[미디어] 자연어처리 NLP, 현업에서는 이렇게 활용합니다.
자연어처리 NLP, 현업에서는 이렇게 활용합니다.
매년 빠르게 성장하며, 다양한분야에서 활용되고 있는 자연어처리 NLP 분야. 로봇, 금융, 의료, 번역, E-Commerce, 제조 등 산업에 관계 없이 딥러닝 기술이 자연어 처리 NLP 분야에 적용되고 있습니다. 이제 AI와 자연어처리는 뗄 수 없는 필수불가결한 요소입니다.
이러한 자연어처리 NLP 분야에 관심이 있는 분들이 흔히들 가지고 있는 고민과 다양한 문제들이 있었는데요.

현업에서 활용되고 있는 실제 알고리즘과 모델을 제대로 구현 해 본 경험이 없어요.
최신 기술과 모델 자료가 포함되어 있는 논문 내용을 이해하고 직접 프로젝트에 적용하는데 어려움이 많아요.
자연어처리에 대한 기초 지식은 있는데, 어떻게 응용하고 효과적으로 문제를 해결할 수 있을지 잘 모르겠어요.
위와 같은 고민에 기반하여, 현재 K사 엔터프라이즈에서 Natural Language Processing, Research Engineer 로 근무하고 있는 rung님과 L사에서 AI Engineer로 근무중인 이현정님을 만나서 이야기를 들어보았습니다.
먼저 현재 K사 엔터프라이즈에서 Natural Language Processing, Research Engineer 로 근무중인 rung님 먼저 만나보겠습니다.
Q1. 안녕하세요. 현재 구체적으로 어떤 업무를 하시는지 말씀 부탁 드리겠습니다.
자연어처리에서 대화를 처리하는 조직에 있습니다. 대화에서도 어떤 목적의 대화가 아닌, 오픈 도메인 대화를 처리하는 일을 담당합니다. 저는 이에 도움이되는 여러가지 서브 모듈들을 연구개발하고 있습니다.
Q2.K사 엔터프라이즈에서 근무하기 이전에는 LG Sciencepark와 LG CNS에서 근무하신 것으로 알고 있습니다. 혹시 이전에는 어떤 업무를 하셨는지 구체적으로 말씀 해 주실 수 있을까요?
두 회사에서도 자연어처리를 연구개발했습니다. 현재회사와 달리, 큰 주제를 가지고 연구개발을 한 것은 아니라서 다양한 테스크들을 시도했습니다. 그당시, 저는 서비스보다는 연구중심적으로 문제들을 접근했었고 문장유사도, 의도분류, 스타일변화 등의 다양한 테스크를 시도했었습니다.
Q3. 다양한 논문들에도 참여하신 것으로 알고 있는데요. 혹시 제일 기억에 남는 논문은 어떤 것이며, 특별히 기억에 남는 이유가 있으신지 말씀 부탁 드립니다.
CoMPM: Context Modeling with Speaker’s Pre-trained Memory Tracking for Emotion Recognition in Conversation입니다. 이 논문은 감정인식을 개발하다가 아이디어를 논문으로까지 출판한 것인데요. 영어데이터로 연구되는 방법론의 한계 등을 해결해서 한국어에서도 적용하기 위한 모델을 개발한 것입니다. 즉 서비스적인 관점, 연구적인 관점 모두 반영이 되었고 오랜 기간 작업했고 좋은 학회지에까지 출판되어서 기억에 남습니다.
Q4. 앞으로 자연어처리 NLP 분야가 얼마나, 어떠한 방향으로 발전할 것이라고 생각하실까요?
감정인식과 같은 경우는 공감대화 쪽으로 확장될 수 있습니다. 이미 많은 연구가 진행되고 있습니다. 감정인식 자체만으로도 다양한 어플리케이션으로 활용될 수 있는데요.
즉 서비스관점에서 human-like 로봇, 자동 콜텐서응답 등등 여러 분야로 활용될 가능성이 있다고 봅니다.
대화 응답선택은 꾸준히 관심받고 있고 앞으로도 대화시스템에서 빠질 수 없는 필수적인 모듈입니다. 최근 연구방향은 단순한 응답선택이 아닌, 커스터마이징, 페르소나, 지식기반의 응답선택이고요. 즉, 어떤 조건에 따라 응답이 달라지는 연구 분야로 점점 커지고 있습니다.
Q5. 자연어처리 NLP 분야와 관련하여 강사님께서 직접 얻으신 인사이트나 이 글을 보는 분들에게 조언의 한마디 부탁 드립니다.
많은 자연어처리 분야와 연구의 모델링은 다릅니다. 하지만 많은 분야의 모티브나 방법론은 은근히 비슷한 부분이 많습니다.
즉 다양한 프로젝트, 테스크들을 계속해서 경험하신다면 분명 다른 테스크지만 그로부터 인사이트를 얻을 수 있을 것이라 확신합니다.

