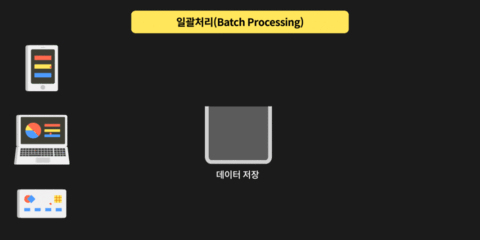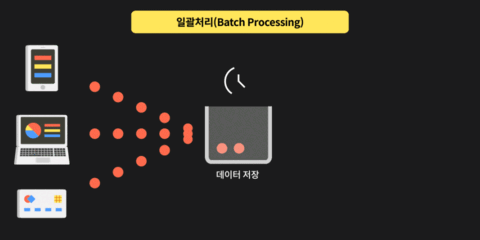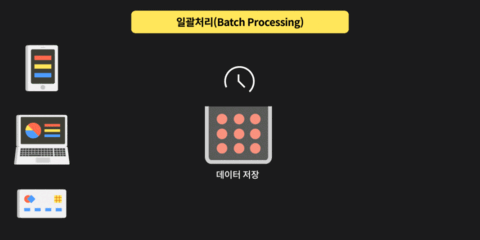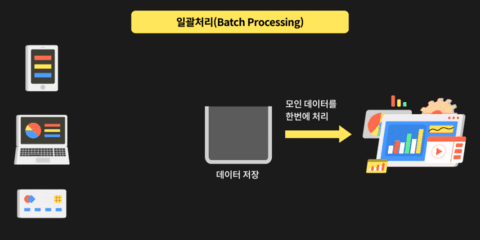
특정 시간 범위 내 대량의 데이터를 일괄 처리
매주 발행하는 뉴스레터매월 서비스 내 관심을 보인 유저에게 마케팅 이메일 발송
특정 일자 수요와 공급 예측
...
초격차 패키지
실시간 빅데이터 처리 위한
Spark & Flink & Kafka


실시간 데이터 처리 주요
프레임워크의 핵심개념과 기술 학습
Spark & Flink & Kafka & Airflow 4가지 실시간 처리 주요 프레임워크의 핵심 개념과 기술들을 배워보고 이해할 수 있습니다.
데이터 프로세스 조직화
데이터를 생산하는 프로듀서, 데이터를 소비하는 컨슈머, 분석 및 저장하는 단계까지 실시간 데이터 처리를 위한 스케줄링과 모니터링을 통한 조직화 방법을 배울 수 있습니다.
다양한 도메인과 서비스 환경에 맞는
실시간 데이터 처리와 문제해결
현업에서 실시간 데이터 처리가 필요할 때 기술 선택부터 해결방법, 실행까지 활용하는 방법을 배울 수 있습니다.


대용량 트래픽이 발생하는 대기업일수록 빅데이터를
