주요 경력
현) 당근
· 실시간 데이터 처리가 필요한 로컬 비즈니스 서버 개발
· POI 플랫폼 서버 개발
전) 네이버
· 데이터 실시간 처리 애플리케이션 서버 개발
· 네이버쇼핑 프론트엔드/백엔드 개발
· 쇼핑검색 서비스 설계
백엔드 개발자를 위한 Kafka 실습 0 to 1 : 입문부터 EDA까지
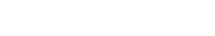
백엔드 개발자를 위한 Kafka 실습 0 to 1
: 입문부터 EDA까지

-
기본 정보

∙ 2개 대주제, 63여개 강의 클립 (약 17시간 분량)
∙ 사전 지식 : Java, Spring 기본 지식, DB 기본 지식, Docker 기본 지식 -
강의 특징
∙ 수강료 1회 결제로 평생 소장
∙ 부가 학습 자료 제공 -
영상 공개
∙ 전체 공개 : 2024년 06월 07일
백엔드 개발자를 위한 Kafka 실습 0 to 1 : 입문부터 EDA까지
실시간 데이터, 대용량 데이터를 처리해야 하는 기업를 필두로
채용 공고에서 Kafka 활용 능력이 급 부상!
백엔드 개발자들이 Kafka를 경험해야 하는 시대가 왔습니다.
BUT,
Kafka 실전 경험 기회조차 얻기 어려우시다면?




백엔드 개발자를 위한 Kafka, 이 강의로 끝내세요.


Kafka 이론학습을 넘어 이렇게 실전으로 체득시켜보는 과정을 거치시면 분명
백엔드 시스템을 보는 시야가 아예 달라지실 거예요.
Point 1
기초부터 탄탄하게!
17시간으로 끝내는
백엔드 개발자를 위한 kafka
Kafka가 처음이어도! 걸음마부터 실전투입까지 모두 가능한 커리큘럼

∙ Kafka 실행하기
∙ 토픽 생성하기
∙ 메시지 프로듀스하기
∙ 메시지 컨슘하기
∙ 11가지 Messaging Que 활용법
∙ Application 단에서 데이터 이관/복제
∙ Consumer 에러 핸들링
∙ 선착순 쿠폰 발행 시스템 서버 개발 및 대응
∙ 실시간 로그 파이프라인 구축
∙ 이벤트 기반 대규모 서버 구축
Basic
Kafka의 걸음마, Spring Boot 환경에서 Kafka 개발환경을 세팅부터 시작합니다.
백엔드 개발자 중에서도, Java+Spring을 다루는 분들이 실무에 바로 적용하실 수 있도록!
기본적으로 Spring Boot와 JDK 17 기준으로 프로젝트를 구성하고 Kafka를 사용할 수 있는 개발환경부터 세팅해봅니다.
 학습 내용
학습 내용
프레임워크와 각종 인프라 요소들을 Kafka와 연동하는 실습으로 Spring 환경 개발에 Kafka를 적용하는 방법을 배웁니다.
학습 내용
Kafka 내부 관리 도구들을 살펴보고 도구들로 Kafka 내 메시지를 발송하고 수신받는 기본 실습을 진행합니다.

Advanced
백엔드 개발자를 위한 Kafka 핵심, Messaging Que로 활용하는 11가지 활용법
 학습 내용 키워드 엿보기
학습 내용 키워드 엿보기
자동커밋과 수동커밋 중복 컨슘 Throughtput 늘리기 Batch Listener 늘리기 Dead Letter Topic 멱등성 보장 EOS Error Handler Partition Key 지정 애플리케이션 레벨의 CDC Retry
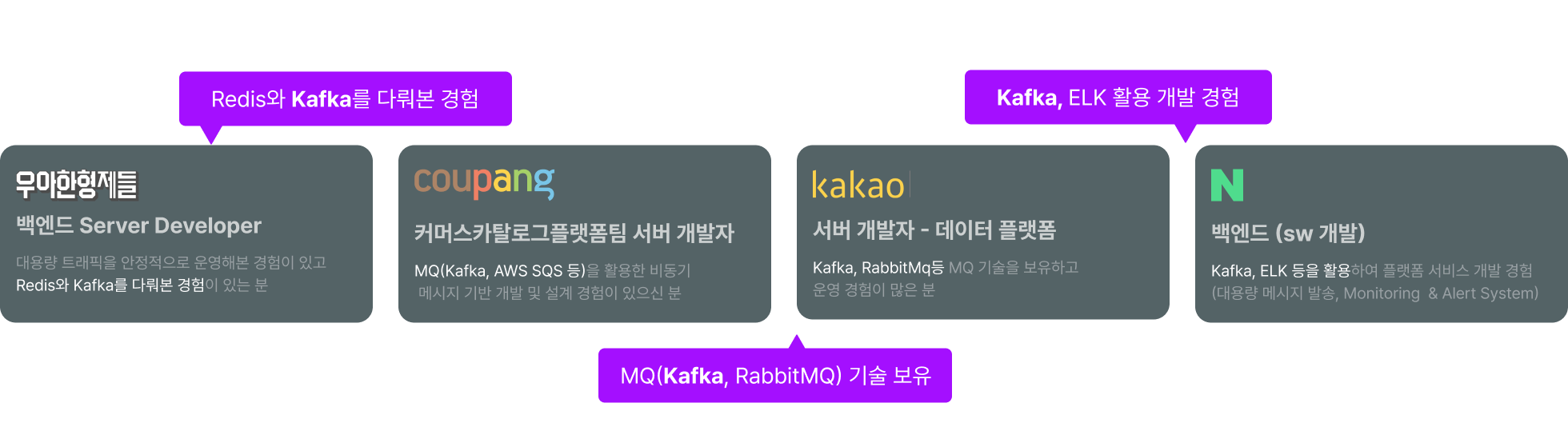
백엔드 개발자를 위한 Kafka 마스터를 위한 마지막 단계
총 3개의 프로젝트로 대표 Use Case 부터 EDA 기반의 플랫폼 구축까지 마스터하세요!
