Question 1
어떤 분들이
수강하시면 좋을까요?
FuriosaAI와 함께 NPU로 끝내는 Computer Vision 프로젝트 구현

ONLINE #AI 반도체 #NPU #Computer Vision 모델 개발 및 배포 #WARBOY
FuriosaAI와 함께 NPU로 끝내는
Computer Vision 프로젝트 구현
NPU를 활용하여 AI 서비스를 개발하면서 발생하는 대표 4가지 병목 지점인 Latency, Throughput, 전력 소비, 정확성 4가지 문제를 한 번에 잡을 수 있는 강의
 기본 정보
기본 정보
∙ Vision & LLM, Multimodal 구현 가능한 AI 개발자
 강의 특징
강의 특징
 강의 공개
강의 공개
[300% 페이백 : 7월 8일 쿠폰 3종 자동 발급]FuriosaAI와 함께 NPU로 끝내는 Computer Vision 프로젝트 구현
FuriosaAI와 함께 NPU로 끝내는 Computer Vision 프로젝트 구현
일상 속에서 쉽게 볼 수 있는
AI 서비스들의 개발 과정에서 발견할 수 있는 공통점은?

바로 반도체를 활용한 AI 추론 연산을 진행한다는 것!
AI 추론 연산을 진행하는 반도체에는
대표적으로 어떤 반도체가 있을까요?
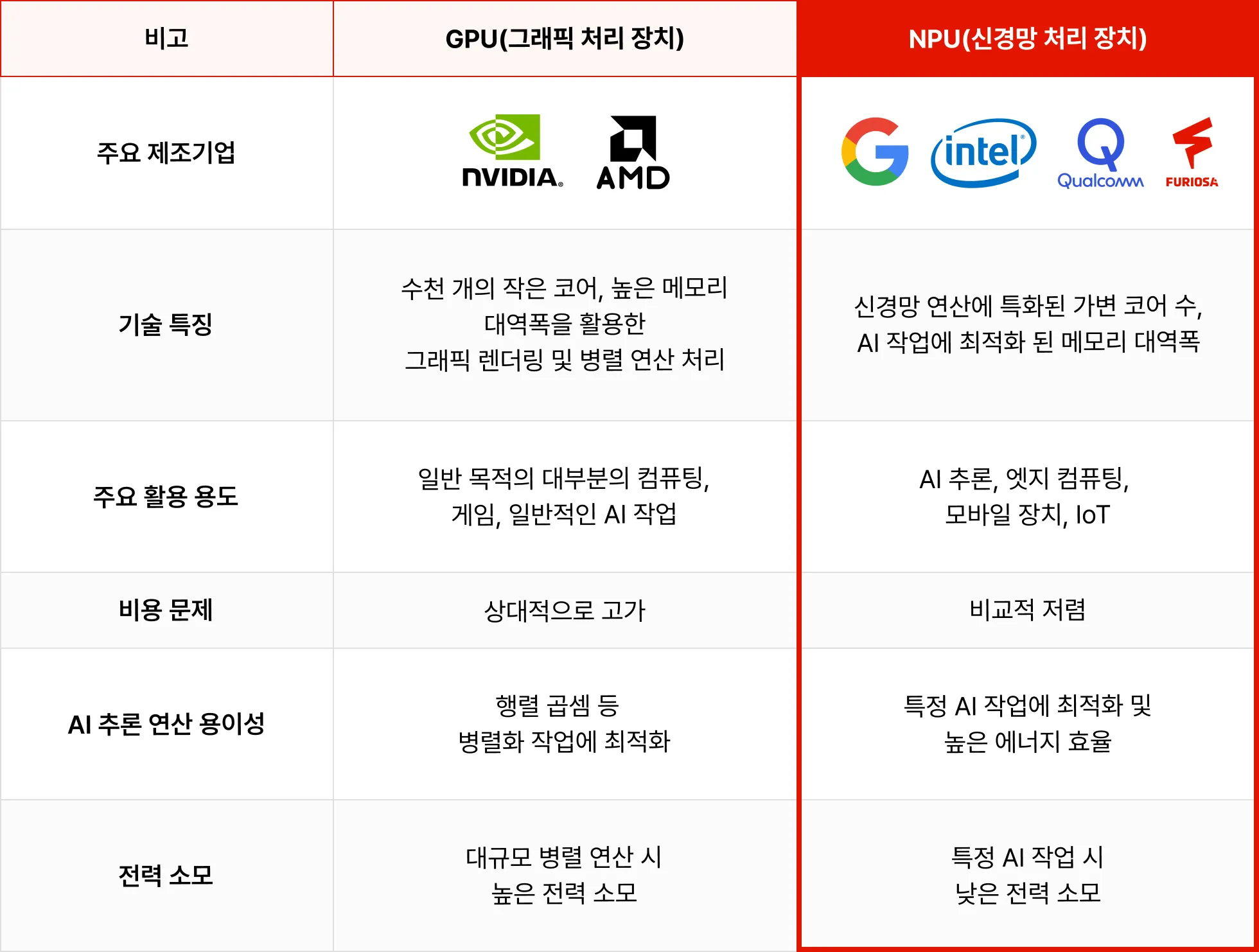
현재 시장에서는 NVIDIA가 GPU 시장을 휩쓸며
AI 추론 연산에 대표적으로 활용되고 있습니다.

