
핵심 01.
30시간으로 완성하는
체계적인 파인튜닝 로드맵
NLP 기초부터 RAG, 파인튜닝, 데이터 전처리, LLM 서빙까지
파인튜닝을 중심으로 맞춤형 LLM 서비스 개발 과정을 학습합니다.
파인튜닝과 RAG로 완성하는 맞춤형 LLM 서비스 개발
파인튜닝과 RAG,
모든 성공은 데이터에서 시작됩니다.
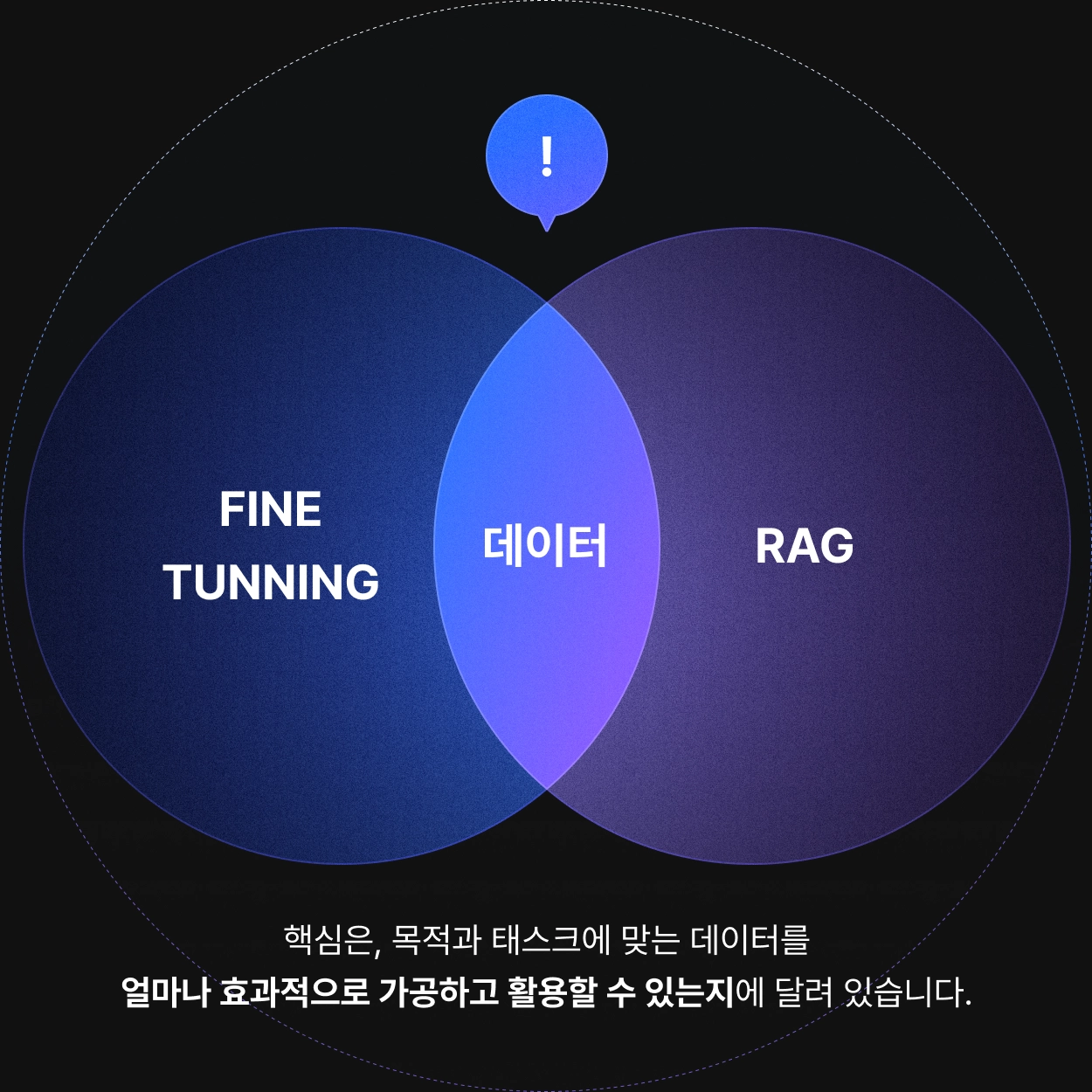

준비된 다양한 프로젝트를 통해
목적과 태스크에 맞는 데이터 가공 방법을 학습하세요!
01. 강의 정보 및 혜택

핵심 02.
8개 프로젝트로 완성하는
도메인 맞춤형 파인튜닝 ft. RAG
NLP 현업에서 가장 자주 사용되는
8개의 상황(Task)별 파인튜닝 방법을 학습합니다.
8개 프로젝트로 완성하는
도메인 맞춤형 파인튜닝 ft. RAG
NLP 현업에서 가장 자주 사용되는
8개의 상황(Task)별 파인튜닝 방법을 학습합니다.
핵심 03.
클라우드 기반 실습으로
현업과 동일한 실무 경험 제공
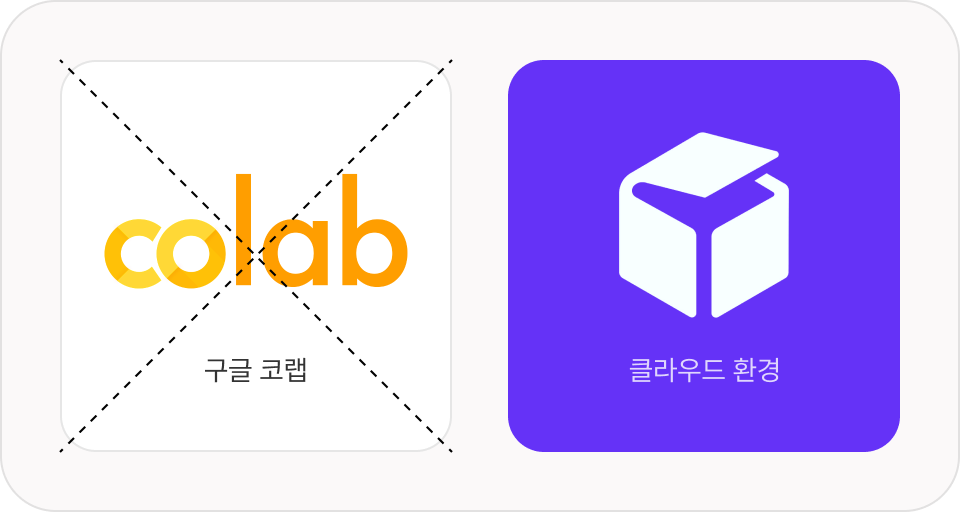
NLP 구글 코랩이 아닌, 현업과 동일한
클라우드 환경에서의 파인튜닝을 경험을 제공합니다.
클라우드 기반 실습으로
현업과 동일한 실무 경험 제공
NLP 구글 코랩이 아닌, 현업과 동일한
클라우드 환경에서의 파인튜닝을 경험을 제공합니다.
핵심 04.
2인의 베스트셀러 저자와
직접 주고 받는 질의응답 커뮤니티
NLP 질의응답부터 특급 자료 공유까지,
수강생만을 위한 전용 커뮤니티에 참여해보세요.
2인의 베스트셀러 저자와
직접 주고 받는 질의응답 커뮤니티
NLP 질의응답부터 특급 자료 공유까지,
수강생만을 위한 전용 커뮤니티에 참여해보세요.
02. 강사 소개
파인튜닝을 가장 쉽게 설명하는
베스트셀러 저자 2인

