
한번에 끝내는 LLMOps & 데이터 파이프라인 구축
생성형 AI와 LLM의 등장은 새로운 데이터 시대의 탄생을 알리면서
새로운 데이터 엔지니어링 사이클이 생성되었습니다.
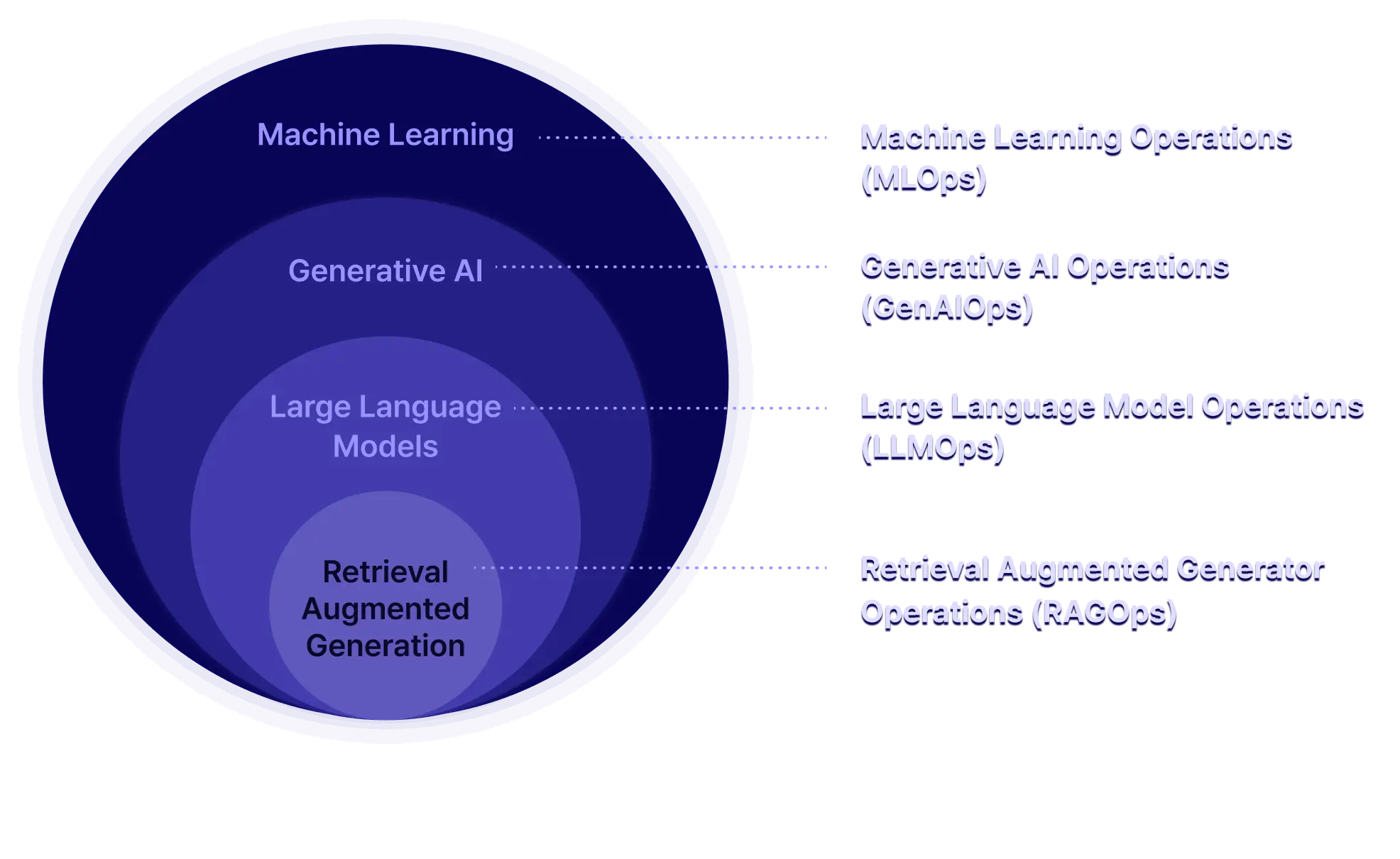
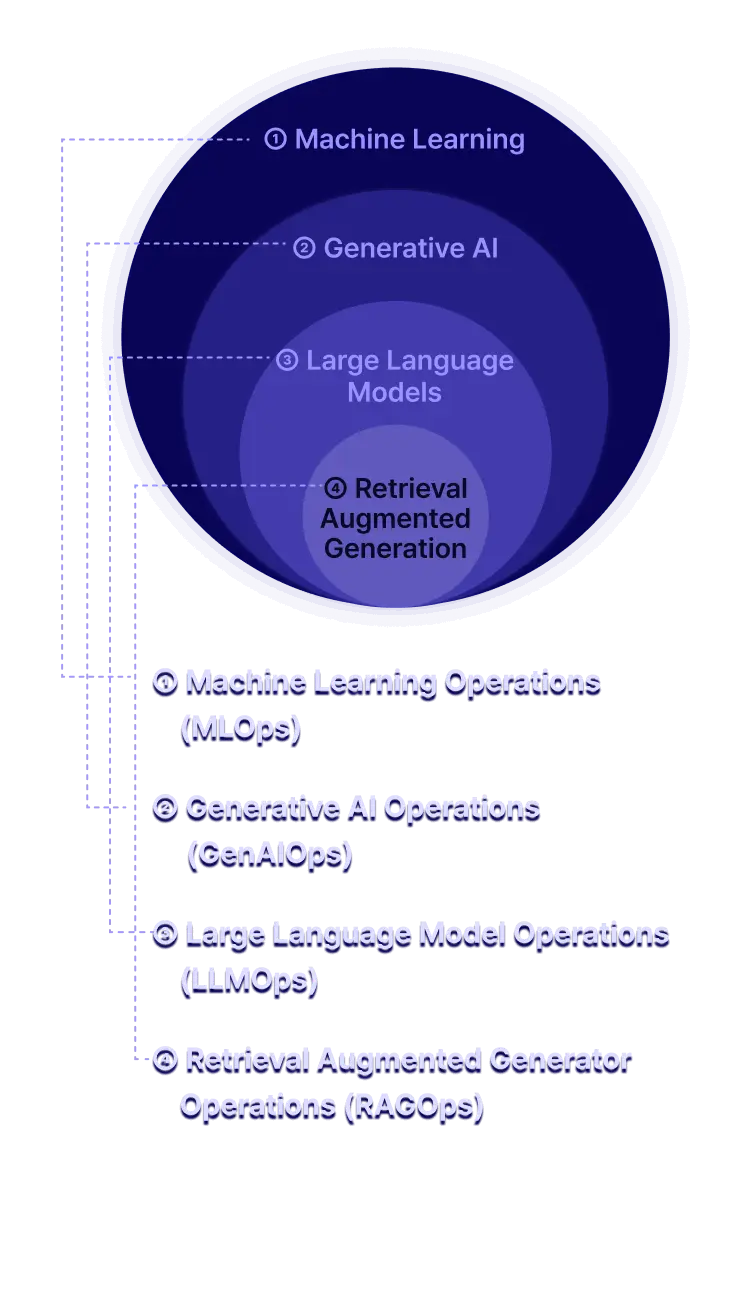


AI 서비스에 맞는
새로운 데이터 엔지니어링이 등장하게 된 이유는?
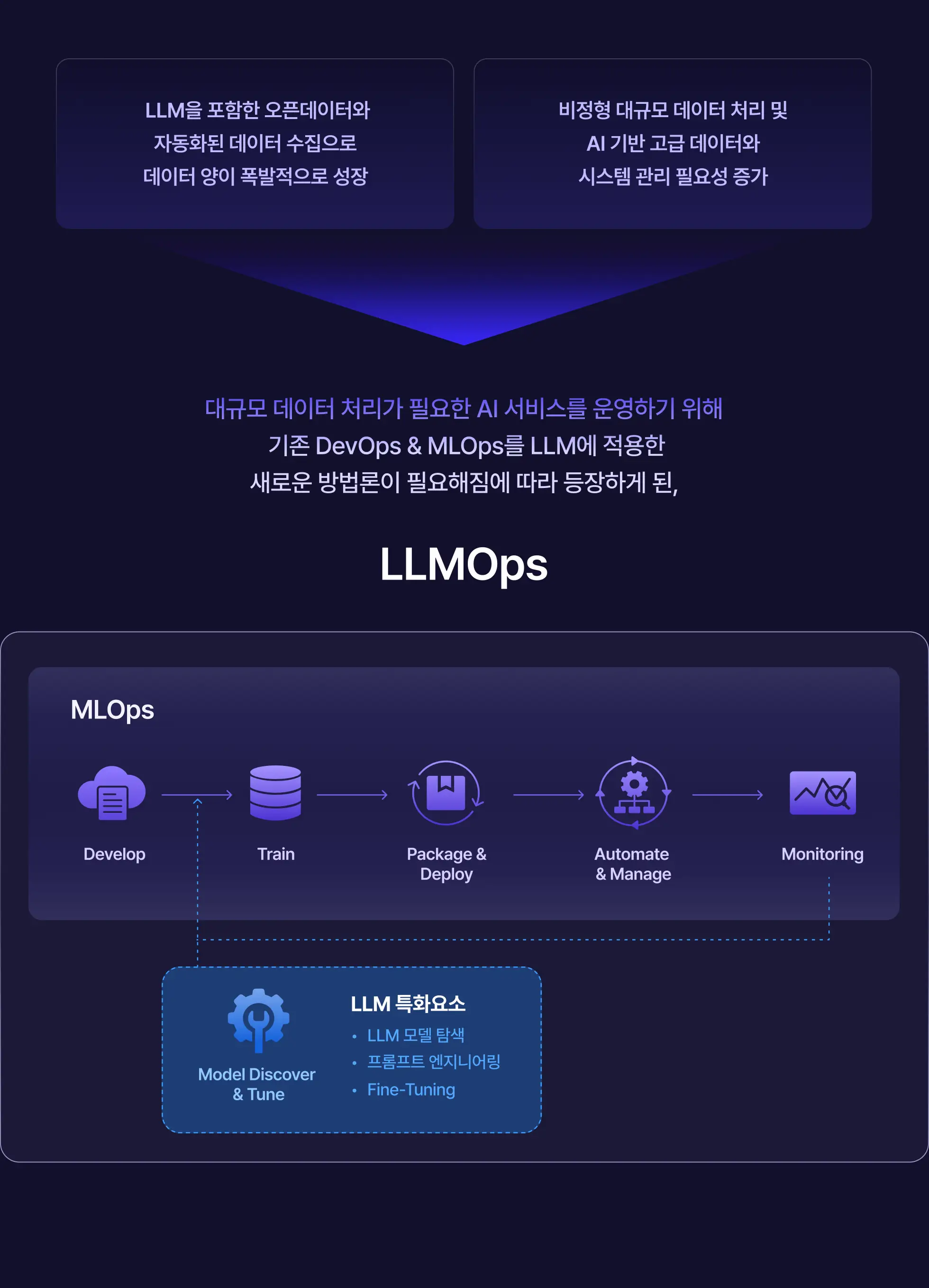
LLM 데이터 엔지니어링 구축 &
LLMOps 운영 프로세스 필요성
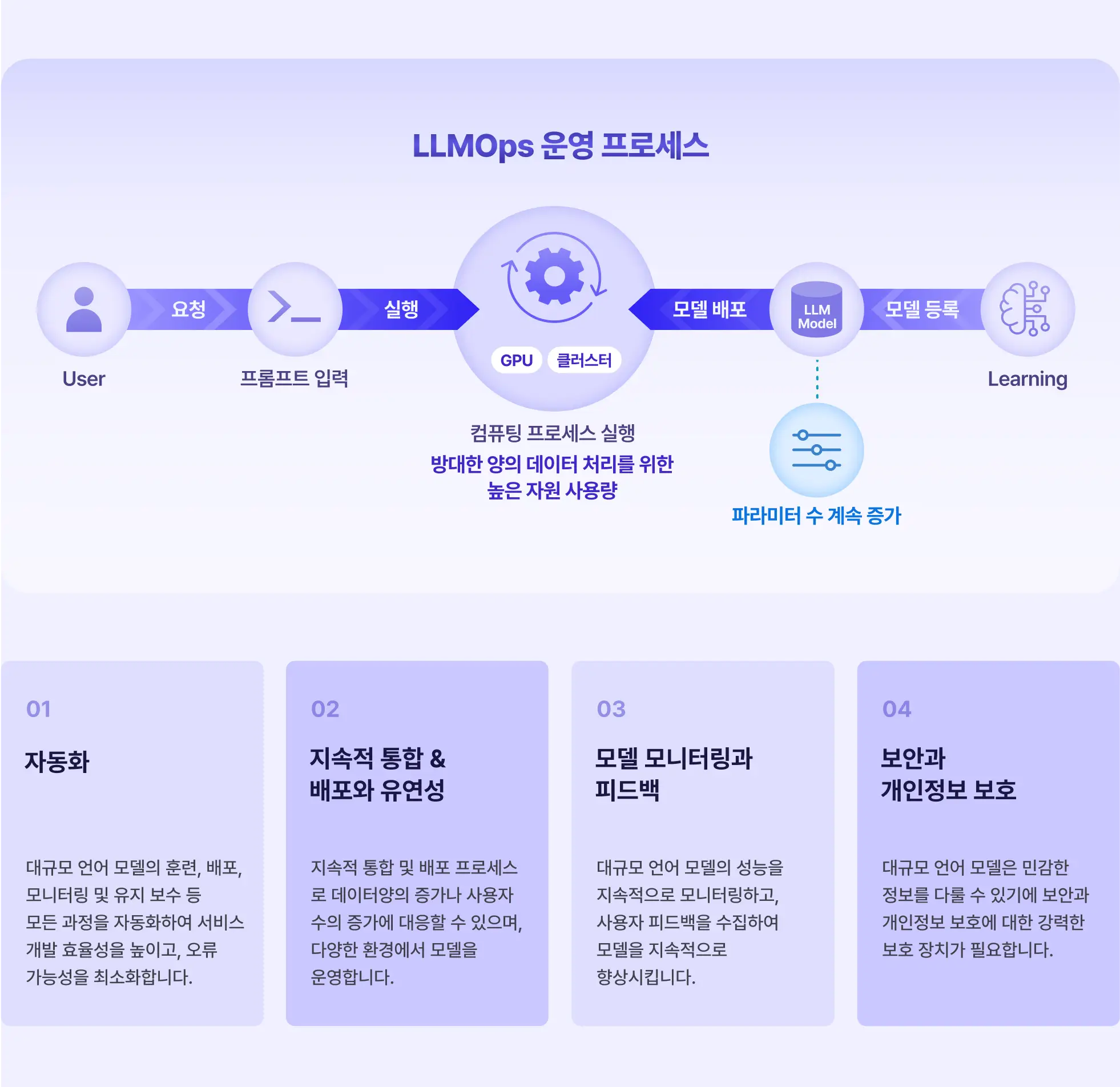
기존 MLOps 와 LLMOps 비교 분석하여 서비스 목적과 환경에 맞는