효율적으로 처리할 수 있는 데이터 엔지니어의 역할이 중요합니다.
특정 시간 범위 내 대량의 데이터를 일괄 처리
매주 발행하는 뉴스레터
특정 시간 범위 내 대량의 데이터를 일괄 처리
매주 발행하는 뉴스레터
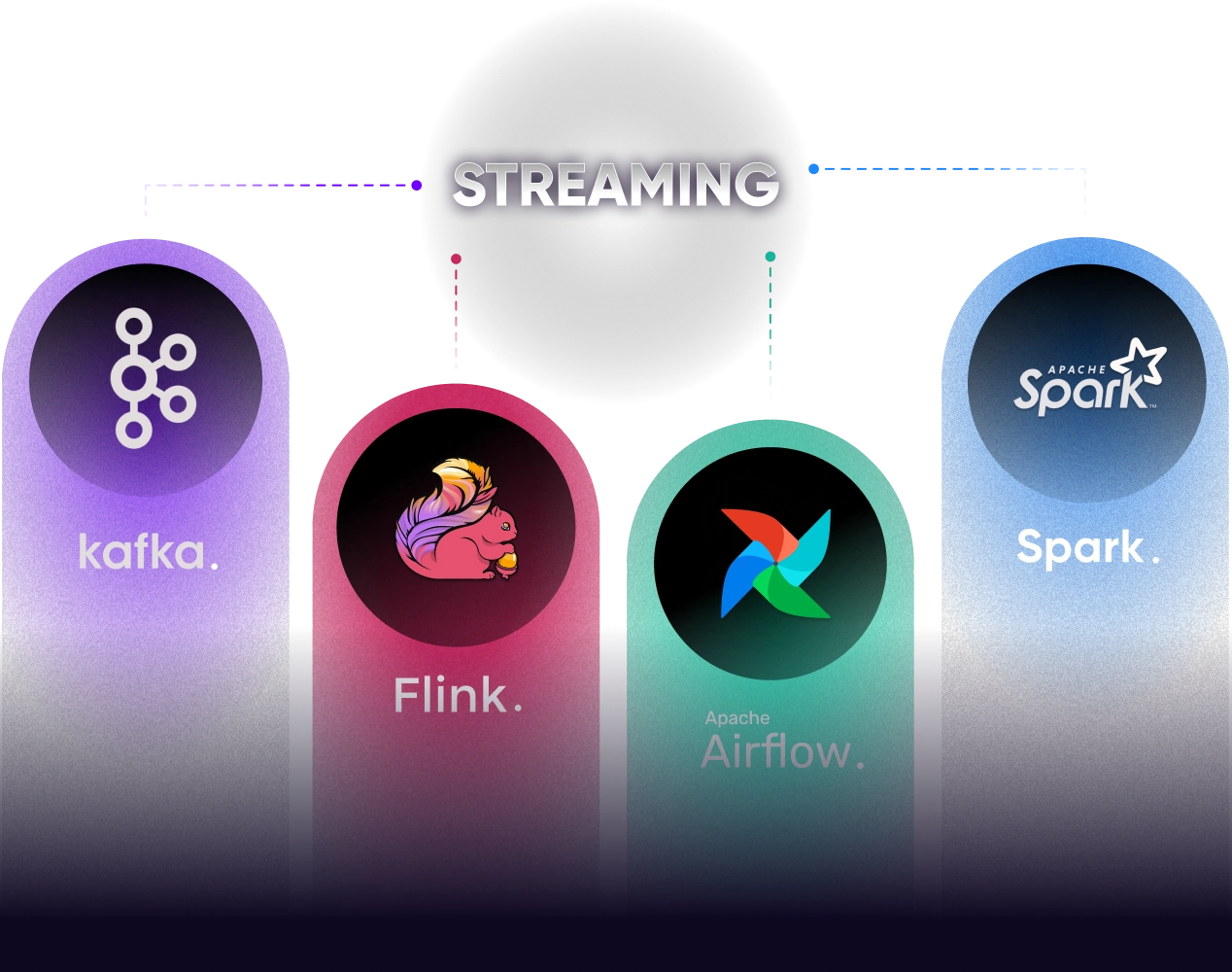
실시간 데이터 처리 주요 프레임 워크
상황과 목적에 맞게
데이터 일괄처리(batch processing) 와
실시간 처리(Stream processing)을
적절히 확용하는 것이 데이터 엔지니어링의 핵심입니다.
실시간 데이터 처리의 핵심 기술인 Spark, Flink, Kafka, Airflow 핵심 개념과 각 프레임워크가 제공하는
여러 기능들을 배우고 다양한 실습을 통해 어떻게 활용되는지 노하우를 얻어갈 수 있습니다.




POINT 1
실시간 데이터 처리 주요 기술들을 한번에!
Apache Spark & Flink & Kafka & Airflow


POINT 2
실무에 바로 적용할 수 있는 실시간 데이터 처리 실습
실시간 데이터를 어떻게 다루고 처리할 수 있는지 각 기술별로 다양한 예제와 실습을 진행해봅니다.
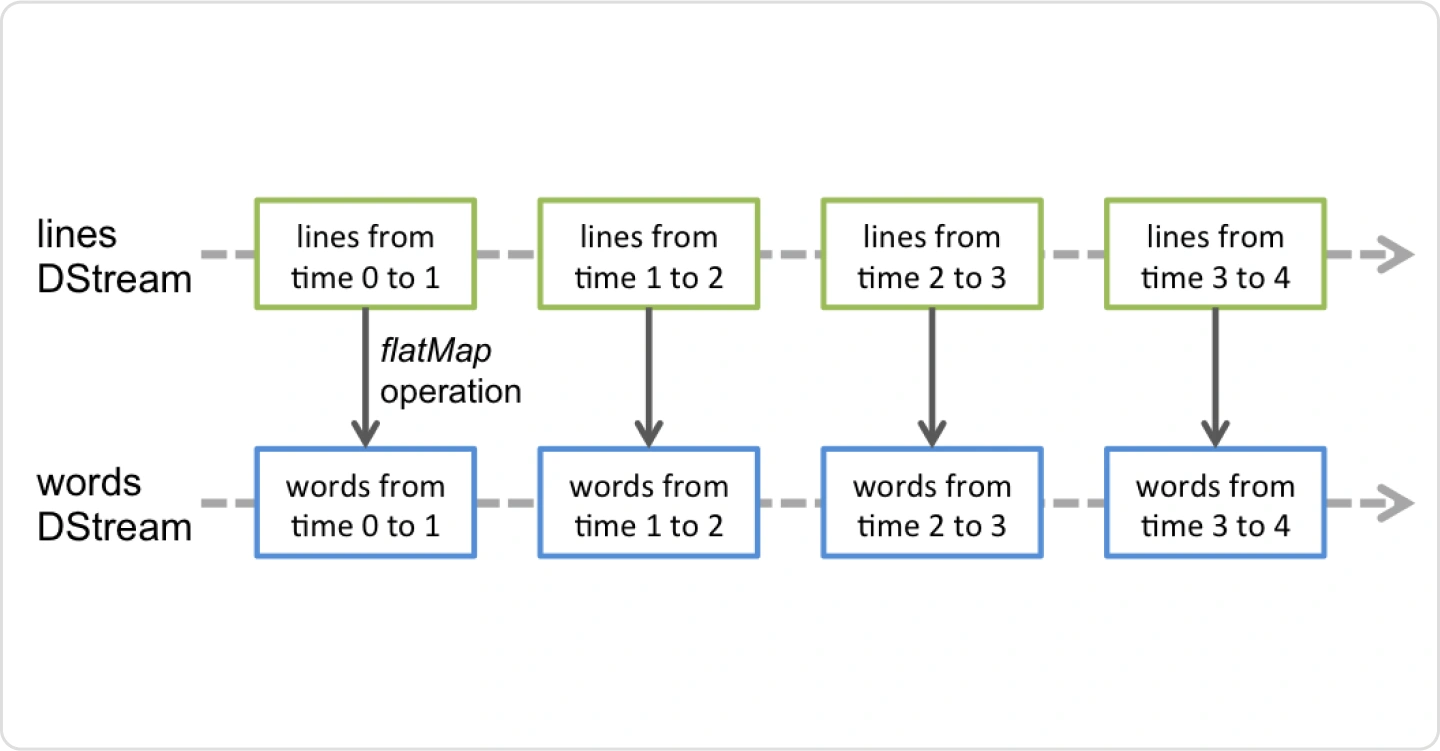
Spark의 주요 Streaming API인 DStream API를 통해
마이크로 배치 방식 데이터 처리 실습 진행해봅니다.
