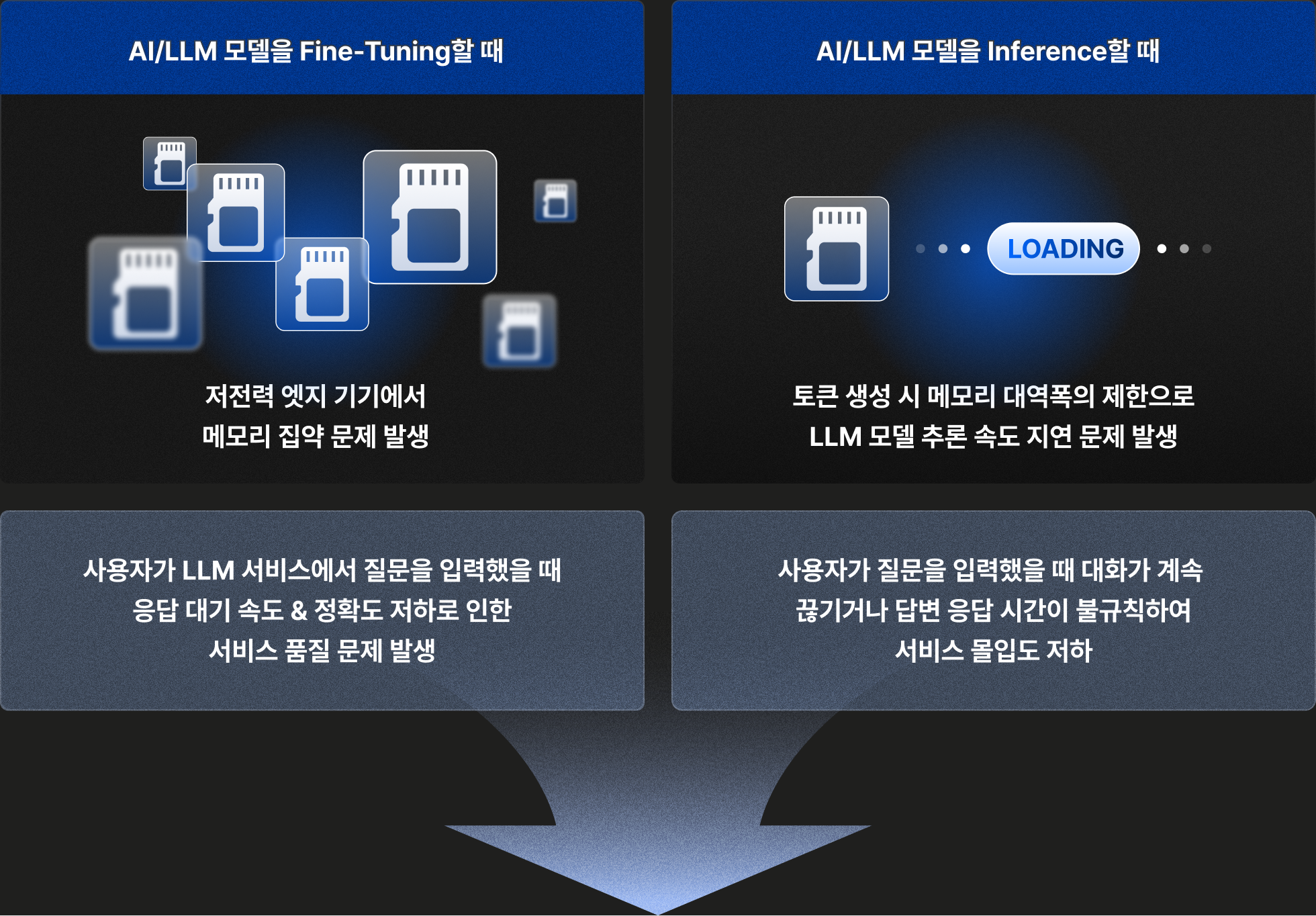
GPU 메모리 부족 문제로
AI/LLM 서비스 개발에 어려움을 겪고 있습니다.

글로벌 IT 빅테크 기업들의
AI/LLM 서비스 개발을 위한 LLM Quantization 구축 및 활성화
서비스 개발을 위한 기술을 적용하고 있습니다.



한정된 자원 내 모델 사이즈를 압축하면서 높은 모델 성능을 보여줄 수 있는
LLM Quantization이 AI/LLM 서비스 개발의 새로운 경쟁력으로 떠오르고 있습니다.

그래서 패스트캠퍼스와 LLM 파인튜닝 전문가 이승유 개발자가 뭉쳤습니다!
Open Ko-LLM LedaderBoard에서 최장기간 성능 1위 모델 개발!LLM 모델 파인튜닝 전문가 이승유님과 LLM 파인튜닝 Quantization 강의를 구성하였습니다!

RTX 3090만으로도 NVIDIA A100 수준의 컴퓨팅 파워를 낼 수 있는 방법,
이승유 강사님의 LLM Quantization 노하우를 바로 확인하세요!

트레일러
추천사
AI/LLM 업계 전문가들이 인정하는
이승유 개발자에게 배우는 LLM 모델 파인튜닝을 위한 Quantization




극한의 GPU 환경에서 LLM 모델의 메모리 사이즈를 줄이고
연산 능력을 올리기 위한 7가지 스폐셜 포인트!


Point 1
Quantization의 기초 개념 이해를 위한 LLM
LLM의 파라미터와 계산 복잡도가 모델 크기와 성능에 따라 어떻게 영향을 미치는지 알아보고,LLM의 메모리 절약과 연산 속도를 올리기 위한 Quantization의 기초 개념을 학습합니다.
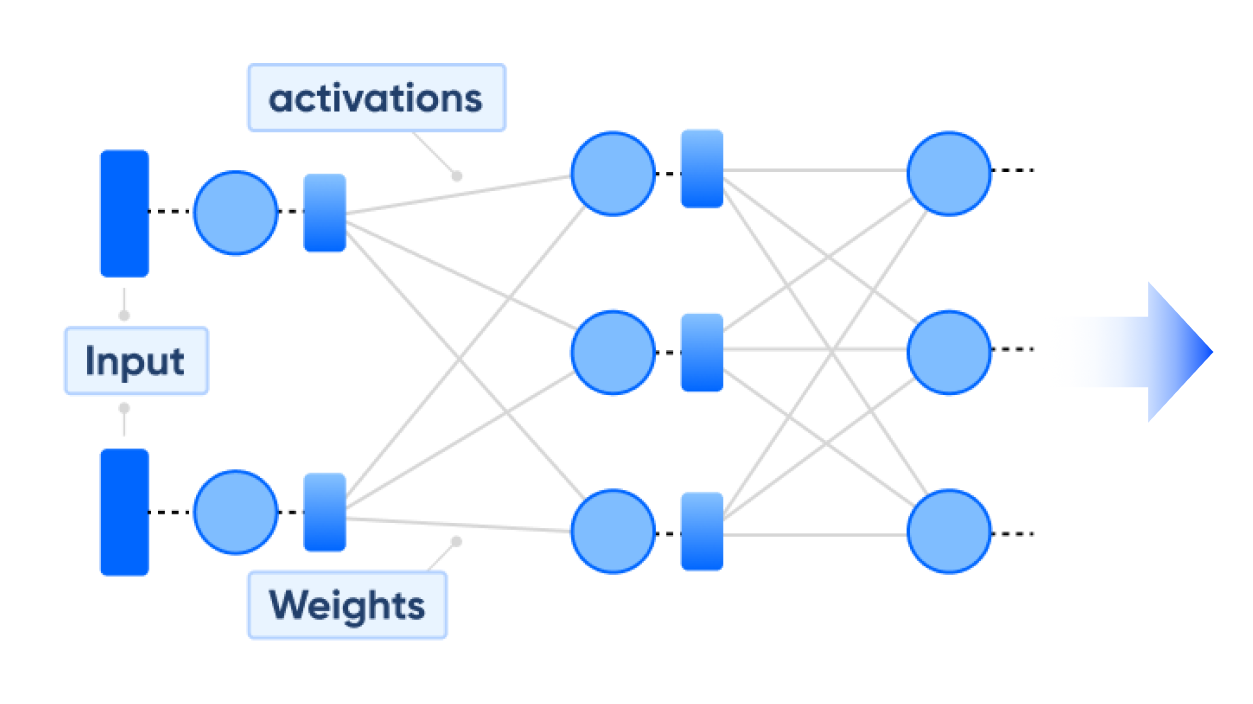
LLM은 수식업 개의 파라미터를 가지고 있다 보니, LLM을 연산할 때많은 비용과 자원이 소모되어 비효율의 문제를 가지고 있습니다.