최적의 데이터 파이프라인을 구축할 수 있는 경험은 더더욱 중요해지고 있습니다.
그래서 준비했습니다.
대규모 데이터 서비스를 위한 LLMOps 와 LLM 기반 데이터 파이프라인 구축방법을
한번에 끝낼 수 있습니다.

AI 서비스를 위한 데이터 파이프라인 구축 고민을 모두 해결해줄
LLM 데이터엔지니어링 & LLMOps 강의 포인트 3가지!



한번에 끝내는 LLM 데이터 엔지니어링 & LLMOps
대규모 데이터를 효율적으로 수집, 큐레이션, 저장하기 위한 데이터 파이프라인을 설계하고
최적화하는 방법을 다루어보며, AI 서비스의 데이터 품질 모니터링과 관리까지 체계적으로 학습

Point 1
고급 데이터엔지니어링을 위한 LLM &
데이터 엔지니어링 핵심 개념 학습
LLM 기반의 고급 데이터 엔지니어링 솔루션을 위해 반드시 알고가야 할
데이터 엔지니어링 & LLM 의 핵심 개념과 기술, 툴에 대한 전반적인 내용을 학습합니다.
Data engineering
· LLM 기반 고급 데이터 엔지니어링 솔루션을 설계하고 구축하기 위해 반드시 알고가야 할 데이터 엔지니어링의 기본 개념을 학습합니다.
· 5가지 데이터 처리 주요 프레임워크와 핵심 개념, 기술 내용 살펴봅니다.

실시간 데이터 처리에서 메시지 큐로부터 실시간으로 읽어온 데이터를 가공하고 여러 데이터 저장소에 저장하는 역할을 담당하며, 데이터를 다루고 활용하는 법부터 application 운영까지 Streaming data를 처리하는 방법을 학습합니다.
· Transformation, Action, Lazy Evaluation
· RDD - 로그집계 파이프라인 & Spark UI
· Spark SQL, Dataframe, Dataset, Structured Streaming
· Event Time windows, Processing Time Windows
· Watermark
· Partitioning,Repartition, Coalesce,Caching, Persistence

대용량의 데이터를 안정적으로 전송할 수 있고, 필요에 따라 데이터를 생산하고 소비하는 역할에 활용되고 있으며, kafka의 기본 개념부터 Streaming pipeline 구성까지 배워봅니다.
