[미디어] YOLO v3 기반 사용자 데이터 라벨링, 훈련/객체 인식 기술 개발
YOLO v3 기반 사용자 데이터 라벨링, 훈련/객체 인식 기술 개발
“골치 아픈 밀린 자동차세 징수…AI 블랙박스가 체납 차량 찾아드립니다.”, “딥러닝 객체 알고리즘 개발하여 드론 기반의 생존자 수색 기술 개발”
이 모든 것들이 ‘YOLO’ 알고리즘을 통해 개발되었다는 사실 알고 계신가요?

[ 건설 객체 탐지 딥러닝 모델 결과 ]
이번 글에서는 YOLO v3 기반 시멘틱 객체 라벨링, 훈련 및 인식 기술 개발 방법을 간단히 다뤄보려 합니다. 참고로 YOLO v3는 이전 버전 욜로에 비해 정확도는 높아졌고, 속도는 다소 낮아졌는데요. 본 콘텐츠에서 YOLO를 이용해 다음과 같이 건설 객체를 인식할 수 있는 딥러닝 모델을 개발하는 방법을 알아보도록 하겠습니다!
* 본 콘텐츠는 다크넷 및 YOLO 개발 환경이 구축되었다고 가정하여 작성되었습니다.
YOLO 출력 구조 이해
YOLO의 예측 결과는 클래스 별로 예측된 경계박스(anchor box={cx, cy, width, height})입니다. 이 경계박스를 다음 그림과 같이 클래스별로 입력된 학습데이터에 맞게 조정해 학습모델을 만듭니다.
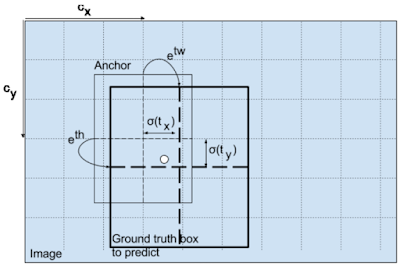
그러므로, YOLO의 학습 모델은 train data={image, {anchor box, label}*} 가 입력되고, 출력으로 output={anchor box, objectness score, class scores}* 가 되는데요. (*=multiple) 이는 이미지를 격자화해, 3개의 aspect ratio별 anchor box로 출력되며, 이 결과로 COCO 데이터셋 80개 클래스 경우 각 격자(cell)마다 depth 방향으로 (4 + 1 + 80) * 3 = 255 개 depth가 쌓이게 됩니다.
경계박스 정의
경계박스 정의 이미지 별 격자 크기는 13x13, 26x26, 52x52인 3가지 종류로 나뉩니다. 다음 그림은 이를 보여줍니다.
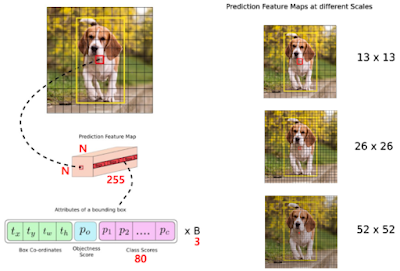
참고로, 기존 방법(SSD, R-CNN)은 정해진 ratio의 경계박스만 사용했습니다.
* YOLO v1: 98 boxes=7x7 cells. 2 boxes per cell. 448x448 pixels
* YOLO v2: 845 boxes=13x13 cells. 5 anchor boxes. 416x416 pixels
* YOLO v3: 10,647 boxes=((52x52) + (26x26) + (13x13)) x 3 (anchor box count). 416x416 pixels
모델구조 재활용
앞서 설명한 부분을 제외한 나머지 부분은 기존에 개발된 CNN(Convolutional Neural Network), FCN(Fully Convolutional Network), ResNet 등을 재활용합니다. 일반적으로 활용되는 ResNet은 네트워크의 깊은 깊이로 인한 gradient vanishing/exploding 문제로 Degradation되는 현상을 피하기 위해 개발된 것입니다. 만약, 신경망 학습목적이 입력 x를 목적값 y로 맵핑하는 함수 H(x)를 탐색하는 것이라면, 학습방향은 H(x) − y를 최소화하는 것입니다. ResNet에서는 관점을 바꿔 H(x) − x를 탐색하도록 수정합니다. 입출력 잔차를 F(x) = H(x) − x로 정의를 하고 학습은 이 F(x)를 탐색합니다. 이 F(x)가 잔차이므로, 이를 Residual learning, Residual mapping라 합니다. 계산 상으로는 단순히 F(x) + x를 한 것으로 그 전 레이어 값을 더하고 relu연산 적용한 것 뿐인데 이런 문제를 개선해 높은 성능을 얻었습니다.
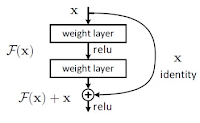
[ ResNet 핵심 구조(좌=기존. 우=ResNet) ]
Up-sampling은 저해상도에서 고해상도로 이미지 스케일 업할 때 사용되는데요. 이는 보간법과 유사한 방식으로, Transpose convolution, Deconvolution으로 불립니다.
최종 YOLO 모델 구조
이런 입출력을 고려해 CNN 레이어를 개발하면, 다음과 같은 YOLO 딥러닝 모델이 됩니다.
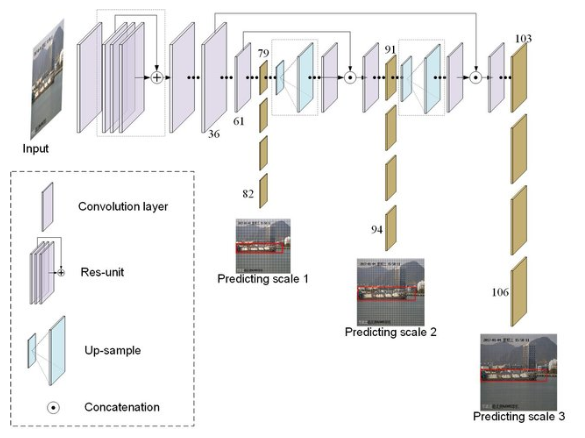
[ YOLO 딥러닝 모델 레이어 구조(Xin Nie 외, 2019) ]
이 결과로 다음과 같이 객체 세그먼테이션이 가능해지는 것이죠!