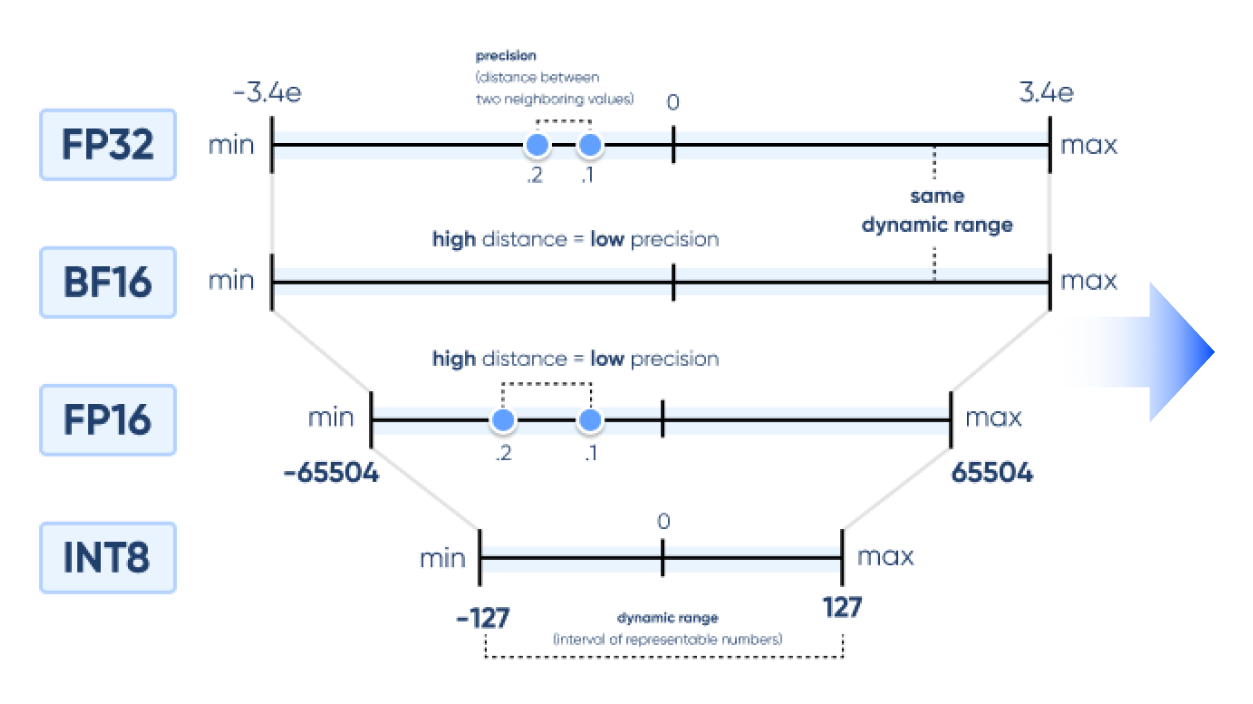
그렇다보니 연산 비용과 자원을 줄이기 위해 소요되는 메모리 용량을 줄일 수도 있지만 낮은 정밀도로 인해 모델 품질에 부정적 영향을 미칩니다.
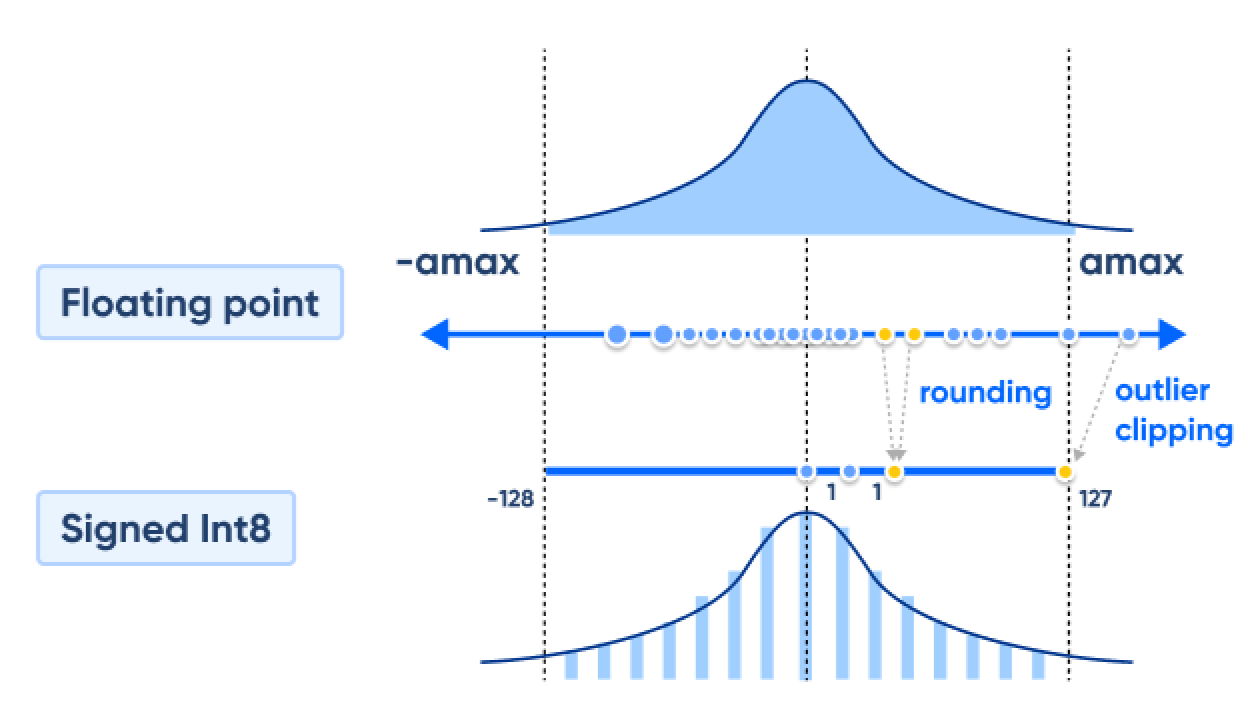
그래서 높은 정밀도의 값을 저장하는 가중치를 낮은 정밀도의 데이터 유형으로 매핑하기 위한 Quantization이 최근 LLM 개발에 화두가 되고 있습니다.
LLM 모델을 Quantization 할 때 활용되는 대표적인 2가지 방법
PTQ, QAT의 개념을 학습합니다.
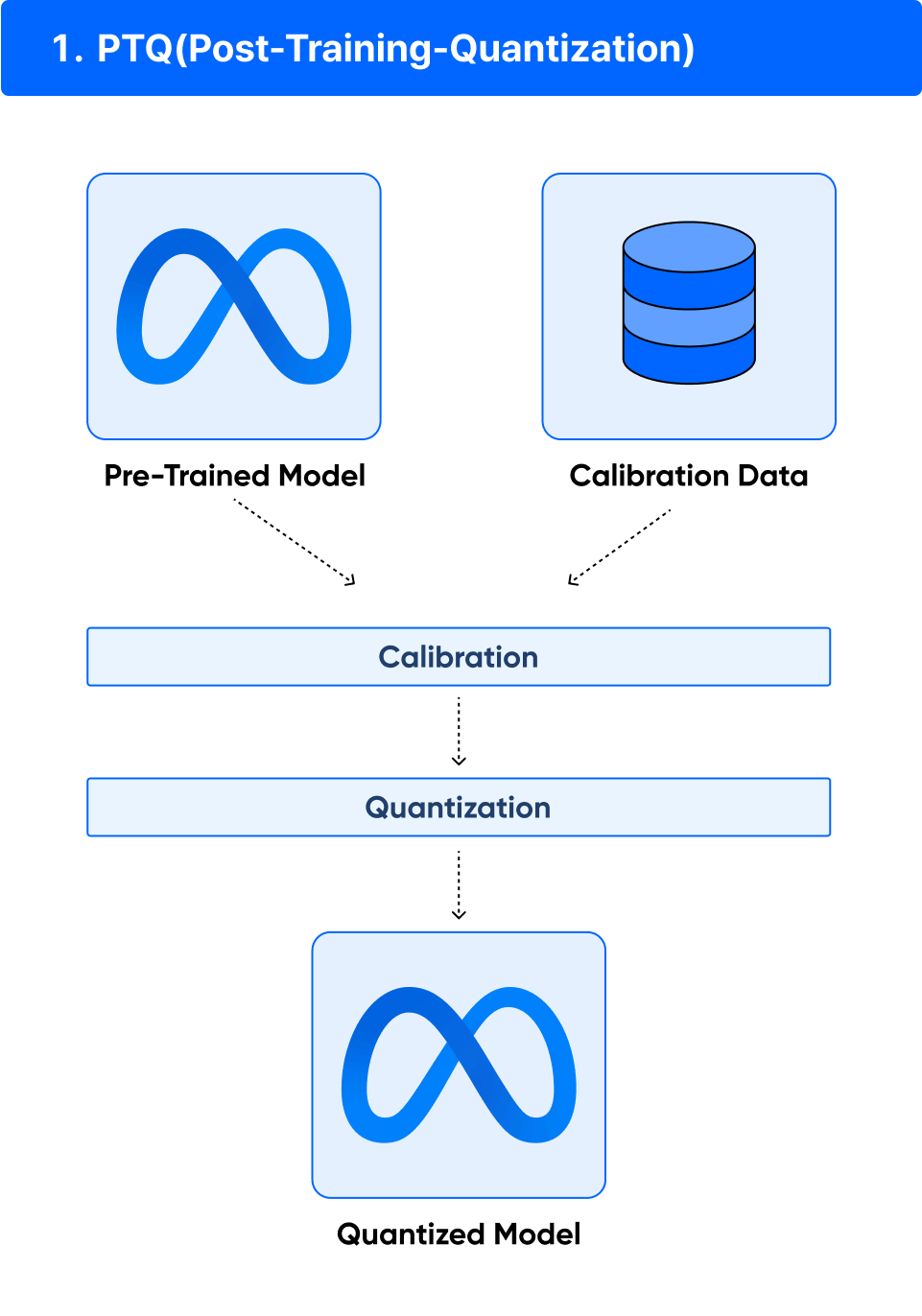
ㅣ학습 포인트
• LLM 모델의 훈련이 완료된 후 훈련된 모델을 양자화하는 방법으로 32비트 부동 소수점 표현에서 8비트 정수로 모델 파라미터의 정밀도를 줄여 메모리 소비 감소, 추론 시간 단축 효과를 낼 수 있는 방법을 학습합니다.
