[미디어] MLOps란? | MLOps 구성요소, 실제 활용 사례, MLOps 파이프라인 구축, 학습방법 총정리 가이드
MLOps란? | MLOps 구성요소, 실제 활용 사례, MLOps 파이프라인 구축, 학습방법 총정리 가이드
| MLOps의 탄생배경: 기계학습 시대의 도래
기계학습(ML) 시대가 도래하였습니다. 불과 몇 년 전까지만 하더라도 인공지능, 기계학습의 성취가 연구분야에서만 머물러 있었다면 이제는 기계 스스로 새로운 글을 쓰고, 이미지를 생성하고, 상품을 추천해 주는 시대에 살고 있습니다.
이렇게 AI, ML 붐이 일어난 이후, 머신러닝을 담당하는 엔지니어 채용이 많이 이루어졌는데요. 하지만 실제 현장에서는 연구 레벨에서의 성공과 실제 서비스로의 적용 간의 괴리가 커 ML모델을 만들어놓고도 서비스화에 실패하는 비율이 굉장히 큽니다. 실제로 개발된 모델의 80%가 버려진다는 조사 결과도 있는데요.
그렇다 보니 기업에서도 점점 머신러닝 모델 자체보다는 잘 정제된 데이터를 준비하는 것, 모델을 서비스화하는 것, 서비스화한 모델을 모니터링하는 것 등. 모델 연구 외의 많은 업무(Ops)들의 비중이 점점 크다고 느꼈고, MLOps라는 단어가 대두되었습니다.
| 성공적인 ML모델 서비스화를 위한 필수적 환경: MLOps
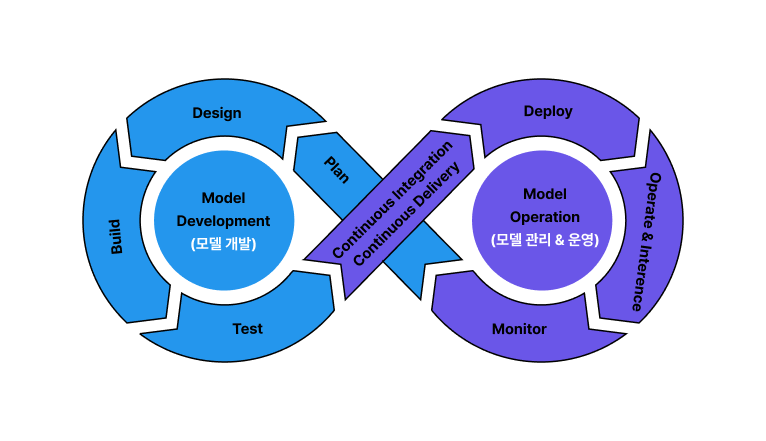
MLOps란, Machine Learning에 Operations를 덧붙인 단어로, ML 시스템 개발과 ML 시스템 운영을 통합하는 것을 목표로 하는 ML 엔지니어링 문화 및 방식입니다.
연구 위주의 머신러닝 모델을 안정적이고 효율적으로 배포 및 유지 관리하기위해 고안되었으며, 머신러닝 시스템을 위한 CI/CD(지속적 통합, 지속적 배포), 지속적인 학습을 구현하고 자동화하는 기술을 의미합니다.
MLOps는 크게 ML(개발) 단계와 Ops(운영) 단계로 나눌 수 있습니다.
그 구성을 간단히 살펴보자면,
ML 단계에서는 데이터 수집, 전처리, 모델 구축, 학습, 평가 등의 과정이 이루어집니다.
Ops 단계에서는 ML 단계에서 완성된 모델의 배포, 모니터링, 테스트 등을 수행할 수 있습니다.
| MLOps가 현장에서 필요한 이유는?
MLOps가 무엇이고 왜 생겨났는지는 알아봤는데요. 그렇다면 MLOps가 현장에서 필요한 구체적인 이유는 무엇일까요?
MLOps가 도입되어야 하는 이유는 크게 4가지로 꼽을 수 있습니다.