엔비디아, 2024년 1분기 매출 35조 5,000억원 달성

‘GPU 품귀’ 언제까지 이어질까... 굳건한 엔비디아 천하

엔비디아, ‘GPU 가상화’ 스타트업 인수 추진


그러나!
GPU가 AI Application 개발에 적합하지 않다는 사실,
알고 계셨나요?
인공지능 서비스에 필요햔 대용량 연산 처리의 최적화에 GPU가 활용되고 있지만
학습 및 추론 과정에서 중간 데이터들을 저장하는 메모리와의 연결 구조의 비효율성으로 인해 비용과 전력 손실이 크고,
AI 알고리즘을 고려한 최적화가 어려워 특정 AI 서비스 개발에 부적합합니다.
그래서 최근에는 NPU라는 인공지능 반도체 개념이 새롭게 등장하며
AI 서비스 개발의 핵심 요소로 주목받고 있습니다.

그렇다면 인공지능 반도체,
NPU란 무엇인가요?


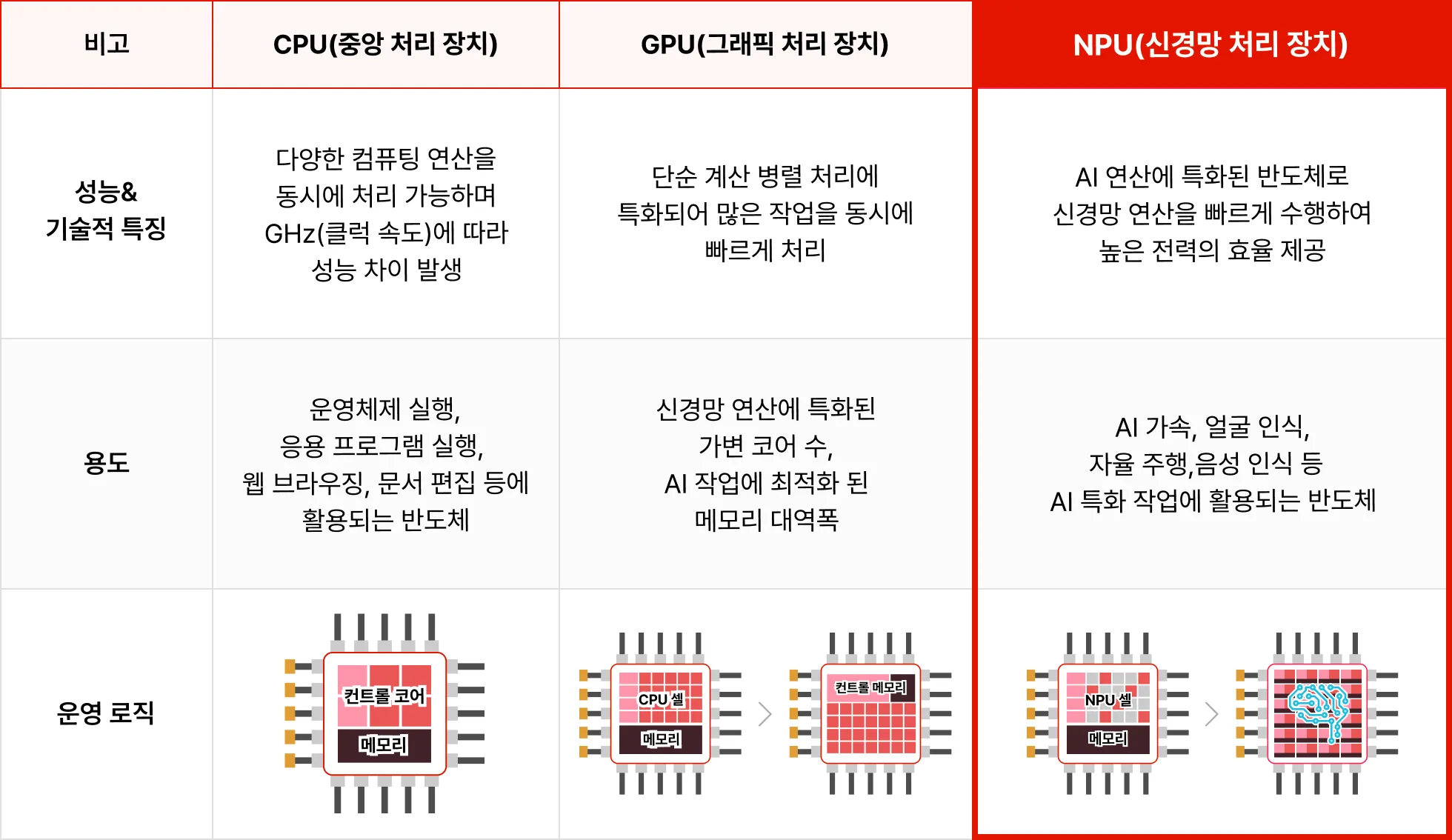
AI 컴퓨팅 연산과 추론에 있어서 최적화 된 NPU
효과적인 AI 서비스 개발을 위해서라면, 필수로 학습해야 합니다.

국내 AI 반도체 분야에서 선두를 달리고 있는 FuriosaAI와 함께
인공지능 서비스 개발의 핵심 요소인 AI 반도체, NPU를 학습합니다.

KEY POINT 1
AI 반도체 시장의 이해
AI 반도체에 활용되는 반도체들의 종류와 주요 흐름,그리고 현재 NPU가 AI 반도체 중 주목받고 있는 이유를 학습합니다.

OpenAI의 사례부터 NPU의 핵심 경쟁력이
AI 서비스 개발 과정에서 어떻게 작용되고 있는지 학습합니다.