Point 2
실전에서 가장 많이 쓰이는 Kafka 활용법을
3가지 프로젝트로 경험하세요.
Kafka를 활용한 DB 부하 분산, 로그 적재 그리고 애플리케이션 연결까지
실무 수준의 Kafka 활용법을 경험할 수 있는 프로젝트로 설계했습니다.
가장 대표적인 2가지 Use Case별 프로젝트
부하분산 동시성
선착순 쿠폰 발행 이벤트 시 순간적으로 대량의 트래픽이 몰릴 때
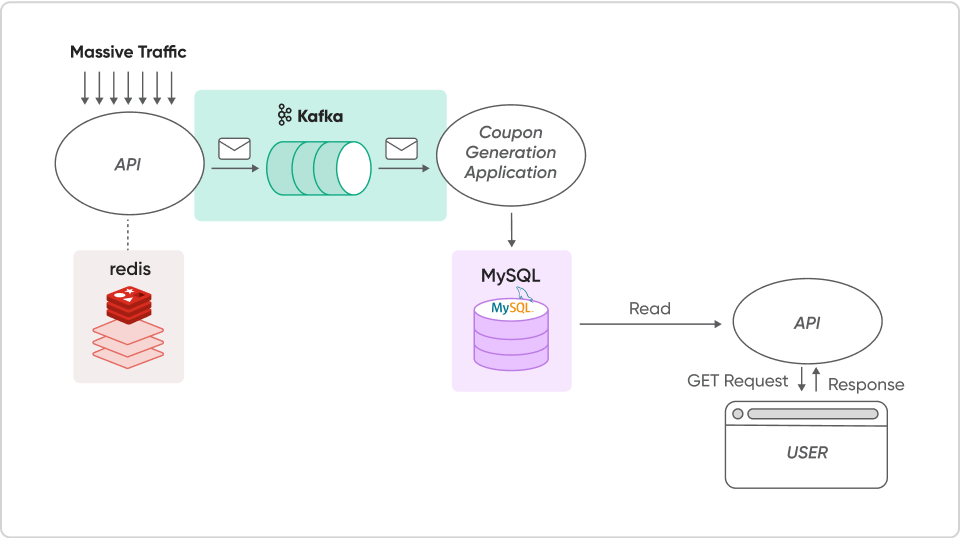
문제 상황
실제 백엔드 업무에서 꼭 한번 경험하는 트래픽 부하 문제, 동시성 문제
실습 내용
사용자들에게 빠르게 서빙 되어야 하는 데이터는 빠른 속도의 Redis로,
순차적으로 처리 해도 되는 데이터는 MySQL단에서 처리할 수 있도록
Kafka를 활용한 분산 처리를 수행합니다.
주요 스택

실제 백엔드 업무에서 꼭 한번 경험하는 트래픽 부하 문제, 동시성 문제
실습 내용
사용자들에게 빠르게 서빙 되어야 하는 데이터는 빠른 속도의 Redis로,
순차적으로 처리 해도 되는 데이터는 MySQL단에서 처리할 수 있도록
Kafka를 활용한 분산 처리를 수행합니다.