1. 효율성 증진
ML옵스를 도입하면 시스템 개발과 운영을 통합해 개발 속도를 단축시킬 수 있으며, 자동으로 데이터를 처리 및 개선된 모델을 배포하여 시간과 오류를 줄이고 모델 개발 ~ 운영 시 발생하는 수많은 비효율화를 감소시킬 수 있습니다.
우선 모델 개발 시에는,
① 모델 학습을 위한 반복되는 데이터 셋에서 Feature Selection을 적용시켜 수 많은 데이터 셋을 효율적으로 관리할 수 있습니다.
② 성능 높은 모델을 개발하기 위해선 다양한 머신러닝 알고리즘을 계속 대입해야 하는데, 이 과정에서 발생하는 대량의 파라미터를 MLOps를 활용하여 한 번에 학습할 수 있습니다.
③ 마지막으로 MLOps를 사용하지 않고 머신러닝 모델을 최적화할 경우 Learing rate 등 에폭시를 계속 변경하며 최적화해야 해서 여러 달이 소요되지만, 하이퍼파라미터 튜닝을 통한 최적화로 서비스 자동화는 물론 기간도 대폭 감소하며 서비스를 최적화할 수 있습니다.
다음으로 모델 운영 시에는,
개발된 모델을 서빙 후, MLOps를 활용하지 않는다면 계속해서 새로 유입되는 데이터 기반으로 모델을 업데이트하느라 많은 리소스가 들 텐데요. MLOps를 활용한다면 자동화가 가능해 리소스를 대폭 줄이는 것이 가능합니다.
2. 긴밀한 협업
개발자들이 ML Engineer / Data Scientist 들을 고려하지 않고도 빠르게 데이터/모델 버전 업데이트에 따른 개발 환경 구성을 자동화할 수 있습니다.
또한 소프트웨어 엔지니어와 데이터 사이언티스트에게 협업 환경을 제공하여 실시간 공동 작업과 반복 데이터 탐색 기능을 지원하여 실험 추적, 모델 관리, 피처 엔지니어링 등을 간편하게 수행하도록 돕습니다.
이에 데이터 사이언티스트, DevOps 팀, 개발팀, 운영팀과의 갈등을 줄여 릴리즈 속도를 향상시킬 수 있습니다.
3. 확장성
모델의 개수가 어떻든, 모델 & 데이터 업데이트의 주기가 얼마나 다양하던지 수천 개의 모델을 지속적으로 관리하고 배포할 수 있습니다. MLOps는 확장성과 유지·관리에 특화되어 있습니다. 자동으로 대량의 모델을 관리·감독·제어·모니터링하며 모델을 통합하고 배포할 수 있습니다.
3. 안정성
MLOps의 필수 조건인 지속적인 통합·배포·학습을 통해 데이터의 품질을 높은 상태로 관리할 수 있으며 ML 시스템을 자동으로 관리하기 때문에 안정적입니다.
| 자동화에 따른 단계별 MLOps
MLOps에도 단계가 존재하는데요. 구글은 자동화가 필요하지 않은 가장 일반적인 수준부터 ML 및 CI/CD 파이프라인 모두를 자동화하는 수준까지 MLOps을 세 가지 수준으로 나눠 설명합니다.
MLOps level 0: Manual Process
데이터 분석, 데이터 준비, 모델 학습, 모델 검증을 포함한 모든 단계를 수동으로 수행하는 단계입니다.
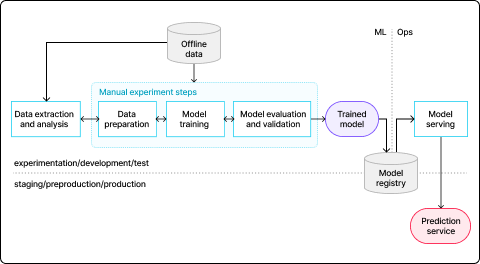
•모델 구현 시에 최적화/모델 선택을 manually(손수) 진행
•모델 업데이트 주기가 길거나 관리할 모델이 적은 경우에 사람이 직접
모델 업데이트를 진행
•구현 변경사항과 모델 버전이 자주 배포되지 않으므로 CI/CD가
고려되지 않음
•모델 최적화를 진행하기 위한 모니터링을 수행
MLOps level 1: ML pipeline automation
ML 파이프라인 자동화를 통해 모델을 지속적으로 학습하고 모델 예측 서비스를 지속적으로 수행할 수 있는 단계입니다.