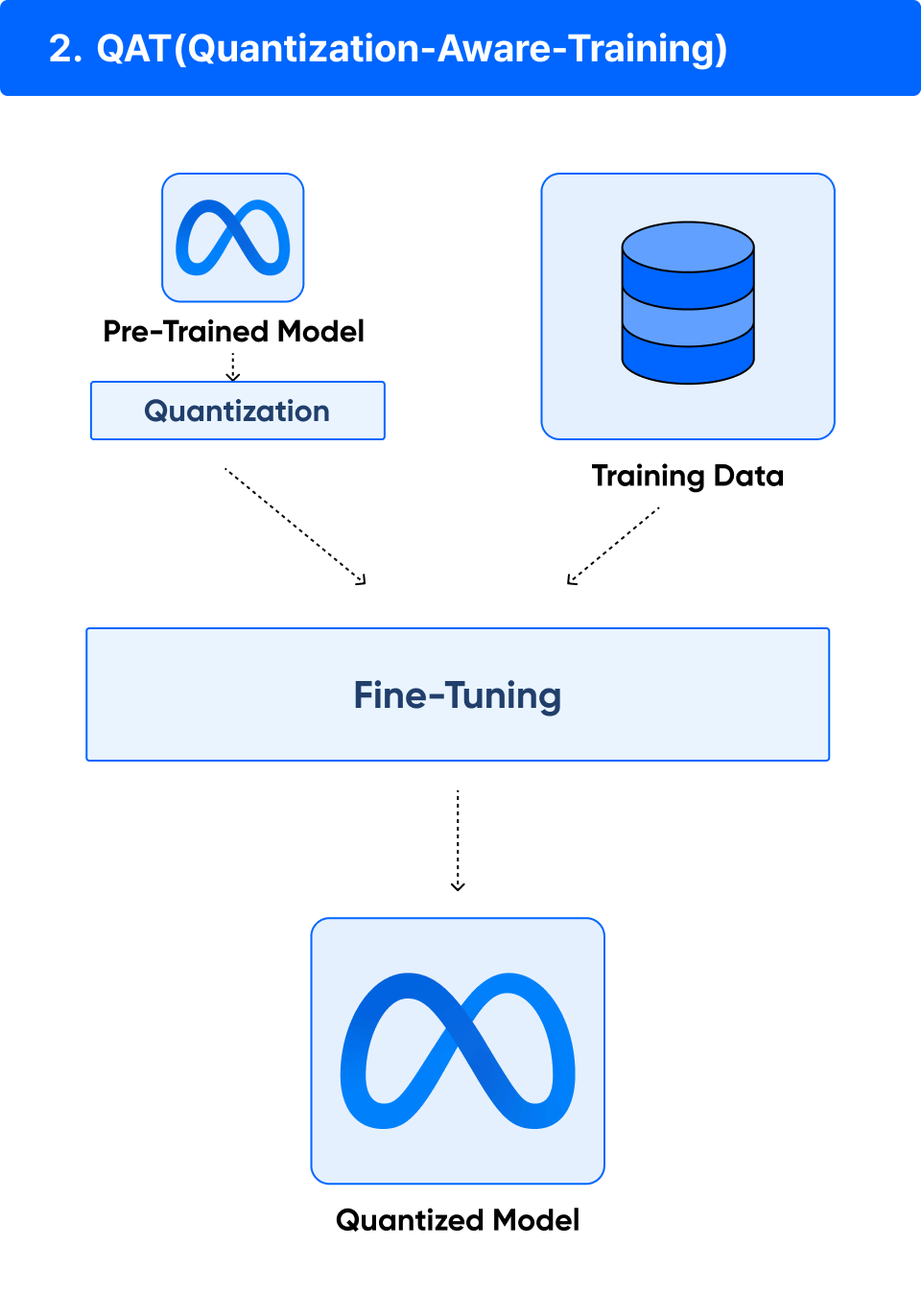
ㅣ학습 포인트
• Quanziation 이후에도 정확도를 유지하기 위해 PTQ 모델을 정제하는 방법으로 LLM 모델을 학습하는 과정
자체에서 Quantization을 통합합니다.
• 스케일링, 클리핑, 라운딩 등 QAT 방법에서 활용되는 양자화 기술들을 적용하며 모델 파라미터를 최적화하여
정확도 손실을 완화하는 방법을 학습합니다.
Point 2
학습된 LLM 모델을 Quantization하는 방법 학습
LLM 모델을 훈련 후 양자화하는 방법인 PTQ 방법론의 개념을 이해하고,PTQ 방법에서 활용하는 대표 3가지 방법을 실습합니다.
유형 1. Llama.cpp 라이브러리를 활용한 GGUF Quantization
다양한 하드웨어 환경에서 실행될 수 있는 Llama.cpp 라이브러리를 사전 양자화 방식을 통해
자원 제약이 있는 환경에서도 LLM을 활용할 수 있는 방법을 직접 실습을 통해 구현합니다.
ㅣ학습 개요
Llama.cpp 라이브러리의 특징을 이해하고 로컬 서버 실행과 성능 최적화의 강점을 활용하여 다양한 장치에서 적은 메모리와 연산 자원으로 LLM 모델을 빠르게 추론합니다.
ㅣ실습 포인트
• Llama.cpp 라이브러리의 특징을 이해하고 로컬 서버 실행과 성능 최적화의 강점을 활용하여 다양한 장치에서은 메모리와 연산 자원으로 LLM 모델을 빠르게 추론할 수 있는 방법을 학습합니다.
• LLaMA 모델에서 GGUF 형식으로 변환하면서 GGUF 형식을 낮은 정밀도로 양자화할 수 있어 다양한 수준의 양자화를 진행해볼 수 있습니다.
ㅣ실습 포인트
• Llama.cpp 라이브러리의 특징을 이해하고 로컬 서버 실행과 성능 최적화의 강점을 활용하여 다양한 장치에서은 메모리와 연산 자원으로 LLM 모델을 빠르게 추론할 수 있는 방법을 학습합니다.
• LLaMA 모델에서 GGUF 형식으로 변환하면서 GGUF 형식을 낮은 정밀도로 양자화할 수 있어 다양한 수준의 양자화를 진행해볼 수 있습니다.
유형 2. Auto GPT-Q 라이브러리를 활용한 GPT-Q Quantization
전체 모델 훈련이나 파인튜닝 비용이 많이 드는 대규모 모델에서 특히 유용하며,
계층별 양자화를 통해
각 계층의 “원래 출력”과 “양자화된 출력” 간 제곱 오차를 최소화하는 방법을 직접 실습을 통해 구현합니다.
ㅣ학습 개요
사후 훈련 양자화 방법으로 이미 훈련이 끝난 LLM의 모델 파라미터를 낮은 정밀도로 변환하여 양자화를 진행합니다.