· Topic, Partitions, Offset
· Producer, Message Keys
· Consumer, Deserialization
· Consumer Group, Consumer Offsets
· Brokers, Replication
· Zookeeper, Kraft

실시간 데이터 처리에서 배치성으로 동작하는 역할들을 효율적으로 스케쥴링하는데 가장 많이 활용되고 있습니다. Airflow의 Operator를 이해하고 Custom operator를 보다 자유롭게 구현할 수 있는 방법 등에 관한 내용을 학습합니다.
· DAG, task, operator
· template, branch
· Plugin & Connector
· airflow + spark

Apache Lucene기반의 Java 오픈소스 분산 검색 엔진으로, 방대한 양의 데이터를 신속하게, 거의 실시간( NRT, Near Real Time )으로 저장, 검색, 분석할 수 있습니다.
· 인덱스,문서,노드,클러스터
· CRUD
· 쿼리 DSL
· 분석기와 토큰필터
· 캐딩과 샤딩
· Kibana

Prometheus 는 시스템 및 서비스의 상태를 모니터링하는 인기 있는 오픈소스 모니터링 도구이며, Grafana 는 오픈소스 데이터 시각화 및 모니터링 도구로 애플리케이션의 성능을 모니터링하고 대시보드 등을 제공해주는 오픈소스 툴킷입니다.
· Prometheus pushgateway
· Output meta data monitoring
LLM
· LLM 정의를 기반으로 동작원리와 주요 모델들을 학습하며 서비스 목적에 적합한 모델을 선택하는 방법 배워봅니다.
· 데이터를 효과적인 LLM 모델 학습에 적합한 형태로 선별하는 과정을 학습합니다.

LLM 정의와 함께 동작원리와 대표 모델들을 비교해보면서 현업에서 LLM을 어떻게 활용하고 있는지 살펴봅니다.
· LLM 이란?
· LLM History (LLM 변천사)
· LLM 비즈니스 활용 사례
· LLM 동작 원리
· LLM 대표 모델 비교
· LLM 시대의 데이터 엔지니어링

LLM 기반 프로젝트의 구성 요소를 체계적으로 이해하고, 실제 프로젝트를 설계하고 구현하는데 필요한 주요 구성 요소를 단계적으로 학습합니다
· 임베딩 (Embedding)
· 다양한 임베딩 알고리즘 소개
· 벡터 데이터 다양한 임베딩 알고리즘 소개 (Vector Data base)
· Langchain & Pipeline 구축
· ChatGPT API 사용해보기
· 프롬프트 엔지니어링 & RAG

데이터를 효과적인 LLM 모델 학습에 적합한 형태로 선별하는 과정을 학습하고, 이 과정에서 준수해야 할 데이터 윤리는 어떤 것들이 있는지 배워봅니다.
· LLM 을 위한 데이터 셋
· LLM 학습 위한 데이터 수집
· 데이터 큐레이션 - LLM 학습 데이터셋 구성
Point 2
플랫폼 별 최적의 데이터 파이프라인 구축을 위한
MLOps 와 LLMOps 비교분석
MLOps와 LLMOps 비교 분석을 통해 LLM이 기존 머신러닝 모델과 비교했을 때 어떤 차이점이 있고,
이를 통해 데이터 파이프라인을 구축하고 운영하는 측면에서 어떤 관리 포인트의 차이점이 있는지 학습해봅니다.