KEY POINT 2
AI Application 개발을 위한 Computer Vision 기초와
Computer Vision 연산에 특화 된 NPU, Warboy 실습
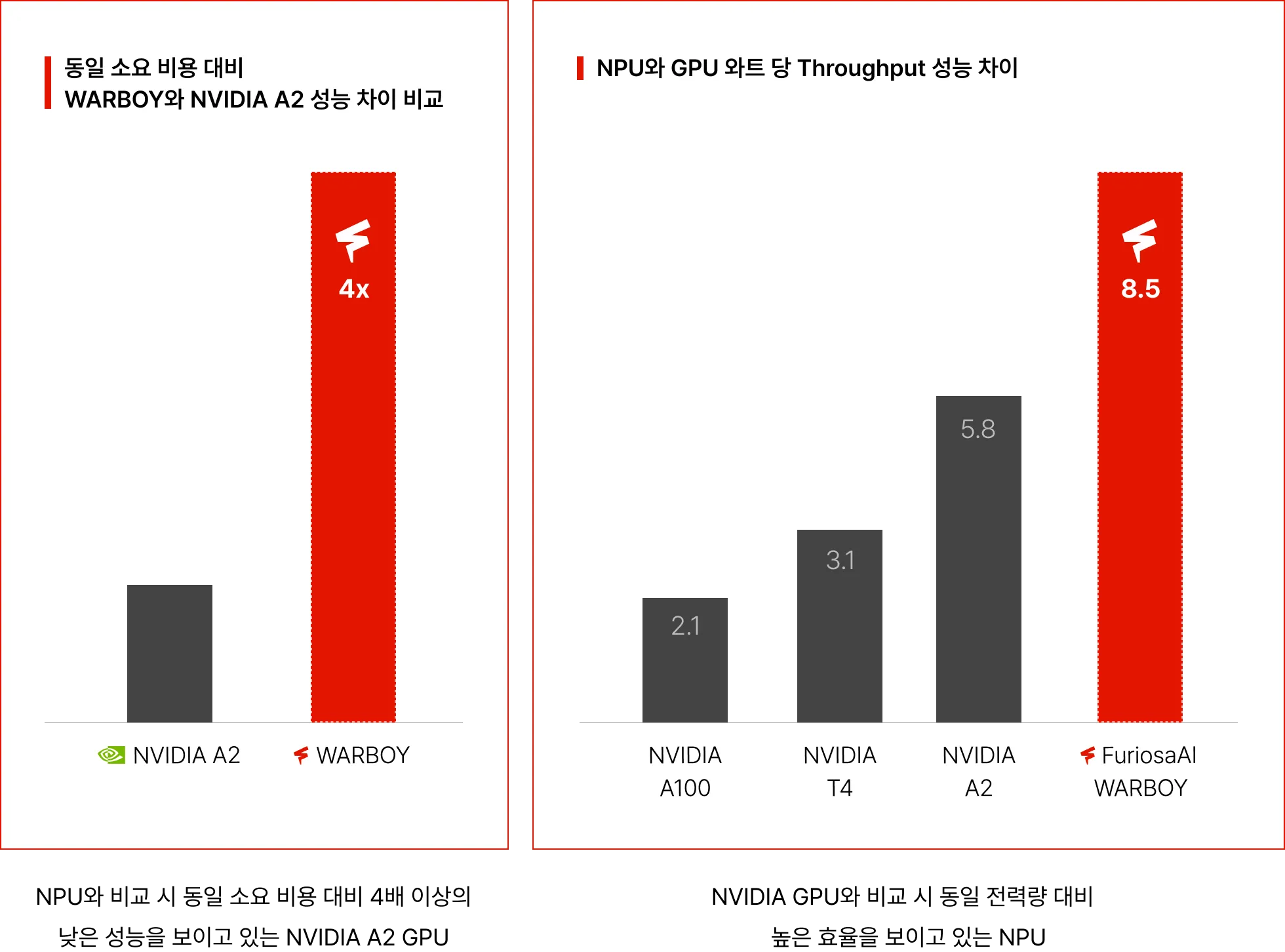
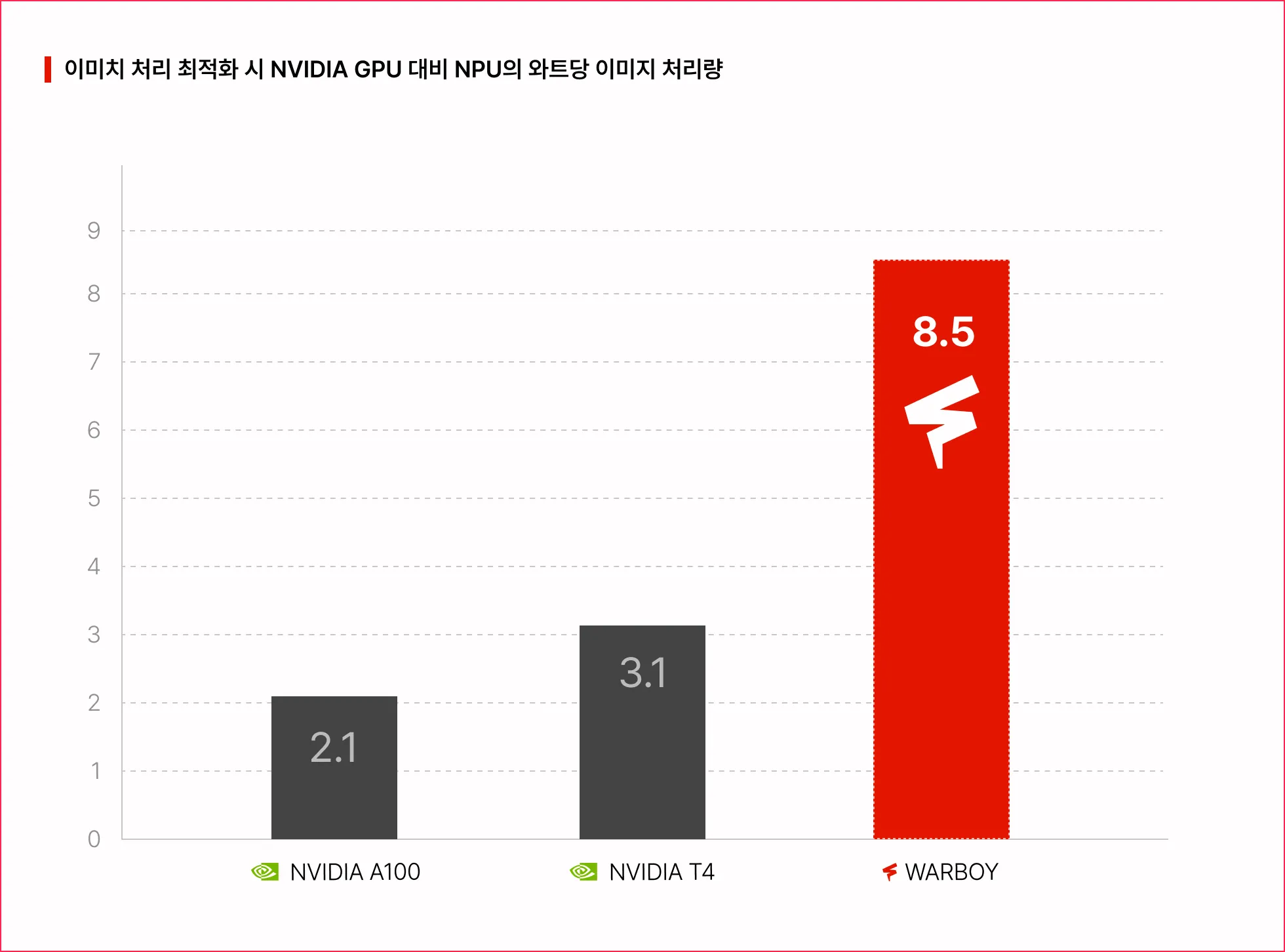
NPU가 Vision 모델 연산 시 전력 대비 높은 성능을 보여주고 있는지 학습합니다.