• GPT-Q의 3가지 유형을 학습합니다
- Static Range GPT-Q : 신경망의 각 레이어를 작은 그룹 단위로 나누어 파라미터를 양자화하는 방법을 학습합니다.
- Dynamic Range GPT-Q : 파라미터 및 활성화 값을 낮은 정밀도로 변환하는 방법을 학습합니다.
- Weight Quantization : 파라미터를 낮은 정밀도로 변환하여 메모리 절약과 계산 속도를 높이는 방법을 학습합니다.
ㅣ실습 포인트
• 가중치 행렬의 각 행을 독립적으로 양자화화여 오차를 최소화하는 가중치 버전을 찾는 방법을 학습합니다.
• int4 가중치가 GPU의 전역 메모리 대신 결합된 커널에서 역양자화되기 때문에 메모리 사용량을 4배 절약하며, 더 낮은 비트 너비를 사용하여 통신 시간을 줄이고 추론 속도를 높이는 방법을 학습합니다.
• GPT-Q의 3가지 유형을 학습합니다
- Static Range GPT-Q : 신경망의 각 레이어를 작은 그룹 단위로 나누어 파라미터를 양자화하는 방법을 학습합니다.
- Dynamic Range GPT-Q : 파라미터 및 활성화 값을 낮은 정밀도로 변환하는 방법을 학습합니다.
- Weight Quantization : 파라미터를 낮은 정밀도로 변환하여 메모리 절약과 계산 속도를 높이는 방법을 학습합니다.
ㅣ실습 포인트
• 가중치 행렬의 각 행을 독립적으로 양자화화여 오차를 최소화하는 가중치 버전을 찾는 방법을 학습합니다.
• int4 가중치가 GPU의 전역 메모리 대신 결합된 커널에서 역양자화되기 때문에 메모리 사용량을 4배 절약하며, 더 낮은 비트 너비를 사용하여 통신 시간을 줄이고 추론 속도를 높이는 방법을 학습합니다.
유형 3. Auto AWQ 라이브러리를 활용한 AWQ Quantization
CPU, GPU 등 여러 하드웨어 환경에서 활용하는 양자화 방식으로 LLM 모델의 중요하지 않은
파라미터만 선별하여 모델의 성능을 유지하는 방법을 직접 실습을 통해 구현합니다.
ㅣ학습 개요
• 기존의 양자화 방법들처럼 단지 오차를 최소화하기 위한 방법을 적용하는 것이 아닌, 오차가 발생하는 이유부터 고려하여 양자화를 진행합니다.
• 다른 양자화 기법들을 함께 적용할 수 있다는 특징이 있고 특히 Calibrate(보정) 데이터를 활용하여 오차를 최소화한다는 점에서 양자화 방법들 중 많이 고려되고 있는 방법입니다.
ㅣ실습 포인트
• 사전 훈련된 LLM에 샘플 데이터를 전달하여 가중치와 활성화의 분포를 파악하는 방법을 학습합니다.
• 핵심 엔티티를 확장하면서 중요한 가중치는 확대하고 중요하지 않는 가중치의 정밀도를 줄이면서 양자화로 인한 정확도 손실을 최소화하는 방법을 학습합니다.
• 다른 양자화 기법들을 함께 적용할 수 있다는 특징이 있고 특히 Calibrate(보정) 데이터를 활용하여 오차를 최소화한다는 점에서 양자화 방법들 중 많이 고려되고 있는 방법입니다.
ㅣ실습 포인트
• 사전 훈련된 LLM에 샘플 데이터를 전달하여 가중치와 활성화의 분포를 파악하는 방법을 학습합니다.
• 핵심 엔티티를 확장하면서 중요한 가중치는 확대하고 중요하지 않는 가중치의 정밀도를 줄이면서 양자화로 인한 정확도 손실을 최소화하는 방법을 학습합니다.
Point 3
LLM 파인튜닝에 필요한 Quantization하는 방법 학습
LLM 모델을 훈련 후 양자화하는 방법인 PTQ 방법론의 개념을 이해하고, PTQ 방법에서 활용하는 대표 3가지 방법을 실습합니다.



Step 1. | QLoRA의 개념과 QLoRA가 개발된 계기
1️⃣ Full-Fine Tuning
ㅣ학습 포인트
• LLM 모델의 모든 파라미터를 포함하여 사전 학습된 모델 전체를 파인튜닝 하는 방법을 학습합니다.
• 이 방법에서는 사전 학습된 모델의 모든 레이어와 파라미터 변수가 업데이트되고 최적화되기에 높은 성능을 보이지만 상당한 리소스와 시간이 필요합니다.
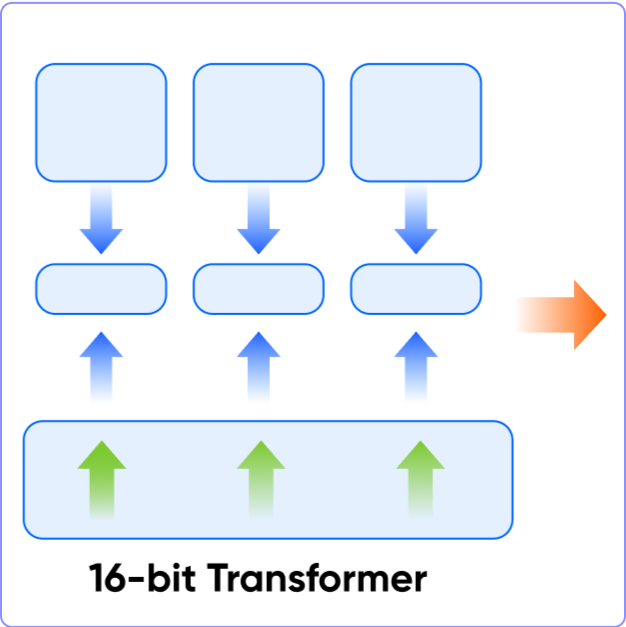
2️⃣ LoRA
ㅣ학습 포인트
• LLM 모델의 특정 층에서 저 차원(Low-rank) 행렬을
사용하여 파라미터를 조정하는 방법을 학습합니다.
• 전체 모델을 업데이트하는 것이 아닌, 일부 파라미터만을
조정하여 기존 파인튜닝 대비 높은 성능을 내는 방법을 학습합니다.
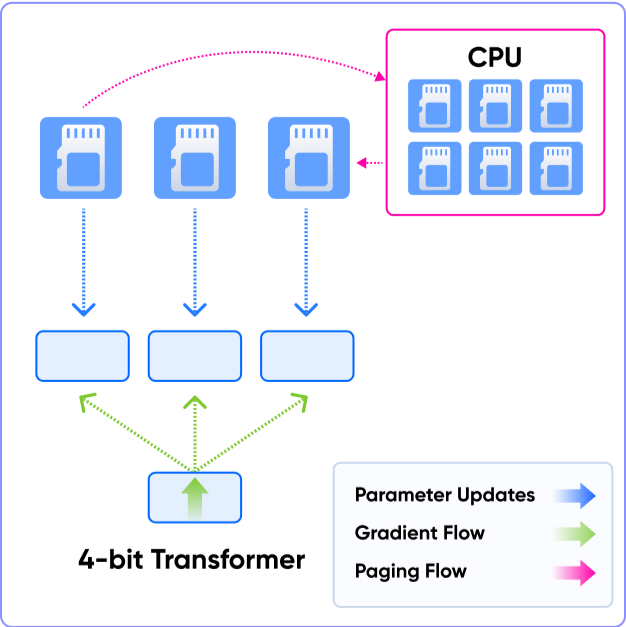
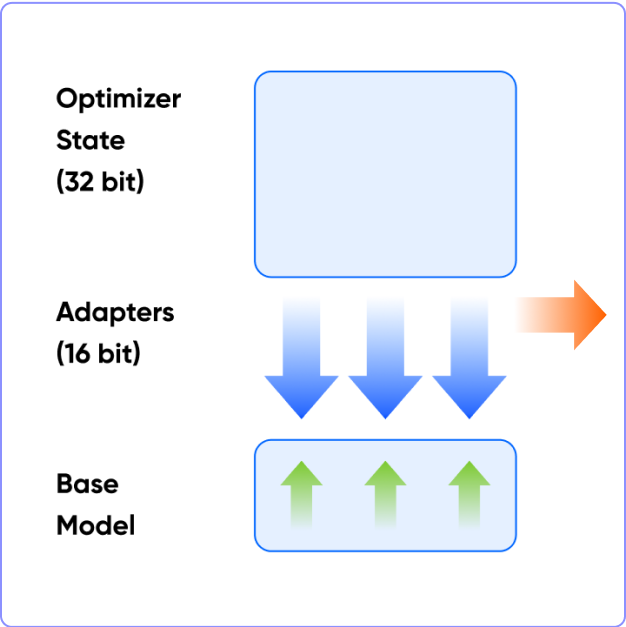
3️⃣ QLoRA
ㅣ학습 포인트
• LoRA Adapter의 파라미터를 더 낮은 정밀도로 양자화하여 메모리가 극도로 제한된 환경에서 파인튜닝하는 방법을 학습합니다.
