[미디어] 빅데이터 엔지니어에 관심 있다면? 결코 피할 수 없는 Spark와 Hadoop
빅데이터 엔지니어에 관심 있다면? 결코 피할 수 없는 Spark와 Hadoop
0.1초마다 새 데이터가 쌓이는 빅데이터 시대
이제 실시간으로 빅데이터를 처리하고 활용합니다. 이렇게 빅데이터와 관련된 실무 데이터 엔지니어, 취업 준비생, 데이터 분석가, 데이터 분야 종사자들은 다들 공감하실 하기와 같은 페인포인트가 있으실텐데요.
1. "빅데이터분석과 분산처리의 핵심이라고 하는 Spark와 Hadoop은 배워도 끝이 없는 것 같다."
2. "지금까지는 파이썬으로 충분했는데, 데이터 처리량이 많아져서 로딩 시간이 오래 걸린다."
3. "지금은 주로 데이터 분석만 하고 있는데, 데이터 파이프라인 구축까지 기술을 확장하고 싶다."
4. "요즘 기업에서 빅데이터 분야 전문가에 대한 수요가 많다고 하는데,
실제로 실무 데이터분석가나 엔지니어는 어떤 일을 하는지 궁금하다."
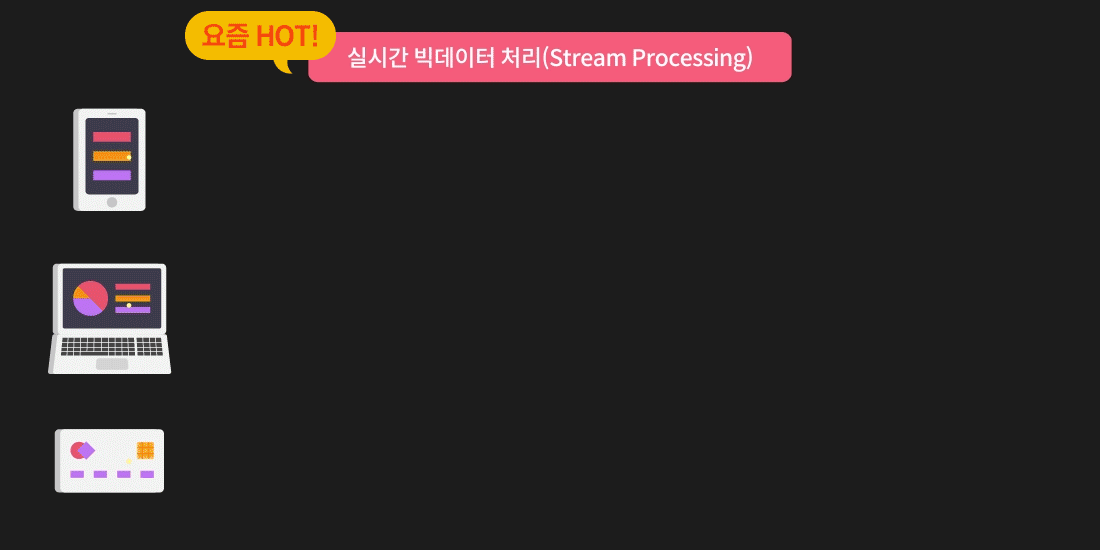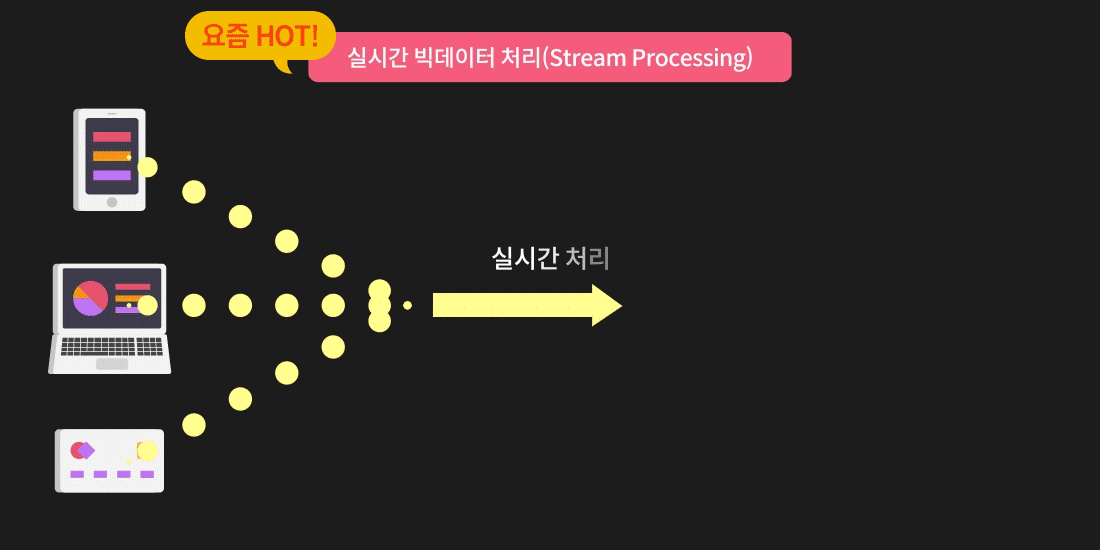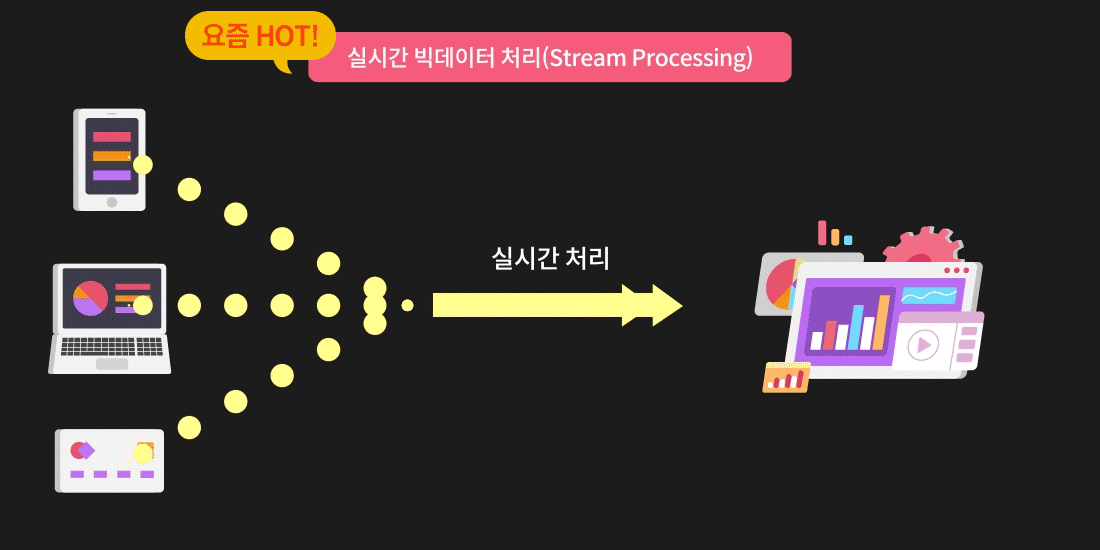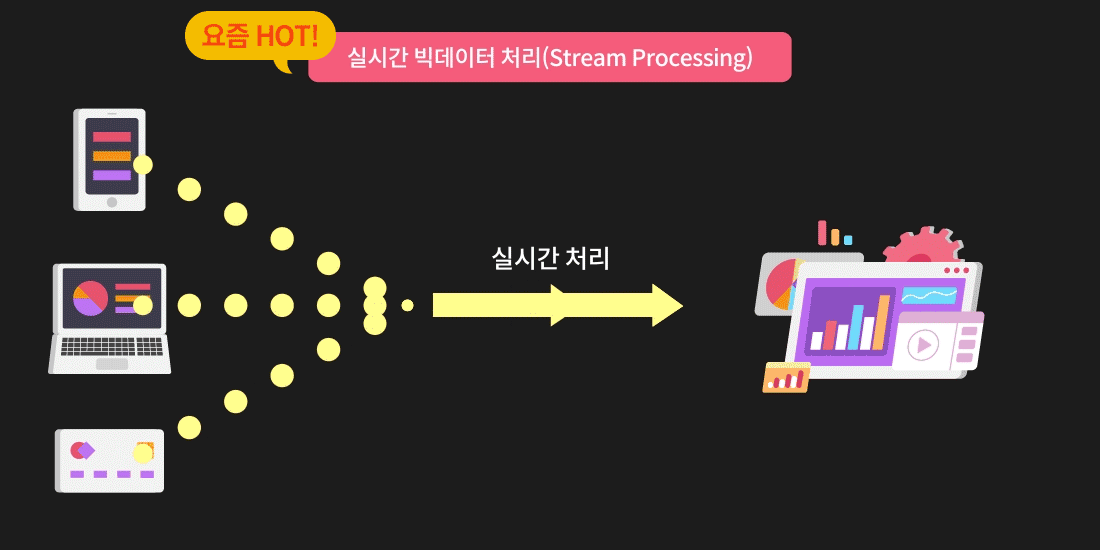
빅데이터 엔지니어가 되고 싶다면
이렇게 빅데이터를 처리하고 싶다면 Spark와 Hadoop이 필수인데요. 게다가 빅데이터 엔지니어 신입 및 경력 공고를 보면 Spark와 Hadoop을 강조하고 있다는 사실을 알 수 있습니다. 기업의 공고들은 하기와 같은 사항을 요구하고 있습니다.