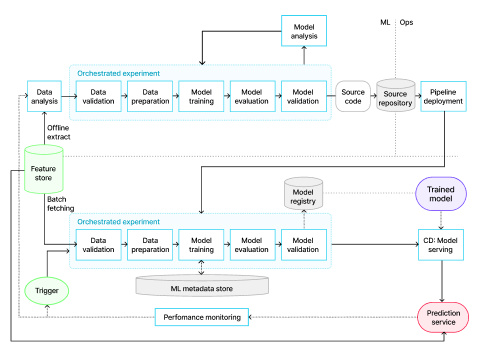
•실시간 파이프라인 트리거를 기반으로 하는 새로운 데이터를 사용하여 모델이 프로덕션 단계에서 자동으로 학습
•새로운 데이터로 학습된 새 모델에 예측 서비스를 지속적으로 배포
•학습된 모델을 예측 서비스로 제공하기 위한 자동 반복 실행되는 전체 학습 파이프라인을 배포
MLOps level 2: CI/CD pipeline automation
프로덕션 단계에서 파이프라인을 빠르고 안정적으로 업데이트 하기위한 강력하고 자동화 된 CI/CD 시스템을 구축하는 단계입니다.
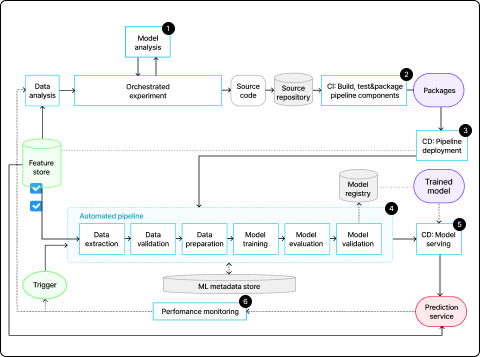
•특성 추출, 모델 아키텍쳐, 초매게변수에 대한 새로운 아이디어를 빠르게 살펴볼 수 있음
•CI : 소스 코드를 빌드하고 이후 단계에서 배포할 파이프라인
구성요소(패키지, 실행 파일 및 아티팩트)를 테스트
•CD : CI 단계에서 생성된 아티팩트를 대상 환경에 배포하고,
모델의 새로운 구현이 포함된 파이프라인을 출력
•일정에 따라 혹은 트리거에 대한 응답으로 프로덕션 환경에서
파이프라인을 자동으로 실행
| 실제 기업들의 MLOps 도입 사례
그렇다면 이러한 MLOps를 실제 기업들은 어떻게 활용하고 있을까요? 국내 기업과 글로벌 기업 사례로 MLOps를 어떻게 활용할 수 있는지 알아보겠습니다.
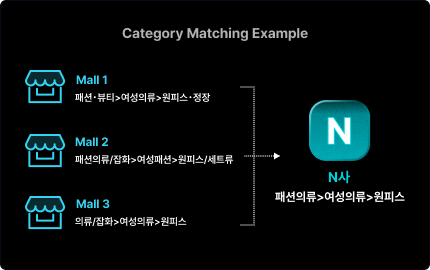
● N사 이커머스
이커머스를 운영하는 회사들은 MLOps를 실시간 유입 상품 카테고리 분류를 위한 Serving 파이프라인 및 Inference환경 구축에 사용하고 있습니다. 상품 카테고리를 자동으로 분류하는 모델을 구축하고 배포를 자동화하여 모델 수정 시에도 배포에 들어가는 리소스를 감소시킵니다.
또한 이커머스에서 발생하는 대표적인 문제 사례 중 하나인 상품이 유저에게 노출되지 않는 문제를 해결하기 위해 카프카를 사용해서 ML 모델을 운영하고, ml 모델을 배포할 때 kserve 를 이용해서 자원에 유동적으로 운영합니다.