주요 스택
실시간 데이터 처리 로그 적재
실시간 로그 수집 파이프라인에서의 대량 데이터 처리
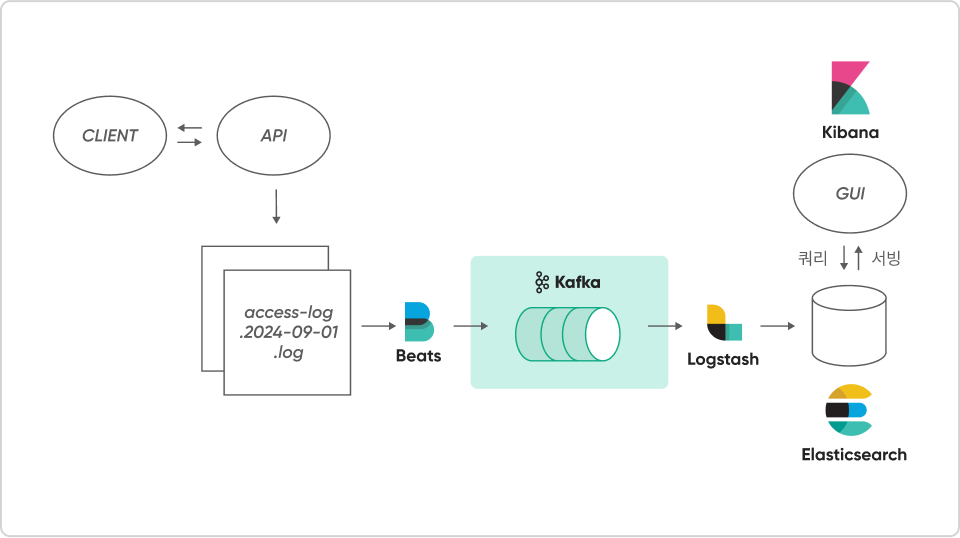
문제 상황
로그 수집 시 파이프라인이 많은 양을 빠르게 받아들일 때
데이터가 일부 유실되는 문제
실습 내용
로그 수집 파이프라인에 높은 신뢰성(고가용성)과 실시간성을 더할 수
있도록 Kafka를 메시징큐로 활용하여 로그를 적재합니다.
주요 스택

로그 수집 시 파이프라인이 많은 양을 빠르게 받아들일 때
데이터가 일부 유실되는 문제
실습 내용
로그 수집 파이프라인에 높은 신뢰성(고가용성)과 실시간성을 더할 수
있도록 Kafka를 메시징큐로 활용하여 로그를 적재합니다.
주요 스택
대용량 데이터 분산 및 처리를 위한 Kafka 중심 EDA 프로젝트
프로젝트 주제
Event Driven Architecture 형태로 콘텐츠 플랫폼 설계 및 구축
실습 내용