25년 1월 기준 위키독스 추천수 2위

25년 1월 교보문고 주간 베스트
업계에서 인정받는
두 전문가의 3가지 특별함
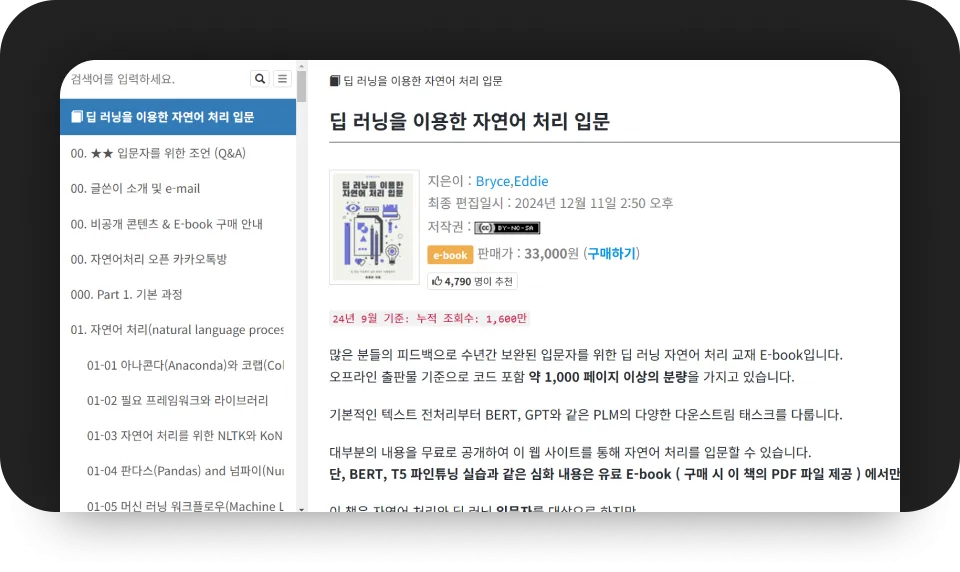
특별함 01.
누적 조회수 1,720만을 자랑하는
’딥 러닝을 이용한 자연어 처리 입문’ 저자
위키독스 추천수 2위
*25년 1월 기준 : 누적 조회수 1,720만 무료 전자책 바로가기 →
누적 조회수 1,720만을 자랑하는
’딥 러닝을 이용한 자연어 처리 입문’ 저자
위키독스 추천수 2위
*25년 1월 기준 : 누적 조회수 1,720만 무료 전자책 바로가기 →

 인공지능 연구방 바로가기 →
인공지능 연구방 바로가기 →

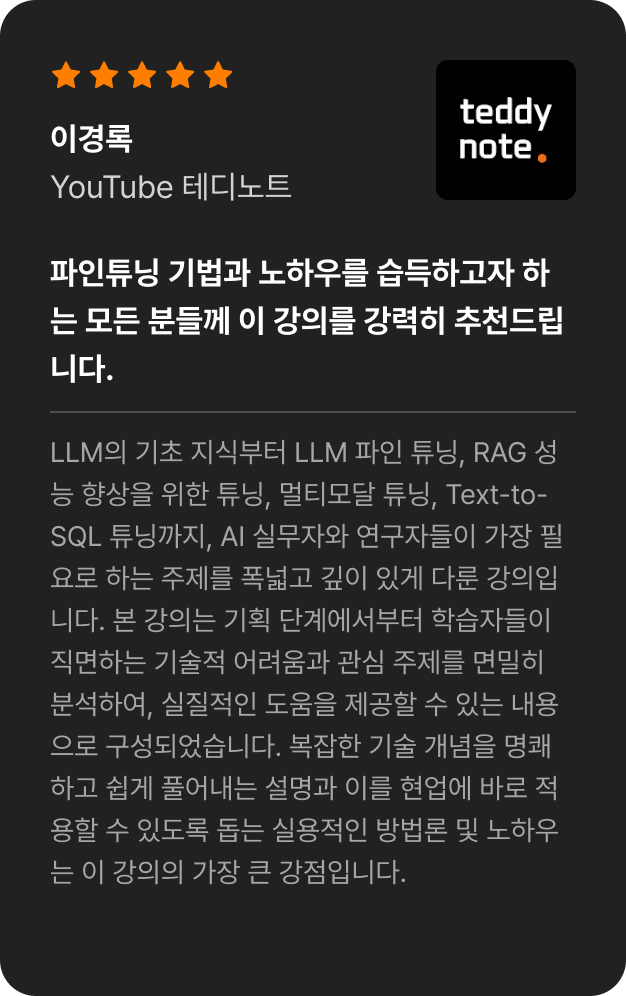
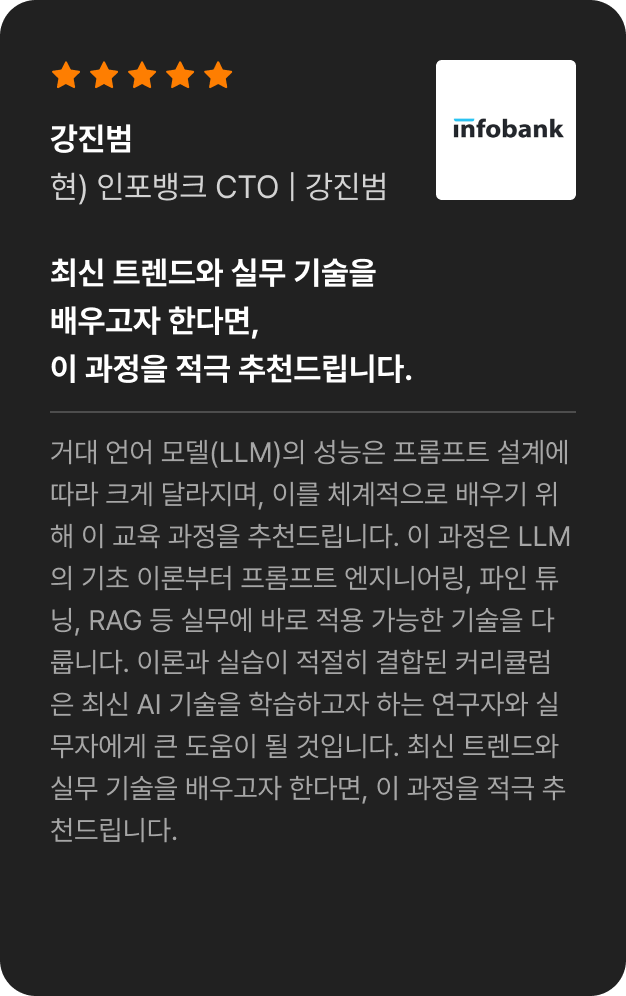
특별함 03.
테디노트를 비롯한
업계 전문가들의 강력한 추천 조희열 | 테디님 | 김수종 | 강진범
테디노트를 비롯한
업계 전문가들의 강력한 추천 조희열 | 테디님 | 김수종 | 강진범