※ 실제 강의에서는 NPU를 직접 활용하는 실습이 아닌 Furiosa AI에서 제공하는 코드를 활용하여 실습하게 됩니다.
STEP 01
ONNX EXPORT
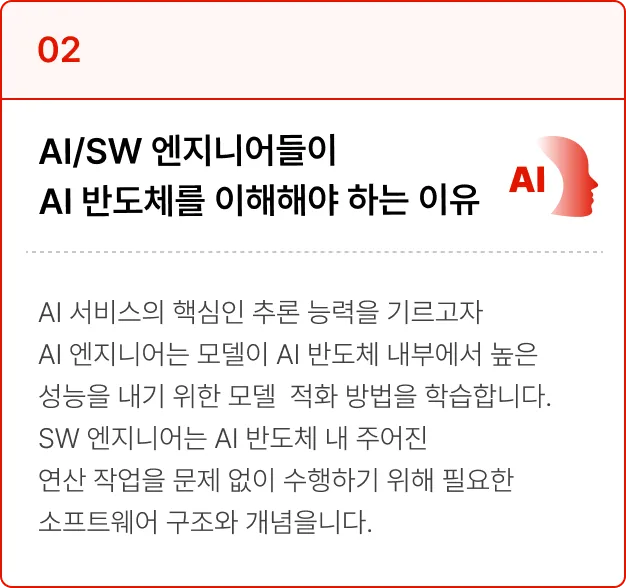
NPU에서 실행한 Binary를 만들기 위해 NPU Compiler를 구성하는 방법을 학습합니다.