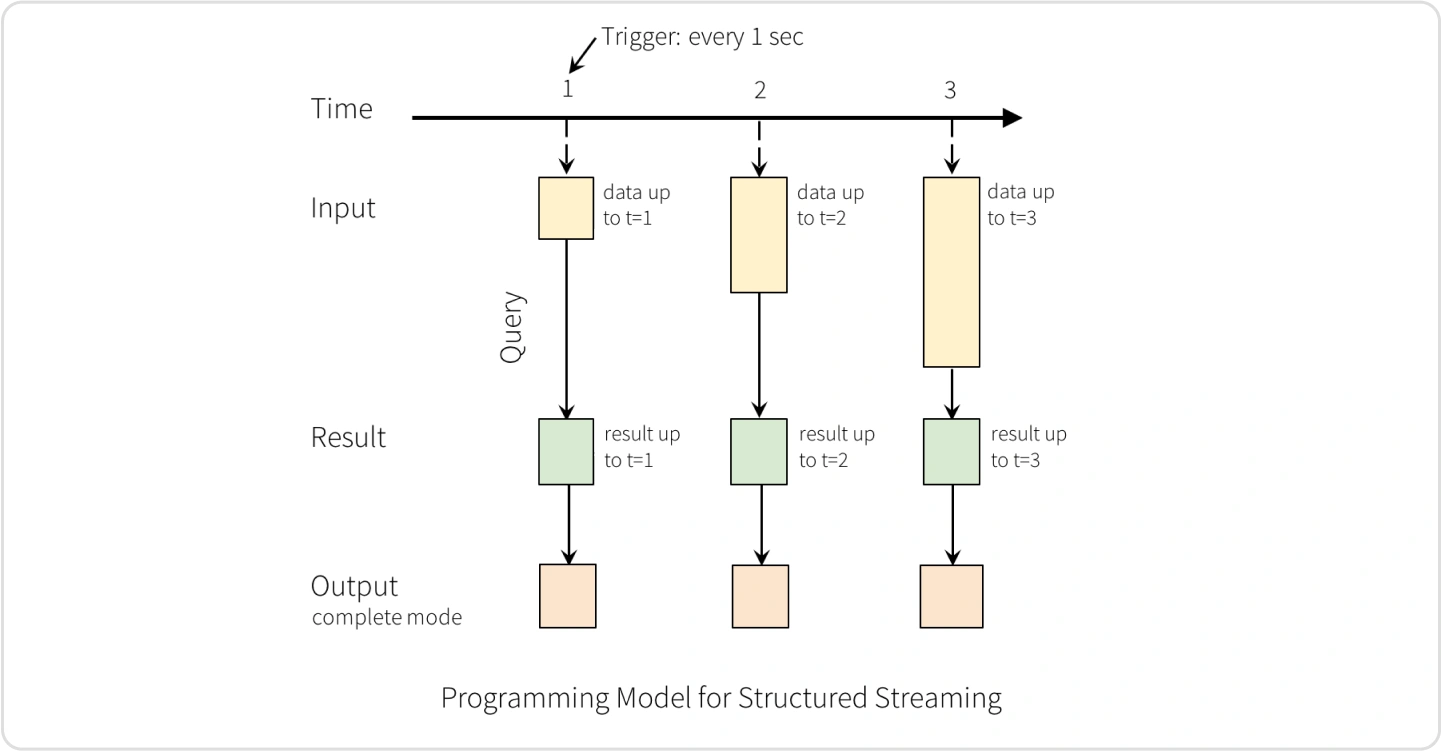
Streaming data를 Spark로 처리해보고
간단한 Spark Structured Streaming Pipeline 구축해봅니다.