03. 커리큘럼 상세 소개
맞춤형 파인튜닝을 위한 개념 학습
01. LLM을 위한 기초 NLP 개념
LLM 서비스 개발의 기초가 되는 기본적인 NLP 지식과 언어모델의 구조를
이해하며 현업 문제 해결 접근법을 학습합니다.
| 학습 내용
 LLM을 위한 기초 지식
- Langchain 기반 RAG
LLM을 위한 기초 지식
- Langchain 기반 RAG
- ReAct와 Function Calling
LLM 파인 튜닝 입문하기
- Pre-training, Fine-tuning, LoRA, QLoRA, SFT, DPO
- Paged Attention과 vLLM
LLM 서비스 개발의 기초가 되는 기본적인 NLP 지식과 언어모델의 구조를
이해하며 현업 문제 해결 접근법을 학습합니다.
| 학습 내용
LLM을 위한 기초 지식
- ReAct와 Function Calling
LLM 파인 튜닝 입문하기
- Paged Attention과 vLLM
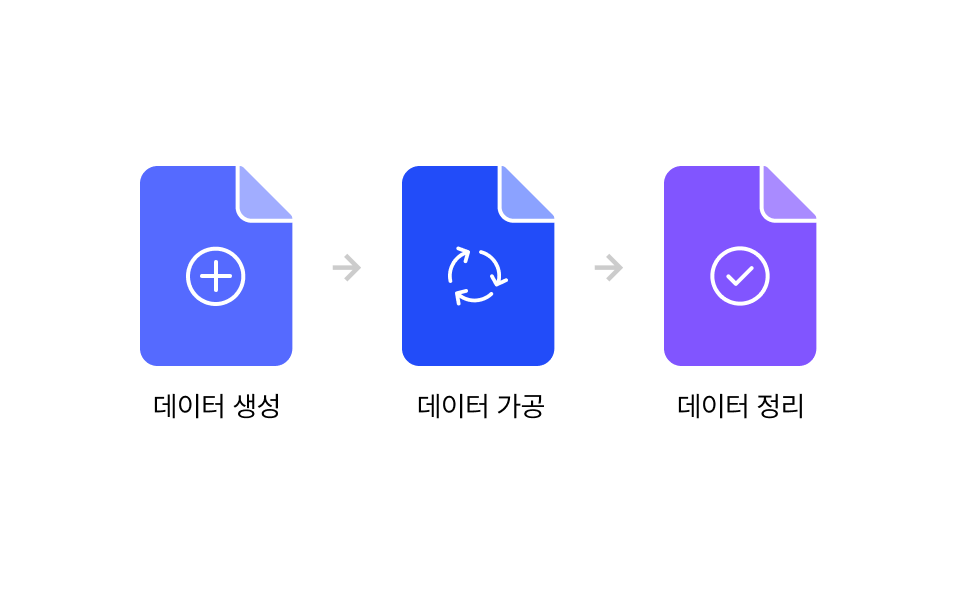
02. 문제 해결을 위한 데이터 가공
LLM 서비스 도메인 맞춤형 데이터를 준비하는 과정에 초점을 맞춥니다. 데이터 수집, 전처리, 정제, 그리고 구조화된 데이터셋을 만드는 방법을 다룹니다.
| 학습 내용
문제 분해와 단순화 전략
데이터 증강 및 레이블링
도메인 특화 데이터 전처리
실제 사례 기반 문제 해결
LLM 서비스 도메인 맞춤형 데이터를 준비하는 과정에 초점을 맞춥니다. 데이터 수집, 전처리, 정제, 그리고 구조화된 데이터셋을 만드는 방법을 다룹니다.
| 학습 내용
문제 분해와 단순화 전략
데이터 증강 및 레이블링
도메인 특화 데이터 전처리
실제 사례 기반 문제 해결
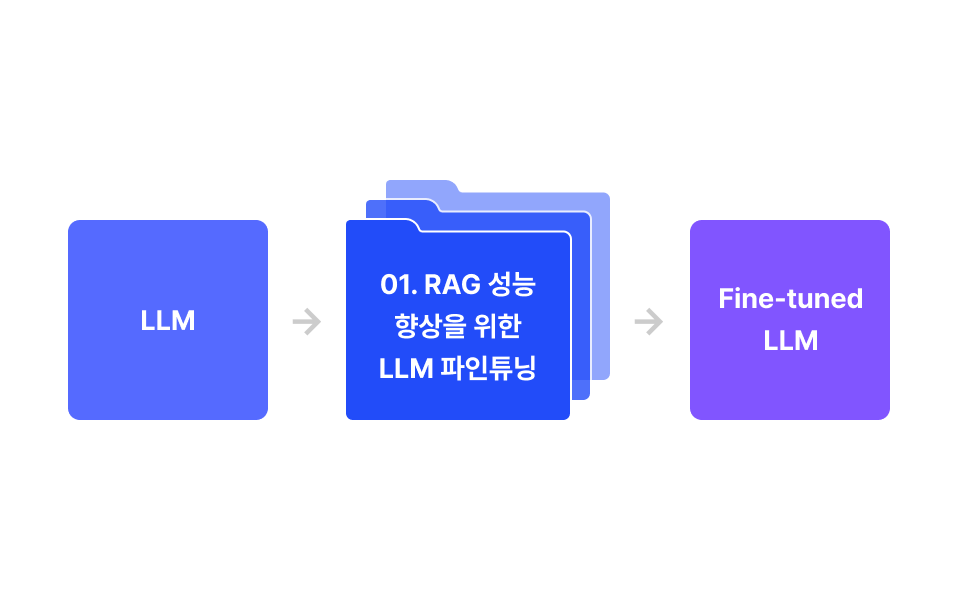
03. 도메인 맞춤형 파인튜닝 ft.RAG
8가지 태스크에 맞는 LLM 파인튜닝 기법을 학습합니다.
파인튜닝 기법과 데이터 커스터마이징의 실무적인 접근법을 학습합니다.
| 학습 내용
RAG 성능 향상을 위한 LLM 파인 튜닝
이미지를 인식하는 멀티모달 파인 튜닝
고객 응대 에이전트 파인 튜닝
··· 외 5개 프로젝트
8가지 태스크에 맞는 LLM 파인튜닝 기법을 학습합니다.
파인튜닝 기법과 데이터 커스터마이징의 실무적인 접근법을 학습합니다.
| 학습 내용
RAG 성능 향상을 위한 LLM 파인 튜닝
이미지를 인식하는 멀티모달 파인 튜닝
고객 응대 에이전트 파인 튜닝
··· 외 5개 프로젝트
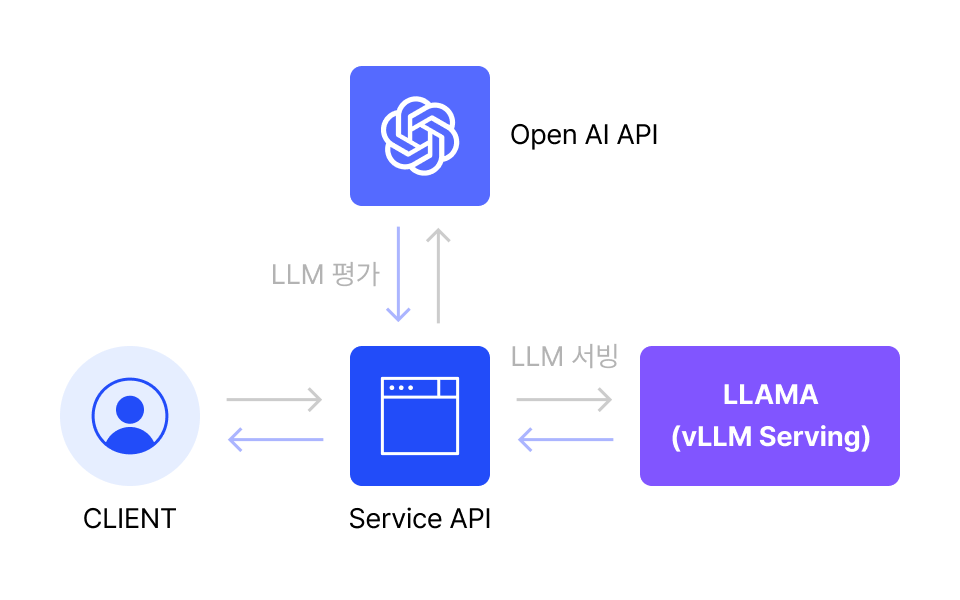
04. 평가와 서빙
다양한 도메인에서의 파인튜닝 적용 사례를 학습하며, LLM 평가와 서빙을 통해 서비스를 실제 환경에 통합하는 방법을 학습합니다.
| 학습 내용
OpenAI API를 활용한 성능 평가
vLLM을 이용한 모델 서빙
다양한 도메인에서의 파인튜닝 적용 사례를 학습하며, LLM 평가와 서빙을 통해 서비스를 실제 환경에 통합하는 방법을 학습합니다.
| 학습 내용
OpenAI API를 활용한 성능 평가
vLLM을 이용한 모델 서빙
현업에서 가장 필요한 도메인과
태스크를 담은 8개의 실전 프로젝트와 함께합니다.
모든 실습은 유료 클라우드 환경에서 진행되며, 실제 업무와 동일한 실무 경험을 제공합니다.

