[아티클] “RAG는 죽었다?” AI 에이전트 시대에 ooo가 뜨는 이유
5분 트렌드 아티클 | AI
“RAG는 죽었다?”
AI 에이전트 시대에 ooo가 뜨는 이유
📌 5초 핵심 요약
• 단순 RAG의 한계 돌파: AI 에이전트 시대의 핵심은 정보의 양이 아니라 '연결'입니다. 기존 벡터 검색(Naive RAG)의 서술적 한계를
극복하고, 멀티홉(Multi-hop) 추론을 가능하게 만드는 지식 그래프(Knowledge Graph)가 대안으로 떠오르고 있습니다.
• 헷갈리는 지식 아키텍처 체계화: 기존 RDF/SPARQL 방식은 LLM이 읽기 좋은 지식 창고인 LLM Wiki, 관계 기반 검색을 수행하는
GraphRAG, 비즈니스 규칙을 검증하는 온톨로지(Ontology)를 하나의 파이프라인으로 엮는 실무 관점의 아키텍처 기준을 제시합니다.
• 실무형 지식 레이어 구축 로드맵:
금융 공시, 의료 약물 상호작용, 연구 문헌 분석 등 실제 도메인에 바로 적용할 수 있는
에이전트 하네스(Agent Harness) 구축 프로세스를 통해 프롬프트 엔지니어링을 넘어선 '지식 구조 설계'의 핵심을 파악할 수 있습니다.
최근 AI 업계에서 가장 많이 들리는 도발적인 문장이 있습니다.
바로 “RAG(Retrieval-Augmented Generation)는 죽었다”!
정말 그럴까요? 결론부터 말하자면 아닙니다. 정확히는 ‘단순히 문서 쪼개서 벡터 데이터베이스에 넣고 돌리던 Naive RAG의 시대’가 끝났을 뿐입이죠.
LLM이 스스로 판단하고 행동하는 'AI 에이전트(Agent)' 시대가 도래하면서, 기존 RAG 시스템의 밑천이 드러나기 시작했습니다. "분명 문서는 제대로 찾아서 프롬프트에 넣어줬는데, 왜 에이전트는 엉뚱한 추론을 할까?" 이 질문에 대한 답을 찾지 못했다면, 당신의 AI는 지금 '연결되지 않은 지식의 늪'에 빠진 것입니다.
🫢기존 Vector RAG가 ‘에이전트 시대’에 힘을 못쓰는 이유

기존의 벡터 검색 기반 RAG는 문장을 적당히 잘라(Chunking) 유사한 의미를 가진 텍스트를 찾아내는 데 탁월합니다. 하지만 AI 에이전트가 복잡한 비즈니스 로직을 수행할 때는 다음과 같은 세 가지 치명적인 한계에 부딪힙니다.
1) 파편화된 정보와 '멀티홉(Multi-hop)' 추론의 부재 :
에이전트에게 "A사의 규제 위반 리스크가 B사 공급망에 미치는 영향은?"이라는 질문을 던지면, 기존 RAG는 A사 문서와 B사 문서를 각각 찾을 뿐, 두 회사 사이의 '관계'를 연결해 추론하지 못합니다.
2) 맥락(Context) 이해력의 한계 :
데이터의 양이 부족해서가 아닙니다. 데이터 간의 '연결의 부재' 때문입니다. 문서 간의 선후 관계, 인과 관계를 모르는 에이전트는 늘 단편적인 대답만 내놓습니다.
3) 할루시네이션과 근거 검증의 어려움 :
에이전트가 생성한 답변이 기업의 실제 '정책 가이드라인'이나 '비즈니스 규칙'에 부합하는지 의미적으로 검증할 수 있는 브레이크 장치가 없습니다.
🌐지식 그래프(Knowledge Graph), 관계와 맥락의 뼈대를 세우다
이 한계를 돌파하기 위해 구글, 삼성, KB금융그룹 등 국내외 테크 선두 기업들이 다시 주목하는 기술이 바로 지식 그래프(Knowledge Graph)와 GraphRAG입니다.
지식 그래프는 문서 속 흩어진 정보를 개념(Entity)과 관계(Relation)로 연결하여 하나의 거대한 네트워크 데이터베이스(GraphDB)로 구축하는 기술입니다.
텍스트 검색에서 '관계 검색'으로: 단순 키워드나 벡터 유사도가 아니라, "A —[공급처]→ B —[소송중]→ C"와 같은 명확한 관계망을 따라 탐색하므로, 에이전트가 복잡한 맥락을 뇌처럼 연결하며 근거 있는 추론을 할 수 있게 돕습니다.