가장 먼저 데이터 저장, 구독, 캐싱, 색인 그리고 외부 API(ChatGPT) 연동까지 자연스럽게 흐르는 데이터 흐름을 설계하고,
각 요구사항에 따른 애플리케이션을 구축해나가며 Event Driven Architecture기반의 거대한 플랫폼을 완성합니다.
주요 스택

 1. 설계
1. 설계
요구사항을 정리하고 이에 따라 플랫폼 전체를 Kafka를 이용한 Event Driven Architecture 형태로 설계합니다.

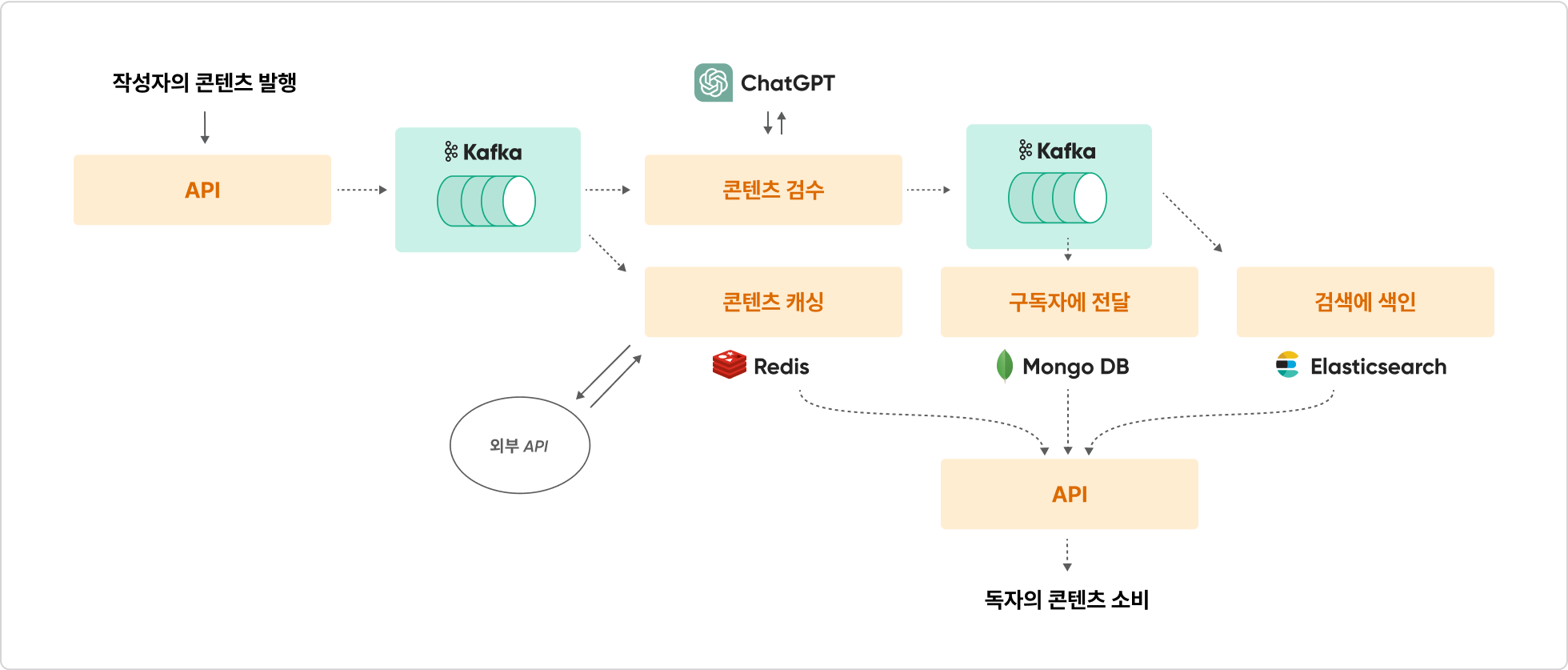
2. 요구사항에 필요한 인프라 요소를 Kafka로 각각 연결
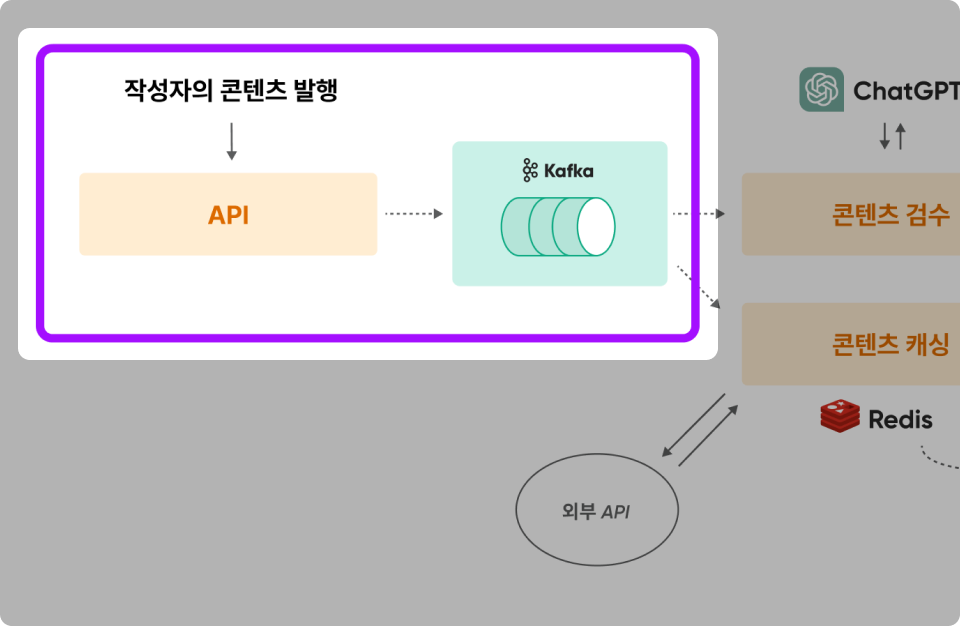
요구사항 1 : 유저는 콘텐츠(Post)를 발행할 수 있다.
Kafka 실습 내용
Kafka와 MySQL을 연결하여 콘텐츠 원천 데이터를 저장하고 Kafka로 Produce한다.
Kafka와 MySQL을 연결하여 콘텐츠 원천 데이터를 저장하고 Kafka로 Produce한다.