ONNX란?

‘Open Neural Network Exchange’ 의 약자로,
다양한 DNN 프레임워크 환경(eg. Pytorch, Tensorflow, Python, etc..)에서
만들어진 AI 모델들이 서로 호환될 수 있게 만들어진 공유 플랫폼입니다.

STEP 02
Quantization Method(모델 학습 최적화 기법)
NPU 환경에서 모델 크기가 커지면 커질수록 Latency가 길어짐에 따라 추론 시간이 길어집니다.
지연 시간을 줄이기 위해 Vision 모델을 경량화하는 10가지 Quantization 기법을 학습합니다.

MIN-MAX_ASYM(Asymmetric Min-Max)
데이터의 최소값과 최대값을 사용하여
양자화 범위를 결정하는 방법을 학습합니다.
데이터의 최소값과 최대값을 사용하여
양자화 범위를 결정하는 방법을 학습합니다.
MIN-MAX_SYM(Symmetric Min-Max)
데이터의 절대 최대값을 사용하여
대칭적인 양자화 범위를 결정하는 방법을 학습합니다.
데이터의 절대 최대값을 사용하여
대칭적인 양자화 범위를 결정하는 방법을 학습합니다.

ENTROPY_ASYM(Asymmetric ENTROPY)
데이터의 엔트로피(데이터의 불규칙성)을 기준으로
범위를 결정하는 방법을 학습합니다.
데이터의 엔트로피(데이터의 불규칙성)을 기준으로
범위를 결정하는 방법을 학습합니다.
ENTROPY_SYM
엔트로피(데이터의 불규칙성)를 기준으로
대칭적인 양자화 범위를 결정하는 방법을 학습합니다.
엔트로피(데이터의 불규칙성)를 기준으로
대칭적인 양자화 범위를 결정하는 방법을 학습합니다.

PERCENTILE_ASYM(Asymmetric Percentile)
Talking, Drawin 데이터의 특정 백분위수 값을 기준으로
양자화 범위를 결정하는 방법을 학습합니다.
Talking, Drawin 데이터의 특정 백분위수 값을 기준으로
양자화 범위를 결정하는 방법을 학습합니다.
PERCENTILE_SYM(Symmetric Percentile)
데이터의 특정 백분위수 값을 기준으로
대칭적인 범위를 결정하는 방법을 학습합니다.
데이터의 특정 백분위수 값을 기준으로
대칭적인 범위를 결정하는 방법을 학습합니다.

MSE_ASYM(Asymmetric Mean Squared Error)
양자화 오차의 제곱의 평균(MSE)를
최소화하는 방식으로 범위를 결정하는 방법을 학습합니다.
양자화 오차의 제곱의 평균(MSE)를
최소화하는 방식으로 범위를 결정하는 방법을 학습합니다.
MSE_SYM(Symmetric Mean Squared Error)
대칭적인 MSE를 기준으로 양자화 범위를 결정하는 방법을 학습합니다.
대칭적인 MSE를 기준으로 양자화 범위를 결정하는 방법을 학습합니다.

SQNR_ASYM(Asymmetric Signal-to-Quantization-Noise Ratio)
신호 대 양자화 잡음 비율(SQNR)을
최대화하는 방식으로 범위를 결정하는 방법을 학습합니다.
신호 대 양자화 잡음 비율(SQNR)을
최대화하는 방식으로 범위를 결정하는 방법을 학습합니다.
SQNR_SYM(Symmetric Signal-to-Quantization-Noise Ratio)
대칭적인 SQNR을 기준으로 양자화 범위를 결정하는 방법을 학습합니다.
대칭적인 SQNR을 기준으로 양자화 범위를 결정하는 방법을 학습합니다.
STEP 03
Quantization Method(모델 학습 최적화 기법)
모델을 최적화해서 지연 시간을 줄여보았다면, 이번에는 추론을 효과적으로 실행할 차례입니다.
Runtime 최적화로 지연 시간을 줄이고 추론 처리량을 향상 시키는 방법을 학습합니다.