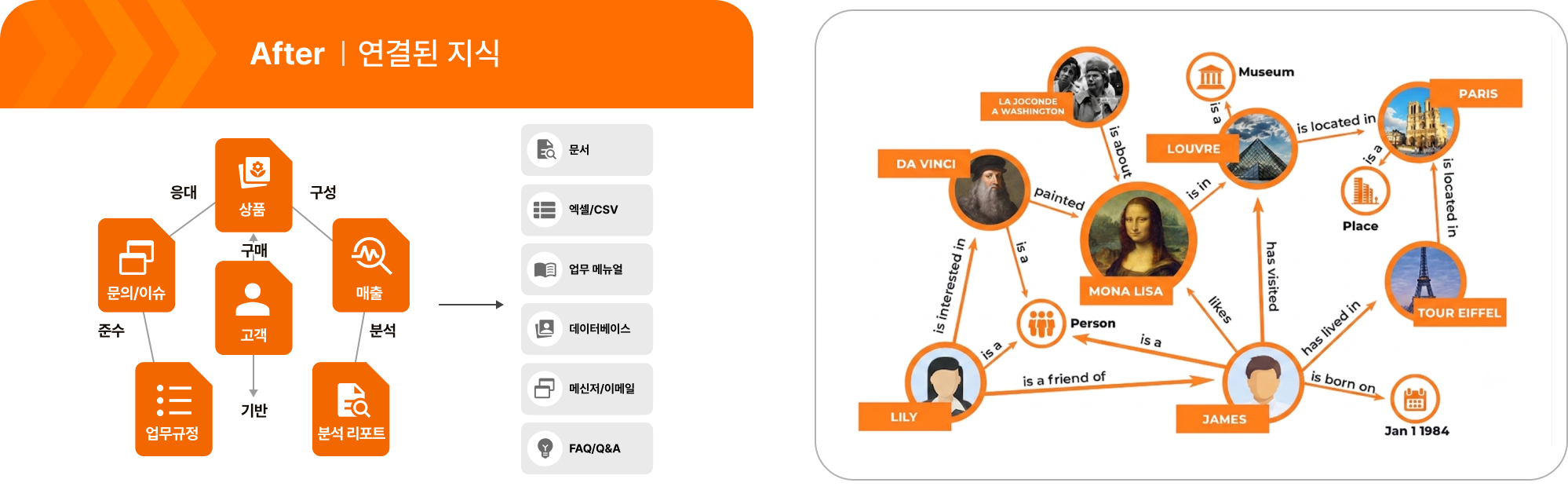
💡 잠깐! 지식그래프를 언제, 왜 사용하는지 먼저 이해해봐요!








📚 내 서비스에는 무엇이 필요할까? 실무 도입 가이드라인
막상 내 비즈니스에 적용하려고 하면 "우리도 무조건 다 구축해야 하나?"라는 의문이 듭니다. 비용(Token)과 인프라 효율을 고려한 현실적인 선택 기준은 다음과 같습니다.
1단계: 정형화된 매뉴얼과 FAQ가 중심이라면?
➡️ LLM Wiki + Vector RAG
단순히 흩어진 사내 규정이나 제품 가이드라인을 검색하는 수준이라면 잘 구조화된 마크다운 위키와 기본 RAG로도 충분합니다.
2단계: 데이터 간의 관계를 추적하고 멀티홉 질문이 많다면?
➡️ GraphRAG
"A 부품의 결함이 B 제품군 출시 지연과 C사 공급망에 미치는 영향"처럼 정보와 정보 사이의 인과관계, 영향도를 분석해야 하는 복잡한 리서치 업무에는 지식 그래프 기반의 GraphRAG가 필수적입니다.
3단계: 오답이 치명적이거나 엄격한 비즈니스 규칙이 있다면?
➡️ Ontology + Semantic Validation
금융 컴플라이언스(규제 준수), 의료 약물 상호작용 검토 등 잘못된 추론이 법적·치명적 문제를 일으키는 도메인이라면, 온톨로지를 통해 AI가 규칙을 위반하지 않았는지 검증하는 브레이크 장치를 반드시 결합해야 합니다.