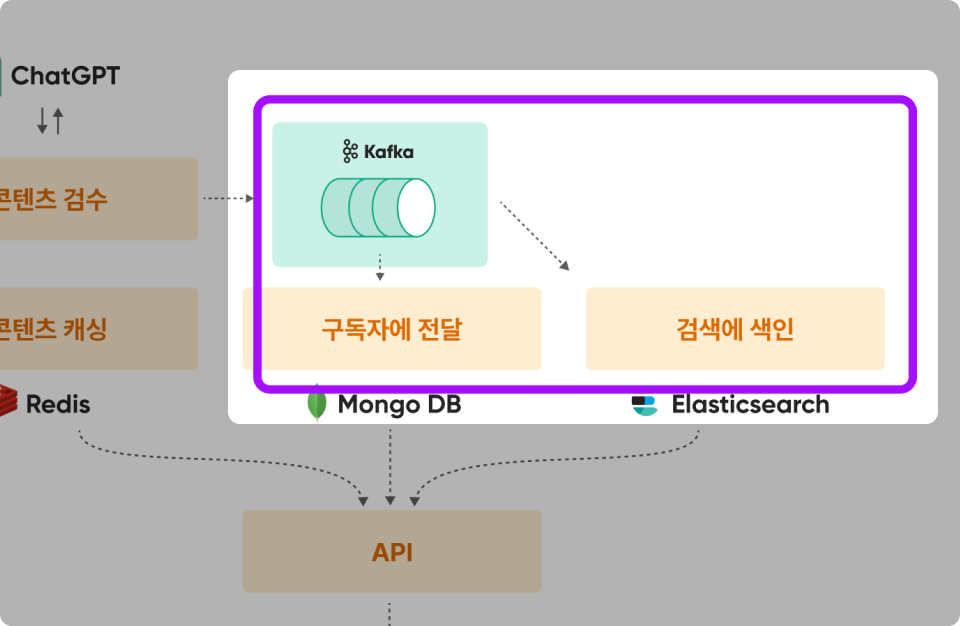
요구사항 2 : 유저는 다른 유저를 구독(Follow) 가능하며, 구독자는 콘텐츠를 받아볼 수 있다.
Kafka 실습 내용
Kafka와 MongoDB을 연결하여 유저별 구독 콘텐츠 조회 Use Case 작성하고 콘텐츠 구독 서비스를 만든다.
Kafka와 MongoDB을 연결하여 유저별 구독 콘텐츠 조회 Use Case 작성하고 콘텐츠 구독 서비스를 만든다.
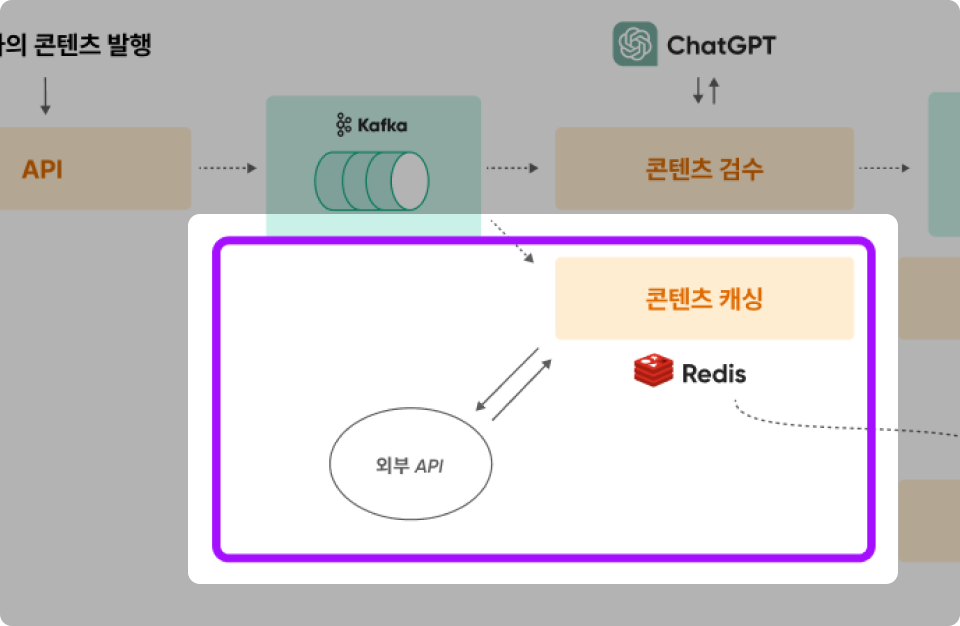
요구사항 3 : 소비자가 실시간으로 정보를 볼 수 있다.
Kafka 실습 내용
Kafka와 Redis를 연결하여 캐싱에 실시간성 부여하도록 Kafka를 통해 Cache로부터 Pipeline을 연결하고 컨텐츠 캐싱 전략을 개선한다.
Kafka와 Redis를 연결하여 캐싱에 실시간성 부여하도록 Kafka를 통해 Cache로부터 Pipeline을 연결하고 컨텐츠 캐싱 전략을 개선한다.