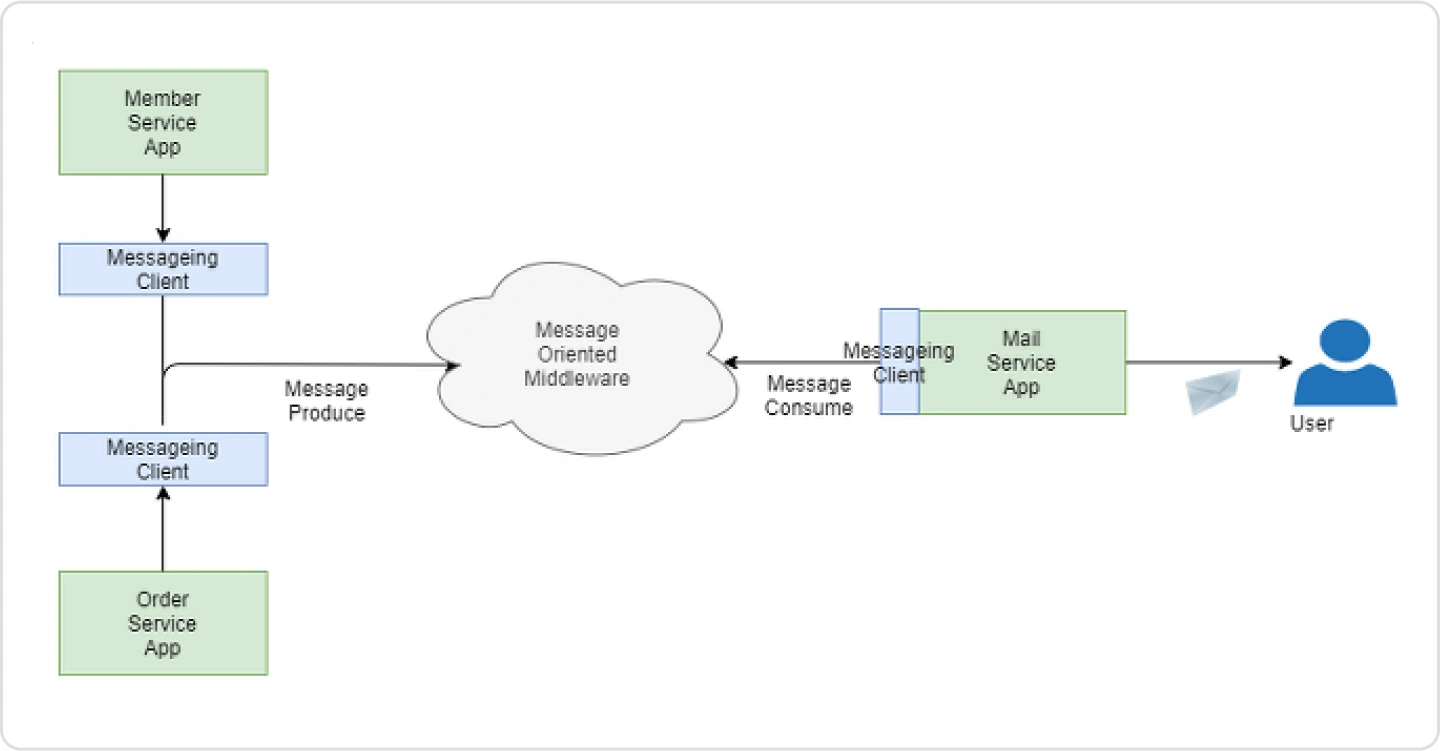
메일 전송에 필요한 데이터를 API로 호출하고
Kafka를 통해 메시지를 생산한 후 API 정보를 User에게 발송하는 실습
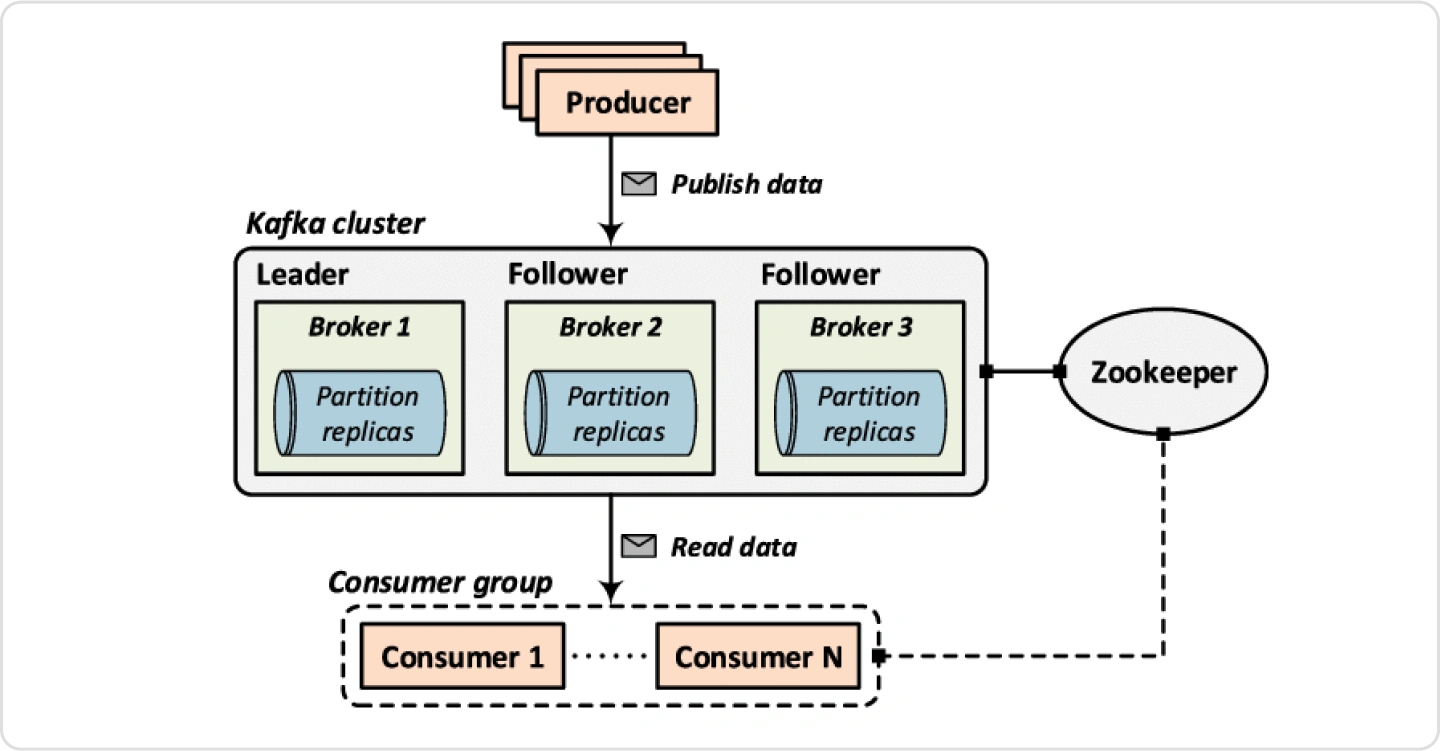
Producer과 Consumer구성을 알아보고
간단한 Event Streaming Pipeline을 구성해보는 실습
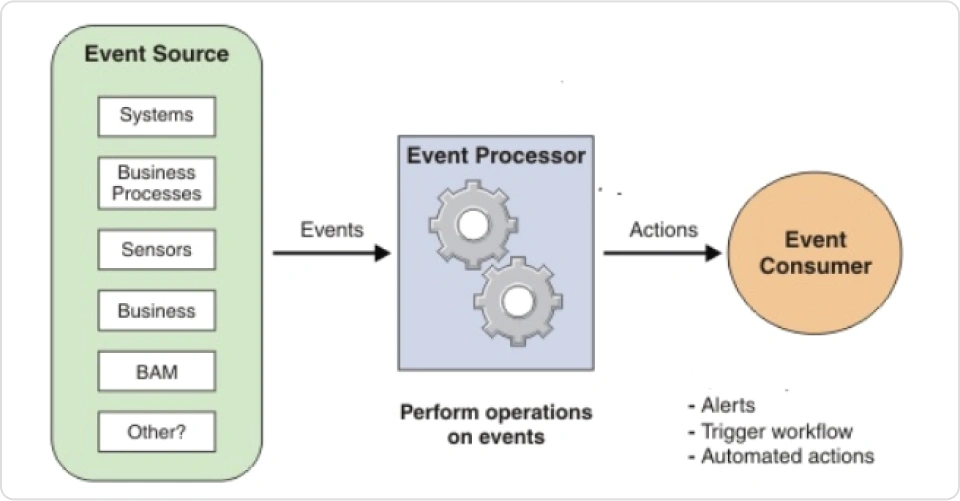
Pattern API 를 활용하여 Time 정보 없이 서로 다른 정보를 집계하여
인과관계를 식별 및 분석하는 방법에 대한 실습

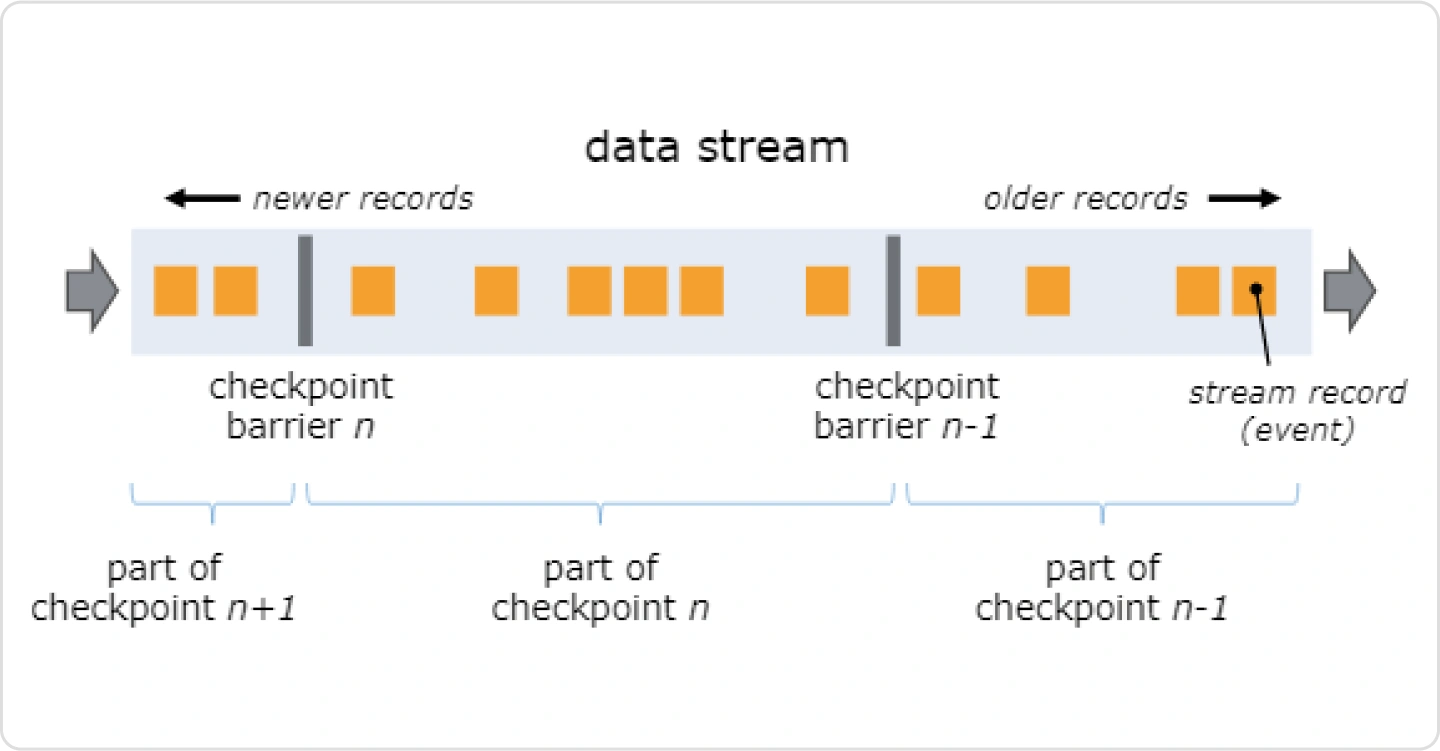
각 Process Function을 활용하여 Stateful하고
Timely한 스트리밍 데이터를 어떻게 다룰 것인지 간단한 예제와 실습 병행
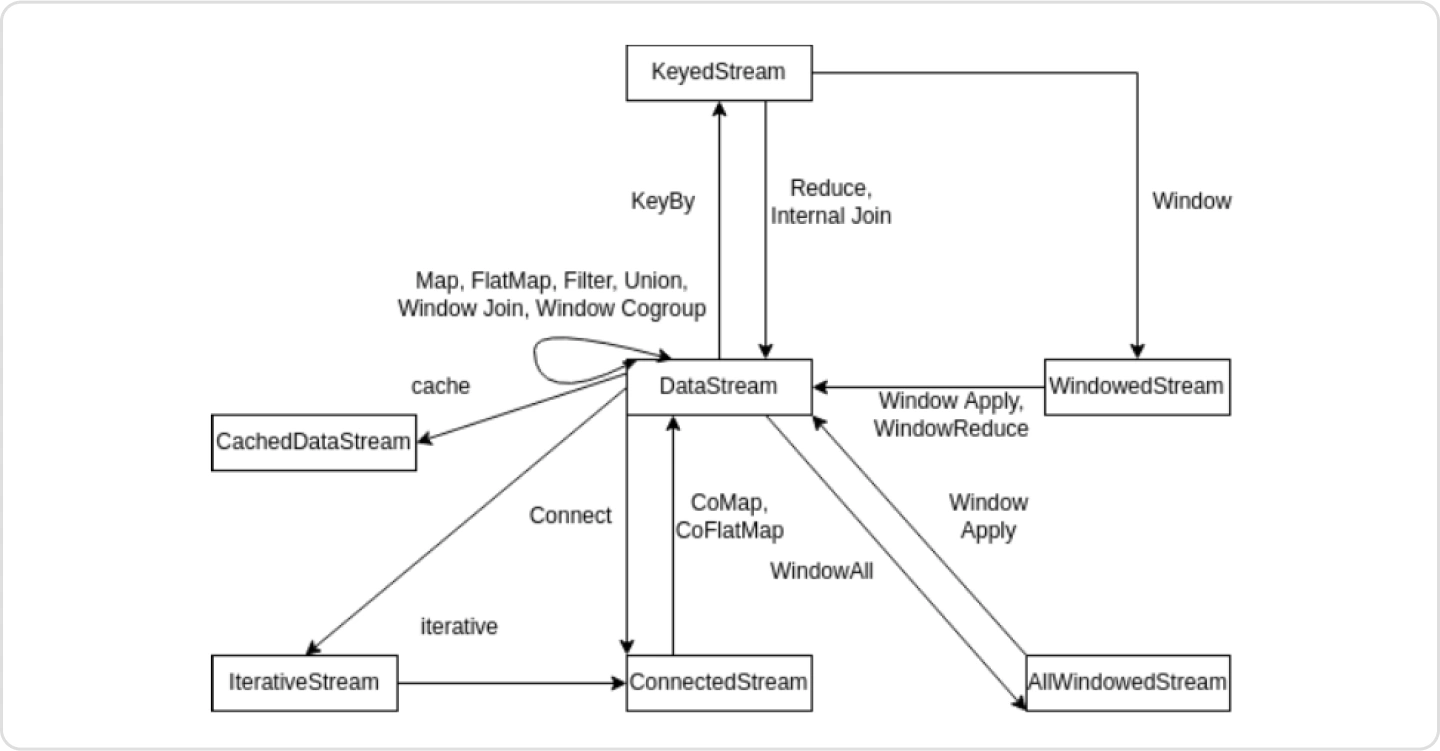
