
허정준 강사님
yes24, 교보문고, 알라딘
베스트셀러 ‘LLM을 활용한 실전 AI 애플리케이션 개발‘ 저자
vLLM의 사용법 자체는 쉽죠.
그러나, 근간인 추론을 이해하는 것과,
효율적으로 활용할 수 있는 전략을 짜는 것이 어렵습니다.
안녕하세요, 허정준입니다. 현업에서 AI 엔지니어링 업무를 하며
2023년 LLM을 지탱하는 주요 기술들이 조금씩 정리되는 느낌이 들었고
LLM과 관련된 전반의 기술을 총정리하여 책을 집필하였습니다.
책에서 LLM 서빙을 위한 프레임워크로 vLLM을 간단히 소개했었는데요.
이번 강의를 통해 vLLM과 LLM 서빙에 대해 깊이 있게 다뤄보고
단순한 프레임워크 사용법이 아니라 LLM에 대한 기술적 이해를 바탕으로
자신있게 LLM 서빙에 접근할 수 있도록 도와드리려고 합니다.
책 구매 바로가기 (교보문고)
vLLM을 활용한 고성능 저비용 LLM 서빙의 모든 것
vLLM을 활용한 고성능 저비용 LLM 서빙의 모든 것

AI 실 서비스를 오픈할 때 마주하는 가장 큰 문제가 무엇일까요?



이에 주목받고 있는, 서빙의 성능을 높이기 위한
추론 라이브러리 vLLM과 추론 최적화 전략!

실제로 vLLM을 채택하는 기업들은 점점 늘어나고 있으며,
특히 글로벌 IT 대기업들은 앞장서 채택하고 있습니다.

vLLM 추론 라이브러리로 추론 시
추론 속도는 10배 빠르고!
GPU 사용료는 1/10배 절약!
 Before
Before
huggingface 기본 라이브러리로 추론할 때
Before
huggingface 기본 라이브러리로 추론할 때
추론 프레임워크 없이 서빙될 때 추론속도가 느립니다.
 After
After
vLLM 추론 라이브러리로 추론할 때
After
vLLM 추론 라이브러리로 추론할 때
추론 프레임워크 vLLM을 활용하여 서빙하면 추론속도가 빨라집니다.

쏟아지는 책 간증으로
의심할 여지 없는 저자의 역량.



베스트셀러 저자와 함께
LLM 서빙의 개념과 GPU 최적화를 완성하세요.



커리큘럼
베스트셀러 저자 허정준이 정리한
LLM 모델을 저비용 고성능으로 서빙하기 위한 모든 것
입문자를 위한 LLM 의 개념부터 비용효율적인 추론을 위한 최적화 전략 6가지,
그리고 책에서는 볼 수 없었던 vLLM을 활용한 실습까지!
Course 01
LLM 서빙을 위한 기초
LLM을 처음 입문하는 분들도 시작하실 수 있는 기초지식을 압축하여 알아봅니다.



Course 02
6가지 LLM 추론 최적화 전략
빠르고 비용효율적으로 LLM을 서빙할 수 있는 6가지 전략을 알아봅니다.



Course 03
vLLM을 활용한 추론 최적화 전략 적용
vLLM을 활용한 실습을 통해 Step 2에서 배운 추론을 최적화 방법을 직접 체득해 봅니다.
* 오직 패스트캠퍼스에서만 수강할 수 있는 내용입니다.



개별적으로 최적화 전략을 이해하고 vLLM과 함께 실습으로 구현하는 강의는
전세계 어디에도 없습니다!
초보자도, 고수도! 국내외 통틀어 LLM서빙을 가장 체계적으로 배울 수 있는 커리큘럼

vLLM을 활용하여 LLM 추론 속도를 제.대.로. 높이려면
먼저 LLM 추론 최적화 전략을 정복하셔야 합니다.
추론 속도를 높이는 6가지 LLM 추론 최적화 기법

Point 1
상황별 / 모델별로 더 GPU 사용 시간을 줄일 수 있는
추론속도 최적화 전략 6가지를 지금 공개합니다.
6가지 추론 최적화 전략을 이해하고 실습하여 상황별 / 모델별로 더 GPU 사용 시간을 줄일 수 있는
최적화 전략 선택 기준을 지금 공개합니다.

