
국내 1티어급 이커머스 플랫폼으로 배우는 대용량 데이터 처리 끝판왕
Advanced Backend Projects
미들 · 시니어 개발자로 거듭나기 위한 유일무이 프로젝트
프로덕트 시리즈 강의 묶음 PASS
시리즈 더 구경하기 →


국내 1위 쿠X은 전체 모바일 커머스 앱 사용자 중 79%를 점유*할 만큼 거대한 플랫폼입니다.
쿠X 급 규모
에서 발생하는
대용량 데이터 처리
천만 단위의 이용자와 십만 단위의 입점사를 감당하는
*초 거대 이커머스 비즈니스 라면 1TB 수준의 데이터를 처리할 수 있어야 합니다.

일반적인 프로젝트로는 절대 불가능한,
대용량 데이터를 끝판왕으로 처리할 수 있는 이커머스 도메인으로 시작해야 합니다.
이커머스에서 필요한 대용량 데이터 처리의 모든 것을 담얐습니다.
타 사 어디에서도 볼 수 없는 수준의 진.짜 대용량!
고성능/초고가용성 대용량 플랫폼 구축을 위한 5 Key Point
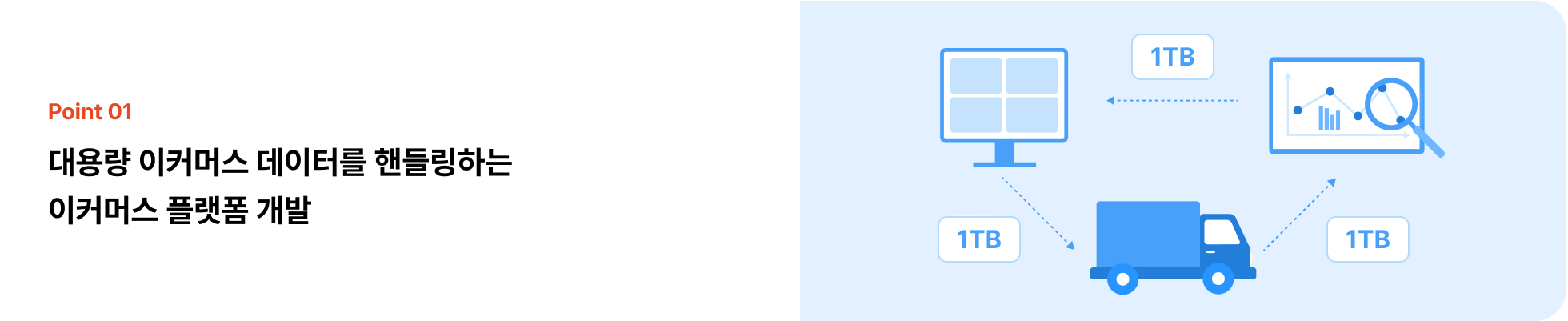



Point 1
국내 1위 이커머스 플랫폼, 쿠* 프로젝트로 정복하는
1TB 수준의 대용량 데이터가 흐르는 데이터 플랫폼 구축
상품 구매, 재고 처리, 실시간 가격 조정 등 커머스 핵심 기능부터 전체 대시보드 구축까지!
(프로젝트 + 프로젝트 + 프로젝트 ...) = 1개의 대규모 플랫폼을 개발하며, 대용량 데이터의 흐름까지 파악합니다.

여러 개의 프로젝트가 결합된 대규모 이커머스 플랫폼은 이렇게 개발합니다.




ㅣ 실시간 가격 조정 기능
구현 기능
∙ 상품 판매 데이터를 활용한 실시간 가격 조정 알고리즘
∙ 실시간 구매와 재고 수준을 Stream 형태로 받아 연산 처리
주요 데이터 소스
∙ 실시간 구매 이벤트 (구매 수량, 시간 등)
∙ 재고 수준
사용기술
∙ Apache Kafka: 실시간 구매 & 재고 스트림을 수집.
∙ Apache Flink: 실시간 데이터 처리 및 가격 조정 알고리즘 실행.
∙ Redis: 실시간 재고 수준 캐싱 및 빠른 데이터 접근.