💡 실제 산업군별 적용 예시
1) 금융 (Enterprise Research):
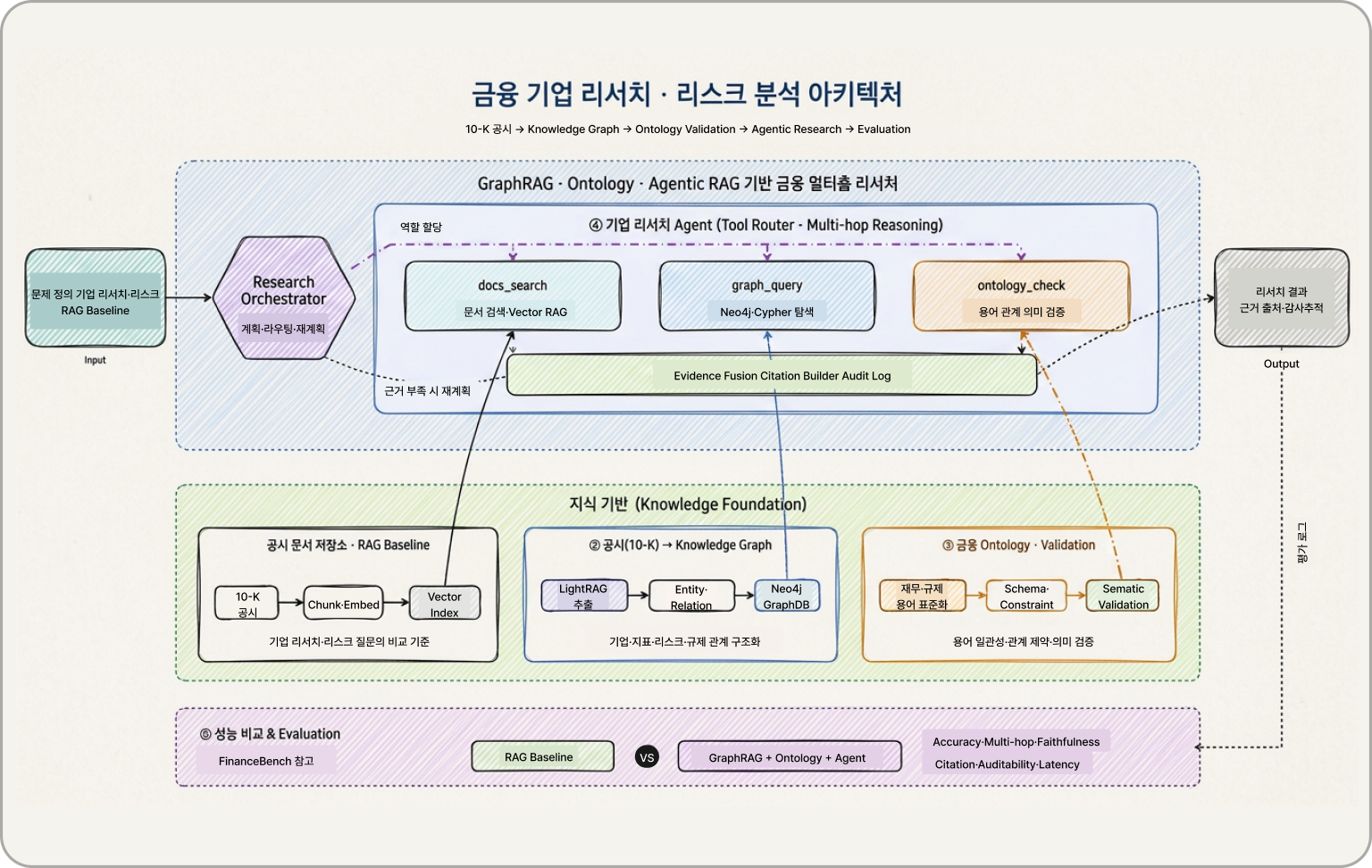
10-K 기업 공시 데이터와 재무 지표 간의 관계 네트워크를 구축해 리스크를 추적하는 '기업 리서치 에이전트'
2) 의료 (Clinical Helper):
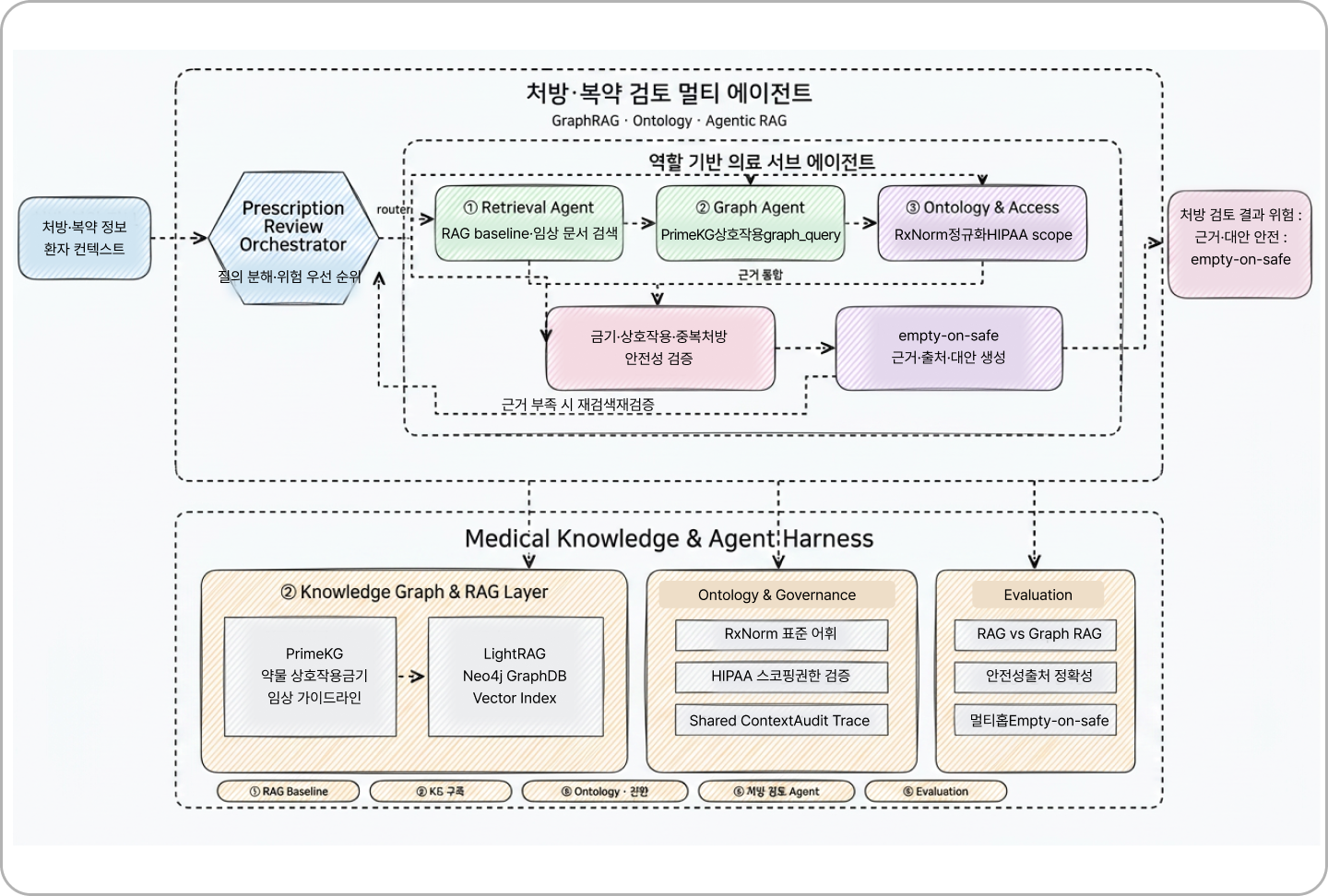
임상 가이드라인과 환자 컨텍스트, 약물 금기 사항(RxNorm, PrimeKG)을 매핑하여 안전성을 검증하는 '처방·복약 검토 에이전트'
3) 연구 (Academic Harness):