모든 프로젝트 실습은
아래 4단계 프로세스에 따라 진행됩니다.





파인튜닝의 결과를 좌우하는 핵심 요소는
Task에 맞는 데이터를 준비하고 가공하는 과정에 있습니다.

8개의 실전 프로젝트로 완성하는
현업 Task 중심 파인튜닝
8개의 프로젝트를 통해 현업에서 가장 필요한
Task와 Domain에 따른 파인튜닝 과정을 학습할 수 있습니다.
CASE 01.
데이터 구조화 (아웃풋 커스터마이징)
방대한 데이터를 처리하고 핵심 내용을 요약하거나
데이터베이스에서 필요한 정보를 커스터마이징하는 기술을 학습합니다.
데이터베이스에서 필요한 정보를 커스터마이징하는 기술을 학습합니다.
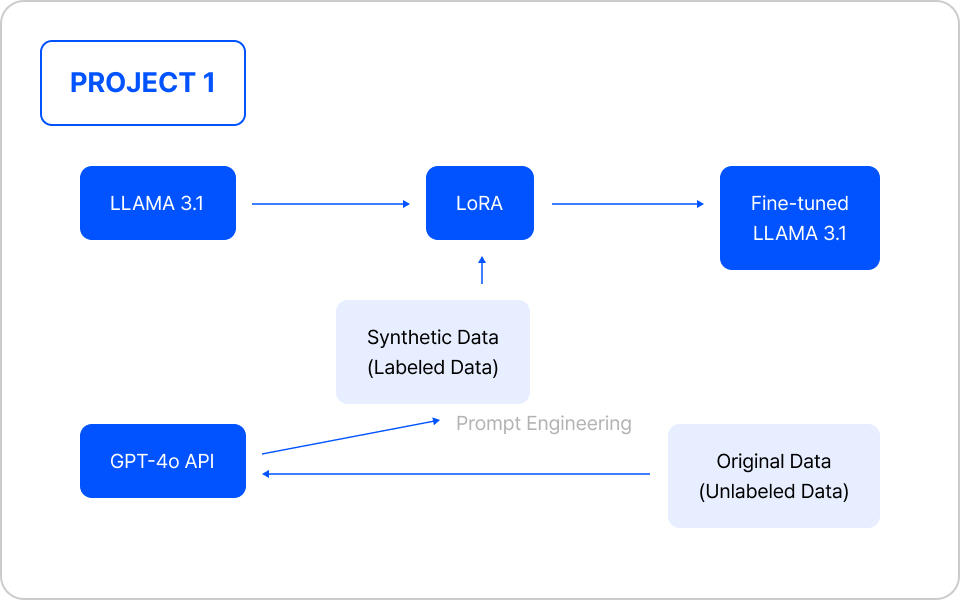
파인 튜닝을 통한 구조화된 요약 모델 만들기
| 주요 학습 포인트
- 비즈니스 문제 정의와 합성 데이터 생성 전략 수립
- 프롬프트 엔지니어링과 LoRA 기반 모델 학습
- 정량적 평가 지표 설계와 성능 분석 방법론
- vLLM 기반 실시간 추론 시스템 구축 및 운영

실습 프로세스 자세히보기
01. No-Data 상황에서의 문제 정의와 데이터 전략
- 해결하고자 하는 비즈니스 문제를 정의하고 필요한 데이터의 종류와 범위 파악
- LLAMA 3.1 모델을 활용해 다양한 시나리오의 합성 데이터 생성
- 유사 도메인의 공개 데이터를 분석하여 Seed 데이터 구축
02. LLAMA 3.1 프롬프트 최적화 및 LoRA 튜닝
- Chain of Thought 프롬프트 템플릿 설계 및 단계별 프롬프트 구성
- LLAMA 3.1 모델에 LoRA 방식을 적용한 파인튜닝 프로세스 구현
- 설계된 프롬프트와 LoRA 기반의 모델 학습 진행
03. 성능 평가
- 데이터와 모델의 성능을 측정할 수 있는 정량적 평가 지표 선정
- 서비스 목적에 부합하는 성능 기준과 평가 방법론 수립
- 정의된 메트릭에 따른 모델 성능 분석
04. 실시간 추론 시스템 구축
- LLAMA 3.1 모델의 vLLM 기반 서빙 시스템 구현
- 전처리부터 추론, 후처리까지 전체 파이프라인 구성
- 실제 서비스 환경에서의 안정적인 운영 아키텍처 설계
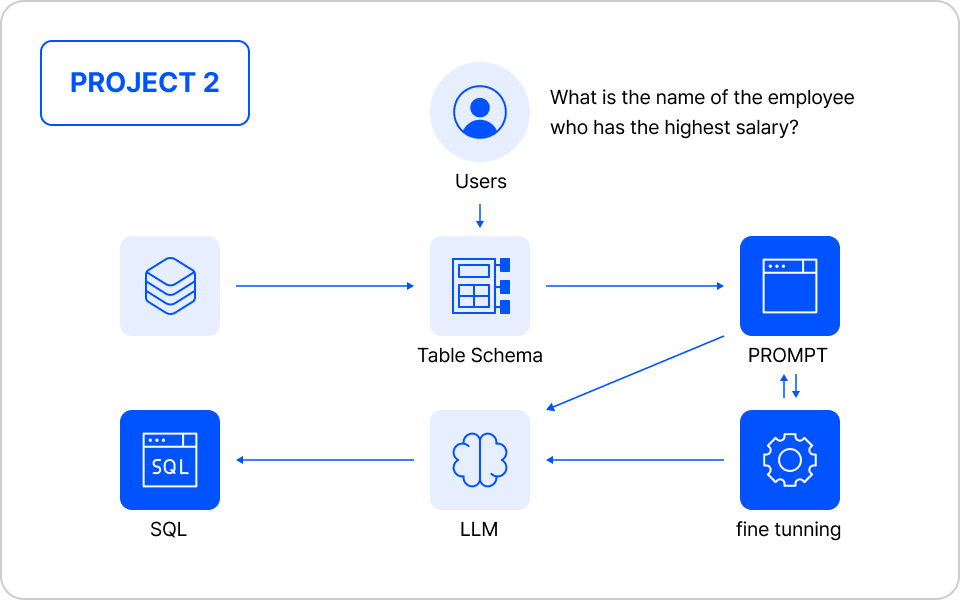
Text-to-SQL 파인 튜닝
| 주요 학습 포인트
- Text-to-SQL 기술의 핵심 개념과 데이터 전처리
- LoRA 기반 Qwen-2.5-coder 모델 Fine-tuning
- SQL 쿼리 변환 성능 평가
- vLLM 기반 Text-to-SQL 시스템 구축 및 운영

