[아티클] AI 시장을 움직이는 온톨로지, 하지만 왜 정작 내 서비스에 도입 못할까?
5분 트렌드 아티클 | AI
AI 시장을 움직이는 온톨로지,
하지만 왜 정작 내 서비스에 도입 못할까?
📌 5초 핵심 요약
• 할루시네이션 방지의 핵심: AI 에이전트와 GraphRAG의 핵심인 온톨로지는 LLM의 환각 현상을 막고 검증 가능한 논리적 사고를 부여하는
필수 기술입니다.
• 전통 방식의 한계 극복: 기존 RDF/SPARQL 방식은 복잡한 문법과 무거운 구조로 실무 도입이 어려웠으나, 자연어로 추론 구조를 설계하는
'LLM 친화형 Datalog 온톨로지'가 그 해결책으로 떠오르고 있습니다.
• 실무형 3단계 빌드업: LLM을 통한 데이터 구조화(TBox&ABox), Datalog 기반 추론 규칙 설계, 그리고 사람의 정책 기준 이식을 거쳐
완벽한 AI 에이전트 시스템을 완성할 수 있습니다.
최근 AI 업계의 화두는 단연 Agent(에이전트)와 GraphRAG(그래프 RAG)
단순히 질문에 답하는 LLM을 넘어, 스스로 판단하고 행동하는 AI 시스템을 만들기 위해 많은 기업이 앞다투어 기술을 도입하고 있죠.
이 중심에 다시금 떠오른 핵심 개념이 바로 '온톨로지(Ontology, 데이터 구조화 및 지식 모델링)'입니다. LLM의 고질적인 문제인 할루시네이션(환각 현상)을 막고, AI에게 '설명 가능하고 검증 가능한' 논리적 사고 능력을 부여하려면 데이터 간의 관계를 정의하는 온톨로지가 필수적이기 때문입니다.
하지만 현업에서 온톨로지를 내 서비스에 선뜻 도입하기란 쉽지 않습니다.
"온톨로지가 좋다"는 말은 무성한데, 왜 우리 서비스에는 적용하지 못하고 겉돌기만 할까요?
😭우리가 온톨로지 도입에 번번이 실패했던 이유 (전통형 온톨로지의 한계)
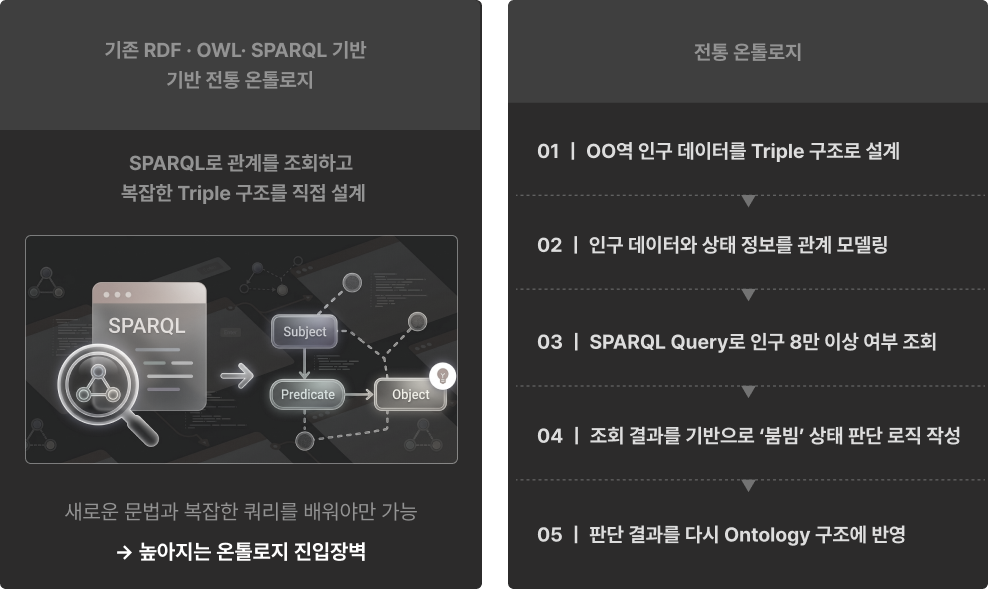
그건 바로 기존의 전통적인 온톨로지(RDF · OWL · SPARQL 기반)가 가진 진입장벽이 너무 높았기 때문입니다.
1) 낯설고 복잡한 문법 : AI 서비스를 고도화하기도 바쁜데 RDF, OWL 같은 생소한 개념부터 데이터 조회를 위한 SPARQL 쿼리문까지 새로 배워야 했습니다.