Map 및 FlatMap 등 기본적인 Transformation부터
Window, Join, Connect 및 Iterate 까지 각 Operate 실습

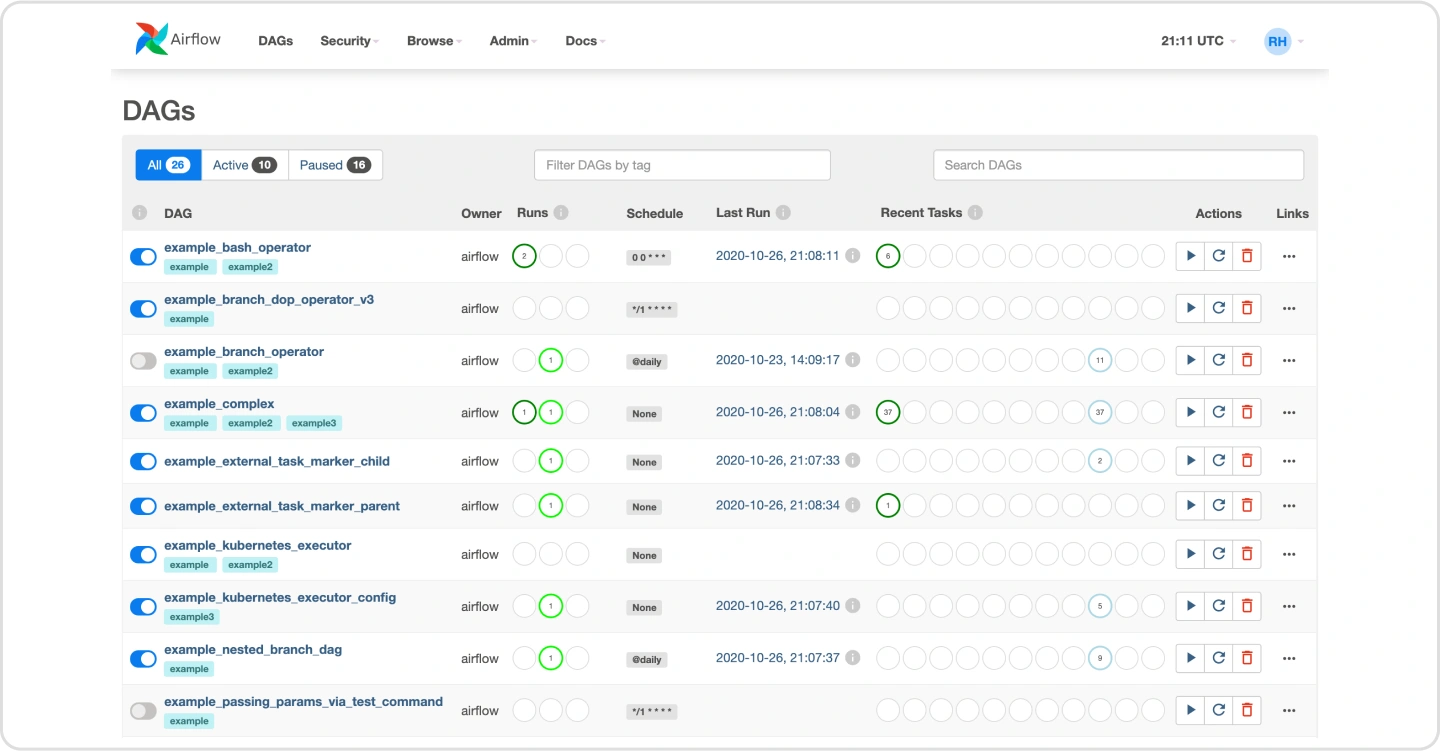
Airflow가 Batch workflow를 오케스트레이션하기 위해 선택했던
DAG구조와 해당 구조에 접근하는 사용자에게 마련한 계층적인
인터페이스 형태를 이해하고 Operator에 적용할 수 있는 틀 잡기
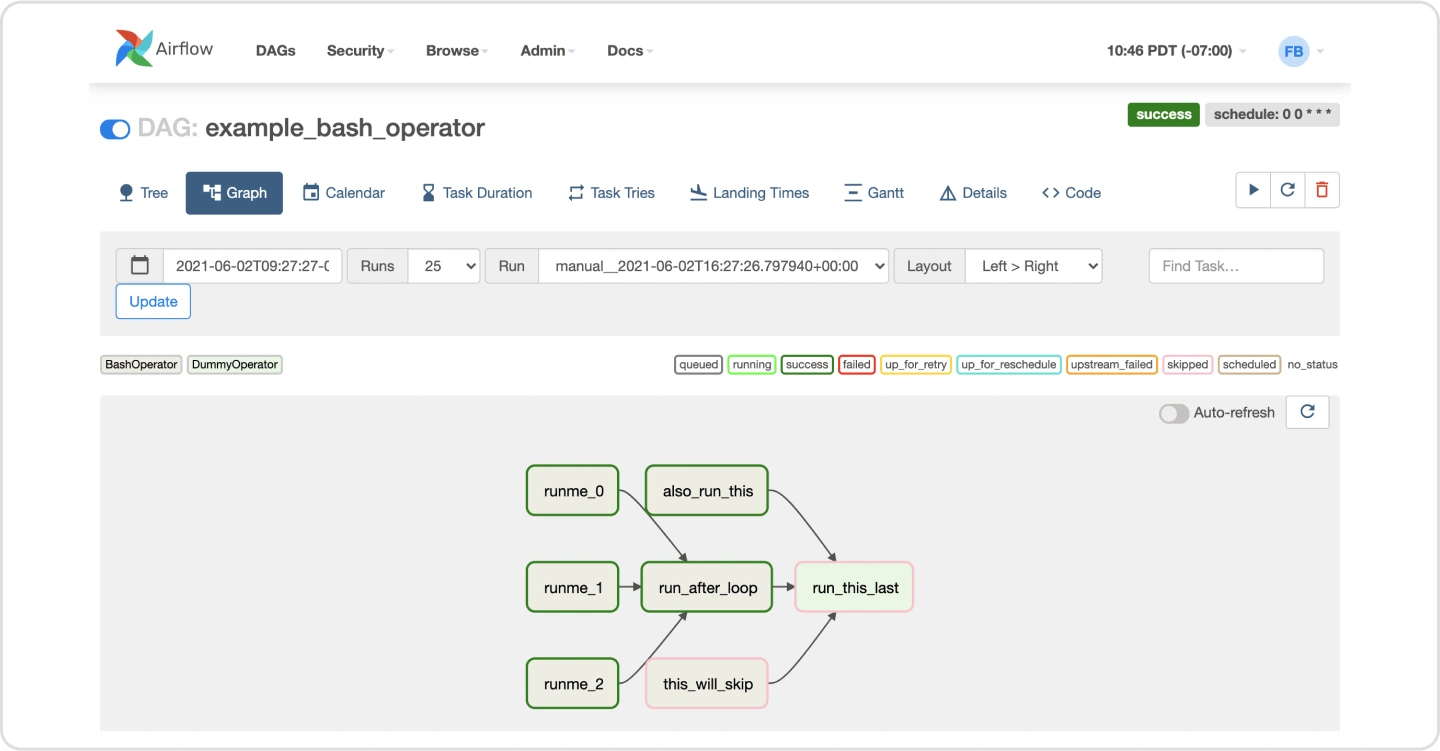
Data pipeline의 근간을 이루는 Operator 중 대표적인 것들을 살펴보고, 제공하지 않는 기능을 가진 Operator를 자유롭게 구현할 수 있는 방법 학습
POINT 3
실무 데이터를 활용한 실시간 데이터 처리 프로젝트
여러 서비스 환경과 상황에 따른 실무 데이터를 활용하여 실시간으로 데이터를 처리하는 프로젝트를 진행해봅니다.

뉴스를 실시간으로 kafka 에 저장한 후 Flink를 통해