ㅣ 결제 & 구매 기능
구현 기능
∙ 상품 데이터와 백엔드 API를 활용한 실시간 주문, 결제, 재고 업데이트 기능
∙ 주문 생성 및 관리
∙ 결제 처리
∙ 재고 업데이트
주요 데이터 소스
∙ 실시간 구매 이벤트
∙ 상품 데이터와 백엔드 API 요청
사용기술
∙ Apache Kafka: 실시간 데이터 스트림 플랫폼


ㅣ 실시간 가격 조정 기능
구현 기능
∙ 재고 관련 API와 상호작용하며 데이터를 캐싱하고 업데이트함.
∙ 상품이 주문될 때마다 재고 수준을 확인.
∙ 주문이 완료되면 재고 수준을 감소시키고, Redis에 업데이트.
∙ 재고 수준이 임계값 이하로 떨어지면 알림을 생성.
주요 데이터 소스
∙ 실시간 구매 이벤트 (구매 수량)
∙ 재고 데이터
사용기술
∙ Redis: 재고 데이터 캐싱 및 업데이트

ㅣ 결제 & 구매 기능
구현 기능
∙ 재고 관련 API와 상호작용하며 실시간으로 신규 발주 현황을 관리함.
∙ 재고 업데이트 이벤트 발생 시 발주 여부 확인
∙ 발주 필요시 발주 요청 이벤트 생성
주요 데이터 소스
∙ 상품 데이터와 백엔드 API 요청
∙ 재고 데이터
∙ 발주 관련 API
사용기술
∙ Apache Kafka: 발주 요청 및 상태 업데이트 처리
∙ Redis: 발주 데이터를 캐싱하고, 상태 데이터 조회&업데이트

ㅣ 실시간 가격 조정 기능
구현 기능
∙ 상품 판매 데이터를 활용한 상품 판매 리포트
∙ 필요한 판매 관련 데이터를 추출 및 변환하고, 필요한 계산을 수행.
∙ 정기적인 배치 작업으로 매출 리포트를 생성.
주요 데이터 소스
∙ 판매 이력 데이터
사용기술
∙ Apache Spark: 배치 처리를 위한 분산처리 엔진
∙ Apache Airflow: 정기적인 처리를 위한 워크플로우 관리

ㅣ 결제 & 구매 기능
구현 기능
∙ 상품 구매 후기 데이터를 활용한 상품 만족도 분석 기능
∙ 상품평 데이터를 벡터링하여 저장
∙ Full-Text 검색 및 집계 기능을 활용하여 긍정/부정 분석 진행
주요 데이터 소스
∙ 상품 구매 후기 데이터
사용기술
∙ Elasticsearch: 대규모 텍스트 데이터를 저장하고 검색하는 분산 검색 엔진


Point 2
고성능 & 고가용성 대용량 데이터 처리를 위한
필수 기술 스택 6가지 사용법을 실무 수준으로 학습합니다.
대용량 데이터 처리를 위한 실시간, 캐싱, 배치, 검색 최적화의 4가지 핵심 처리 방식을
실무 수준으로 사용할 수 있도록 꼼꼼하게 이론부터 실습까지 학습합니다.
Step 1
효율적인 대용량 데이터 처리를 위한 대표 개념 2가지와 맞춤 기술 스택 3가지를 실무 수준으로!
데이터가 생성되는 즉시 연속으로 처리하는
실시간 처리를 위한 Kafka & Flink
Kafka Stream이 있는데, Flink 꼭 배워야 할까요? 정답은 Yes! Kafka + Flink 조합법을 알아야 합니다!