● 카카오뱅크
금융업계에서는 개인신용평가, 이상거래 탐지, 유저 프로파일 ML모델을 사용하는데요. 데이터가 지속적으로 증가함에 따라 데이터에 변화가 생기고 모델 업데이트가 필요하자 비용과 리소스 감소를 위하여 MLOps를 도입하였습니다.
데이터 변화에 따라 A 모델의 사용이 불가해졌을 때, B 모델을 개발한다면 모델 B를 서빙하기 위한 파이프라인 추가 개발 등 중복 개발이 필요하기에 생산성이 저하되고 피쳐 통합 관리가 어려우며, 운영 복잡도 또한 증가합니다.
이에 카카오뱅크는 AWS, Jenkins, Model Registry, 도커, Spinnaker, EKS 등을 활용하여 모델 학습 파이프라인을 통해 학습된 모델을 얻고, Feature Store통해 학습과 모델 서빙에 필요한 데이터를 준비, 모델 Serving을 통해 시스템에 모델을 적용하는 환경을 만들어 모델이 지속적으로 관리되고 배포되는 환경을 구축하였습니다.
그 결과 개발 리소스 50% 효율화, 30% 비용 절감을 이루었습니다.
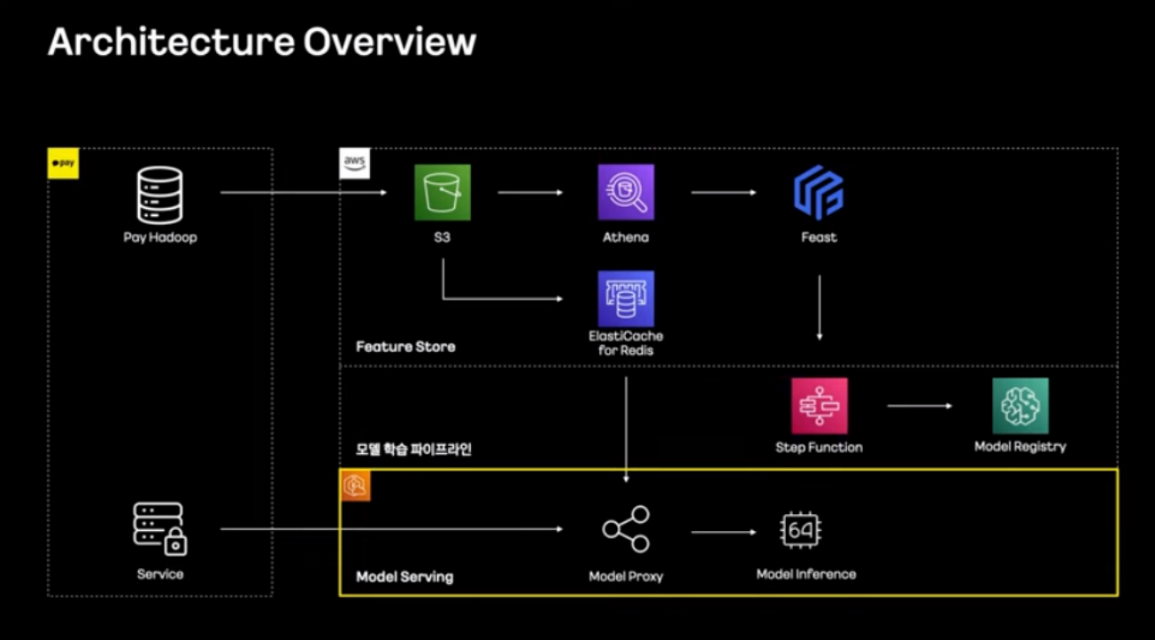
출처: https://www.youtube.com/watch?v=5FvTXzDLPxI
● 제조업
제조업에서 발생하는 대표적인 문제 상황은 센서 데이터나 로그 데이터가 자동으로 쌓이게 되면서 부품의 변경이나 시즈널 한 데이터로 인해 모델의 성능이 저하되는 문제가 발생할 수 있습니다.
다른 도메인에 비해 예측과 모델 업데이트 주기가 짧다는 특징이 있는데 이를 고려하여 시계열 데이터로 일 단위 배치성 업데이트를 통해 발생하는 문제를 해결할 수 있습니다.