2) 복잡한 Triple 구조 설계 : 데이터 구조를 일일이 주어-수로-목적어(Triple) 형태로 직접 설계하고 매핑해야 하므로, 초기 모델링 단계에서 지쳐버리기 일쑤였습니다.
3) 실무 활용과의 괴리 : 쿼리를 짜고 그래프를 구축하는 것(예: 옵시디언 등)에 그칠 뿐, 정작 "이걸 내 서비스와 LLM 에이전트에 어떻게 연결해서 판단 로직으로 쓸 것인가?"에 대한 해답을 찾기 어려웠습니다.
결국 예전 방식의 온톨로지는 '개념 배우다 끝나는 기술', '실무에 쓰기엔 너무 무거운 기술'이라는 오명을 쓸 수밖에 없었습니다.
🧠해결책은 'LLM 친화형 온톨로지' (Datalog와 뉴로심볼릭 AI)
LLM 시대인 지금은 온톨로지에 접근하는 패러다임이 완전히 달라져야 합니다. 복잡한 문법 중심의 전통 방식에서 벗어나, AI가 이해하기 쉬운 'LLM 친화형 온톨로지'로 전환해야 합니다. 그 핵심 키워드가 바로 뉴로심볼릭 AI와 Datalog 언어입니다. 기존 방식과 LLM 친화형 방식이 어떻게 다른지 비교해 보면 그 차이가 극명합니다.
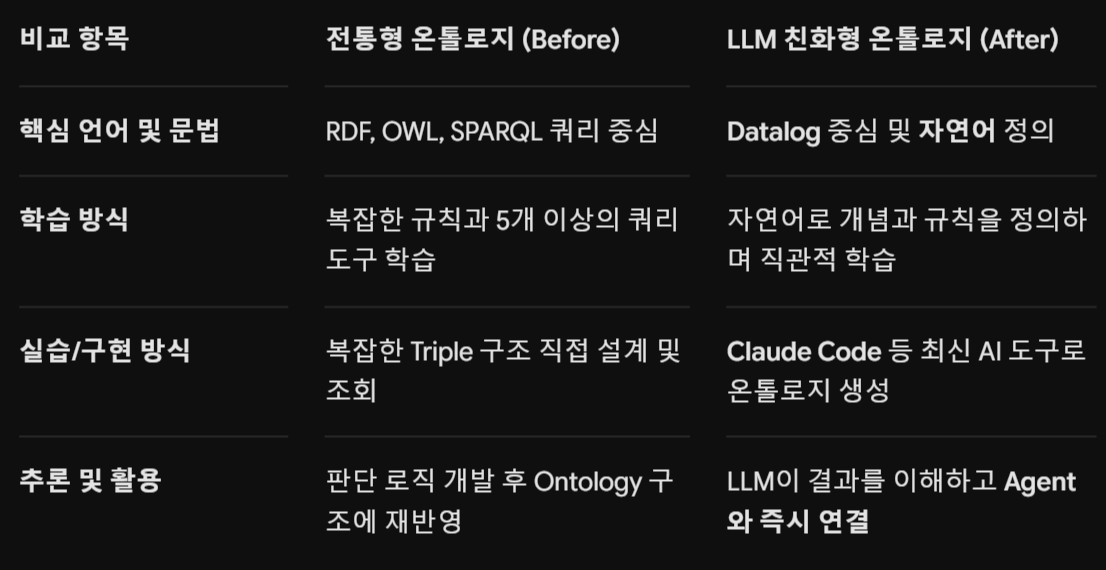
💡 잠깐! "왜 RDF/SPARQL 대신 Datalog인가요?"
예를 들어 *"OO역 인구가 8만 명 이상이면 '붐빔' 상태로 판단한다"*는 규칙을 세운다고 가정해 봅시다. 전통 방식에서는 인구 데이터를 Triple 구조로 설계하고, 관계를 모델링한 뒤, SPARQL 쿼리로 조회해 판단 로직을 직접 짜야 했습니다.
반면, Datalog 기반의 LLM 친화형 온톨로지는 자연어로 조건을 입력하면 Datalog가 이를 추론 구조로 관리하고, LLM이 결과를 이해해 에이전트의 행동(Skill)으로 곧바로 연결합니다. 복잡한 코드가 아니라 '어떤 논리적 구조를 만들 것인가'에만 집중할 수 있게 되는 것입니다.

🌐 그래서 'LLM 친화형 온톨로지', 어떻게 설계하면 좋을까?
단순히 "구축하기 쉽다"를 넘어, 실제로 이 기술이 서비스 아키텍처에 들어왔을 때 해결할 수 있는 실무 시나리오는 무궁무진합니다. 그렇다면 이 강력한 지식 구조를 실제 내 서비스에 심기 위해선 어떤 빌드업 과정이 필요할까요?