YOLO 실행 환경 테스트
YOLO가 제대로 설치되었다면 제대로 실행되는 지 테스트해보기 위해 COCO 데이터를 다운로드 받아 수정하고, 학습 작업을 하여 제대로 수행되는지 확인해보는 작업을 거칩니다. 제대로 수행되면, 다음 단계에서 YOLO v3 기반 예측 모델을 개발해 보도록 하겠습니다.
딥러닝 기반 예측 모델 개발 순서
딥러닝 모델을 학습하고, 이를 통해 사용자 데이터에서 객체 예측 모델을 개발하는 순서는 다음과 같습니다.
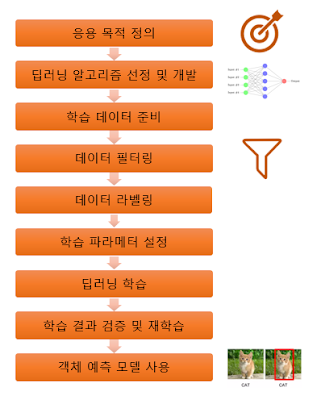
이 글에서 딥러닝 모델 사용 목적은 건설 객체 중 건설장비와 작업자를 인식하는 것입니다. 딥러닝 모델은 YOLO v3로 선정하였고, 전이학습을 사용합니다. 이후 과정은 다음과 같습니다.
학습 데이터 준비
딥러닝의 가장 큰 장애물은 학습 데이터를 준비하는 것입니다. 지금까지 딥러닝 연구자들의 많은 노력으로 수많은 딥러닝 모델이 이미 개발되어 있는데요. 이 것을 잘 활용하면 되는 좋은 모델이 많습니다. 하지만, 각자 응용 영역에 적용할 수 있는 데이터는 매우 제한되어 있는 것이 문제죠.
딥러닝에서는 데이터가 소스코드나 마찬가지이므로, 학습용 데이터 확보가 매우 중요합니다. 하지만, 학습 데이타를 만들기 위해서는 매우 노동집약적인 작업이 필요합니다. 참고로, DQN(Deep Q-Networks)와 같은 강화학습(reinforcement learning)을 사용할 수도 있는데요. 하지만, 강화학습은 일정 규칙을 추출할 수 있어 바둑과 같이 학습 데이터 생성을 예상할 수 있는 문제에서 적용이 가능한 방법입니다.
본 글에서는 학습 데이터를 건설 중장비 이미지를 준비해 봅니다. 그리고, CNN 기반 딥러닝 모델을 학습해 봅니다.
이미지 준비를 위해 구글에서 이미지를 다운로드하는 프로그램을 다음과 같이 설치하고, 실행한다. 이 작업을 위해서는 미리 아나콘다 개발 환경이 준비합니다.

