[미디어] 데이터 엔지니어라면 꼭 알아야 하는 플링크, 스트림 프로세싱
데이터 엔지니어라면 꼭 알아야 할 플링크와(Flink)와 스트림 프로세싱(Stream Processing)

여러분이 예비 또는 현역 데이터 엔지니어라면,
스트림 프로세싱(Stream Processing)을 꼭 알아야 합니다
*데이터 엔지니어가 하는 일은?
조직 내 사업이나 서비스에 필요한 데이터를 잘 분석 및 활용할 수 있도록 데이터 시스템을 관리합니다. 빅데이터의 등장으로 데이터가 중요하게 되자 데이터 엔지니어링이 급부상하게 되었습니다.

그 이유는 카카*택시, Amazo* 등 수많은 기업들이 스트림 프로세싱을 실제 서비스에 적용하고 있기 때문입니다.
최근 실생활에서 가장 많이 접하는 서비스들에 구현된 기술이라니, 모르면 안 되겠죠?
그렇다면 스트림 프로세싱(Stream Processing)이란 무엇일까요?
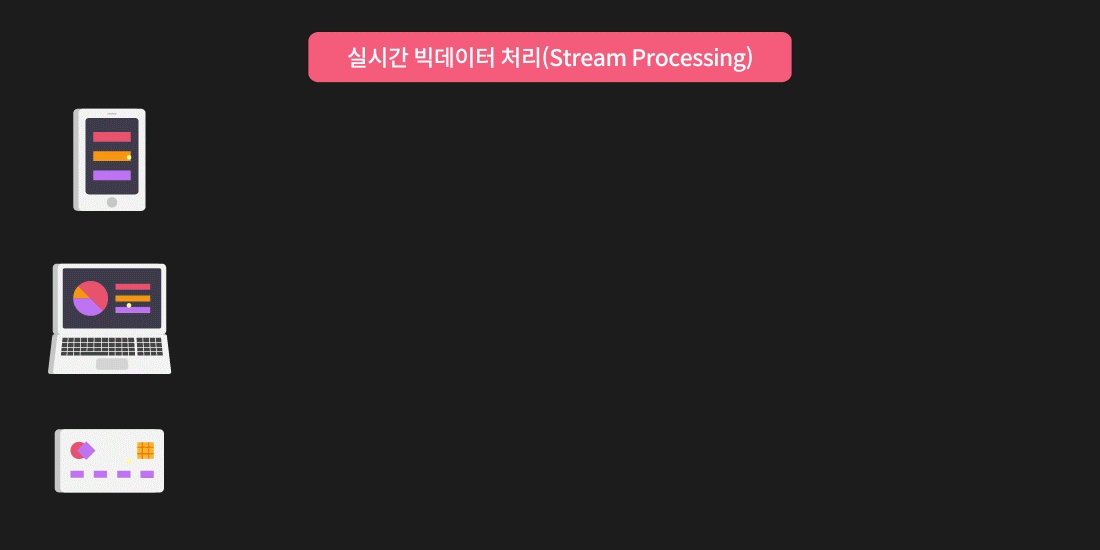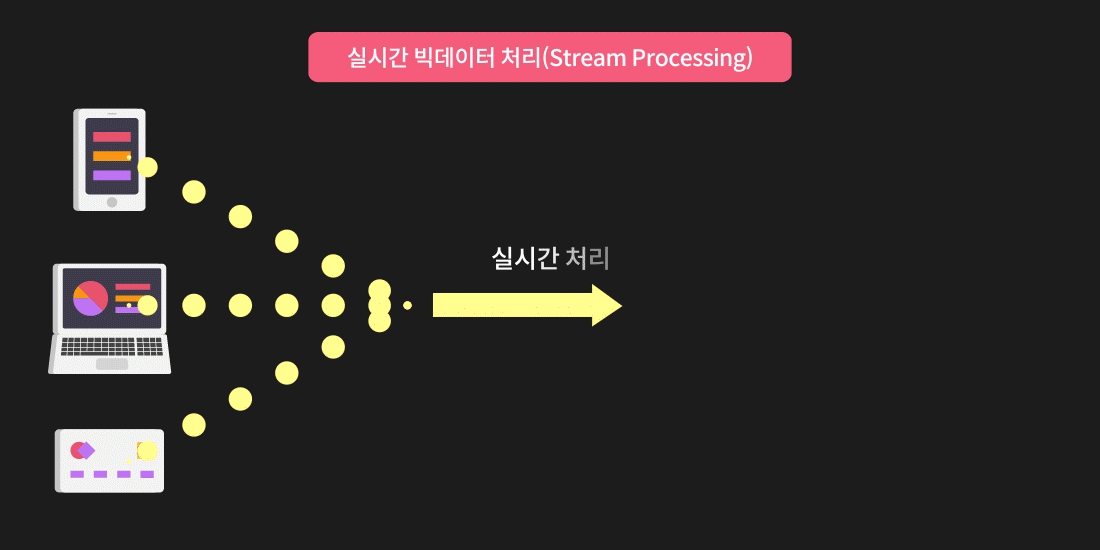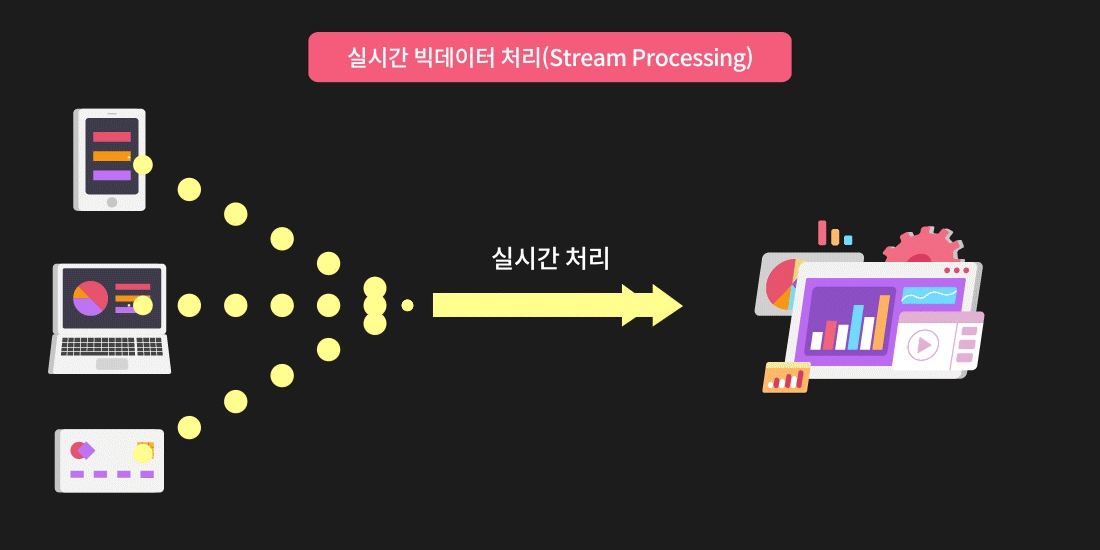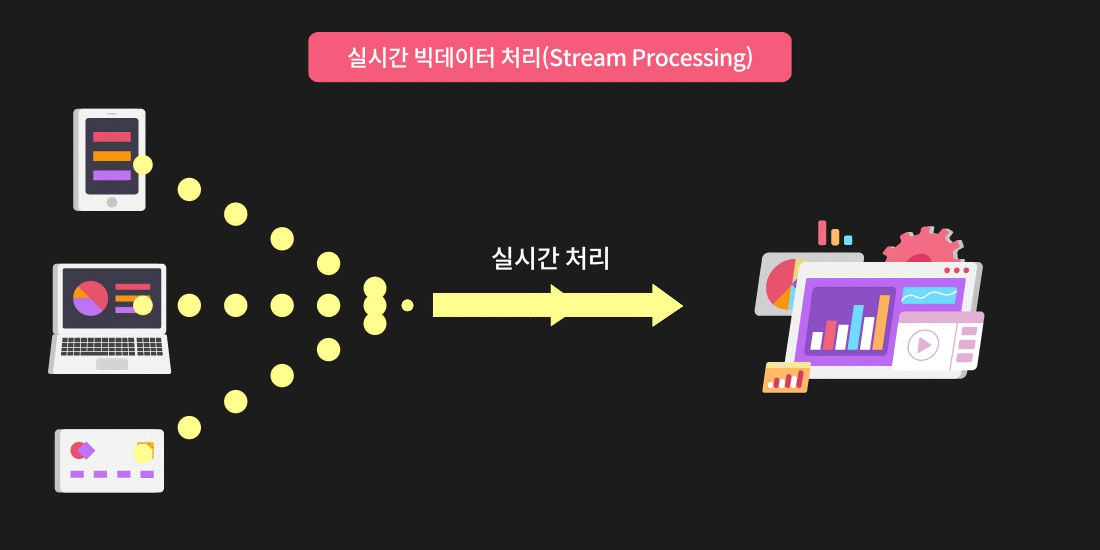
스트림 프로세싱은 데이터 처리 방법 중 실시간으로 발생한 데이터를 즉각적으로 처리하여 활용하는 방식입니다.
실시간 빅데이터 처리, 데이터 스트리밍이라고 표현하기도 합니다.