• 모델이 차지하는 weight의 메모리 크기가 제일 작기에, 더 많은 Adapter를 활용하기 쉬워 가장 효율적인 경량화가 가능합니다.
Step 2 | LLM 모델 크기를 대폭 줄이면서도 성능을 그대로 유지하면서 파인튜닝 할 수 있는 QLoRA의 대표 3가지 유형 학습
유형 1
QLoRA의 가장 핵심적인 방법론,
4-bit NormalFloat(NF4)
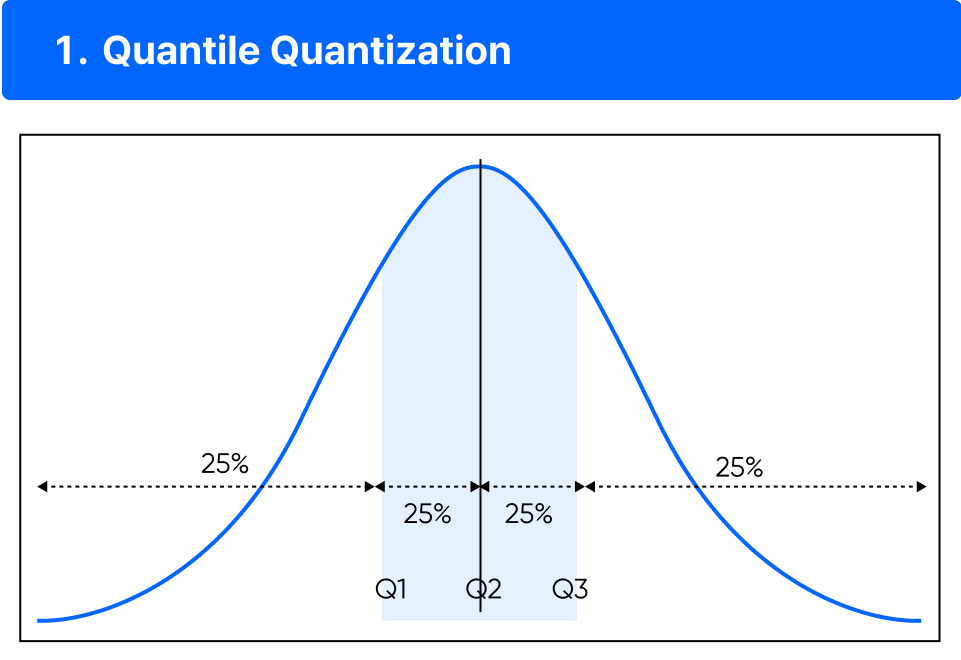
ㅣ학습 포인트
• Quantile Quantization은 말 그대로 분위수를 통한 양자화 방법으로 분포 함수를 통해 input tensopr에 대한 분위를 추정하는 방식으로 동작합니다.
• 즉 해당 데이터의 분포에 따라 비선형적인 구간을 가질 확률이 높고, 데이터의 분포가 달라질 때마다 이를 새로 계산해야 하는 비용이 높기에 이상치에 상당히 취약한 양자화 방식이기도 합니다.
• 그래서 이러한 trade-off를 줄이기 위해 확률 분포 추정, 분위 분할 등 과정을 모두 생략하고 이미 정해진 양자화 구간에서 데이터 포인트들을 맵핑하는 방법을 학습합니다. 데이터를 이산화하면서 정보의 분포를 최대한 이성적으로 유지하면서 계산 비용까지 함께 줄이는 방법을 학습합니다.
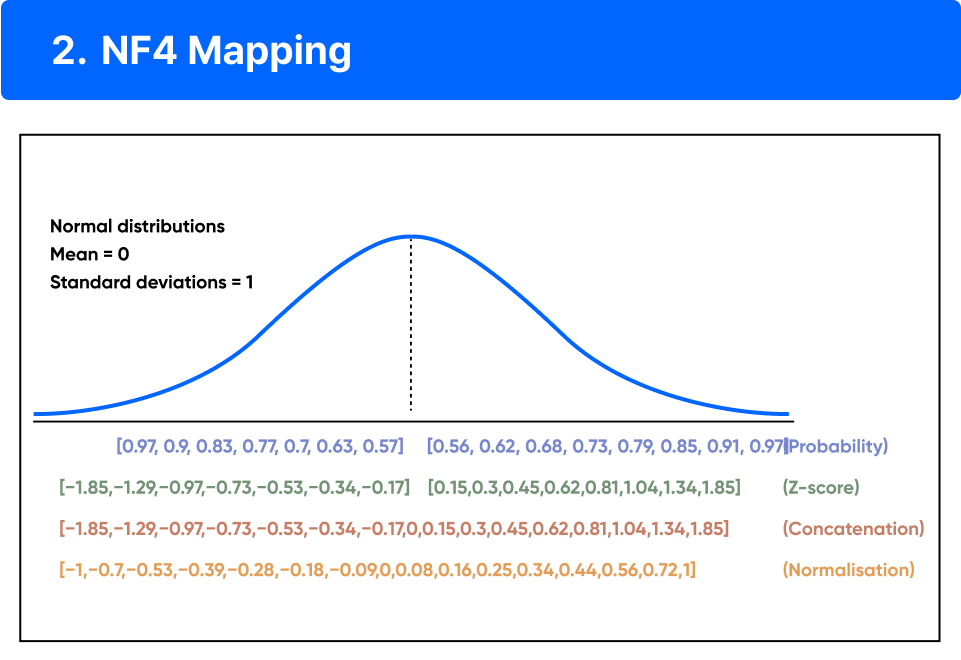
ㅣ학습 포인트
• 8bit 이상의 실수를 NF4 타입의 양자로 맵핑하는 과정에서 0에 대한 명확한 표현을 가질 수 없기에 0값의 텐서를 입력받았을 때, Quantization loss를 유의미하게 증가시킬 수 있습니다.
• Task과 무관하게 입력 텐서에는 zero-padding 등 처리해야 하는 0이 많기 때문에 정확하게 0을 표현하는 것은 중요합니다.
• 그래서 구간을 대칭으로 16등분하는 것이 아닌, 음수부를 7등분, 양수부를 8등분으로 나누고 0을 중심으로 구간을 Concatenate하게 만듭니다. 구성된 16개의 분위수를 [-1.1]로 정규화하여 입력된 텐서의 값에 해당하는 양자로 맵핑하는 방법을 학습합니다.
유형 2
한 번 양자화된 값을 한번 더 양자화하여
추가적인 메모리 효율을 볼 수 있는 Double Quantization

ㅣ학습 포인트
• NF4 양자화는 [-1, 1] 내로 구간을 정규화하기에 입력 텐서의 absmax 값으로 나머지 값들을 나누는
과정이 필요합니다. 이때 사용되는 absmax가 양자화 상수입니다.
• QLoRA에서 PLM은 얼어있지만 LoRA는 업데이트가 필요해 Adapter는 4bit가 아닌 16bit 실수형으로 존재해
4bit 모델과 16bit Adapter 간 연산을 위한 quantization-dequantization을 반복해 양자화 상수는 모델 밖에 저장됩니다.
• LLM의 크기가 billion에서 trillion으로 넘어가는 상황 속 전체 가중치의 absmax를 상수로 고를 때 아무리
zero-centered 정규 분포라 한들 매우 큰 상수가 선정되기에 일정 개수의 가중치를 묶어 하나의 블록으로 보고,
해당 블록의 absmax를 양자화 상수로 채택하는 k-bit block-wise quantization 방법을 학습합니다.