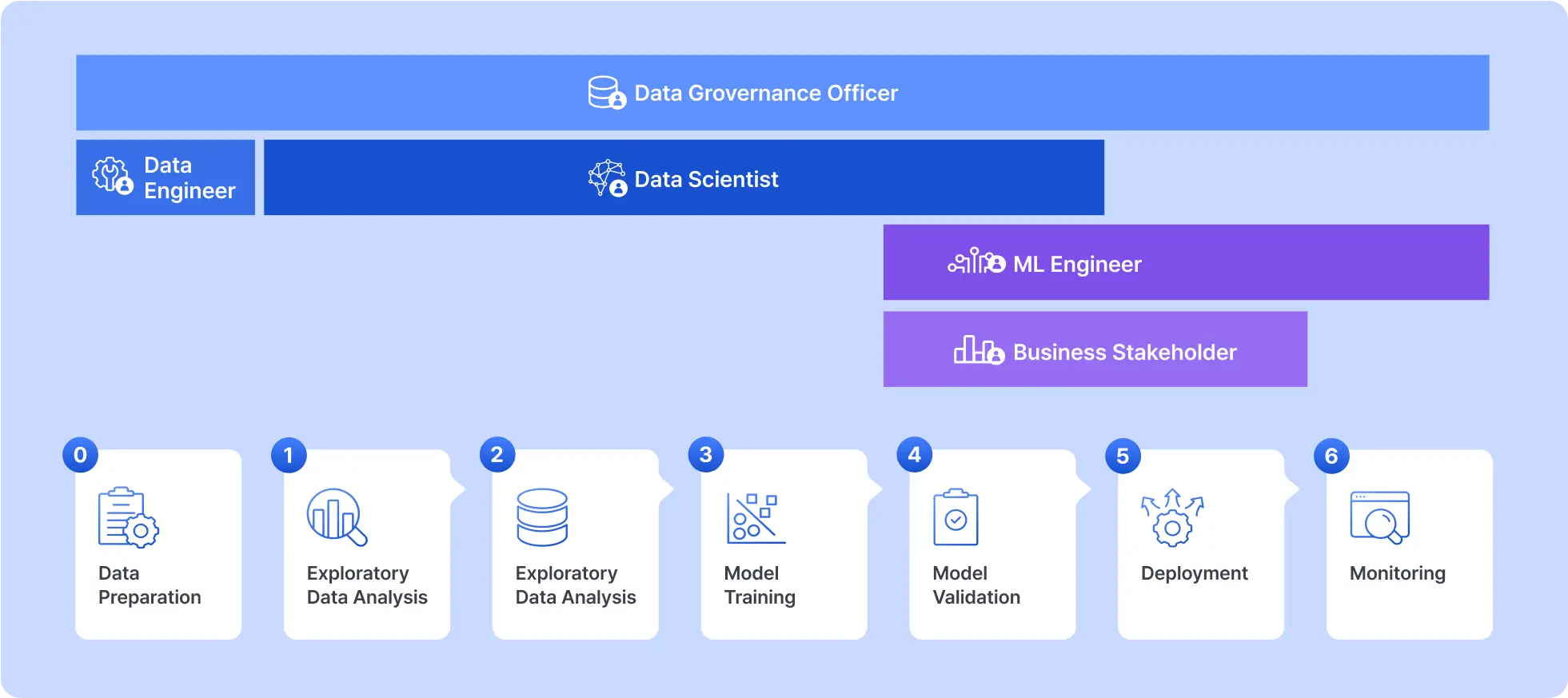
MLOps - ML & 데이터 엔지니어링
클라우드 환경에서의 MLOps를 설계하는 방법을 학습하고,
각 클라우드 플랫폼에서 제공하는 ML 플랫폼으로 서버 환경 별 MLOps 파이프라인을 구현합니다.
1px 선
STEP 1
MLFlow 설명 및 환경 구축
기존 MLOps 를 이해하고 구축하기 위해 필요한 MLFlow 프레임워크 개념을 학습하고 MLFlow 프레임워크 실습을 위한 로컬 환경 구축합니다.
· LLM 시대의 데이터 엔지니어링과 MLOps
· MLFlow 프레임워크 소개
· MLFlow 실습 위한 로컬 환경 구축
1px 선
STEP 2
MLFlow 프레임워크 실습
기존 머신러닝 학습, 운영, 배포를 체계적으로
관리하기 위한 프레임워크인 MLflow에 대해
학습합니다.
· MLFlow 실습 01 - Tracking
· MLFlow 실습 02 - Logging
· MLFlow 실습 03 - Modeling
· MLFlow 실습 04 - Model Registry
1px 선
STEP 3
Feature Store
LLM을 기반으로 데이터 준비부터 모델 학습,
배포, 모니터링, 최적화까지의 전체 워크플로우를 실습합니다.