데이터 처리 방법 중에는 스트림 프로세싱 이외에도 배치 프로세싱이라는 방식이 있는데요, 비교해보면 더 쉽게 차이를 이해할 수 있습니다.
배치 프로세싱(Batch Processing)
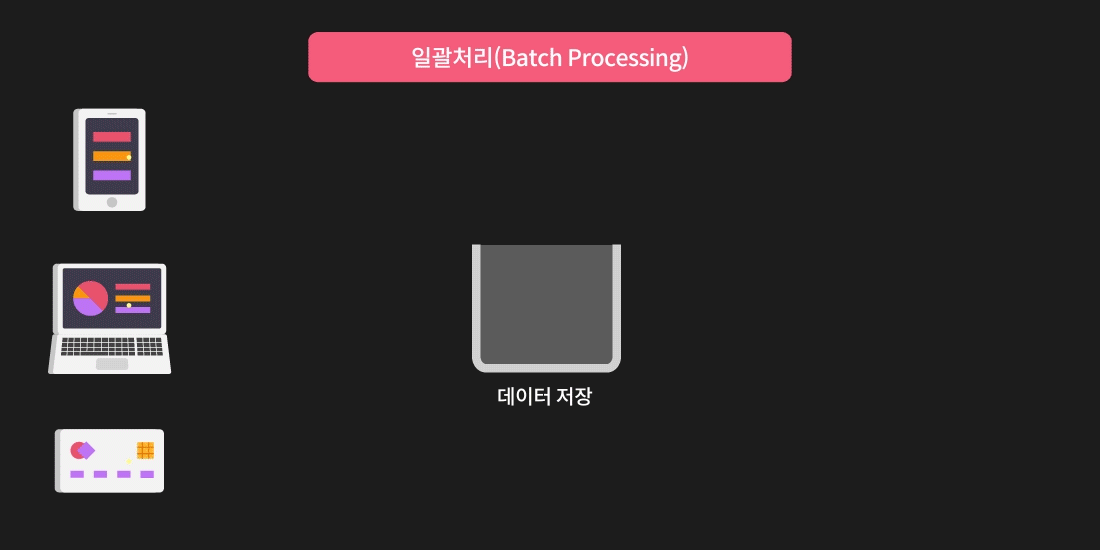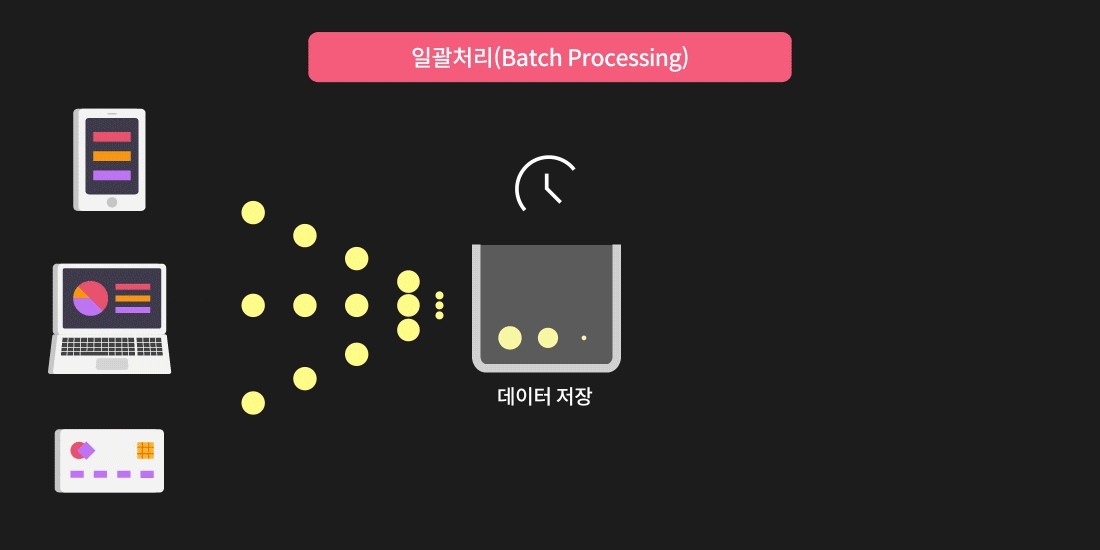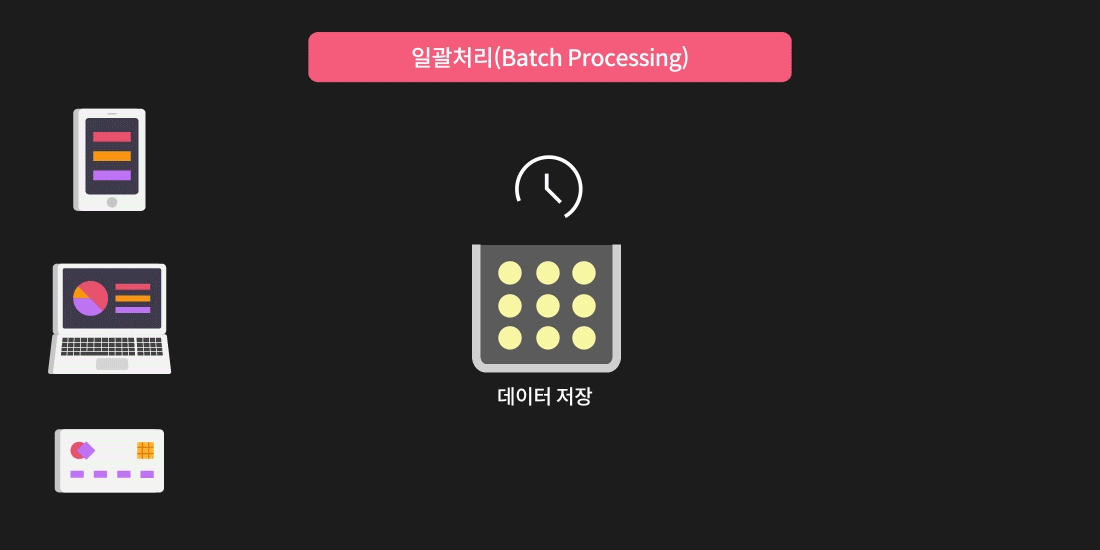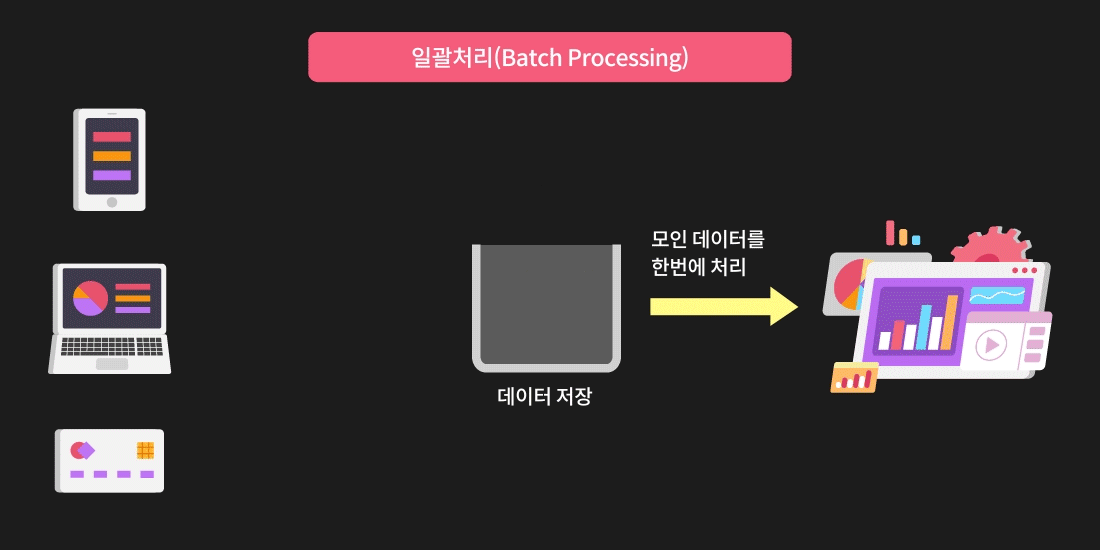
일괄처리라고도 불리는 배치 프로세싱(Batch Processing)을 이용하면 간단한 프로그램으로 많은 양의 데이터를 처리할 수 있다는 큰 장점이 있습니다. 하지만
- 데이터가 전부 처리될 때까지 시간이 다소 걸린다는 점
- 주기적으로만 결과를 확인할 수 있다는 점
- 데이터 저장 공간이 많이 필요하다는 점
의 단점이 있습니다.
반면 스트림 프로세싱은 가장 최신의 데이터를 실시간으로 처리하기 때문에 그런 단점이 없습니다. 0.1초마다 새로운 데이터가 쌓이는 요즘과 같은 빅데이터 시대에 반드시 필요한 기술이겠죠?
배치 프로세싱과 스트림 프로세싱을 상황과 목적에 따라 적절히 사용할 줄 아는 능력이 최근 데이터 엔지니어의 핵심 역량이라고 할 수 있습니다.
지금 패캐머들이 읽고있는 BEST 아티클이 궁금하다면