STEP 04
Application on Warboy
배운 내용을 활용하여 Computer Vision 알고리즘 기초를 학습하고 NPU에 구동 시켜봅니다.
모델 경량화, Runtime 최적화 기술을 응용하여 NPU 환경에서 AI 서비스를 개발하는 방법을 학습합니다.


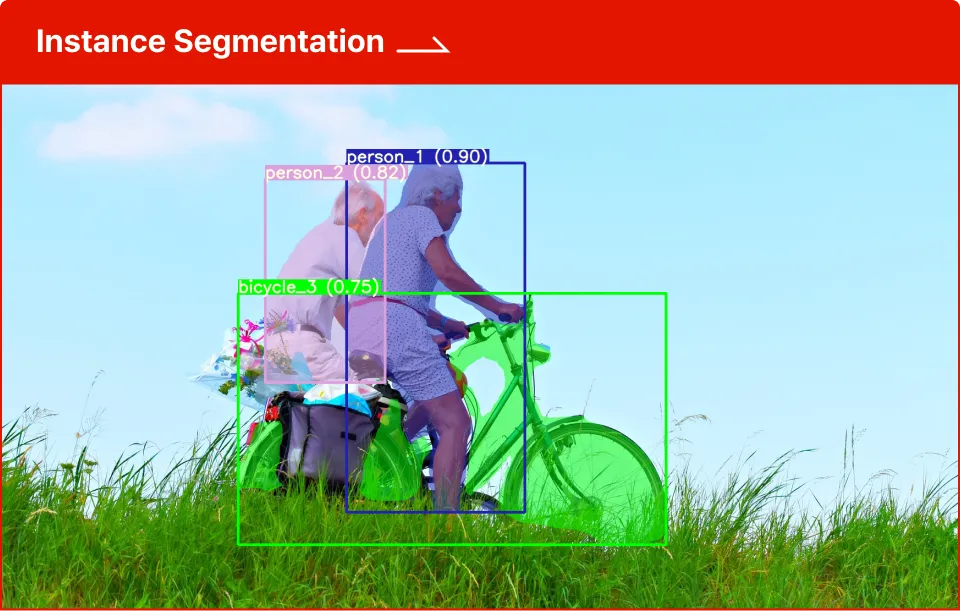




KEY POINT 3
NPU Performance Review
AI 서비스 개발 경쟁력의 핵심인 낮은 Latency와 높은 Throughput을 내기 위해NPU의 성능을 평가 및 프로파일링 하는 방법을 학습합니다.