Kafka로 수집한 실시간 데이터를 Flink로 집계하고 처리하며
실시간 데이터 처리 파이프라인 전체를 완벽하게 정복할 수 있습니다!
특정 시간 범위 내에서 대량의 데이터를 일괄 처리하는
배치 처리를 위한 Spark
Spring Batch 대신 꼭 Spark 를 써야 하나요? 물론이죠! Spark 는 진짜 대/용/량/ 데이터를 위한 기술스택이기 때문이죠!

Step 2
빠르고 정확한 기능 동작을 위한 모든 것! 서비스에 고성능 & 고가용성을 보장해 줄 심화 스택까지!
대용량 데이터 처리 시스템의 고성능을 보장하는
캐싱 전략을 위한 Redis
Spring Batch 대신 꼭 Spark 를 써야 하나요? 물론이죠! Spark 는 진짜 대/용/량/ 데이터를 위한 기술스택이기 때문이죠!


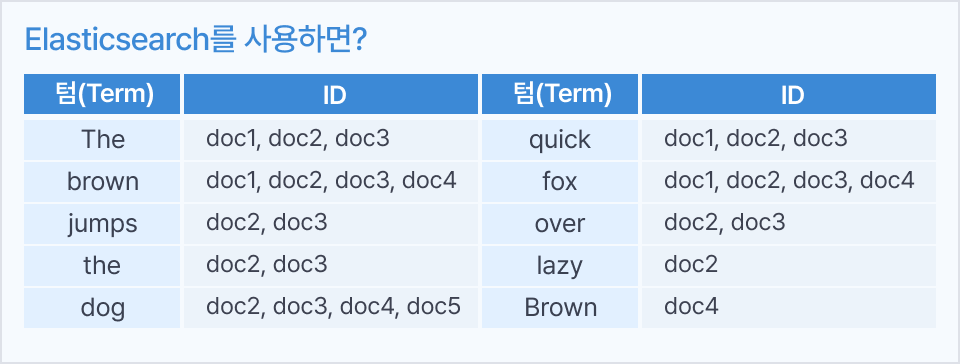
대용량 텍스트 데이터
조회, 검색, 가공 최적화를 위한 Elasticsearch
Elasticsearch로 검색 최적화를 구현하면 RDB로만 데이터 검색을 하는 것과는 차원이 다른 결과를 눈으로 보고 학습합니다.

Step 3
대규모 작업의 효율을 올려줄 대용량 데이터 처리 특화 툴로 생산성까지 UP!
대용량 데이터 처리를 위한 파이프라인
자동화 및 오케스트레이션 작업을 위한 Airflow
주문, 재고, 상품 가격 등 여러 데이터 파이프라인을 관리해야 하는 복잡한 플랫폼에 꼭 필요한 Airflow를 처음부터 실무 수준까지 학습합니다.


Point 3
DBA부터 백엔드, 데이터 플랫폼까지!
대용량 데이터 처리에 특화된 경험을 쌓아오신 현직 테크 리드에게 완벽하게 학습하세요!
국내 TOP 급 이커머스 플랫폼의 데이터 플랫폼 테크 리드이신 강사님께
백엔드 개발자의 대용량 데이터 처리를 위한 기술 스택부터 실무 노하우까지 얻어가실 수 있는 최고의 기회입니다!