1. 분산 처리 시스템(Spark, Hadoop) 활용 개발 경험
2. Hadoop ecosystem 이해
3. 데이터 환경(Spark, Presto/Hive, Spark Streaming 등) 을 활용한 데이터 입수/분석 경험
4. 대용량 분산 처리 시스템 (Hadoop 및 Spark 등) 을 통해 분산 처리 경험
실제로 어느정도 규모를 가진 데이터가 쌓이는 회사라면 Spark & Hadoop 사용하고 있어요. 현재는 사용하지 않더라도, 활용을 고려하고 있기도 하고요.
대체적으로 Spark & Hadoop은 최신 기술을 이해하는 엔지니어들이 있는 후기 스타트업이나 테크 기업들에서 많이 사용합니다. 머신러닝 기반 회사들에서도 백엔드에 많이 사용되고요.

Spark & Hadoop 필요한 이유
그렇다면 이 Spark & Hadoop 은 무엇이며 왜 필요한 것일까요? 데이터 엔지니어링의 표준이라고 부를 수 있는 Hadoop & Spark!
Hadoop은 상대적으로 저렴하고 셋업이 쉬우며, 데이터 웨어하우징에 최적화 된 솔루션이라고 볼 수 있어요. 다만 수직적인 확장만 가능하다는 단점이 있죠. 그렇기에 수평적인 확장으로 커버해주는 Spark가 필요한 것이고요. Spark를 활용하면 많은 양의 데이터를 빠르게 처리할 수 있어요.
좀 더 자세히 알아보면, Hadoop은 분산 환경의 병렬 처리 프레임워크로 크게 보면 분산 파일 시스템인 HDFS와 데이터 처리를 위한 맵리듀스 프레임워크로 구성되어 있습니다. 여러 대의 서버를 이용해서 하나의 클러스터를 구성하며, 이렇게 클러스터로 묶인 서버의 자원을 하나의 서버처럼 사용할 수 있는 클러스터 컴퓨팅 환경을 제공합니다.
Spark는 Hadoop과 유사한 클러스터 기반의 분산 기능을 제공하는 오픈소스 프레임워크입니다. 처리 결과를 항상 파일 시스템에 유지하는 Hadoop과는 달리, 메모리에 저장하고 관리할 수 있는 인 메모리 캐싱을 제공함으로써 속도가 빠르고 반복적인 데이터 처리에 뛰어난 성능을 보입니다.
이렇게 데이터를 한번에 많이 처리하기 위해 기업에서는 Spark & Hadoop을 활용하고 있는데요. 배치 프로세싱이나 스트림 프로세싱을 하려면 필요하고, 점점 쌓이는 데이터가 많아질수록 단순 스크립트로는 처리하기가 힘들어지기 때문입니다.
다른 프레임워크 대비 Spark & Hadoop 의 장점
Spark & Hadoop의 장점은 이들을 대체할 수 있는 프레임워크가 많이 없다는 점입니다.
AWS나 GCP 그리고 다른 서비스들이 제공하는 클라우드 서비스가 있다고 해도, 대부분 내부적으로 Spark와 Hadoop 기반이거나 사촌정도 되는 기술을 이용합니다.

Spark & Hadoop 이렇게 배우면 해결
이렇게 대체가 어려운 Spark & Hadoop. 함께 활용할 수 있다면 이점이 배가 되기 때문에, 한 번에 배울 수 있는 강의를 소개합니다.
1. 설치부터 기초 이론, 확장 라이브러리들까지 빠짐없이 모아놓았습니다.
2. 빅데이터 적재, 처리, 분석, 추천 머신러닝까지 실무 빅데이터처리 실습도 다 해 볼 수 있습니다.
(실습내용 : AWS에서 클러스터 환경 구성하기, Spark에서 SQL 사용하기, 트위터 데이터 실시간 수집/저장하기 ...)
3. 강사님 질의응답 케어로 다양한 꿀팁과 실무 이야기까지 공유할 수 있습니다.
총 100시간의 방대한 구성 중에 실습도 무려 60시간 차지!
더 자세한 내용은 아래 링크에서 확인하세요.

지금 패캐머들이 읽고있는 BEST 아티클이 궁금하다면