실습 프로세스 자세히보기
01. 데이터셋 준비 및 가공
- Text-to-SQL 기술의 주요 개념과 활용 사례 학습
- Qwen-2.5-coder 모델의 구조 및 기능 이해
- 자체 번역 및 구축한 Text-to-SQL 데이터셋 분석
- 한국어 기반 자연어 질의와 SQL 쿼리 간의 매핑 데이터 전처리
02. 성능 향상을 위한 파인튜닝
- - LoRA(Low-Rank Adaptation) 기법의 이론 및 적용 방법 학습
- Qwen-2.5-coder 모델에 LoRA를 적용하여 효율적인 파인튜닝 진행
03. 성능 평가
- OpenAI API를 활용한 SQL 쿼리 성능평가
04. 구현 및 서빙하기
- vLLM 서빙 시스템 구현
CASE 02.
대화 시스템 개발
사용자와의 자연스러운 소통을 목표로 하는 대화형 AI를 설계하고,
특정 도메인에 맞춘 응답을 생성할 수 있는 맞춤형 모델을 개발합니다.
특정 도메인에 맞춘 응답을 생성할 수 있는 맞춤형 모델을 개발합니다.
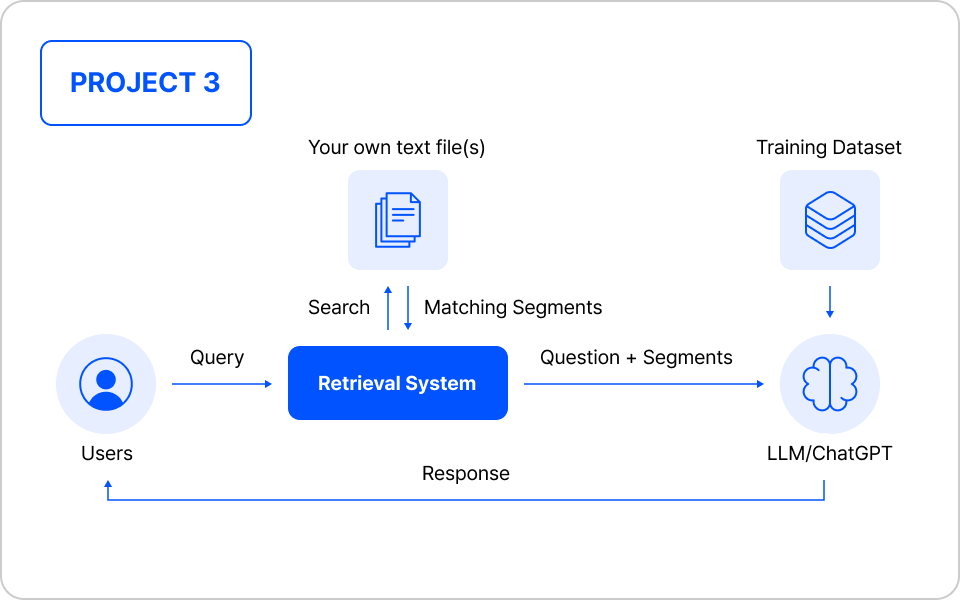
페르소나 챗봇 구현을 위한 파인 튜닝 (캐릭터 챗봇)
| 주요 학습 포인트
- RAG와 Fine-tuning의 결합을 통한 페르소나 챗봇 설계
- Memory/Training 데이터셋 구축 및 검증 방법론
- 페르소나 일관성과 응답 품질 평가 기준 수립
- vLLM 기반 페르소나 챗봇 서빙 시스템 구현

실습 프로세스 자세히보기
01. Persona Chatbot 아키텍처 설계
- RAG와 Fine-tuning의 결합 필요성 분석
- Persona Chatbot의 구조적 특징 이해
- Memory와 Training 데이터의 역할 구분
02. Persona Chatbot 데이터 구축
- Memory Dataset 구조화 및 구축
- Training Dataset 설계 및 구축
- 데이터 정제 및 검증
03. 성능 평가
- Persona 일관성 평가 지표 설정
- 응답 품질 측정 기준 수립
- 평가 결과 분석
04. vLLM 기반 추론 시스템 구축
- vLLM 서빙 시스템 구현
- 추론 파이프라인 구성
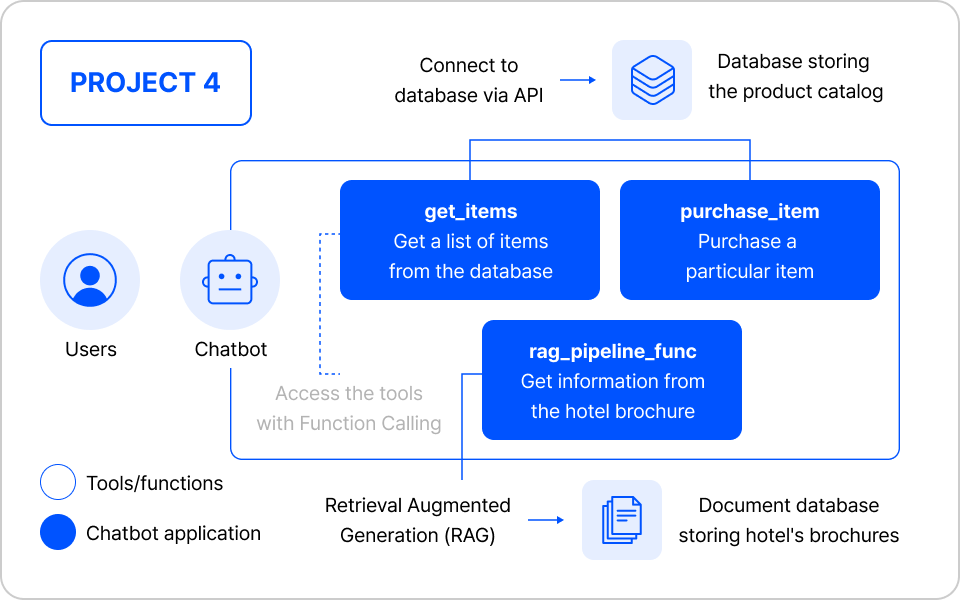
고객 응대 에이전트 파인 튜닝 (E-commerce)
| 주요 학습 포인트
- ReAct와 Function Calling 방식의 에이전트 설계 전략
- E-commerce 도메인 특화 학습 데이터셋 구축 방법
- 에이전트 응답 정확도와 고객 응대 품질 평가
- vLLM 기반 에이전트 챗봇 서빙 시스템 구현