· Feature store 개요, 필요성
· Feast 프레임워크 소개
· 로컬 환경 구축
· Feast 로컬 실습
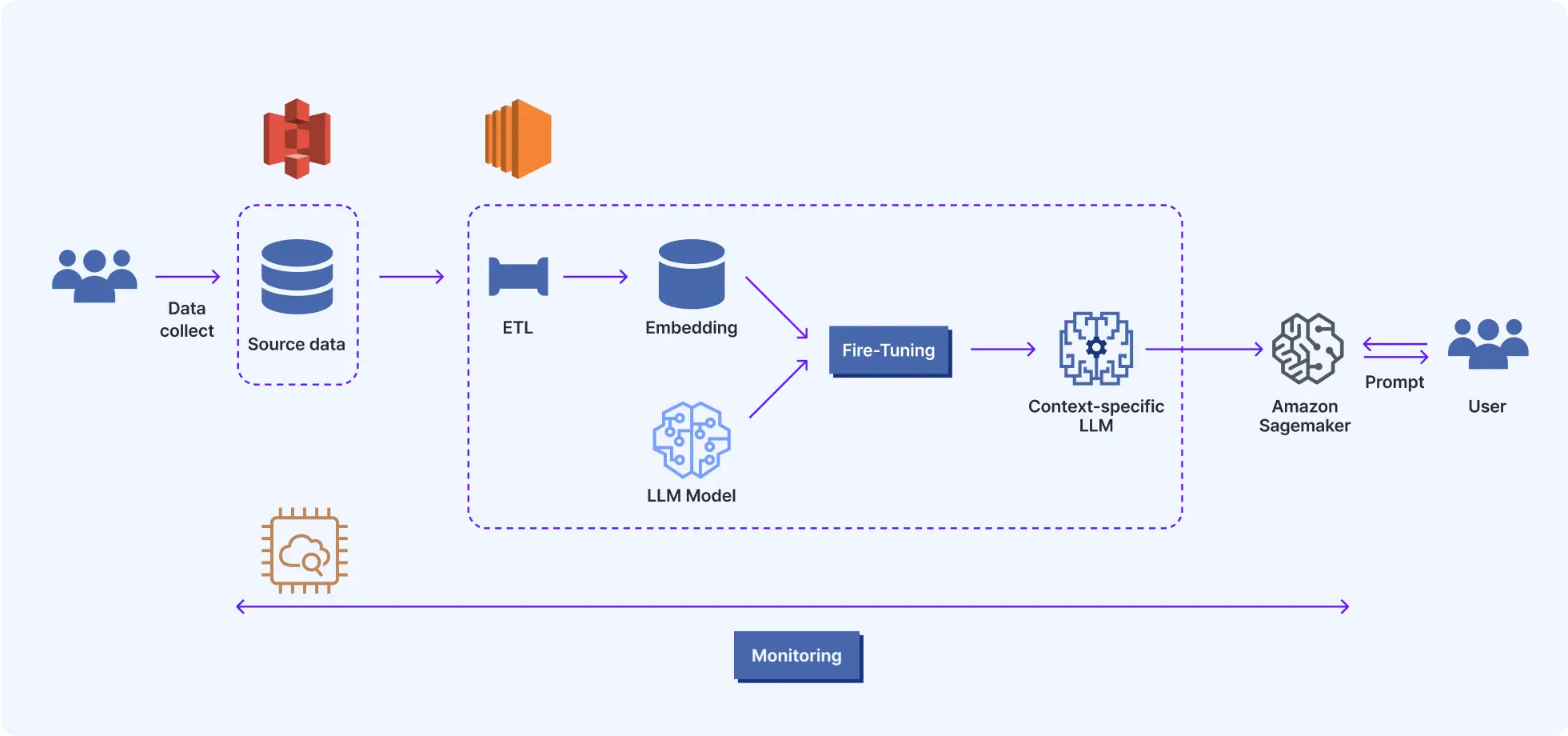
LLMOps - LLM & 데이터 엔지니어링
LLM 학습, 운영, 배포를 체계적으로 관리하기 위한 프레임워크인 LLMflow에 대해 학습해보고,
이를 기반으로 데이터 준비부터 모델 학습, 배포, 모니터링, 최적화까지의 전체 워크플로우를 실습합니다.
1px 선
STEP 1
LLMOps 소개
LLM을 운영하고 관리하기 위한 실무 접근법인 LLMops가 무엇인지 배워보고, MLOps와 LLMOps 차이를 비교해봅니다.
· LLMOps 개념 및 필요성
· LLMOps vs MLOps: 주요 차이점
· LLMOps의 핵심 구성 요소
1px 선
STEP 2
LLMFlow 프레임워크
LLM 학습, 운영, 배포를 체계적으로 관리하기 위한 프레임워크인 LLMflow에 대해 학습합니다.
· LLMFlow의 정의와 필요성
· LLMFlow의 구성 요소 - 데이터 준비, 모델학습,
배포 및 모니터링
· LLMFlow장점과 활용 사례
1px 선
STEP 3
LLMFlow 실습
LLM을 기반으로 데이터 준비부터 모델 학습, 배포, 모니터링, 최적화까지의 전체 워크플로우를 실습합니다.