이제는 모든 라이브러리에 적용된
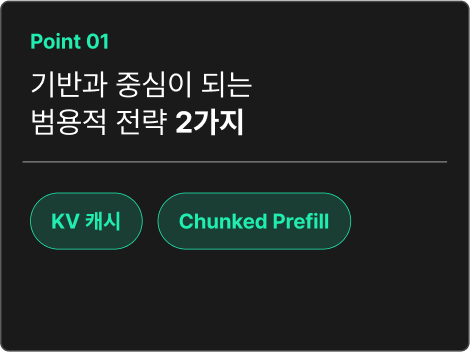
KV 캐시를 사용한 추론 속도 높이기
| KV 캐싱 기법의 Key Point
LLM 추론 과정에서 반복적인 어텐션 연산을 효율적으로 처리하기 위해 이전 연산 결과를 저장해 활용함으로써 중복 연산을 줄여 추론 속도를 높입니다.
| 학습 내용 미리보기
• GQA, MQA 살펴보기
• Prefix 캐싱 기법
• Prefix 캐싱 기법

청킹 전략 중 범용적으로 활용되는
Chunked Prefill 추론 최적화
| chunked prefill의 Key Point
입력 처리 단계(Prefill)와 출력 생성 단계(Decoding)를 분리해서 처리하며 응답시간이 길어질 때, 분리해서 처리하던 Prefill을 묶음으로 나눠 Decoding과 함께 처리합니다.
| 학습 내용 미리보기
• 배치 전략 - 정적 배치
• 배치 전략 - 연속 배치(Continuous Batching)
• 페이지 어텐션으로 메모리 사용량 줄이기
• 배치 전략 - 연속 배치(Continuous Batching)
• 페이지 어텐션으로 메모리 사용량 줄이기
Point 2
모델 상황별로 적합한 전략을 활용하는
파인튜닝을 통해 성능을 높이는 최적화 전략 3가지
파인튜닝의 상황별로 더 GPU 사용 시간을 줄일 수 있는
최적화 전략 선택 기준을 지금 공개합니다.

여러 디코딩 헤더들을 추가하여
추론 속도 높이는 추측 디코딩(Speculative Decoding)
| 추측 디코딩의 Key Point
LLM이 토큰을 생성할 때 작은
모델과 큰 모델 2개를 활용해 추론 속도를 높입니다.
이때 두 개의 모델을 활용하면 복잡해지기 때문에 하나의 모델을 사용하면서 여러 개의
토큰을 한
번에 예측하는 헤드를 추가하는 방식을 택합니다.
| 학습 내용 미리보기
• 추측 디코딩 소개
• 디코딩 알고리즘 메두사
• 디코딩 알고리즘 메두사

어댑터만 학습시켜서 메모리 사용량을 줄이는
파인 튜닝, LoRA와 QLoRA
| LoRA와 QLoRA의 Key Point
사용하려는 작업에 따라 추가적인 성능
향상이 필요합니다. 전체보다는 일부 파라미터만 파인튜닝함으로써 적은 GPU에서도 학습이 가능하게 합니다.
| 학습 내용 미리보기
• 어댑터와 기초 모델 결합해 추론하기

연산 전략을 짜서 불필요한 소요 시간을 줄이는
Multi-LoRA 서빙
| Multi-LoRA 서빙의 Key Point
여러 어댑터가 있는 경우(ex.
요약을 위한 어댑터, 번역을 위한 어댑터)
추론 과정에서의 요청에 따라 다른 어댑터를
효율적으로 활용할 수 있어야 합니다.
| 학습 내용 미리보기
• 여러 개의 어댑터를 전략적으로 정리하여 추론하기
Point 3
요즘 가장 핫한 양자화!
양자화 모델에 적용할 수 있는 최적화 전략의 끝판왕
6가지 추론 최적화 전략을 이해하고 실습하여 상황별 / 모델별로
더 GPU 사용 시간을 줄일 수 있는 최적화 전략 선택 기준을 지금 공개합니다.

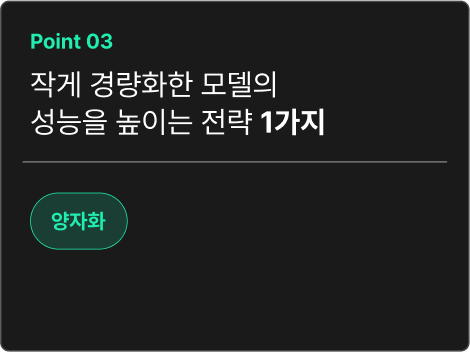
이미 경량화된 모델에서 성능을 높이는
양자화 (Quantization)
| Multi-LoRA 서빙의 Key Point
LLM은 모델이 크기 때문에 하나의 GPU에 올리지 못하거나 올리더라도 배치 크기를
키우지 못하는 문제가 있습니다. 이런 문제를 해결하기 위해 모델의 데이터 타입을 바꿔 모델의 크기를 줄이는 양자화를 활용합니다.
| 학습 내용 미리보기
• 여러 개의 어댑터를 전략적으로 정리하여 추론하기
이론만으로는 아쉽죠?
배운 이론을 통해 실습을 진행합니다.
실습 미리보기
실제 vLLM을 활용한 실습을 통해
상황에 따른 전략 채택 및 실제 추론 최적화를 경험합니다.