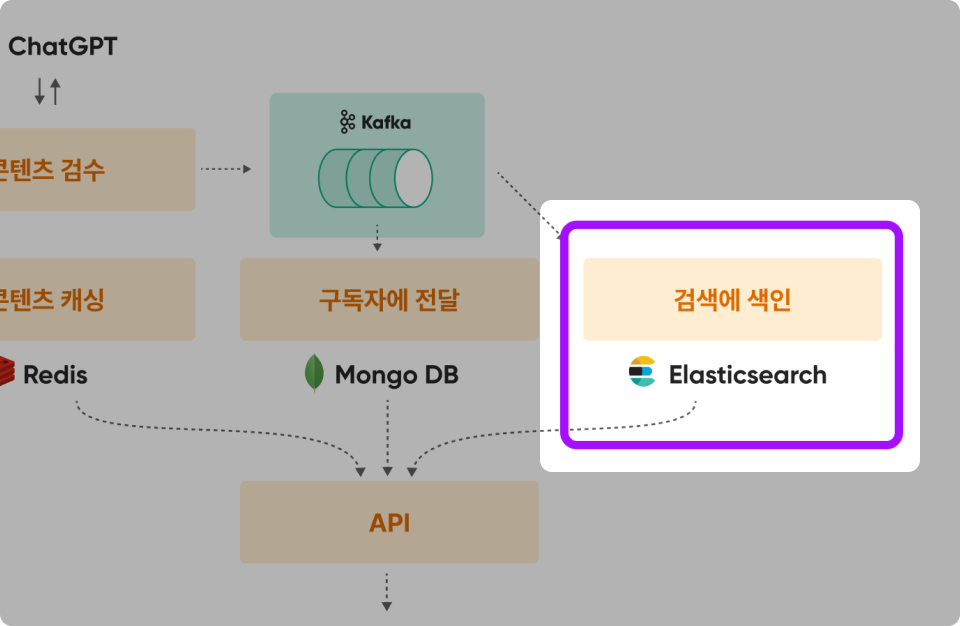
요구사항 4 : 검색(Search)를 통해 콘텐츠를 찾을 수 있다.
Kafka 실습 내용
Kafka와 ElasticSearch를 연결하여 콘텐츠 데이터를 실시간으로 검색시스템에 색인한다.
Kafka와 ElasticSearch를 연결하여 콘텐츠 데이터를 실시간으로 검색시스템에 색인한다.
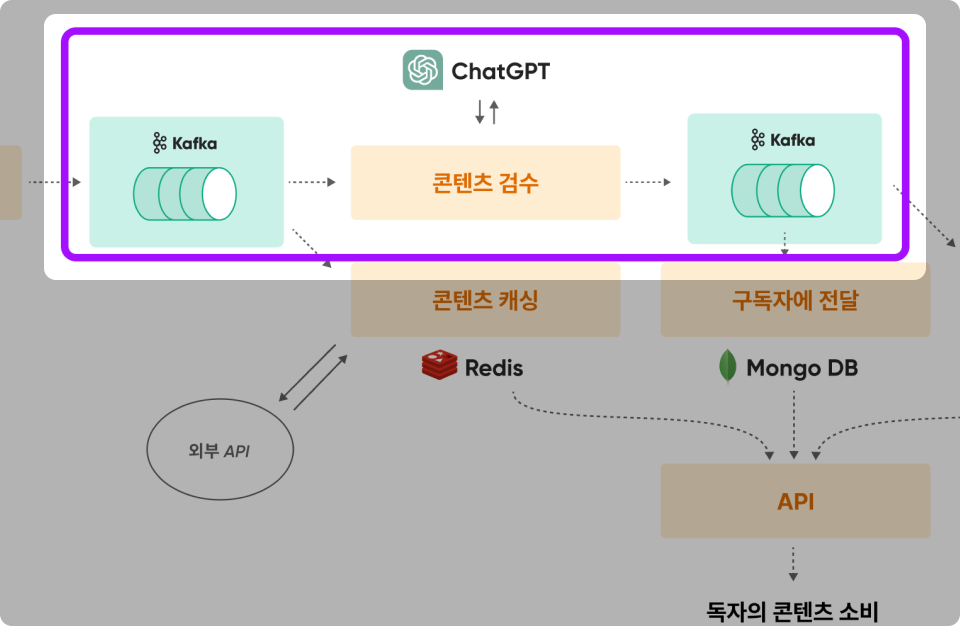
요구사항 5 : ChatGPT API 서버를 이용하여 콘텐츠를 자동으로 검수할 수 있다.
Kafka 실습 내용
외부 API인 ChatGPT 콘텐츠 자동검수 시스템을 만들고 Kafka로 다른 목적의 DB와 연결한다.