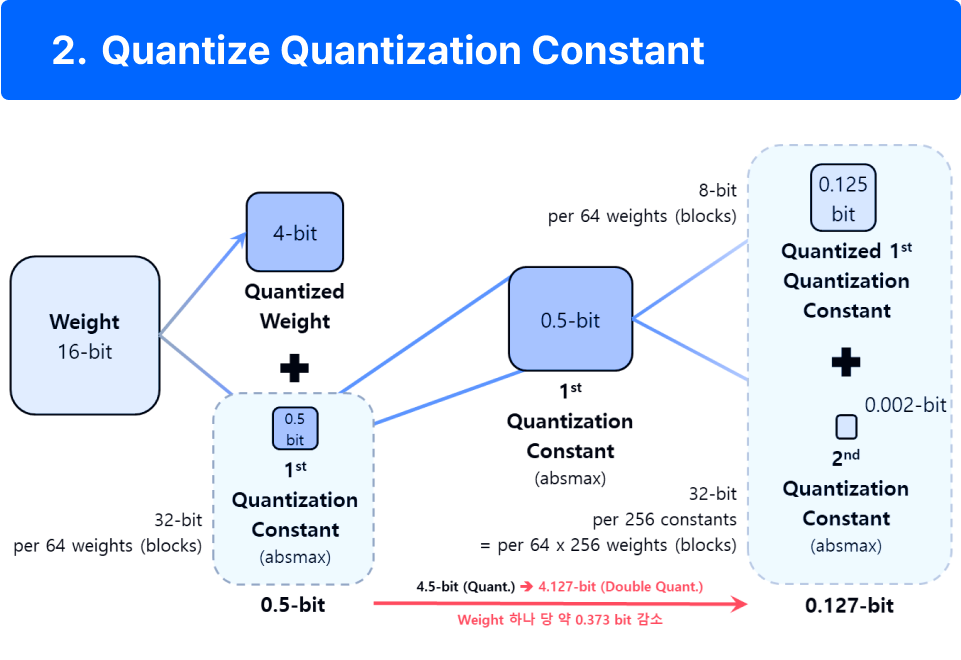
ㅣ학습 포인트
• k-bit block quantization은 블록 크기가 클수록 양자화 상수 개수가 줄어들지만 정밀도가 낮아지는 trade-off
존재하여 QLoRA는 64개의 가중치가 1개의 양자화 상수(64개 가중치 absmax)를 가지고 양자화합니다.
• 양자화 상수는 dequantization을 위해 필요하기에 FP32로 저장되고, 이를 가중치 1개 당 추가 메모리로 계산할 때
0.5비트이기에 NF4는 모델 크기 측면에서 엄밀히 따지자면 4.5비트 입니다.
• 그렇기에 추가되는 비트를 0.5비트보다 작게 만들기 위해 양자화 상수에 quantization을 진행하여 양자화 상수
양자화는 FP32를 FP8로 변환합니다. 단순히 4bit 모델 메모리 외에도 양자화 상수를 저장하기 위한 추가적인 메모리 오버헤드가 발생하기에 추가적인 양자화를 가해 최대한의 메모리 효율을 가져가는 방법을 학습합니다.
유형 3
제한된 리소스 내 학습 및 추론에 도움을 주는
간접적인
유틸리티 기능에 가까운 Paged Optimization
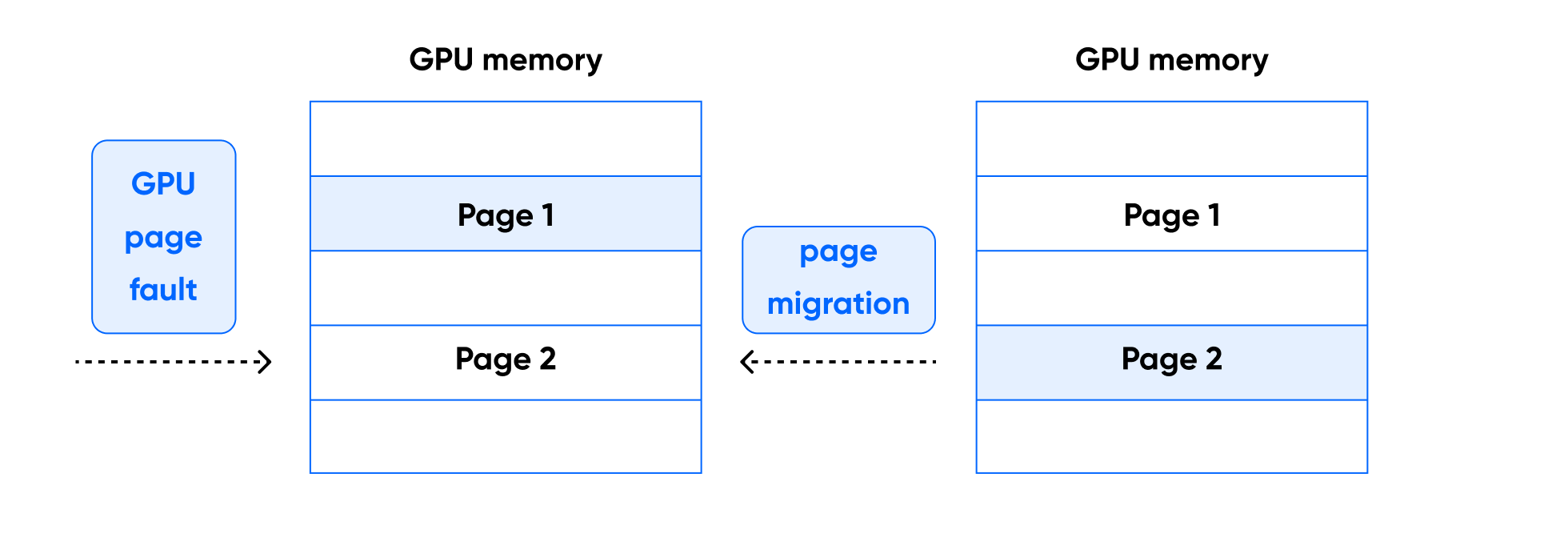
ㅣ학습 포인트
• LLM 개발에 필요한 하드웨어 자원 내에서 프로세스를 메모리로 올릴 때 작은 단위인 page로 분할하여
불연속적으로 저장하는 paging 기술을 학습합니다.
• GPU의 VRAM도 paging을 사용하는 물리 메모리의 일종인데 AI/LLM 모델을 다루면서 메모리가 VRAM
용량을 초과하는 경우 OoM(Out of Memory) 에러가 발생하기 때문에 이러한 방법론이 나오게 되었습니다.
• Paged Optimization은 GPU가 사용하는 VRAM Page를 CPU의 RAM에도 일부 저장할 수 있게 할당하여
가상 메모리와 같은 역할로 활용할 수 있어 메모리 효율을 올리기 위한 하나의 방법으로 활용되고 있습니다.
Step 3. | QLoRA를 활용하여 LLM Fine-Tuning 프로젝트 실습
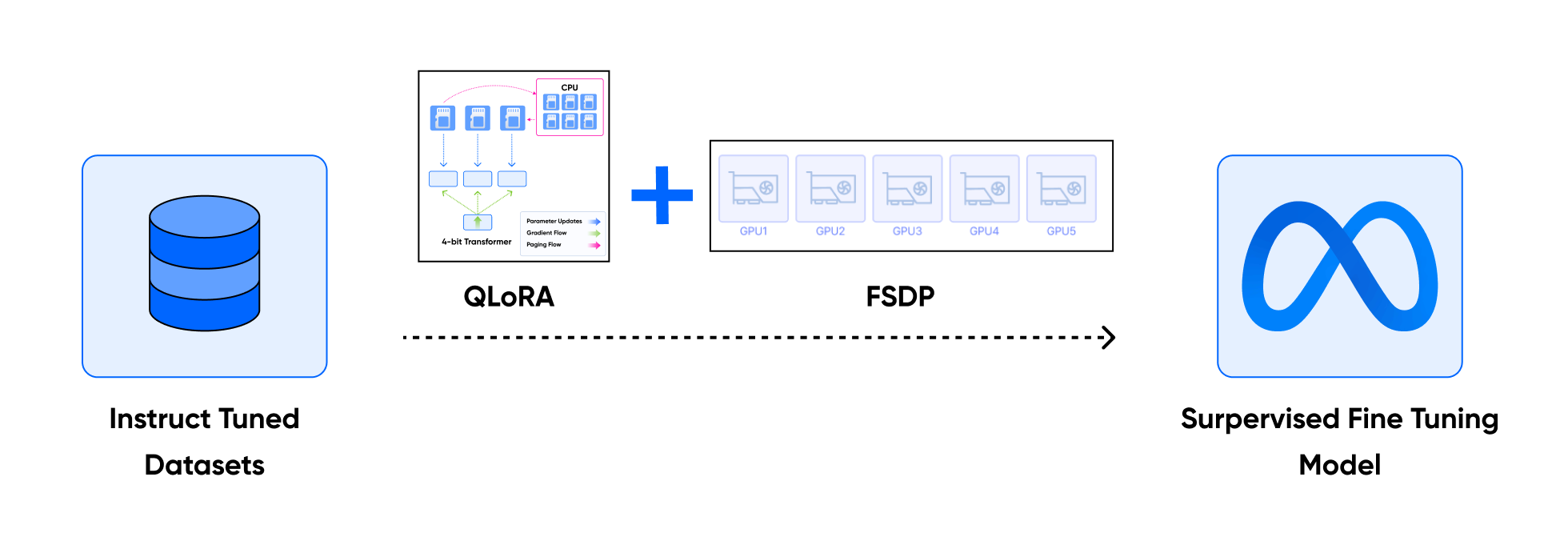
ㅣ학습 포인트
• FSDP와 QLoRA를 결합하여 한정된 자원 내 LLM 서비스를 개발해야 하는 상황에서 LLM 모델을 Robust하게 훈련할 수 있게 하는 방법을 학습합니다.