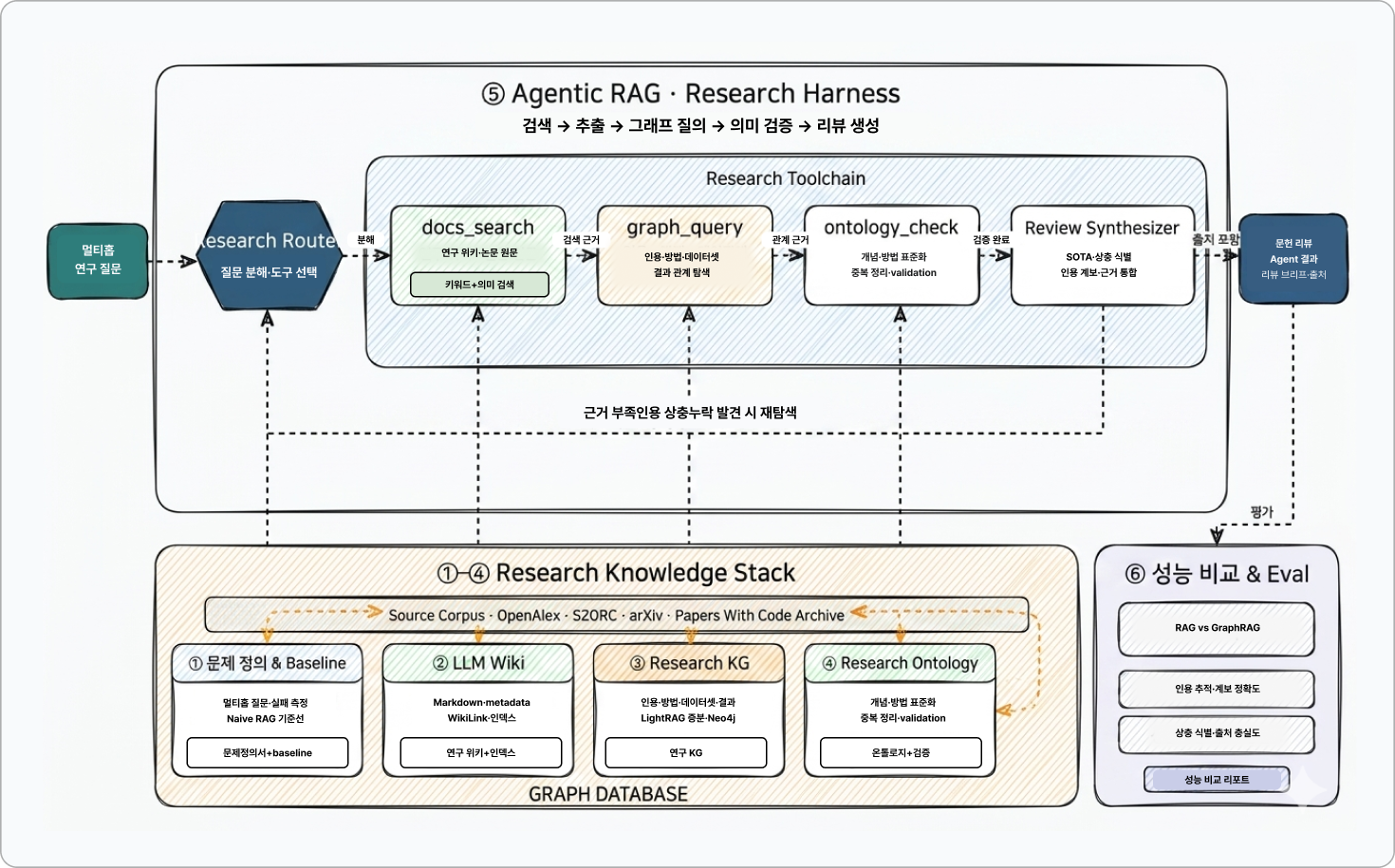
수많은 논문의 인용 계보와 방법론, 데이터셋 간의 상충 관계를 식별하고 문헌 리뷰를 자동화하는 '연구 지식 탐색 에이전트'
✨이제 핵심은 검색이 아니라 ‘지식 구조 설계’다!
더 뛰어난 LLM 모델을 쓰거나, 프롬프트를 수십 번 고치는 것만으로는 에이전트의 한계를 극복할 수 없습니다. 결국 AI 에이전트의 지능은 기업이 보유한 지식을 얼마나 촘촘하고 단단하게 연결해 주느냐(Knowledge Layer 설계)에 달려 있습니다.
이제 여기저기 파편화된 기술 이름을 나열하는 것을 넘어, LLM Wiki부터 GraphRAG, 온톨로지, 그리고 에이전트 하네스까지 하나의 유기적인 흐름으로 엮어내는 실무형 아키텍처를 이해해야 할 때입니다.
금융 공시 분석, 의료 약물 상호작용 검토, 연구 문헌 추적 등 진짜 '돈이 되는' 실무형 지식 에이전트를 내 손으로 직접 구축해보고 싶다면, 이 모든 로드맵을 한 권에 압축한 [김용담의 에이전트를 위한 지식그래프 바이블] 강의를 통해 RAG 이후의 AI 마스터로 거듭나 보세요.

✨ 이 콘텐츠 보신 분에게만 드리는 특별 15% 쿠폰 (~26/12/31)✨
📌쿠폰 코드 : 김용담의에이전트