외부 API인 ChatGPT 콘텐츠 자동검수 시스템을 만들고 Kafka로 다른 목적의 DB와 연결한다.
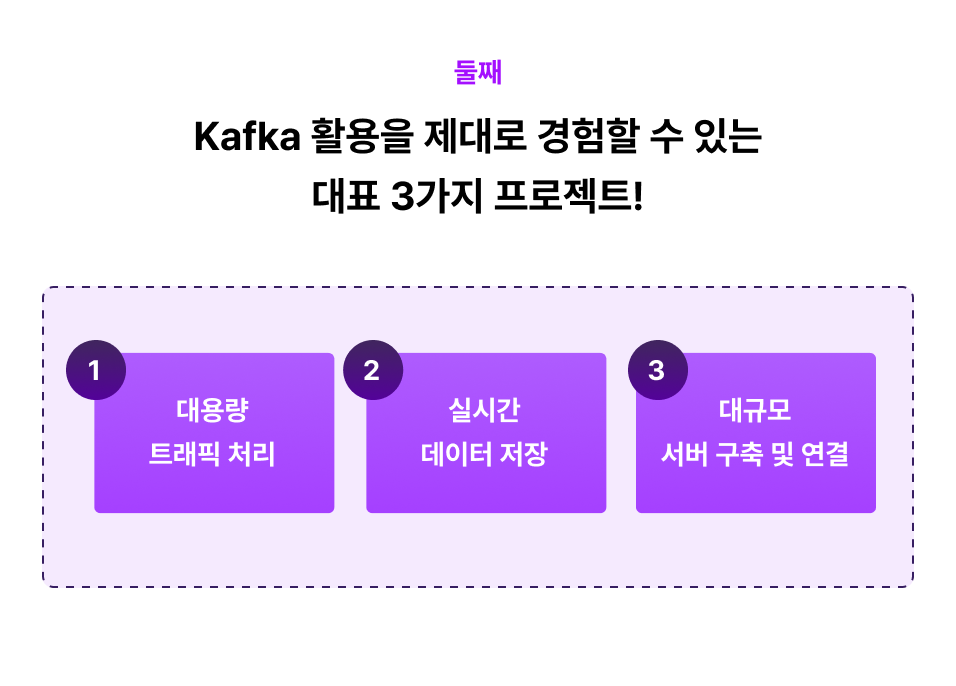
Point 3
백엔드 개발자가 실무에서 Kafka 활용할 때 가장 중요한
Producer / Consumer 심화 활용법까지!
다양한 요구 조건을 소화하기 위해서는 기본적인 사용법만 알아서는 안 되죠!
실무적인 능력을 키우기 위해 Kafka 메시지를 자유자재로 다루어보는 심화 활용법까지 준비했습니다.
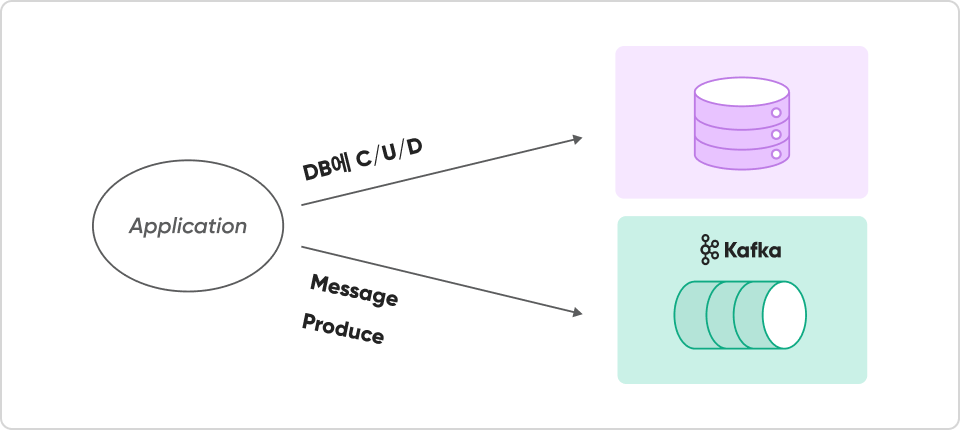
Producer 심화
알아서 데이터 변경사항을 전파하게끔
Producer 고급 구현하기!
알아서 데이터 변경사항을 전파하게끔
Producer 고급 구현하기!
|
Producer를 활용한 Application 단에서 데이터 자동 이관/복제
한번만 만들어두면, 손쉽게 데이터의 변경사항(C/U/D)을 Kafka로 연동할 수 있습니다!
Kafka Connect를 활용한 CDC 등 더 어려운 방법 없이도 간단히 메시지 발행을
자동화하세요!