• QLoRA는 LoRA에 비해 더 적은 메모리 환경에서 가중치를 양자화하여 저장하므로, 파라미터 양이 거대한 LLM에서 메모리 사용량을 절감할 수 있습니다.
• 또한 QLoRA만 사용하였을 때 LLM 모델의 정밀도 손상 가능성을 염두해두고 LoRA를 같이 활용하면서 이를 최소화하며 Fine-Tuning하는 방법을 학습합니다.
• 실습 후, 발생한 여러 상황들과 파라미터들을 구조적으로 이해하며 QLoRA를 고도화하는 방법을 학습합니다.
• FSDP와 QLoRA를 결합하여 한정된 자원 내 LLM 서비스를 개발해야 하는 상황에서 LLM 모델을 Robust하게 훈련할 수 있게 하는 방법을 학습합니다.
• QLoRA는 LoRA에 비해 더 적은 메모리 환경에서 가중치를 양자화하여 저장하므로, 파라미터 양이 거대한 LLM에서 메모리 사용량을 절감할 수 있습니다.
• 또한 QLoRA만 사용하였을 때 LLM 모델의 정밀도 손상 가능성을 염두해두고 LoRA를 같이 활용하면서 이를 최소화하며 Fine-Tuning하는 방법을 학습합니다.
• 실습 후, 발생한 여러 상황들과 파라미터들을 구조적으로 이해하며 QLoRA를 고도화하는 방법을 학습합니다.
Point 4
최신 Quantization 심화 기법 학습
기존 Quantization 진행 중 정수 연산에서 Latency 발생과 저비트로 변환하면서 생기는Outliar와 오차를 막기 위한 최신 Quantization 기법들을 학습합니다.
◈ 4가지 방법론으로 학습하는 최신 LLM Quantization 기법학습
Outliar와 오차가 생기는 기존 LLM Quantization 문제를 극복하고 성능을 올릴 수 있는 방법을 학습합니다.
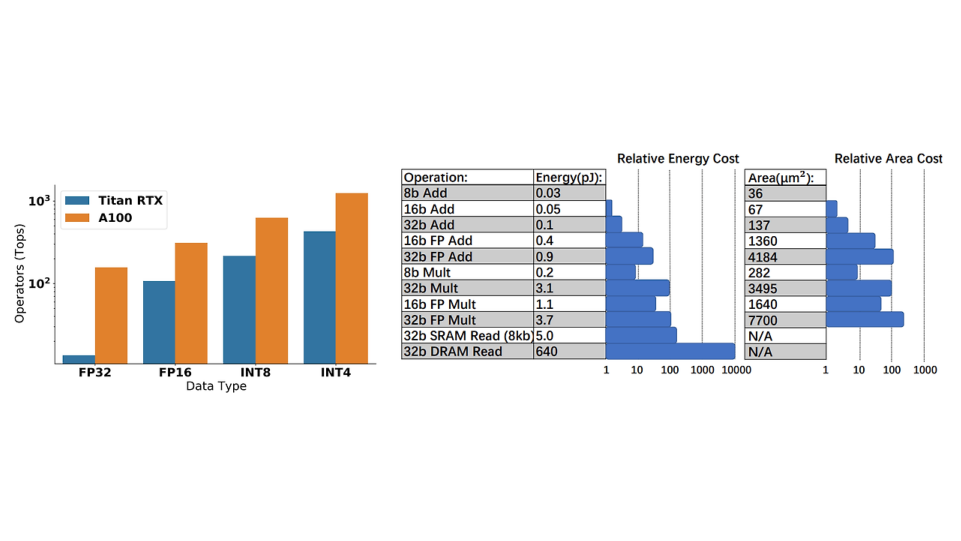
1️⃣ A Survey of Quantization Methods for
Efficient Neural Network Interence
ㅣ학습 목표
• Nerual Network가 획기적으로 높은 성능을 보여주고 있지만 기본적으로
Over-Parameterize 되어 있어
이를 보완하기 위한 다양한 Quantization 기법을
학습합니다.
• 주로 다룰 Quantization 기법
- 효율적인 구조 디자인 : DW Conv, Matrix Factorization, Residual Connection, Inception 등
- 하드웨어를 고려한 NN 구조 설계 : Cache Hierarchy 등을 고려한 NN 구조 설계
- Pruning : Unstructured Pruning / Structured Pruning
- Knowledge Distillation
- Quantization & Quantization and Neuroscience
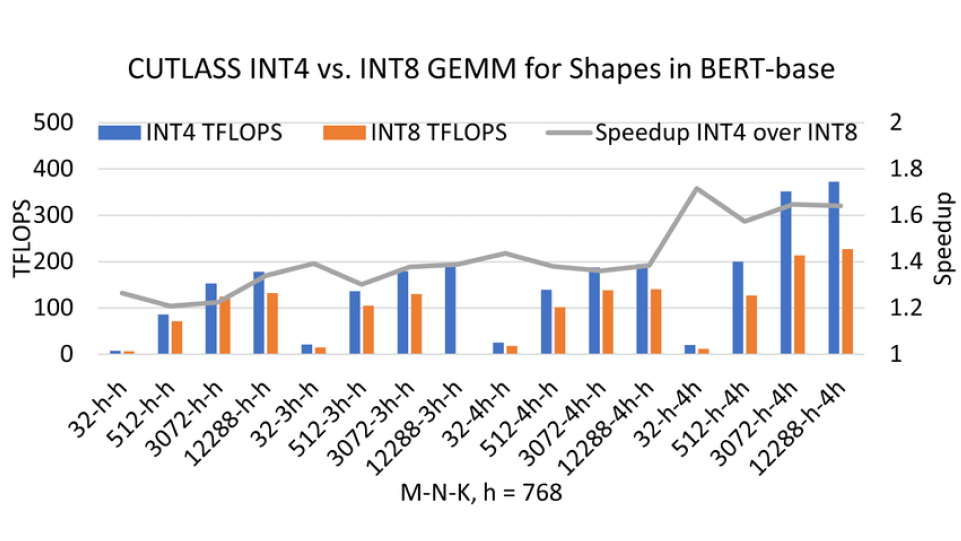
2️⃣ Understanding INT4 Quantization for
Transformer Models
ㅣ학습 목표
• 초기 Quantization은 INT 8과 같은 타입의 Quantization 방법론이 주로 등장하며 Quantization을 진행하는 경향이 짙었습니다.
• 최근, INT 4로 Quantization을 시도하며 기존 Quantization 기법보다 더 빠른 방법론이 관심을 받고 있어 더 경량화 된 LLM 모델을 빠르게 동작할 수 있는 방법을 학습합니다.
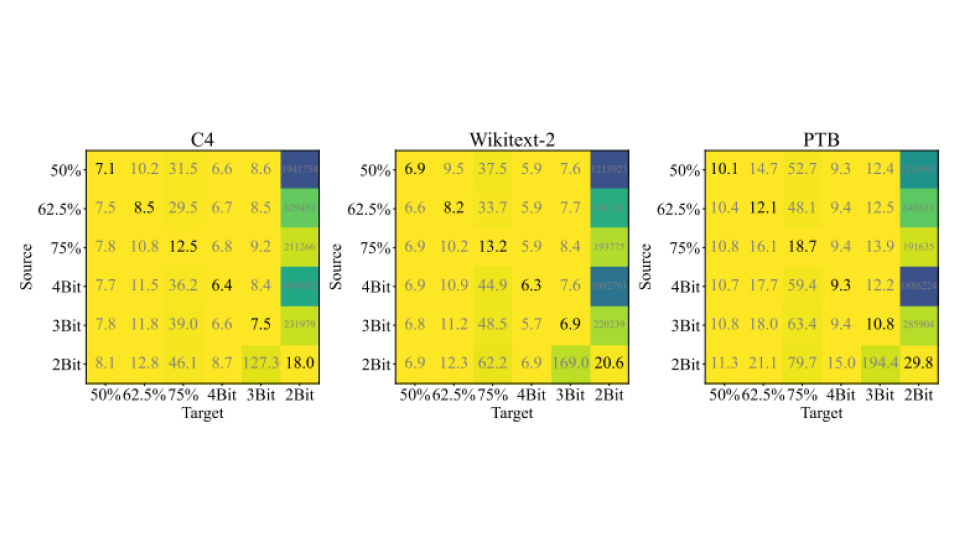
3️⃣ Compress, Then Prompt
ㅣ학습 목표
• LLM은 방대한 파라미터의 양으로 높은 성능을 내지만, 그 규모로 인해 비효율적이고 메모리를 많이 소모합니다.