● Amazon
아마존은 MLOps를 사용하여 ML 모델을 관리하고 배포하여 정확하고 최신 상태를 유지합니다. MLOps를 통해 Amazon은 발생할 수 있는 모든 문제를 신속하게 감지하고 해결할 수 있으므로 모델이 최적의 성능을 발휘하고 정확한 결과를 제공할 수 있습니다.
●Google
구글은 MLOps를 사용하여 크고 복잡한 ML 모델을 관리함으로써 새로운 모델을 더 빨리 시장에 출시하고 기존 모델의 정확도를 향상시킬 수 있었습니다. MLOps를 사용하면 Google은 ML 모델 관리 프로세스를 자동화하여 모델을 생산하는 데 필요한 시간과 노력을 줄이고 최적의 성능을 보장할 수 있습니다.
| 그렇다면 MLOps를 제대로 배우는 방법은 무엇일까요?
MLOps Market - Global Forecast to 2027보고서에 따르면 ML옵스 시장 규모가 2022년 11억 달러에서 2027년 59억 달러로 증가하며 연간 41%의 성장률을 달성할 것으로 예측됐는데요.
MLOps의 시장은 지속적으로 성장하고 있지만 관련 사례나 공개된 자료는 많지 않아 학습에 어려움이 큽니다. 아직 막 성장하는 단계이기에 사람마다 기업마다 말하는 개념이 다르기도 하고 뭐부터 시작해야 하는지, 어떻게 도입해야 하는지 공부와 구축이 쉽지 않은데요. 더군다나 학습해야 할 개념이 많아 파이프라인 구축 방법 자체도 쉽지 않습니다.
이에 현직자분들께 어떻게 학습하는 것이 가장 효율적이고 중요할지 여쭤보고 그 답변을 정리해 보았습니다.
1. 모델 개발 + 최적화 + CI/CD + 자동화를 유기적으로 학습
네이버 커머스 MLOps팀에 계신 현직자분께서는 “ MLOps는 Machine Learning이라는 특성 때문에 데이터 수집부터 배포까지 모두 경험해 보는 것이 좋다. 좋은 ML 모델을 운영하고 배포하는 과정까지 모두 알기 위해서는 양질의 데이터 수집부터 학습된 결과물을 다양한 서버 환경에서 배포하는 경험이 중요”하다는 답변을 주셨습니다.
실제 MLOps Engineer, ML Engineer의 최근 채용공고를 살펴봐도

Model 을 개발 및 실험하는데 필요한 리소스 및 도구들까지도 관리하고 제공하는 것을 MLOps Engineering 에 포함 시키기도 하고, 추가적으로 Serving 및 Inference 관련 영역, CI/CD, 자동화까지 포함되기에 MLOps 전 프로세스를 유기적으로 학습하여야 합니다.
2. 다양한 환경, 여러 스택을 경험
기업마다 활용하는 클라우드나 서버가 모두 다르기에 다양한 환경에서 여러 스택을 경험해 보시는 게 중요합니다. 또한 실제 비즈니스 환경에서는 수많은 복잡성과 불확실성을 마주하게 되는데요. 머신러닝은 목적에 따라 모델의 개수가 단수/복수, 모델/데이터의 업데이트 주기도 천차만별로 바뀌기에 많은 프로젝트를 경험해 보며 현장 중심의 MLOps를 배워야 합니다.
더불어 MLOps 플랫폼 도입 시, 초기 데이터 설계에 유의한 결정이 필요하기에 데이터를 많이 다루는 산업 군( 이커머스, 금융, 제조업 등)의 사례를 학습하는 것도 도움이 됩니다.
3. 오퍼레이션에 초점을 맞춘 학습
ML모델을 개발하는 것도 중요하지만 사실 MLOps의 핵심은 모델링에 집중할 수 있도록 관련 인프라를 만들어 자동으로 운영되도록 하는 것에 있습니다.