양자화 모델 추론 전략 vLLM 구현 실습
허깅페이스에서 양자화된 오픈 모델을 가져온 뒤 이를 vLLM을 활용하여 성능을 높인 후추론에 사용합니다.

LoRA 어댑터 추론 실습
모델과 어댑터를 합쳐서 함께 추론할 때 효율적으로 사용할 수 있는 연산을 통해 빠른 속도를 구현하는 것을 vLLM을 활용하여 직접 서빙해보면서 속도를 확인합니다.
양자화 모델 추론 전략 vLLM 구현 실습
허깅페이스에서 양자화된 오픈 모델을 가져온 뒤 이를 vLLM을 활용하여 성능을 높인 후추론에 사용합니다.
LoRA 어댑터 추론 실습
모델과 어댑터를 합쳐서 함께 추론할 때 효율적으로 사용할 수 있는 연산을 통해 빠른 속도를 구현하는 것을 vLLM을 활용하여 직접 서빙해보면서 속도를 확인합니다.
LoRA 어댑터 추론 실습
모델과 어댑터를 합쳐서 함께 추론할 때 효율적으로 사용할 수 있는 연산을 통해 빠른 속도를 구현하는 것을 vLLM을 활용하여 직접 서빙해보면서 속도를 확인합니다.

Speculative Decoding 활용 실습
메두사 프레임워크를 사용하여 효과적으로 추론속도가 높아진 것을 vLLM을 활용하여 직접 서빙해보면서 확인합니다.

Automatic Prefix Caching 실습
KV 캐시 활용 전략 중 하나인 Prefix 캐싱 기법을 사용하여 효과적으로 추론속도가 높아진 것을 vLLM을 활용하여 직접 서빙해보면서 확인합니다.
Speculative Decoding 활용 실습
메두사 프레임워크를 사용하여 효과적으로 추론속도가 높아진 것을 vLLM을 활용하여 직접 서빙해보면서 확인합니다.
Automatic Prefix Caching 실습
KV 캐시 활용 전략 중 하나인 Prefix 캐싱 기법을 사용하여 효과적으로 추론속도가 높아진 것을 vLLM을 활용하여 직접 서빙해보면서 확인합니다.
Automatic Prefix Caching 실습
KV 캐시 활용 전략 중 하나인 Prefix 캐싱 기법을 사용하여 효과적으로 추론속도가 높아진 것을 vLLM을 활용하여 직접 서빙해보면서 확인합니다.
vLLM 사용법 따로, 최적화 전략 따로?
vLLM으로 각 전략을 직접 구현하며 유기적인 학습을 완성합니다.
BENEFIT
혜택이 이것만 있다면 아쉬우니까!

Fast campus ONLY
지금 강의 구매하고
따끈따끈한 서빙 프레임워크 발전 트렌드까지 다 가져가세요!
Point 1.
다른 프레임워크들과 vLLM을 비교하며 빠르게 성장하고
있는 서빙 프레임워크들의 트렌드를 톺아보세요!

Point 2.
vLLM 경쟁자 SGLang의 활용법까지 익히고 자신의
환경에 알맞은 서빙프레임워크를 채택하세요!
* 24년 말까지 업데이트된 내용을 담은 담은 강의가 25년 1월 6일에 영상 형태로 제공됩니다.

Benefit 1
허정준님이 직접 답변해주시는 게시판에서
LLM 서빙에 대한 모든 궁금증 해소!
LLM 서빙에 대한 모든 궁금증 해소!
∙ 실습 중 궁금한 사항은? 강사님님에게 직접 질의응답하세요.
* 질의응답 게시판을 24년 11월 4일부터 26년 10월 6일까지 운영됩니다.

Benefit 2
이 강의를 따라갈 수 있을까?
걱정하지 마세요.
강의에 사용된 모든 실습 코드를 드립니다.
걱정하지 마세요.
강의에 사용된 모든 실습 코드를 드립니다.
∙ 강의에 사용된 모든 실습 코드 : 꾸준히 업데이트 될 실습코드로 따라 치며 사전 지식이 없어도 편하게 실습하고 학습하세요.