① 1단계: 온톨로지 지식 구조화 및 데이터 구축 (TBox & ABox)

먼저 도메인의 뼈대를 잡아야 합니다. LLM을 활용해 개념과 관계를 정의하는 온톨로지 설계도인 TBox(개념 스키마)를 생성하고 보정합니다. 그 다음, 실제 인스턴스 데이터를 지식화하는 ABox(실제 관계 데이터)를 구축하여 의미 기반의 기초 데이터 레이어(Triple Store)를 완성합니다. 이 단계에서 기존 GraphRAG와 온톨로지 구조의 명확한 차이점을 정립하는 것이 핵심입니다.
② 2단계: 자연어 기반 추론 규칙 설계 (Datalog Engine)
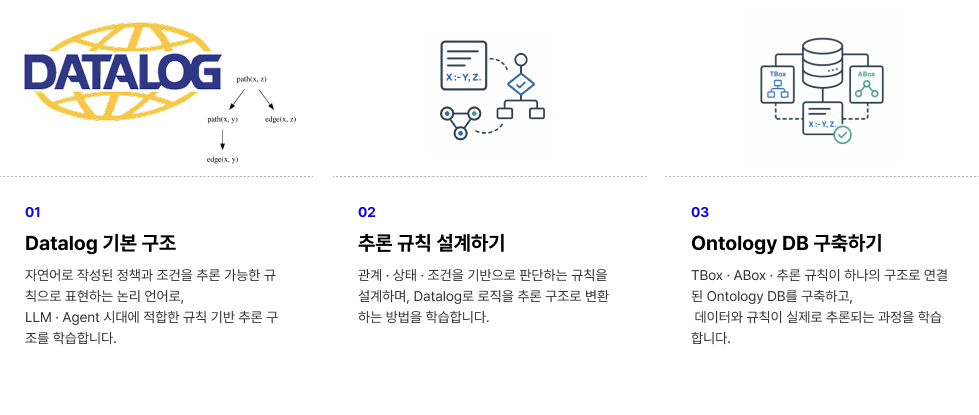
기초 데이터가 쌓였다면, 자연어로 작성된 비즈니스 정책과 조건을 추론 가능한 규칙으로 바꾸는 논리 언어인 Datalog를 결합합니다. LLM을 활용해 관계·상태·조건 기반의 추론 규칙을 설계하고, 데이터와 규칙이 하나의 유기체처럼 맞물려 작동하는 온톨로지 DB를 빌드합니다.
③ 3단계: 사람의 판단과 정책 기준 이식
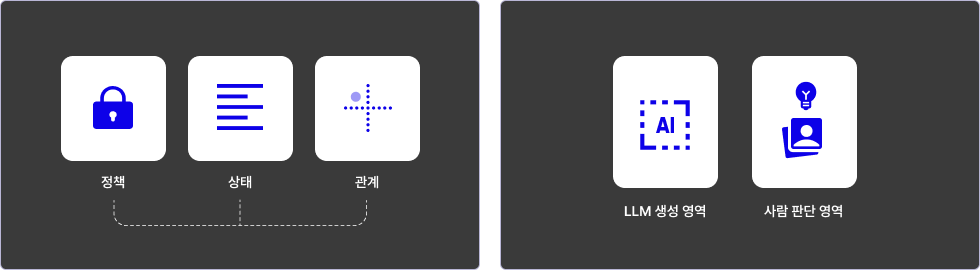
모든 것을 AI에게 전적으로 맡길 수는 없습니다. LLM이 자동으로 생성할 수 있는 영역과, 사람이 직접 판단하고 설계해야 하는 도메인 정책 기준(의사결정 및 상태 분류 기준)을 명확히 구분해야 합니다. 업무 정책을 완벽히 반영한 추론 로직을 얹어 에이전트의 최종 행동 기준을 설계합니다.
✨이제, 내 서비스에 진짜 온톨로지 지능을 더할 때
온톨로지는 더 이상 학술 용어가 아닙니다. 내 서비스의 RAG 에이전트가 가진 구조적 한계를 깨부수고, 사내 지식을 완벽하게 자동화할 수 있는 가장 실무적인 해답입니다.
막막하게만 느껴졌던 온톨로지를 가장 쉽고 직관적으로 내 실무에 적용해보고 싶다면, 10년 이상 국가 · 대기업에서 온톨로지를 적용해 온 [LLM으로 더 쉽게 배우는 온톨로지 : LLM Wiki · Agent 하네스 · Skill 구축으로 실무 완성]으로 배워보세요!

✨ 이 콘텐츠 보신 분에게만 드리는 특별 15% 쿠폰 (~26/12/31)✨
📌쿠폰 코드 : LLM으로더쉽게