• 그렇기에 압축된 모델의 성능을 개선하기 위해 소프트 프롬프트 학습 방법을 배우며 Quantization 시에도
기존 LLM 모델과 동일한 성능으로서 역할을 수행할 수 있는 방법을 학습합니다.

4️⃣How Does Quantization Affect
Multilingual LLMs?
ㅣ학습 목표
• Quantization 기술이 LLM의 추론 속도 개선과 배포를 용이하게 하기 위해 사용되지만, 대부분 영어 작업에
초점을 두고 진행이 되고 있었습니다.
• 해당 방법론을 학습하면서 다양한 언어와 모델 규모에 따른 성능 변화를 통해 Quantization 모델이 다른 언어에서 어떻게 적용되는지 학습합니다.
◈ QLoRA를 활용한 2가지 Fine-Tuning 팁 학습


Final Project
극한의 개발 환경에서 Domain Specific LLM 개발을 위한 프로젝트 실습
극한의 GPU 메모리 환경에서 Domain Specific LLM 모델을 개발하기 위한합성 데이터 생성부터 SFT & QLoRA Inference 프로젝트 실습을 직접 구현합니다.
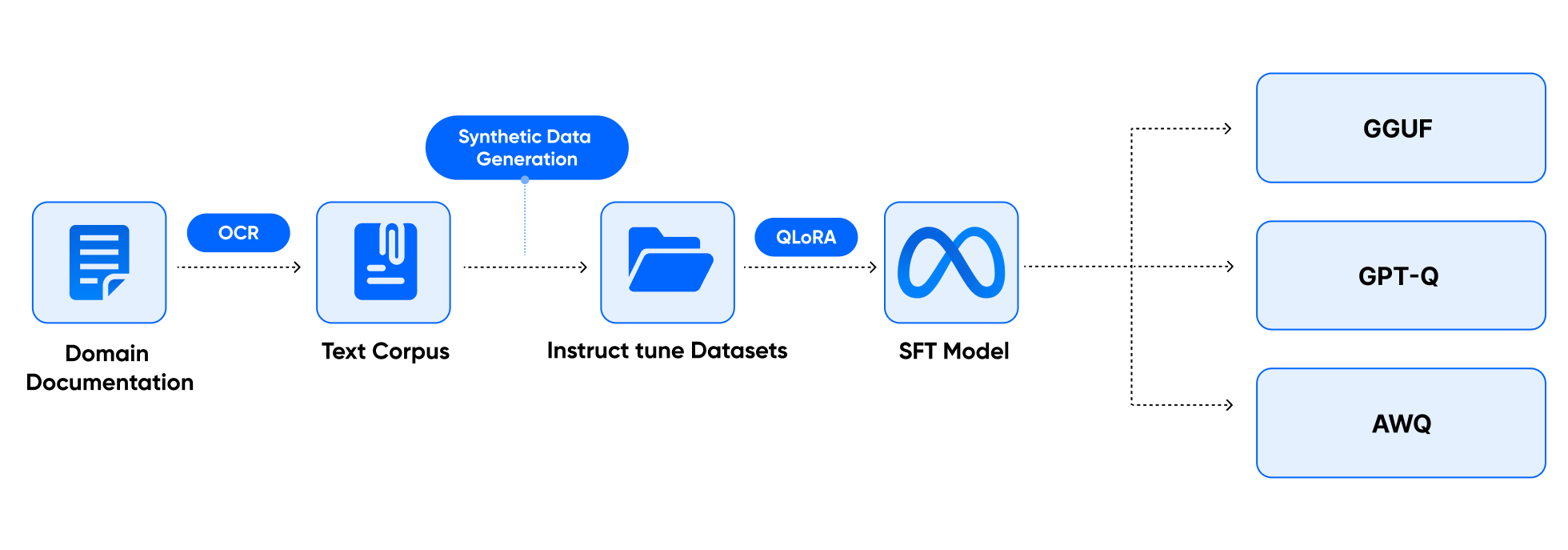
ㅣ프로젝트 실습 개요
• 활용하는 LLM 모델 : LLaMA-3
• Fine-Tuning 방법론 : QLoRA
(8bit 이하의 양자화를 적용하여 적은 메모리 자원에서 Fine-Tuning 가능)
• Data : MarkrAI/kOpen-HQ-Hermes-2.5-60K
• 활용하는 LLM 모델 : LLaMA-3
• Fine-Tuning 방법론 : QLoRA
(8bit 이하의 양자화를 적용하여 적은 메모리 자원에서 Fine-Tuning 가능)
• Data : MarkrAI/kOpen-HQ-Hermes-2.5-60K
ㅣ학습 포인트
• QLoRA를 기반으로 LLM을 특정 서비스 요구에 맞춰 SFT를 진행하는 방법을 학습합니다.
• Fine-Tuning에 필요한 합성 데이터 셋을 생성하는 방법과 모델 학습에 적합한 형식으로 전처리하는 방법을 학습합니다.
• 학습된 모델을 QLoRA로 양자화하고, PTQ(Post Training Quantization) 방법론을 적용하여 메모리 절감과 추론 속도를 향상하는 방법을 학습합니다.
• Fine-Tuning & Quantization이 완료된 LLM 모델을 실제 서비스 환경에서 Inference하는 방법을 학습합니다.
• QLoRA를 기반으로 LLM을 특정 서비스 요구에 맞춰 SFT를 진행하는 방법을 학습합니다.
• Fine-Tuning에 필요한 합성 데이터 셋을 생성하는 방법과 모델 학습에 적합한 형식으로 전처리하는 방법을 학습합니다.
• 학습된 모델을 QLoRA로 양자화하고, PTQ(Post Training Quantization) 방법론을 적용하여 메모리 절감과 추론 속도를 향상하는 방법을 학습합니다.
• Fine-Tuning & Quantization이 완료된 LLM 모델을 실제 서비스 환경에서 Inference하는 방법을 학습합니다.
Q&A
Question 1.
어떤 분들이
수강하시면 좋을까요?
수강하시면 좋을까요?
개인이나 기업은 자원의 부족함으로 인해 LLM 모델을 활용하여
서비스를 개발하는 측면에 항상 부족함을 느끼고 있습니다. 이 강의에서는
AI/LLM 엔지니어분들께서 LLM 모델을 Quantization하는 방법을 학습함으로써,
극한의 환경에서도 개발하고자 하는 서비스에 맞춰 LLM 모델을 개발하실 수 있는
방법을 배우실 수 있습니다.
Question 2.
해당 주제를 학습하면서 겪는
가장 대표적인 어려움은 무엇인가요?
가장 대표적인 어려움은 무엇인가요?
AI/LLM 서비스를 개발하면서 항상 자원과 성능에 큰 어려움을 겪는다고 생각합니다.
특히 이를 해결하기 위한 Quantization을 도입할 때 정밀도를 낮춤으로써 큰 문제점이
발생합니다. 이러한 문제점이 발생하는 원인을 제대로 파악하고 진단하여 맞춤형 LLM을 훈련하고 만들어 배포하기까지 문제 없이 진행할 수 있도록 강의를 기획하였습니다.
Question 3.
강의를 수강한 후에
어떤 내용을 학습할 수 있나요?
어떤 내용을 학습할 수 있나요?
현재 내가 가지고 있는 LLM 자원을 최적화해서 어떻게 성능을 극대화 하여 활용할 수 있는지 알 수 있는 방법과, LLM 파인튜닝을 하더라도 어떻게 파인튜닝하는지 보다 상황 별로 왜 특정 파인튜닝 방법을 선택하였는지 원리를 이해하면서 LLM 파인튜닝을 학습하실 수 있게 됩니다.
Question 4.
개발 환경
강의에서는 Multi-GPU 환경에서 진행 할 예정이지만, Google Colab 활용 Local GPU(유료)
에서도 충분히 진행할 수 있도록 강의를 구성 할 예정입니다.
커리큘럼
아래의 모든 강의를 초격차 패키지 하나로 모두 들을 수 있습니다.
지금 한 번만 결제하고 모든 강의를 평생 소장하세요!
Part 01. LLM과 Quantization 기초
Part 02. Fine-Tuning을 위한 Quantization
Part 03. LLM 모델을 훈련 후 Quantization
Part 04. Quantization 심화
Part 05. 프로젝트 실습 및 응용
LLM 모델 파인튜닝을 위한 Quantization
추천강의