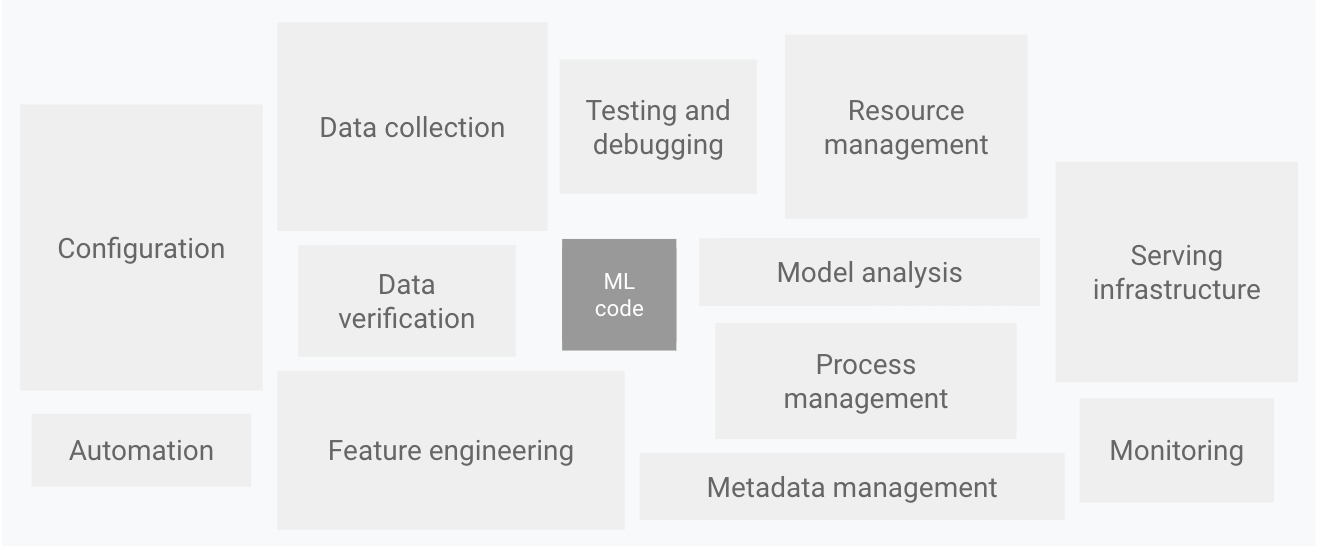
출처: https://bit.ly/3M87Jdg
머신러닝 모델의 코드를 짜는 것이 중요하기는 하지만, 전체 프로덕션 ML시스템의 운영을 고려한다면, ML code를 짜는 것은 머신러닝 프로젝트 실무의 5%에 불과합니다.
실제 현장에서 ML시스템이 유기적으로 잘 돌아가기 위해서는 데이터 파이프라인 구축, 데이터 전처리, 모델 서빙, 모니터링 등의 업무가 95%를 차지합니다.
실제로 챗GPT의 컨트리뷰터 리스트를 봐도 모델러보다 인프라와 시스템 엔지니어를 더 많이 발견할 수 있습니다.
| 마무리하며
한 MLOps 엔지니어 분께선, 머신러닝 파이프라인은 현재 인공지능 업계에서 가장 중요한 부분으로, 인공지능 회사들의 기술 소개 페이지를 가면 항상 빠지지 않는 게 바로 MLOps 관련 기술이라고 말씀하셨습니다.
그래서 MLOps 파이프라인 구축법을 통해 ML엔지니어, AI엔지니어 분들의 더욱 효율적인 리소스 관리를 돕고자 패스트캠퍼스에서 강의를 준비했습니다.
실제 비즈니스 환경에서 마주하는 수많은 복잡성과 불확실성을 해소하고자 다양한 환경, 실제 프로젝트 기반의 강의로 구성하였으니 평소 MLOps 파이프라인 구현에 목마름이 있으셨던 분들은 [10개 프로젝트로 한 번에 끝내는 MLOps 파이프라인 구현] 강의에서 만나보세요.
참고 및 출처:
1. https://bit.ly/3Q4qrDJ
2. https://bit.ly/3QqQTsO
3. https://www.thedatahunt.com/trend-insight/guide-mlops
4. https://elice.io/newsroom/whats_mlops
👉 지금 패캐머들이 읽고 있는 BEST 아티클이 궁금하다면?