[ 인터넷 이미지 자동 다운로드 결과 ]
이제 중복, 불필한 데이터 등을 삭제하는 등 필터링하고, 별도 학습용 폴더에 저장합니다. 저장 후에는 학습 데이터 파일명을 변경하고 데이터 크기를 조정합니다.
참고로, 이미지 데이터가 부족하여 학습 정확도에 문제가 생긴다면 imgaug를 활용해 데이터 파일을 증폭시킵니다. imgaug는 bounding box(바운딩 박스)를 유지한 상태로 데이터 파일을 증폭시킬 수 있습니다.
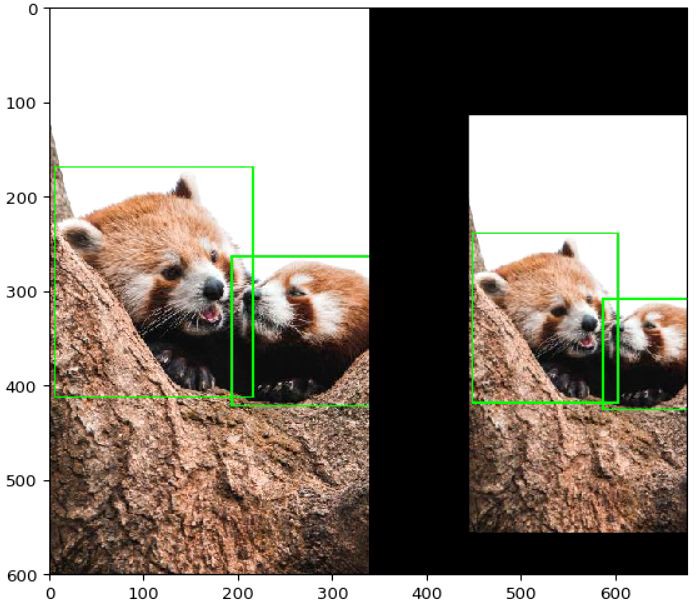
[ 이미지 증폭 결과 예 ]
이제, 데이터를 준비했으므로, 파일들은 다음과 같이 폴더로 분류해 놓습니다. 전체 100이라면, train에 70%, test에 10%, val에 20%을 할당합니다.
학습 데이터 라벨링
BBox Label Tool을 사용해 데이터 라벨링을 수행합니다.
이 도구를 이용해 각 이미지 별 경계 박스 설정 시 시간은 평균 1~10초 정도 걸리는데요. 한 장당 평균 2~5개의 경계박스를 선택해야 합니다. 실제, 미리 준비한 중장비 이미지 데이터는 446장이었고, 이 데이터는 라벨링에 약 50분 시간이 소요되었습니다. 이 경우, 라벨링 속도는 10장/분이고, 6초당 1장 라벨링 속도입니다. 참고로 이미지 별 클래스 개수와 라벨 난이도에 따라 이 시간은 크게 달라질 수 있습니다!

[ 중장비 라벨링 과정 ]
건설 작업자의 경우, 450장 라벨링하는 데, 60분이 소모되었습니다. 이는 7.5장/분 속도로 라벨링한 것인데요. 꽤 많은 수의 데이터임에도 불구하고, 다양한 각도와 거리에서 촬영한 이미지 데이터는 부족한 편입니다.

[ 작업자 라벨링 과정 ]
객체 대상에 따라 라벨링 작업 특성이 다를 수 있습니다. 예를 들어, 사람은 장비보다 겹치는 경우가 많은데요. 중장비의 경우 객체 대상을 본체만으로 하는 지, 부착장비까지로 하는 지에 따라 선택 범위가 달라집니다.
라벨 데이터 형식 변환 및 학습 파라메터 설정
이제 각 라벨 폴더 별로 라벨링 정보가 저장되어 있는 상태의 라벨 데이터 파일들을 darknet 형식으로 변환합니다.
사용자 데이터셋 딥러닝 학습
이제 사용자가 만든 데이터셋으로 YOLO를 학습해봅니다. 이를 위해 클래스와 관련된 부분의 욜로 학습 설정 파일을 수정해야하는데요. 데이터셋 크기가 1,000개 미만일 경우 전이학습(transfer learning) 기법을 사용합니다. 학습 전에 사전 학습된 모델 파일을 사용하면 학습분포가 많아지고, 학습시간도 단축됩니다. 이런 방법을 전이학습기법이라 합니다.
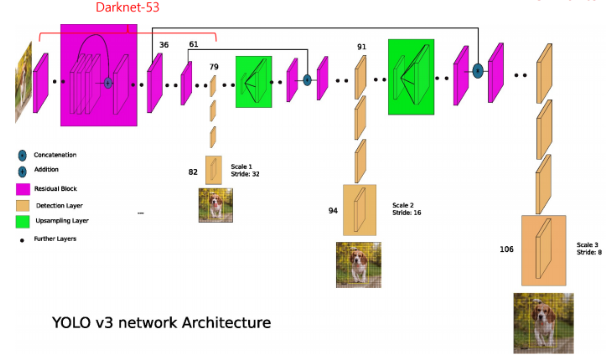
[ YOLO에서 전이학습에 사용된 Darknet53(Joseph Redmon 외, 2018) ]
전이학습은 새로운 모델로 학습할 때보다 이미지 분포가 더 크기 때문에 효율적 학습이 가능합니다. 전이학습은 풀고자 하는 문제와 비슷하면서 사이즈가 큰 데이터로 이미 학습이 되어 있는 모델인데요. 일반적으로, 큰 데이터셋으로 모델을 학습하는 것은 오랜 계산 시간과 연산량이 필요하므로, 보통 VGG, Inception, MobileNet 등 이미 잘 학습되어 있는 모델들을 가져와 사용합니다.
객체 예측모델 학습 결과 객체탐지 정확도 테스트
이제 학습이 끝났으면 테스트를 해보도록 합니다!