이번에는 L사의 AI Engineer, 이현정님을 만나보겠습니다.
Q1. 안녕하세요. 현재 구체적으로 어떤 업무를 하시는지 말씀 부탁 드리겠습니다.
한국어 자연어처리 및 이해를 위한 연구 및 개발을 진행하고 있습니다. 주로 자사 서비스에 사용되는 기술을 개발하고 있으며, 미래에 사용될 기술에 대한 선행 연구도 수행하는 중입니다.
Q2앞으로 자연어처리 분야가 얼마나, 어떠한 방향으로 발전할 것이라고 생각하실까요?
아직까지 모든 영역에 대해서 잘 대답하고 요약하는 AI 모델은 없습니다. 특히 대부분의 모델은 공개된 wiki 데이터를 주로 사용하고 있기 때문에 금융, 제조와 같이 특수한 용어를 사용하는 경우에서는 실험할 때보다 성능이 한참 안 좋은 경우가 부지기수에요.
이러한 한계를 극복할 수 있는 일반화된 모델이 개발되는 것이 궁극적인 목적일 것 같습니다. 거기에 이왕이면 거의 fine tuning 하지 않고 few shot 혹은 zero shot 으로도 사용 가능한 성능을 내면 좋을 것 같아요.
Q3. 자연어처리 NLP 분야와 관련하여 강사님께서 직접 얻으신 인사이트나 이 글을 보는 분들에게 조언의 한마디 부탁 드립니다.
자연어처리에서 요약과 질의응답 테스크는 모두 사람으로 따지면 읽고 쓰는 행위에 해당한다고 할 수 있지요. 일종의 독해력으로 볼 수 있는데 사실 주위를 둘러봐도 여기에 뛰어난 인간조차 많지 않습니다.
2018년부터 시작된 엄청나게 큰 language model이 개발된 이후로 발전을 한 영역인만큼 아직까지는 해결해야할 문제가 너무나도 많습니다. 그렇기에 너무 부담을 가지시지 말고 걸음마부터 뗀다는 생각으로 편하게 임하셨으면 좋겠습니다.

rung님과 이현정님께서는 큰 부담없이, 자연어처리 NLP 분야와 관련하여 다양한 프로젝트와 테스크를 계속 경험한다면 인사이트를 얻을 수 있을 것이라는 말씀을 주셨는데요.
이와 관련하여 rung님과 이현정님 그리고 패스트캠퍼스가 함께 준비한 자연어처리 프로젝트에 대해서 더 깊이 이야기를 나누어 보겠습니다.
Q1. 먼저 rung님께 여쭤보겠습니다. 이번에 대화 속 감정인식, 멀티턴 응답선택 TASK. 이렇게 총 두가지의 프로젝트를 진행하시는 것으로 알고 있습니다. 이러한 프로젝트를 선택하신 이유가 있을까요?
두 프로젝트 모두 제가 회사에서 집중하는 테스크들이기 때문입니다. 따라서 다른 테스크들보다 백그라운드도 좀 더 아는 편이고 무엇보다 제가 직접 해봤던 부분이기 때문입니다.
또한 감정인식은 2022년에 논문 2편을 발표하는 좋은 레퍼런스가 있습니다. 멀티턴 대화선택 또한 공저자로 참여한 논문이 있고 최근에 논문을 발표 준비중에 있습니다.
Q2. 보통 사람들이 이 주제를 학습할 때 겪는 어려움이 무엇이며, 강의에서 진행 해 주시는 프로젝트가 어떤 사람들에게 도움이 될 것이라고 생각하실까요?
이 주제뿐만 아니라 대부분의 경우 학습 데이터의 구축의 문제가 있을 것입니다. 물론 요즘에는 기존보다 다양한 오픈 데이터가 있습니다. 하지만 그것만으로 서비스를 만들어내는데는 한계가 있고 결국에는 자기들만의 데이터가 필요합니다. 특히 멀티턴 대화응답 선택과 같은 경우는 상당히 방대한 데이터가 필요합니다.
또, 이 프로젝트들은 대화처리에 관심있는 분들에게 도움이 되지 않을까 생각합니다. 대화 시스템을 만들때 응답선택이란 방법을 이해함으로써 대화시스템의 구조를 이해하는데 도움이 될 것입니다. 감정인식은 좀 더 발전된 대화 시스템을 만드는데 활용되는 모듈입니다. 따라서 감정인식또한 공감대화생성 등의 관점에서 바라보면 대화 시스템과 연관이 있습니다.