한번만 만들어두면, 손쉽게 데이터의 변경사항(C/U/D)을 Kafka로 연동할 수 있습니다!
Kafka Connect를 활용한 CDC 등 더 어려운 방법 없이도 간단히 메시지 발행을
자동화하세요!
Consumer 심화
까다로운 Consumer 활용, 트러블슈팅 3가지

| Kafka Consume 시 자주 발생하는 예외를 3가지 실습으로 해결!
보통 실무에서는 Producer보단 Consumer를 다루면서 Exception을 자주 만나게 됩니다.
이 때 어떻게 극복해야할지 몰라 데이터 흐름의 병목이 될 수 있어 어려움을 겪는 경우가 많습니다.
Consumer 장애의 상황에 따라 데이터 병목에 대한 알맞은 대비 방안이 무엇인지 체득하세요.
이 파트를 들은 당신은
Kafka의 최대 효율을 끌어낼 수 있게 되고, 어려운 장애 상황을 쉽게 해결할 수 있게 됩니다.
Point 4
‘네이버쇼핑’, ‘당근’이라는 국내 최대 트래픽 규모의 서비스를 만들며,
대용량 데이터를 안정적으로 다루기 위해
Kafka를 실무 최전선에서 사용 중인 강사님과 함께!

Kafka 활용의 최전선 개발자
강사님 소개
‘네이버’, ‘당근’이라는 국내 최대 트래픽 규모의 서비스를 만들며, 데이터의 신규 구축부터 정제, 연동, 색인 등 백엔드 개발자로서 데이터를 서빙하기 위한 라이프 사이클 A to Z를 경험해왔고 그 과정에서 대용량 데이터를 안정적으로 다루기 위해 Kafka는 필수적인 기술이었습니다.
Kafka 이론학습을 넘어 이렇게 실전으로 체득시켜보는 과정을 거치시면 분명 백엔드 시스템을 보는 시야가 아예 달라지실 거예요.
Kafka를 처음 다루는 분들이더라도 실무에서 Kafka를 활용할 일이 생겼을 때 전혀 무리없이 사용하실 수 있게 될 것입니다. 이번 강의를 통해 다양한 형태의 유즈 케이스를 간접경험하고 실무에서 Kafka를 적극 활용해보세요!
Kafka 이론학습을 넘어 이렇게 실전으로 체득시켜보는 과정을 거치시면 분명 백엔드 시스템을 보는 시야가 아예 달라지실 거예요.
Kafka를 처음 다루는 분들이더라도 실무에서 Kafka를 활용할 일이 생겼을 때 전혀 무리없이 사용하실 수 있게 될 것입니다. 이번 강의를 통해 다양한 형태의 유즈 케이스를 간접경험하고 실무에서 Kafka를 적극 활용해보세요!
한현상 강사님
연사 및 강사 경험
[발표]
· NAVER 2022 Engineering Day - "피지(PGSQL) 해변의 카프카(Kafka) 몽고(MongoDB)로 가다"
[교육]
· NAVER 공채 신입사원 Soft Skill 교육 강사
· 한번에 끝내는 Kafka Ecosystem 강사
[발표]
· NAVER 2022 Engineering Day - "피지(PGSQL) 해변의 카프카(Kafka) 몽고(MongoDB)로 가다"
[교육]
· NAVER 공채 신입사원 Soft Skill 교육 강사
· 한번에 끝내는 Kafka Ecosystem 강사
이미 간증 폭발!
강사님 수강평 엿보기

끝나지 않았습니다.
실습에 필요한 쿠폰까지 전부 다! 드립니다.

Q&A
빠른 답변을 약속합니다!
언제든지 질문 가능한 질의응답 게시판에서 해결!
패스트캠퍼스 질의응답 게시판에서 강사님, 그리고 다른 수강생들과 함께 문제 해결!
더하여, 빠르게 답변을 받을 수 있도록 AI 캐미가 먼저 답변을 작성해드려요.
* 질의응답 게시판은 2024년 6월 7일부터 2027년 6월 2일까지 운영됩니다.
더하여, 빠르게 답변을 받을 수 있도록 AI 캐미가 먼저 답변을 작성해드려요.
* 질의응답 게시판은 2024년 6월 7일부터 2027년 6월 2일까지 운영됩니다.
커리큘럼
아래의 모든 강의를 초격차 패키지 하나로 모두 들을 수 있습니다.
지금 한 번만 결제하고 모든 강의를 평생 소장하세요!
* 본 강의는 [초격차 패키지 : 한번에 끝내는 Kafka Ecosystem] 의 일부인 part 2, 3 과 동일한 영상을 제공합니다.
Part1. 백엔드 개발자의 메시징큐
Part2. Event Driven Architecture 실습