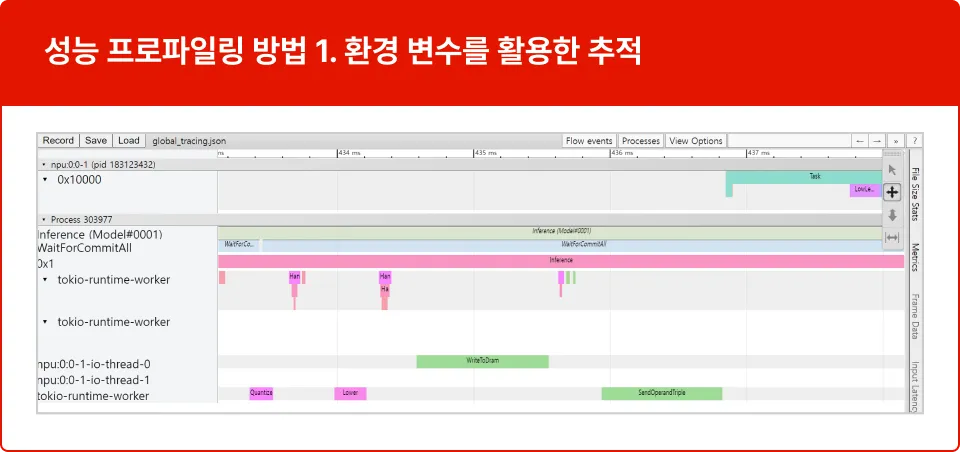
FURIOSA_PROFILER_OUTPUT_PATH에 추적 결과가
기록될 파일의 경로를 설정하여 추적 생성을 활성화하는 방법을 학습합니다.
이 방법의 장점은 코드 변경 없이도 추적이 가능합니다.
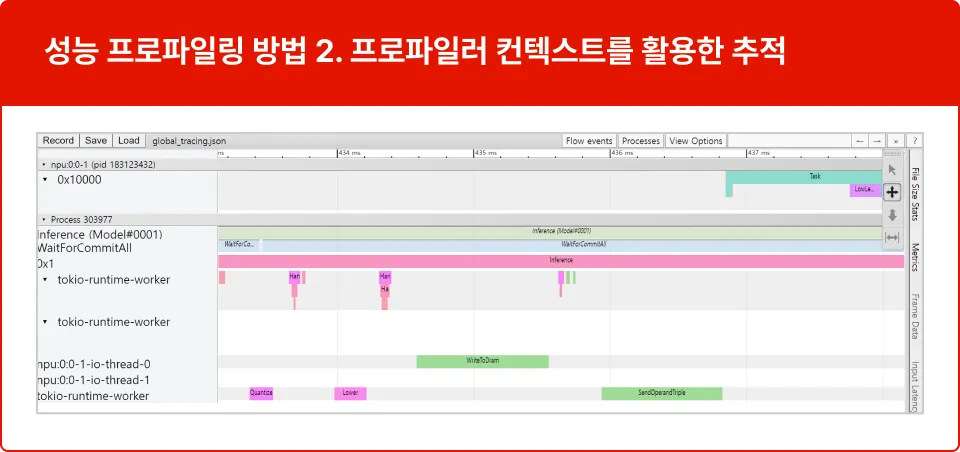
Profiler Context를 활용하여 모델 추론 성능을 추적하는 방법입니다.
특정 추론 실행에 대한 레이블 지정을 허용하고
지정된 연산자 범주를 선택적으로 측정하는 방법을 학습합니다.
KEY POINT 4
FuriosaAI와 함께하는 Vision AI와 NPU 기초 첫걸음
대한민국 AI 반도체 NPU 업계에서 선두를 달리고 있는FuriosaAI의 구형일 교수님 & 정영범 디렉터님과 함께하는 NPU 설계 강의




앞으로는 AI 서비스를 도입하는 단계에서 전력을 많이 사용하는 GPU 대신,
추론에 특화되어 효율적인 NPU를 많이 사용하게 되길 바라며
이 변화의 첫 걸음이 되기를 바라는 마음에서 이 강의를 준비하였습니다.
• AI 서비스를 운영하거나 혹은 개발 예정인 상황에서 GPU를 활용하여
AI Application을 추론하고 있는 AI Engineer & 개발자
Question 2
필요한
선수지식이 있을까요?
필요한
선수지식이 있을까요?
• Python과 Pytorch 프레임워크 능숙한 활용
• Vision, LLM, Multimodal의 이해
• Vision, LLM, Multimodal의 이해
Question 3
개발 환경
개발 환경
• Python Jupyter Notebook 개발 환경
커리큘럼
아래의 모든 강의를 이 강의 하나로 모두 들을 수 있습니다.지금 한 번만 결제하고 모든 강의를 평생 소장하세요!
Part 01. AI 반도체 시장의 이해
Part 02. AI Application 개발을 위한 비전 기초와 NPU 실습
Part 03. Computer Vision 모델 개발 및 배포
Part 04. Vision AI Application on WARBOY
Part 05. Performance Review
-
상세 커리큘럼.
자세한 커리큘럼 및 내용은 여기서 확인하세요!
추천강의