실습 프로세스 자세히보기
01. 에이전트 구현 방식 분석
- ReAct 방식의 특징과 장단점 분석
- Function Calling 방식의 특징과 장단점 분석
02. 에이전트 학습 데이터 구축
- E-commerce 도메인 데이터 수집
- 고객 응대용 Training Dataset 정제
- 데이터 검증 및 보완
03. 성능 평가
- 에이전트 응답 정확도 평가
- 고객 응대 품질 측정
- 평가 결과 분석
04. vLLM 기반 추론 시스템 구축
- vLLM 서빙 시스템 구현
- 추론 파이프라인 구성
CASE 03.
RAG 성능 개선 및 최적화
LLM을 최적화하여 특정 작업에서
더욱 높은 정확도와 효율성을 제공하는 방법을 배웁니다.
더욱 높은 정확도와 효율성을 제공하는 방법을 배웁니다.
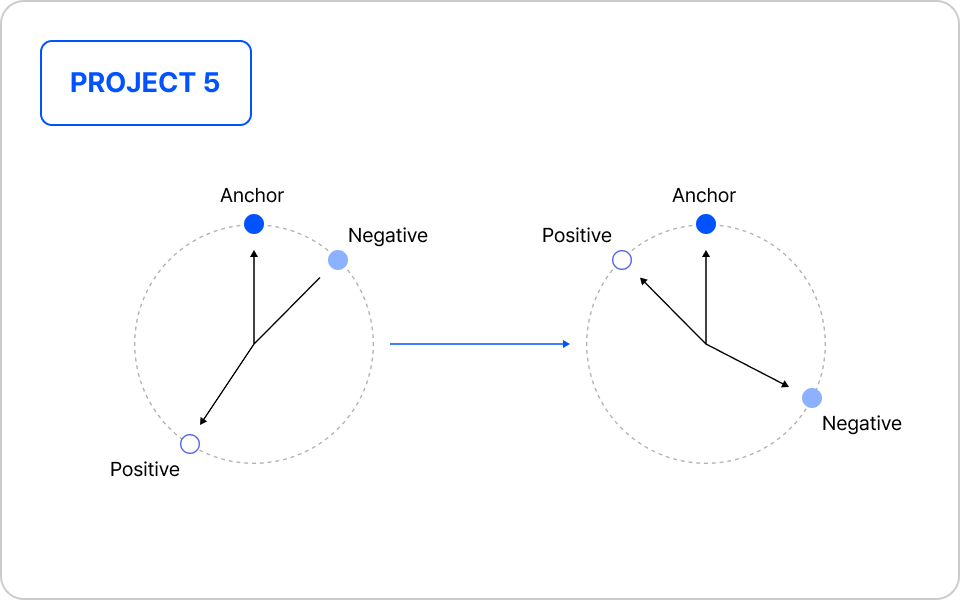
RAG를 위한 임베딩 파인 튜닝
| 주요 학습 포인트
- Positive/Negative Sample을 활용한 QA 데이터셋 구축
- Huggingface 임베딩 모델의 Fine-tuning 프로세스
- 검색 성능 평가 및 최적 모델 선정 방법론
- Fine-tuned 임베딩 모델 기반 실시간 검색 시스템 구현

실습 프로세스 자세히보기
01. 임베딩 모델 학습을 위한 데이터 구축 전략
- 임베딩 학습에 필요한 Positive/Negative Sample의 특성 이해
- QA 데이터셋 구조와 형식 분석
- 학습 데이터 구축 방안 수립
02. Huggingface 임베딩 모델 Fine-tuning
- Fine-tuning을 위한 학습 환경 구성
- 검색 성능 향상을 위한 Fine-tuning 수행
- Fine-tuned 모델 저장 및 관리
03. 성능 평가
- Fine-tuning 전후 성능 비교 분석
- 평가 결과 기반 모델 선정
04. 실시간 검색 시스템 구축
- Fine-tuned 임베딩 모델 서빙 구현
- 검색 파이프라인 구성
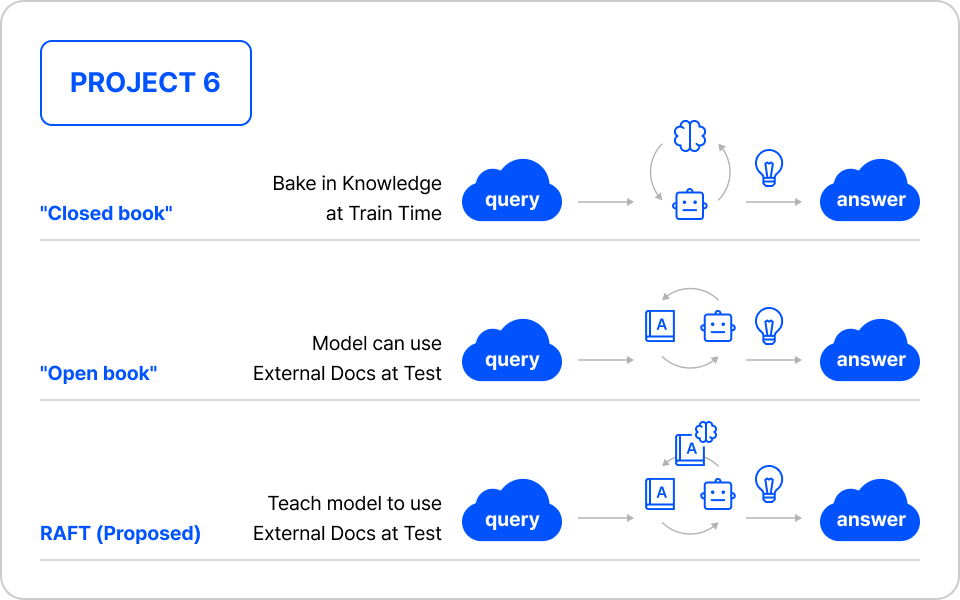
RAG 성능 향상을 위한 LLM 파인 튜닝
| 주요 학습 포인트
- RAFT 논문의 핵심 내용과 현업 적용 포인트 분석
- 도메인 데이터 기반 RAG Fine-tuning 데이터셋 구축
- 정량적/정성적 RAG 성능 평가 방법론 습득
- RAG 특화 모델의 추론 파이프라인 구현 및 서빙

실습 프로세스 자세히보기
01. RAG 파인 튜닝 논문: RAFT 논문의 핵심 분석
- RAG 특화 모델의 주요 특징 이해
- Cohere, Orion 등 다양한 적용 사례 분석
02. RAG 학습 데이터 구축
- 도메인 데이터 기반 RAG 학습 데이터 정제
- RAG Fine-tuning 데이터셋 구조화
- 데이터 품질 관리 방안 수립
03. 성능 평가
- RAG 모델의 정량적 평가 지표 설정
- Fine-tuning 전후 성능 비교
04. RAG 모델 학습 및 서빙
- 학습된 RAG 모델의 추론 파이프라인 구성
- 서비스 환경 구축
CASE 04.
특정 산업 및 도메인 적용
특정 산업이나 데이터 유형에 특화된 AI 모델을 설계하여,
다양한 도메인의 문제를 해결할 수 있는 방법을 익힙니다.
다양한 도메인의 문제를 해결할 수 있는 방법을 익힙니다.
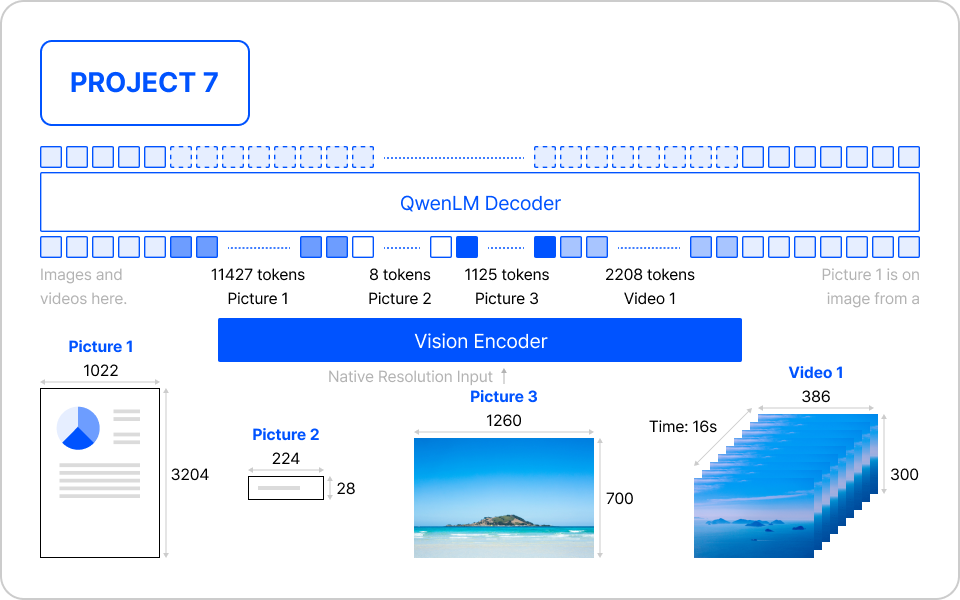
이미지를 인식하는 멀티모달 파인 튜닝
| 주요 학습 포인트
- Qwen2-VL-Chat의 멀티모달 데이터 처리 구조 이해
- LoRA 기반 효율적 Fine-tuning 방법론 습득
- MMHS150K 데이터셋의 혐오 표현 유형별 분석 실습
- vLLM 기반 멀티모달 분석 시스템 구축 및 평가