안창현 강사님
안녕하세요. 강사 안창현입니다. 현재 백엔드 개발 및 데이터 플랫폼 엔지니어로 일하고 있습니다. 최근 들어 데이터 핸들링의 중요성이 점점 더 높아지며, 다양한 방법과 기술로 데이터를 추출하고 가공하는 것에 대한 수요도 높아지고 있습니다. 따라서 이번 강의에서는 왜 많은 양의 데이터가 발생되고, 어떤 것을 처리되어야 하는가를 먼저 이해할 수 있습니다. 이를 위해 실무에서 사용되는 다양한 툴과 기술들이 활용되는 사례들을 직접 실습해 볼 수 있도록 구성하였고. Data의 종류와 니즈에 따라 다양한 방식으로 처리하는 사례들을 경험해 볼 수 있습니다. 결국 여러분이 일하는 목적과 나오는 결과물들은 비즈니스를 위한 도구들입니다. 따라서 비즈니스를 명확하게 이해하지 않으면 왜 하고 있는지 얼마나 중요한지 쉽게 파악하기 어렵습니다. 꽤 긴 과정입니다. 모든 것을 순서대로 익히는 것이 가장 좋지만, 익숙하고 들어본 것 부터 접근하셔도 좋습니다. 각 항목간의 유기적인 관계는 마지막 실습에서 많이 다루게 되니 걱정하지 마세요.
Point 4
실무 현장에서는 이런 데이터를 다룹니다.
이커머스 비즈니스의 흐름부터 시작하는 탄탄한 도메인 지식