우선 비교를 위해 기존 yolov3.weight 모델로 예측해보면 좌측처럼 아무것도 인식되지 않지만, 학습된 모델 파일을 이용해 이미지를 예측해 보면 우측 이미지처럼 잘 예측됩니다!
각 객체의 탐지 정확도는 89%, 87%,78%로 높은 편입니다. 다른 이미지도 인식해 봅니다.

기존 yolov3.weight 모델로 인식한 결과는 다음과 같은데요. 객체 4개만 인식되고 1개는 오탐되었습니다. 잘 인식되지 않는 부분을 확인하였으니, 이를 보완해 모델을 개선해 봅니다. 개선된 모델을 이용해 객체를 인식하면 더 잘 탐색되는 것을 알 수 있습니다!
마무리
지금까지 사용자가 학습 데이터를 준비하고 학습 시켜야 할 때 YOLO에서 어떻게 작업하는 지 전체적인 프로세스를 알려드렸는데요! 기존 YOLO의 학습 모델로는 건설과 같이 특정한 분야에 대한 객체 인식은 제대로 되지 않는 것을 알 수 있었습니다. 이 경우 별도 학습 데이터를 준비해 딥러닝 훈련 시켜야 하죠. 학습 데이터가 부족한 경우, 정확도가 높아지지 않습니다. 이 사례에서는 학습 데이터가 많은 편은 아니지만 객체 인식에 큰 문제가 없는 수준으로 학습 데이터를 구축하고 훈련을 진행해서, 큰 문제 없이 테스트에서 건설 객체들이 학습되는 것을 확인할 수 있었습니다. 학습 데이터가 많아지고, 클래스 수가 높아질수록 데이터 준비 및 학습에 많은 노력과 시간이 들어가겠죠?
이렇게 학습된 커스텀 모델은 해당 분야 데이터에서만 유효한데요. 이를 고려해 딥러닝에 필요한 데이터셋, 학습모델 등을 활용해야 하겠습니다.
오늘 공유해드린 내용을 통해 빠르게 객체를 감지하는 알고리즘인 YOLO에 대해 인사이트를 얻어가는 시간이셨기를 바랍니다.
References
* YOLO v4 — Superior, Faster & More Accurate Object Detection
* YOLO darknet github
* Keras FCN
* DeepLab for Video
* YOLO v3 github
* Custom object training and detection with YOLOv3 (#2)
* How to train YOLO model
* Transfer learning from pre-trained models
* How to implement a YOLO v3 object detector
* Object Detection with Darknet (#2, #3, #4, #5)
* YOLO v2, YOLO9000
* YOLO Darknet v2
* OpenPose (#2)
* Google Images Download and Docs (Error solution)
* Prepare your own data set for image classification in Machine learning Python
* How to prepare Imagenet dataset for Image Classification
* Google Cloud, 학습 데이터 준비
* imgaug with bounding box
* Learn to Augment Images and Multiple Bounding Boxes for Deep Learning in 4 Steps
* CNN architecture - VGG, ResNet
* Xin NieMeifang YangWen LiuWen Liu, 2019, Deep Neural Network-Based Robust Ship Detection Under Different Weather Conditions, IEEE
* Joseph Redmon, Ali Farhadi, 2018, YOLOv3: An Incremental Improvement
* Train, Test, Validation dataset
출처
daddynkidsmakers님의 블로그 글을 동의 하에 업데이트 하였습니다.
[ YOLO v3 딥러닝모델 기반 사용자 데이터 라벨링, 훈련 및 객체인식 기술 개발방법 ]
지금 패캐머들이 읽고있는 BEST 아티클이 궁금하다면