실습 프로세스 자세히보기
01. 데이터셋 준비 및 가공
- 멀티모달 데이터 처리 개념 학습
- Qwen2-VL-Chat 모델의 구조와 특징 분석
- MMHS150K 혐오 표현 유형별(인종차별, 성차별, 동성애 혐오, 종교 기반 공격 등) 데이터 분류
- 텍스트와 이미지 데이터를 모델 입력 형식에 맞게 전처리
02. 성능 향상을 위한 파인튜닝
- LoRA 기법의 이론 학습 및 구현 방법 이해
- Qwen2-VL-Chat 모델에 LoRA 적용하여 혐오 표현 탐지를 위한 파인튜닝 수행
03. 성능평가
- 멀티모달 데이터를 활용한 모델을 OpenAI API로 성능 평가
04. 구현 및 서빙하기
- vLLM으로 서빙하기

개인정보 비식별화 모델 파인 튜닝 (금융 데이터)
| 주요 학습 포인트
- 금융 데이터의 민감 정보 식별 및 전처리 방법론
- LoRA 기반 효율적 Fine-tuning 프로세스 구현
- 비식별화 모델 성능 평가 실습
- vLLM 기반 비식별화 시스템 구축 및 운영

실습 프로세스 자세히보기
01.데이터셋 준비 및 가공
- 데이터셋 분석 및 전처리 수행
- 데이터의 민감한 정보 식별 기준 정의 및 데이터 라벨링
02. 성능 향상을 위한 파인튜닝
- LoRA(Low-Rank Adaptation) 기법의 작동 원리 학습
- Llama3.1 모델에 LoRA 적용하여 비식별화 모델 파인튜닝 진행
03. 성능평가
- OpenAI로 비식별화 처리의 정확도와 성능 평가
04. 구현 및 서빙하기
- vLLM으로 서빙하기
모든 실습은 현업과 동일한
유료 클라우드 환경에서 진행됩니다.
유료 클라우드인 RunPod은 멀티 GPU와 대규모 파인튜닝에 최적화된 고사양 환경을 제공하며,
Google Colab과 달리 실제 업무와 동일한 실무 경험을 제공합니다.
클라우드 환경 실습이 중요한 이유
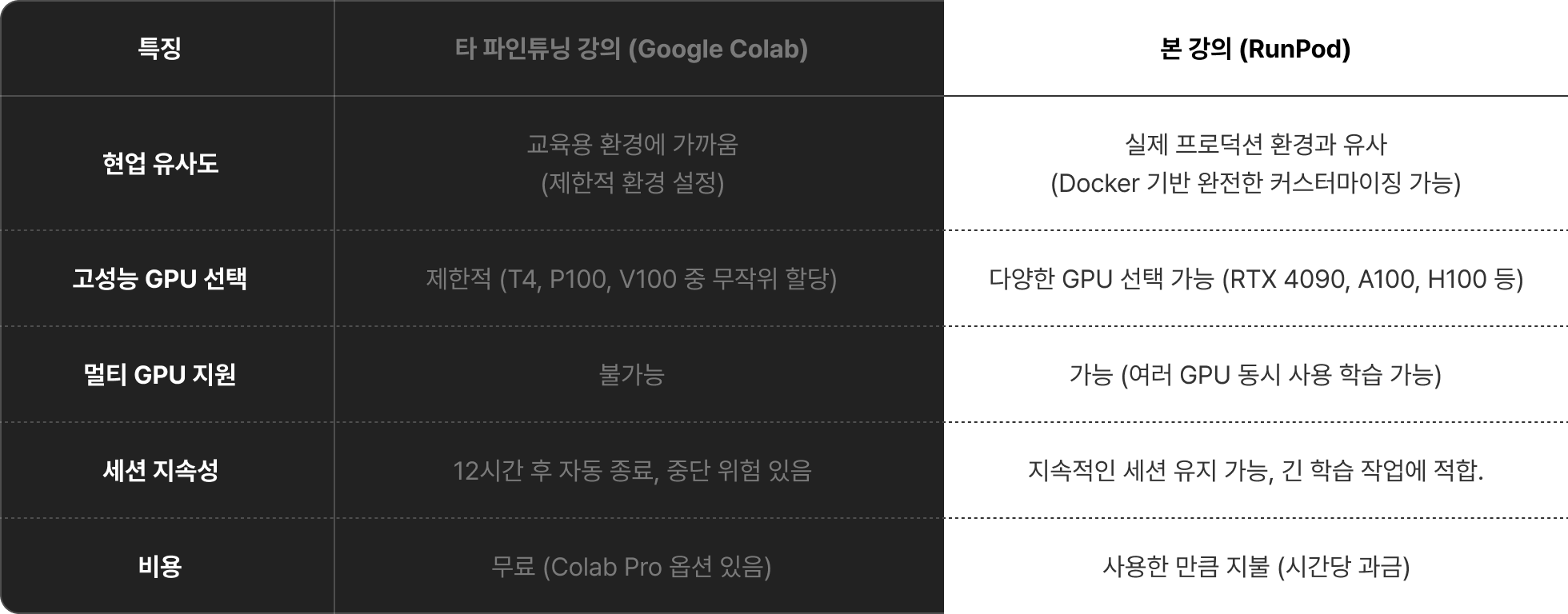
프로젝트 실습 비용은 강의 비용과 별개이며, 프로젝트별 예상 비용은 하단 QnA 섹션에서 확인하실 수 있습니다.
다양한 언어 모델을 기반으로
실습이 진행됩니다.
각각의 문제 상황에 적합한 언어모델을 선택하는 방법부터
언어 모델별 문제 해결을 위한 파인튜닝 방법을 전부 학습하실 수 있습니다.
언어 모델
Llama 3.1
Qwen 2.5
Qwen2-vl
Qwen 2.5 coder
임베딩 모델
BGE-M3
각 언어 모델 별 특징
언어 모델명
언어모델 특징
1. Llama 3.1
최초의 프론티어급 오픈소스 AI
· 모델 크기 : 405B 메인 모델 및 8B, 70B 추가 모델.
· 성능 : MMLU 88.6, GSM8K 96.8 등
· 주요 강점 :
8개 언어 지원과 뛰어난 수학/연산 능력.
128K 토큰 컨텍스트로 복잡한 작업 처리에 최적.
2. Qwen 2.5
다국어 지원과 유연한 크기를 제공하는 다재다능한 모델
· 모델 크기 : 0.5B~72B.
· 특징 : 18T 학습 데이터로 안정적 성능 (MMLU-redux 86.8).
· 주요 강점 :
29개 언어 지원, 챗봇 및 롤플레이 특화.
128K 토큰 컨텍스트와 8K 토큰 생성 가능.
3. Qwen2-VL
시각적 작업과 다국어 이미지 처리에 최적화된 비전-언어 모델
· 기술적 강점 : Native Resolution 입력, M-ROPE 포지셔널 임베딩 적용.
· 특징 : 다양한 해상도의 이미지와 20분 이상의 긴 영상 처리 지원.
· 주요 강점 :
유럽어, 중국어, 일본어, 한국어 등 다국어 이미지 텍스트 이해.
모바일/로봇 기기 제어 지원.
DocVQA, RealWorldQA 등 주요 벤치마크에서 우수한 성능.
4. Qwen2.5-Coder
개발 환경에 특화된 GPT-4급 코딩 능력을 제공하는 모델
· 모델 크기 : 0.5B~32B.
· 특징 : 범용 지식과 수학적 능력을 겸비해 실제 개발 작업에 최적화.
· 주요 강점 :
코드 생성 및 리뷰, 버그 탐지와 수정.
코드 최적화 제안 및 개발 문서 작성 지원.
04. 특별 혜택