· 환경 설정 (python,aws 등)
· 데이터 수집 및 업로드
· Fine-tuning 실습
· 모델 배포 (sagemaker, FastAPI)
· 모니터링 및 최적화 (CloudWatch)
Point 3
LLM 데이터 파이프라인 구축 통한
AI application 개발 실습
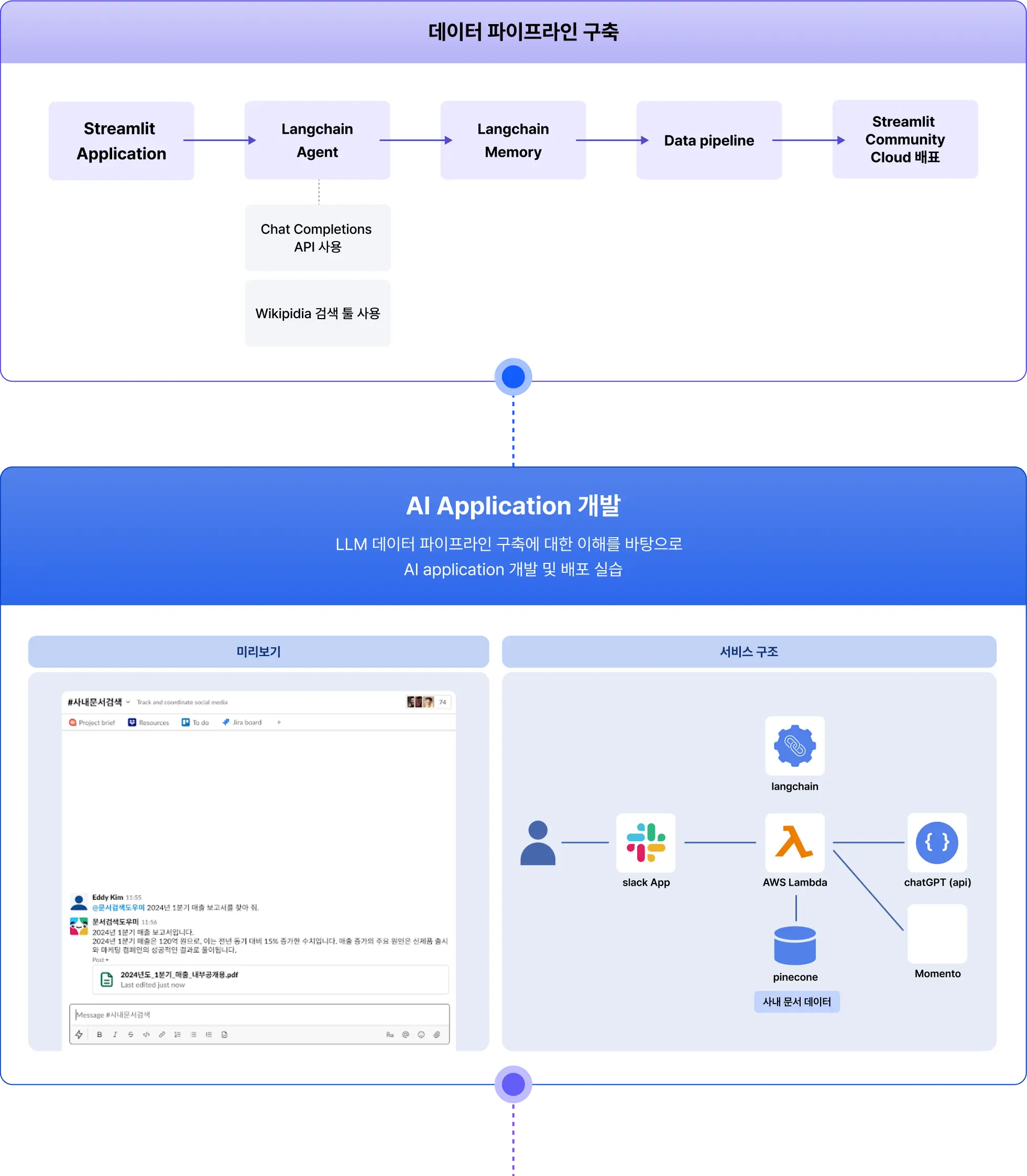
LLM 기반 데이터 파이프라인을 직접 구축해보고 실제 LLM모델에 fine tuning을 적용하여
사내 문서를 기반으로 답변하는 Slack 기반의 application을 개발합니다.






추천 수강 대상