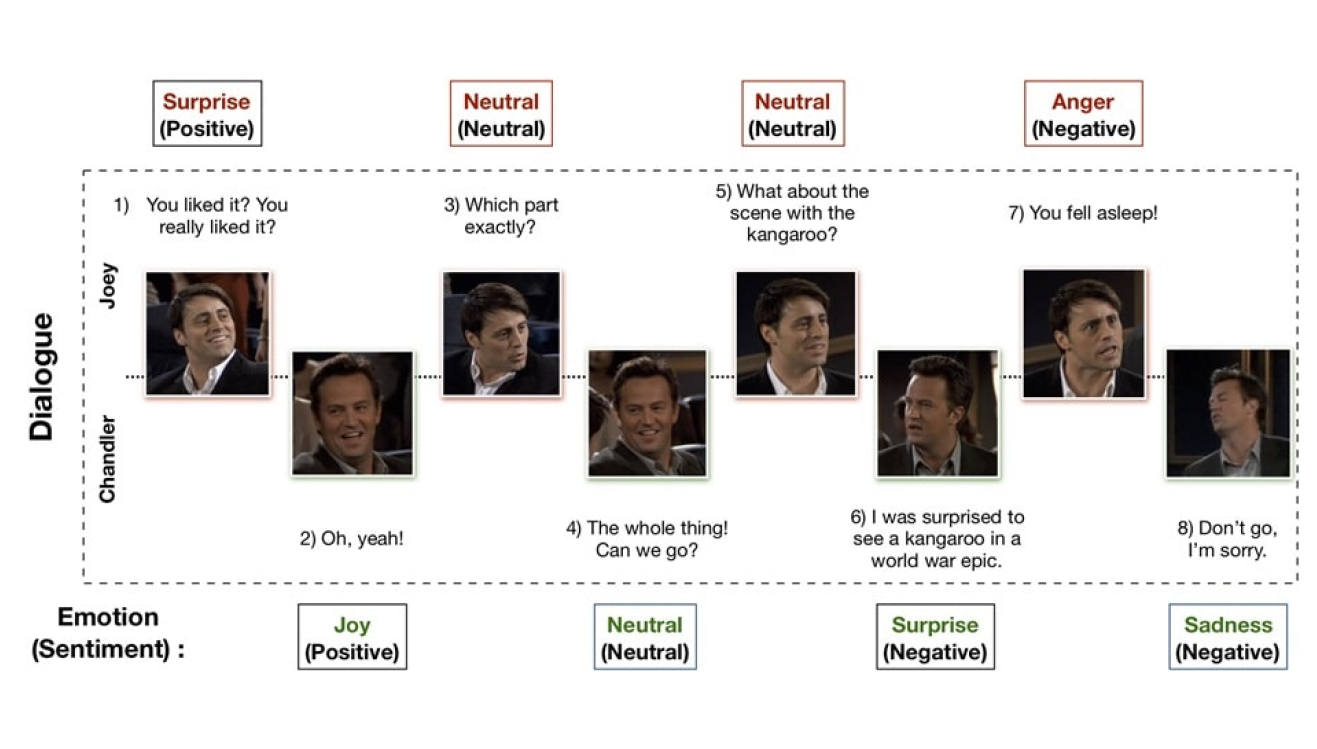
RoBERT 모델 활용한 대화속 감정인식 프로젝트
Q3. 이번에는 이현정님께 여쭤보겠습니다. 이번에 추출 요약, KorQuAD 데이터를 활용한 한국어 질의응답 TASK. 이렇게 총 두가지의 프로젝트를 진행하시는 것으로 알고 있습니다. 이러한 프로젝트를 선택하신 이유가 있을까요? 또, 현정님만의 장점이 있을까요?
개인적으로 요약 및 질의응답이 자연어이해에서 가장 어려운 과제들이라고 생각합니다. 그에 따라 회사에서도 꾸준히 몇년 간 연구, 개발을 해온 경험이 있어서 이 주제를 선택하게 되었습니다.
또, 다년 간 관련 프로젝트를 진행하면서 실제 scene에서 겪는 어려움과 디테일한 부분들을 직접 알려드릴 수 있는게 저의 장점이라고 생각합니다.
Q4. 보통, 사람들이 이 주제를 학습할 때 겪는 어려움이 무엇이며, 강의에서 진행 해 주시는 프로젝트가 어떤 사람들에게 도움이 될 것이라고 생각하실까요?
일단 요약, 질의응답 모두 사람에게도 어려운 과제라 이걸 수행하는 AI 모델을 구현하는 것 자체에 대해서 심적으로 부담이 될 수 있을 것 같습니다. 요즘 AI가 human performance를 넘었다고 광고하는 회사들이 많은데 그건 일반적인 주제에 대해 학습한 모델을 비슷한 데이터로 테스트했기 때문이라고 생각해요.
아직도 실상은 domain specific한 데이터에 대해서는 사람이 원하는 수준에 한참 못 미치는 경우가 많아요. 그러니 이 주제를 접하신 분들께서 너무 부담을 가지지 않으시고 맛볼 수 있도록 도와드릴 수 있을 것 같습니다.

KorQuAD 데이터셋 활용한 한국어 질의응답 모델 개발
지금 패캐머들이 읽고있는 BEST 아티클이 궁금하다면