01
이커머스
비즈니스의 이해
이커머스 비즈니스에서 발생되는 가입부터 배송까지의 데이터 흐름을 이해합니다.
02
정형 데이터와
비정형 데이터의 이해
데이터의 유형과 각각의 특징을 이해하며 데이터 처리를 위한 사전 지식을 쌓습니다.
03
상품, 주문, 고객 데이터 모델링 방법
& RDB와 NoSQL 의 이용
각 도메인 별 발생하는 데이터를 이해하고 그에 맞는 DB형태를 선택하는 방법을 학습합니다.
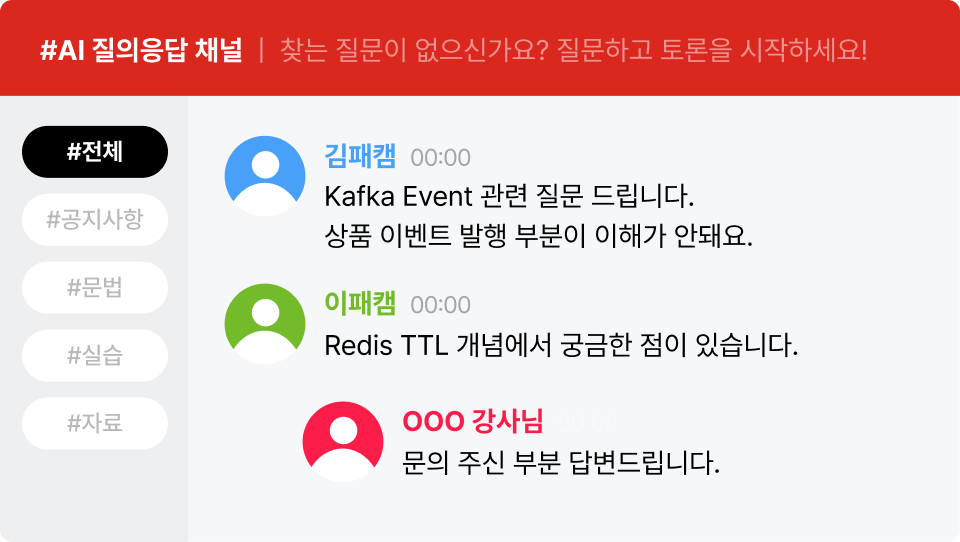
✓ 실습 중 에러가 나면? 질의응답 채널을 통해 빠른 해결 !
✓ 강의를 듣는 중 이해가 안가는 부분이 생기면 바로 질문하세요 !
* 본 채널은 2024.09.02~ 2027.9.02 동안 운영 됩니다.
* 강사님이 현업 중 답변하시기에 답변까지 영업일 기준 7일 내외 시간이 소요될 수 있습니다.
FAST CAMPUS
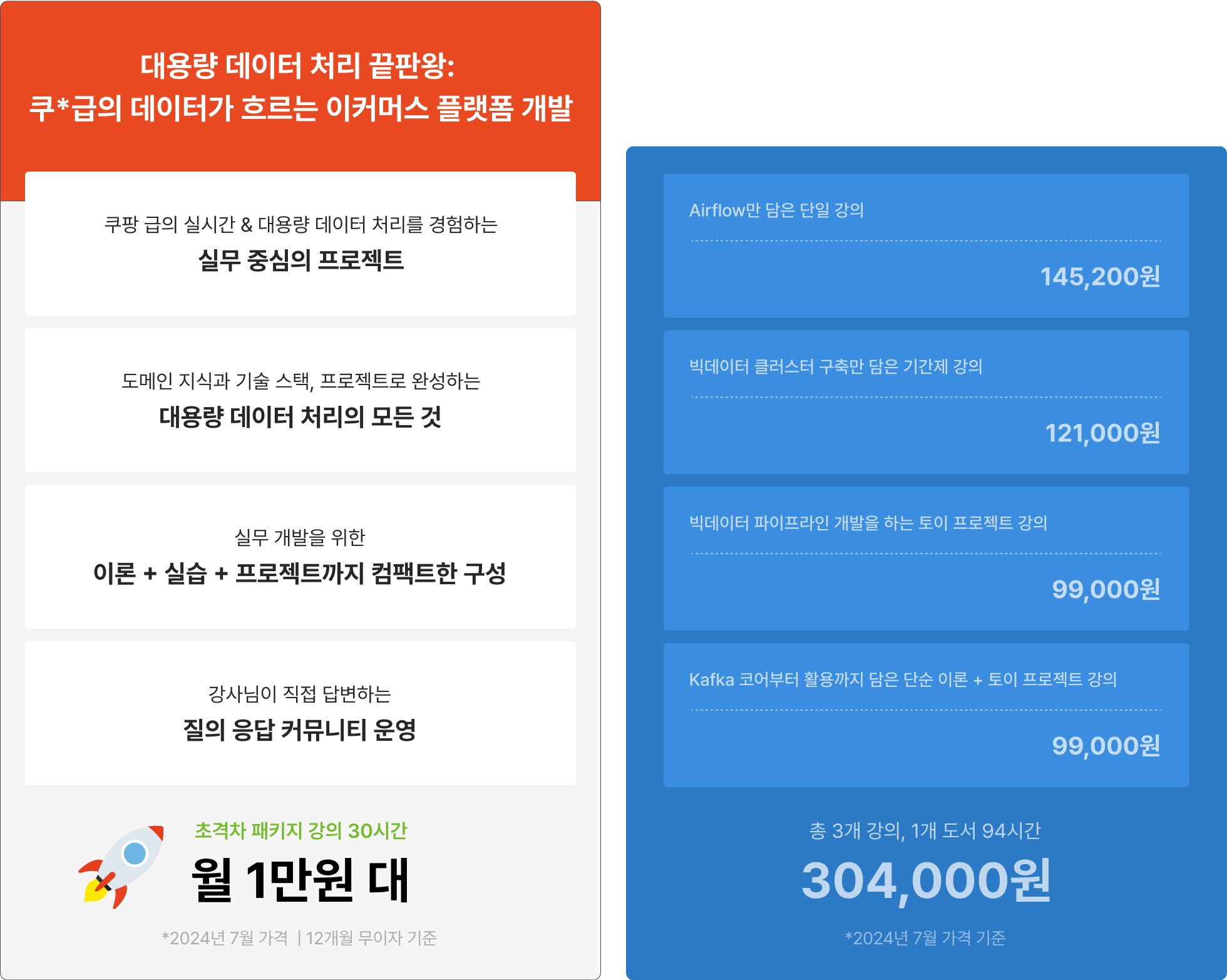
실무 프로젝트로 실시간 & 대용량 데이터 엔지니어링을 경험할 수 있는 끝판왕 강의!
이토록 알차게 담은 강의는 어디에서도 찾을 수 없어요!
추천 대상