커리큘럼
파트 8개클립 56개
- Part 1. 강의 준비하기6 클립
- Part 2. LLM과 GPU6 클립
- Part 3. LLM 추론과 최적화 기법 알아보기16 클립
- Part 4. 양자화와 LLM 추론6 클립
- Part 5. 미세조정과 추론5 클립
- Part 6. 추론 프레임워크 비교하기3 클립
- Part 7. vLLM10 클립
- Part 8.vLLM 배포하기(with 도커)4 클립
커뮤니티
수강생들은 어떤 질문을 하고, 어떤 이야기를 나누고 있을까요?
패스트캠퍼스 커뮤니티에서 다른 수강생들과 함께 궁금했던 주제에 대해 다양한 관점과 답변을 찾아보세요.
커뮤니티 바로가기학습 규정 및 환불 규정
학습 규정
* 본 상품은 동영상 형태의 강의를 수강하는 상품입니다.
* 상황에 따라 사전 공지 없이 할인이 조기 마감되거나 연장될 수 있습니다.
* 해당 강의는 사전 예약 상품으로, 강의 영상이 공개 일정에 따라 순차적으로 제작되어 오픈됩니다.
* 수강 신청 및 결제를 완료하시면, 마이페이지를 통해 바로 수강이 가능합니다.
총 학습기간:
정상 수강기간(유료 수강기간) 최초 30일, 무료 수강 기간은 31일 일차 이후로 무제한이며, 유료 수강기간과 무료 수강기간 모두 동일하게 시청 가능합니다.
본 패키지는 약 8시간 분량으로, 일 1시간 내외의 학습 시간을 통해 정상 수강 기간(=유료 수강 기간) 내에 모두 수강이 가능합니다.
수강시작일: 수강 시작일은 결제일로부터 기간이 산정되며, 결제를 완료하시면 마이페이지를 통해 바로 수강이 가능합니다. (사전 예약 강의는 1차 강의 오픈일)
패스트캠퍼스의 사정으로 수강시작이 늦어진 경우에는 해당 일정 만큼 수강 시작일이 연기됩니다.
일부 강의는 아직 모든 영상이 공개되지 않았습니다. 각 상세페이지 하단에 공개 일정이 안내되어 있습니다.
주의 사항
상황에 따라 사전 공지 없이 할인이 조기 마감되거나 연장될 수 있습니다.
천재지변, 폐업 등 서비스 중단이 불가피한 상황에는 서비스가 종료될 수 있습니다.
본 상품은 기수강생 할인, VIP CLUB 제도 (구 프리미엄 멤버십), 기타 할인 이벤트 적용이 불가할 수 있습니다.
커리큘럼은 제작 과정에서 일부 추가, 삭제 및 변경될 수 있습니다.
쿠폰 적용이나 프로모션 등으로 인해 5만원 이하의 금액으로 강의를 결제할 경우, 할부가 적용되지 않습니다.
환불 규정
환불금액은 정가가 아닌 실제 결제금액을 기준으로 계산됩니다.
쿠폰을 사용하여 강의를 결제하신 후 취소/환불 시 쿠폰은 복구되지 않습니다.
수강시작 후 7일 이내, 100% 환불 가능합니다. (단, 수강하셨다면 수강 분량만큼 차감)
수강시작 후 7일 이내, 1강 이상 수강 시 전체 강의에서 수강한 강의의 비율에 해당하는 수강료를 차감 후 환불 가능합니다.
수강시작 후 7일 초과 시 정상 수강기간 대비 잔여일에 대해 아래 환불규정에 따라 환불 가능합니다.
환불요청일 시 기준
: 수강시작 후 1/3 경과 전, 실 결제금액의 2/3에 해당하는 금액 환불
: 수강시작 후 1/2 경과 전, 실 결제금액의 1/2에 해당하는 금액 환불
: 수강시작 후 1/2 경과 후, 환불 금액 없음
* 보다 자세한 환불 규정은 홈페이지 취소/환불 정책에서 확인 가능합니다.
패스트캠퍼스 정책 안내
[패스트캠퍼스 아이디 공유 금지 정책]
패스트캠퍼스의 모든 온라인 강의에서는 1개의 아이디로 여러명이 공유하는 형태를 금지하고 있습니다.
동시접속에 대한 기록은 내부 시스템을 통해 자동으로 누적되며, 이후 서비스 이용이 제한될 수 있습니다.
[기기제한 정책]
패스트캠퍼스 온라인 강의 시청을 위해서는 ID별 최대 3개의 기기를 등록할 수 있으며, 기기 등록은 온라인 강의장 접속 시 자동 등록됩니다.
최대 갯수를 초과하였을 경우 등록된 기기 해제가 필요합니다.
[저작권 정책]
패스트캠퍼스의 모든 강의는 무단 배포 및 가공하는 행위, 캡쳐 및 녹화하여 공유하는 행위, 무단으로 판매하는 행위 등 일체의 저작권 침해 행위를 금지합니다.
부정 사용이 적발될 경우 저작권법 위반에 의한 법적인 제재를 받으실 수 있습니다.
국내 7개 카드사 12개월 무이자 할부 지원! (간편 결제 제외)