실시간으로 Clustering을 처리하여 kafka와 MYSQL 에 저장하는 프로젝트

쇼핑 시스템에서 결제 데이터를 활용하여 준실시간으로
들어오는 데이터를 가져와 비정상적인 세션을 감지하고 지표를 추출하는 프로젝트
POINT 4
전문가에게 직접 물어보는 실시간 데이터 엔지니어링 실무
실무에서 발생하는 문제들 및 활용방법 등과 관련하여 예비, 현직 데이터 엔지니어가 궁금해할 알짜배기
*교육 내용 범주 안에서만 질의응답 가능합니다.
*2023년 9월 8일부터 2025년 9월 8일까지 운영됩니다.
Question.1
Question.2
Question.3
강사님 소개

[이력]
현) 쿠팡 data engineer
안녕하세요. 저는 국내 IT 대기업에서 데이터 엔지니어로 일하고 있으며,
배치/실시간 데이터 파이프라인을 구축하는 업무를 진행했었고 현재는 데이터 플랫폼을
구축하는 업무를 진행하고 있습니다.
이 강의는 실시간 데이터 처리를 처음 시작하려고 하시는 분들을 대상으로
각각의 프레임워크에 대한 전반적인 이해 및 사용 방법에 초점을 둔 강의입니다만,
알고 있으면 좋다고 느꼈던, 혹은 일하면서 도움이 되었던 심화 개념들에 대해서도
각 파트별로 다룰 예정입니다. 해당 강의를 통해 혼자 공부하시거나 실무 활용에 어려움 겪고
계시는 많은 데이터 엔지니어분들께 조금이나마 도움이 되었으면 합니다.
[이력]
현) 국내 대형 증권사 Data engineer
전) 국내 주요 포털사 Data Engineer
안녕하세요. 저는 포탈 기업에서 데이터 엔지니어를 시작해서, 현재는 증권 회사에서
해당 업무를 지속하고 있습니다. Hadoop 및 EcoSystem 관리부터 Spark 및 Flink 등을
활용한 데이터 분석과 CI/CD 구성 및 API Server 구축까지 데이터 엔지니어로서 할 수 있는
업무 전반에 대한 경험이 있습니다.
해당 강의를 통해 현업에서 실시간 데이터 파이프라인 구성 요구사항이 생겼을 때,
또는 유사한 업무를 해야하는 경우에 기술 선택부터 문제 해결을 위한 방법 및 실행까지
활용될 수 있습니다. 더불어 실시간으로 데이터를 수집하고 저장하는 업무를 수행함으로써
회사의 데이터 활용 전반에 걸쳐 중추적인 역할을 할 수 있고, 더 나아가
데이터사이언티스트/데이터 분석가 분들과 협업을 통해 훌륭한 결과를 도출해내는데
기여할 수 있습니다.
커리큘럼
분산처리의 a to z를 알려주는 학습 커리큘럼을 확인하세요.
분산처리 시스템을 포함한 다양한 툴과 프레임워크 개념부터 현업에서 활용하는 데이터 파이프라인 구축 실습까지 체계적으로 배워가세요
Part1. 데이터 엔지니어링이란?
Part2. 배치 / 스트림 프로세싱 - Apache Spark
Part 3. 스트림 프로세싱 - Apache kafka
Part 4. 스트림 프로세싱 - Apache flink
Part 5. Airflow 통한 배치 프로세싱
Part 6. 스트림 프로세싱 프로젝트
자세한 커리큘럼 및 내용은 여기서 확인하세요!

국내 7개 카드사 12개월 무이자 할부 지원! (간편 결제 제외)