· 질의응답 커뮤니티는 디스코드를 통해 운영되며, 1차 오픈일 부터 28년 1월 12일까지 운영됩니다.
· 운영 기간은 당사 상황에 따라 변경될 수 있습니다.
초보자를 위한
다양한 부가 혜택까지
![ImageSlide<span style="color: rgba(255, 255, 255, 0.5);"> · 부록 파트의 경우 [파이썬으로 개발하는 빅데이터 기반 맛집 추천 서비스 (ft. Django, FastAPI) Online.] 강의 Part1 에서 발췌된 영상입니다.](https://cdn.day1company.io/prod/uploads/202501/160627-1472/08-benefit3.webp)
· 부록 파트의 경우 [파이썬으로 개발하는 빅데이터 기반 맛집 추천 서비스 (ft. Django, FastAPI) Online.] 강의 Part1 에서 발췌된 영상입니다.


QUESTION 1.
어떤 분들이
수강하시면 좋을까요?
수강하시면 좋을까요?
이 강의는 LLM을 서비스에 적용해 보고 싶은 분들, 데이터 준비와 파인튜닝 실무 역량을 키우고자 하는 분들께 추천합니다.
RAG 고도화, 고객 응대 챗봇 개발, 멀티모달, 금융, 데이터베이스 등 다양한 도메인의 LLM 서비스 구축을 목표로 하시는 분들께 특히 유용합니다.
또한, 혐오 표현 탐지, 데이터 비식별화, Text-to-SQL 등 현업에서 자주 필요한 과제를 함께 다루며, 데이터 준비부터 서비스 배포까지 실무 전 과정을 친절하게 안내합니다.
RAG 고도화, 고객 응대 챗봇 개발, 멀티모달, 금융, 데이터베이스 등 다양한 도메인의 LLM 서비스 구축을 목표로 하시는 분들께 특히 유용합니다.
또한, 혐오 표현 탐지, 데이터 비식별화, Text-to-SQL 등 현업에서 자주 필요한 과제를 함께 다루며, 데이터 준비부터 서비스 배포까지 실무 전 과정을 친절하게 안내합니다.
QUESTION 2.
RAG에 파인튜닝이
꼭 필요한가요?
꼭 필요한가요?
네, 필요하다고 볼 수 있습니다.
RAG는 검색 정확도와 생성 품질이 모두 중요한 만큼, 파인튜닝을 통해 도메인 특화 모델을 학습하면 일반 모델이 해결하지 못하는 세부적인 문제를 보다 정확하게 해결할 수 있습니다.
예를 들어, 도메인 특화 데이터를 학습한 모델은 일반 모델에 비해 맥락에 맞고 신뢰할 수 있는 결과를 제공합니다.
결국, 현업에서는 RAG와 파인튜닝을 결합해 도메인에 최적화된 LLM 서비스를 구축하는 것이 필요합니다.
RAG는 검색 정확도와 생성 품질이 모두 중요한 만큼, 파인튜닝을 통해 도메인 특화 모델을 학습하면 일반 모델이 해결하지 못하는 세부적인 문제를 보다 정확하게 해결할 수 있습니다.
예를 들어, 도메인 특화 데이터를 학습한 모델은 일반 모델에 비해 맥락에 맞고 신뢰할 수 있는 결과를 제공합니다.
결국, 현업에서는 RAG와 파인튜닝을 결합해 도메인에 최적화된 LLM 서비스를 구축하는 것이 필요합니다.
QUESTION 3.
유료 클라우드 사용 비용이
별도로 발생하나요?
별도로 발생하나요?
본 강의의 프로젝트 진행 시, 클라우드 사용에 따른 소정의 비용이 발생할 수 있습니다.
일반 프로젝트의 경우 약 2만 원 내외, 이미지를 활용하는 Chapter 9의 경우 약 4만 원 내외의 비용이 예상됩니다.
하지만 모든 프로젝트를 꼭 수행할 필요는 없습니다.
필요하신 내용만 선택적으로 진행하셔도 충분히 학습 목표를 달성할 수 있습니다.
최소한의 비용으로도 실무에 꼭 필요한 핵심 내용을 효과적으로 익히실 수 있도록 구성했습니다.
일반 프로젝트의 경우 약 2만 원 내외, 이미지를 활용하는 Chapter 9의 경우 약 4만 원 내외의 비용이 예상됩니다.
하지만 모든 프로젝트를 꼭 수행할 필요는 없습니다.
필요하신 내용만 선택적으로 진행하셔도 충분히 학습 목표를 달성할 수 있습니다.
최소한의 비용으로도 실무에 꼭 필요한 핵심 내용을 효과적으로 익히실 수 있도록 구성했습니다.
QUESTION 4.
학습을 위해 필요한
사전 지식이 있을까요?
사전 지식이 있을까요?
학습을 위해 특별한 사전 지식은 필요하지 않습니다.
강의에서 파이썬 기초를 제공하므로, 파이썬을 처음 접하시는 분들도 충분히 따라오실 수 있습니다. 다만, 학습을 더욱 효과적으로 진행하기 위해 다음과 같은 태도와 습관이 있으면 도움이 됩니다.
- 구글 검색을 통해 스스로 답을 찾아가는 습관
- 새로운 기술을 배우고자 하는 의지
- 문제해결 과정을 즐기는 태도
- 꾸준한 학습 의지
이러한 자세만 갖추고 있다면 누구나 쉽게 시작할 수 있도록 구성되어 있습니다.
강의에서 파이썬 기초를 제공하므로, 파이썬을 처음 접하시는 분들도 충분히 따라오실 수 있습니다. 다만, 학습을 더욱 효과적으로 진행하기 위해 다음과 같은 태도와 습관이 있으면 도움이 됩니다.
- 구글 검색을 통해 스스로 답을 찾아가는 습관
- 새로운 기술을 배우고자 하는 의지
- 문제해결 과정을 즐기는 태도
- 꾸준한 학습 의지
이러한 자세만 갖추고 있다면 누구나 쉽게 시작할 수 있도록 구성되어 있습니다.